构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(下)
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大、综合成本低、支持非结构化数据、查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式。
作为微软Azure上最新一代的数据湖服务,Data Lake Storage Gen2的发布,将云上数据湖的能力和体验提升上了一个新的台阶。在前面的文章中,我们已分别介绍了其基本使用和大数据集群挂载的场景。作为本系列的下篇,让我们继续深度体验之旅。
ADLS Gen2体验:数据湖共享
在企业中,一个庞大的数据湖往往需要被共享。比如数据湖通常会被划分为多个区域,这些区域最好能够被各自对应的计算集群所访问以进行不同的计算任务。这也充分体现了计算存储分离的理念,是云计算的架构精髓。那么ADLS Gen2能否支持这一重要场景呢?
答案是肯定的。对于各计算集群而言,不妨淡化它自己的“本地”存储,转为考虑集群是否能够读取访问远端的数据湖实例——在这样的思路下,就可以设立一个统一而独立的数据湖实例,被多个计算集群共享,同时按目录进行权限设置和数据隔离。数据湖的生命周期可独立于计算集群的创建和销毁,在需要时作为外部数据被引用和访问就可以了。
接下来我们以前篇文章创建的HDInsight Spark集群为例,继续数据湖共享的实战验证。微软的一段文档告诉了我们如何让HDInsight集群访问“外部”的ADLS Gen2:
To add a secondary Data Lake Storage Gen2 account, at the storage account level, simply assign the managed identity created earlier to the new Data Lake Storage Gen2 storage account that you wish to add.
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-use-data-lake-storage-gen2
看起来颇为容易,只需要将代表集群的identity赋予相应的ADLS Gen2权限即可。注意这里的权限粒度事实上可以设置得非常细致,精确到目录乃至文件层级,这正是我们需要的。
接下来我们来构建和实验这样一个常见的重要场景:原始数据位于数据湖的区域一中,由集群1的spark程序来进行处理,并将处理后的数据落地到同一数据湖的区域二中;集群2则利用hive来对区域二中的处理后数据进行查询。注意这里由于计算存储进行了分离,数据处理和查询集群都可以是无状态的,无工作负载时可以关闭,也能够随时创建或横向扩展。
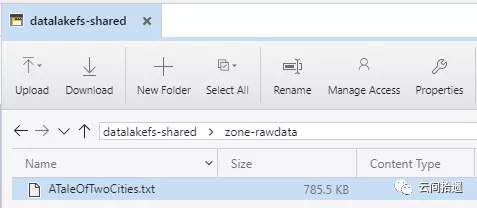
我们先来准备共享数据湖,在系列上篇中已经创建的存储账号cloudpickerdlg2中新建一个文件系统datalakefs-shared用于共享数据。随后在其中分别建立zone-rawdata和zone-processed两个文件夹,并在zone-rawdata文件夹中存放入前面使用过的小说《双城记》文本文件ATaleOfTwoCities.txt:
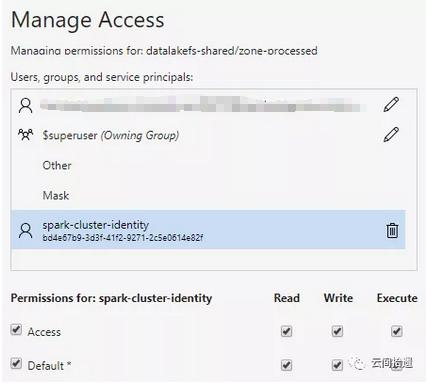
接下来,为使Spark集群顺利访问这个中央数据湖中的数据,我们只需对之前创建的spark-cluster-identity分别对两个文件夹进行授权。这里为zone-rawdata赋予读权限,对于zone-processed赋予读写权限: 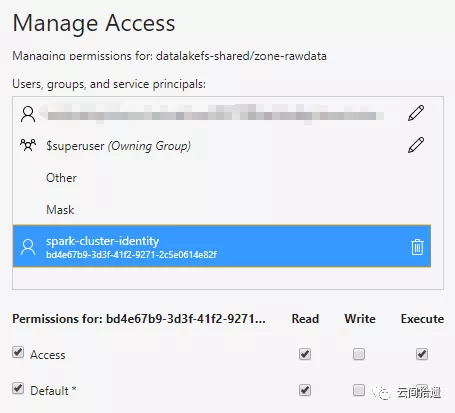
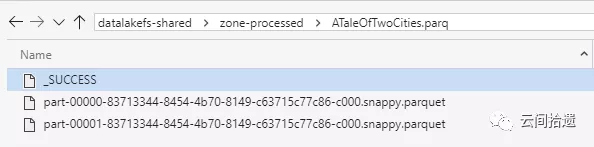
随后,我们就可以复用系列中篇里的Spark集群来访问这个远端的数据湖了。再次祭出Jupyter Notebook进行数据处理,并将Spark的处理结果以parquet形式写入zone-processed:
val domain = "abfss://datalakefs-shared@cloudpickerdlg2.dfs.core.windows.net/"
val book = spark.sparkContext.textFile(domain + "zone-rawdata/ATaleOfTwoCities.txt")
val wordCounts = book.flatMap(l => l.split(" ")).map(w => (w, 1)).reduceByKey((a,b) => a+b).map( { case (w, c) => (w, c, w.length) } )
val wordCountsWithSchema = spark.createDataFrame(wordCounts).toDF("word", "count", "word_length")
wordCountsWithSchema.write.parquet(domain + "zone-processed/ATaleOfTwoCities.parq")
运行之后可以看到,结果集parquet文件已经位于zone-processed中了。
接下来我们进行考虑查询数据湖的部分,可以创建一个独立的Hive查询集群并指向数据湖上的处理结果。在Azure上有一个专门为高性能在线查询优化的HDInsight大数据集群类型,被称为Interactive Query,其中使用了Hive LLAP,很适合我们的场景。我们不妨就部署它作为查询集群。

在此我们略去建立Hive LLAP集群的详细过程,其步骤与建立Spark集群类似,按照Wizard的提示逐步选取即可。需要注意的是,我们也相应地需要为查询者创建一个对应的身份hive-cluster-identity,并将这个hive-cluster-identity设置为查询集群的身份。 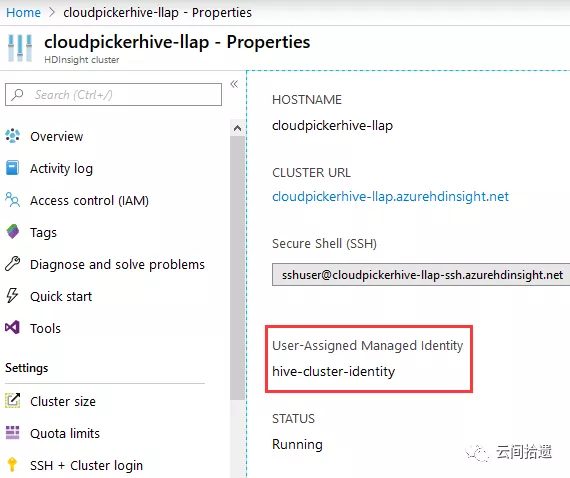
在共享数据湖datalakefs-shared方面无需和查询集群发生直接关联,只要把待读取的路径(zone-processed文件夹)向hive-cluster-identity开放读取权限即可:

然后就可以在Hive集群上用SQL来进行数据湖查询了:
--创建外部表指向数据湖中parquet数据
create external table WordsOnDataLake(
word string,
count int,
word_length int
) STORED AS PARQUET
LOCATION 'abfss://datalakefs-shared@cloudpickerdlg2.dfs.core.windows.net/zone-processed/ATaleOfTwoCities.parq'; -- 立刻就能直接查询数据湖上数据,例如按单词长度分组聚合统计
select word_length, sum(count) as total_count from WordsOnDataLake
group by word_length
order by total_count desc
limit 10;
最后顺利地跑出了结果:
+--------------+--------------+--+
| word_length | total_count |
+--------------+--------------+--+
| 3 | 31667 |
| 4 | 24053 |
| 2 | 22800 |
| 5 | 15942 |
| 6 | 12133 |
| 7 | 9624 |
| 8 | 6791 |
| 9 | 4716 |
| 1 | 4434 |
| 0 | 4377 |
+--------------+--------------+--+
10 rows selected (4.295 seconds)
可以看到Hive LLAP顺利地读取了远端数据湖的数据,而且速度颇为可观,数秒内就返回了结果。如果关闭LLAP模式而采用传统方式执行(将hive.llap.execution.mode设为none),笔者实验下来同样的查询需要25秒左右才能完成。
在实际场景中,Hive LLAP集群可以始终保持在线,以便应对随时到来的查询请求;而负责ETL的Spark集群则可按需启动,计算任务完成后关闭。这样的设计既充分利用了共享数据湖的架构,也体现了云端按需伸缩启停的特点。
总结
数据湖是近年流行的架构思维,有助于提高数据服务能力的灵活性,也为企业跨领域统一大数据平台的构建提供了指导范式和落地支撑。
因此,公有云巨头们纷纷为数据湖构建提供及增强了对应的产品线,本系列文章聚焦的Azure
Data Lakge Storege
Gen2即是其中杰出代表。通过三篇文章的层层深入,我们既分析了产品功能,又结合应用场景进行了POC验证。实践证明,ADLS
Gen2能够成为构建企业级数据湖的坚实基础和可靠保障。
最后,我们使用一张架构图来作为全文的收束,它很好地总结了ADLS Gen2的能力、定位及与周边系统的关系: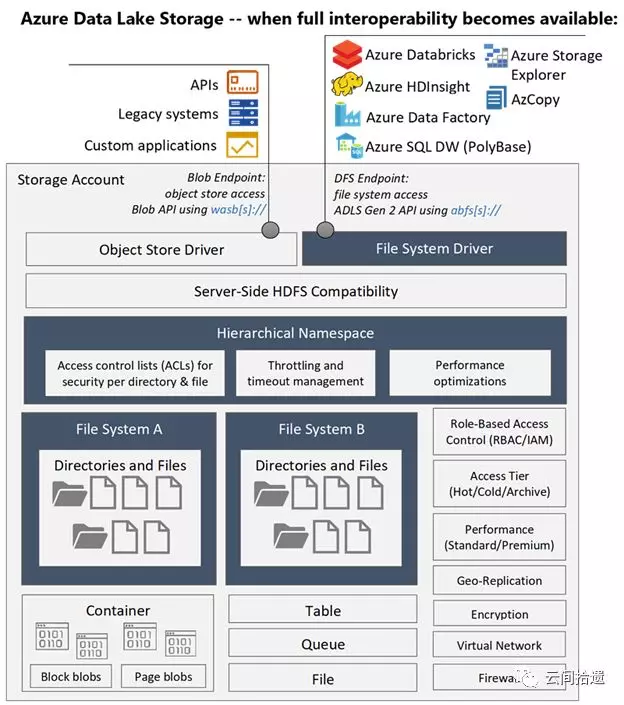
(图片来自https://www.blue-granite.com/blog/10-things-to-know-about-azure-data-lake-storage-gen2)
从现在开始,就请考虑利用ADLS Gen2和相关配套云服务,来构建你自己的数据湖吧!
相关文章:
构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(上)
构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(中)
“云间拾遗”专注于从用户视角介绍云计算产品与技术,坚持以实操体验为核心输出内容,同时结合产品逻辑对应用场景进行深度解读。欢迎扫描下方二维码关注“云间拾遗”微信公众号。

构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(下)的更多相关文章
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(中)
引言 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 因此数据湖相关服务 ...
- Azure Data Lake Storage Gen2实战体验
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2不容错过(上)
背景 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 数据湖的核心功能, ...
- Databricks 第8篇:把Azure Data Lake Storage Gen2 (ADLS Gen 2)挂载到DBFS
DBFS使用dbutils实现存储服务的装载(mount.挂载),用户可以把Azure Data Lake Storage Gen2和Azure Blob Storage 账户装载到DBFS中.mou ...
- 【Azure 存储服务】Hadoop集群中使用ADLS(Azure Data Lake Storage)过程中遇见执行PUT操作报错
问题描述 在Hadoop集中中,使用ADLS 作为数据源,在执行PUT操作(上传文件到ADLS中),遇见 400错误[put: Operation failed: "An HTTP head ...
- Azure Data Lake(一) 在NET Core 控制台中操作 Data Lake Storage
一,引言 Azure Data Lake Storage Gen2 是一组专用于大数据分析的功能,基于 Azure Blob Storage 构建的.Data Lake Storage Gen2 包含 ...
- 使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入 大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的.遵循的基本原则之一是文件的"一次写入多次读取"访问模型.这对于处理 ...
- Big Data Solution in Azure: Azure Data Lake
https://blogs.technet.microsoft.com/dataplatforminsider/2015/09/28/microsoft-expands-azure-data-lake ...
- data lake 新式数据仓库
Data lake - Wikipedia https://en.wikipedia.org/wiki/Data_lake 数据湖 Azure Data Lake Storage Gen2 预览版简介 ...
随机推荐
- pt-archiver归档数据 源库和目标库是否会出现不一致
背景 归档的表在源库和目标库都要存在 pt-archiver归档表的场景有:不删原表数据,非批量插入目标库:不删原表数据,批量插入目标库:非批量删除原表数据,非批量插入目标库:批量删除原表数据,批量插 ...
- javascript中数组常用的方法和属性
前言 在javascript中,数组是一种非常重要的数据类型,我们时常会和它打交道,最近在开发项目中频繁的使用到数组,但是自己对数组的众多方法已经是非常模糊了,为了方便自己以后能够更好的使用数组中的属 ...
- ol/ul/dl的区别
一.无序列表-ul(unorder list) 1.语法 <ul></ul>->Unorder List ...
- javaweb技术入门
JavaWeb巩固和进阶 1.如何配置外部应用? 方法一: server.xml 在<Host>中添加如下配置 <Context path="/xxx" docB ...
- SSM相关知识
1.SpringMVC的工作流程? 1. 用户发送请求至前端控制器DispatcherServlet 2. DispatcherServlet收到请求调用HandlerMapping处理器映射器. 3 ...
- ShaderHelper2 组件升级,支持自动枚举参数!
ShaderHelper2 组件新体验视频演示: https://www.bilibili.com/video/av69314195/ ShaderHelper2 组件我们已经介绍过两次了,不了解的伙 ...
- Java 学习笔记之 线程sleep方法
线程sleep方法: 单主线程使用sleep: Main线程差了2000毫秒. public class MainSleepThread extends Thread{ @Override publi ...
- MongoDB 学习笔记之 地理空间索引入门
地理空间索引: 地理空间索引,可用于处理基于地理位置的查询. Point:用于指定所在的具体位置,我们以restaurants为例: db.restaurants.insert({name: &quo ...
- vue运行报错webpack-dev-server: command not found
翻译过来就是: 'webpack-dev-server' 不是内部或外部命令,也不是可运行的程序 解决方法: 然后总结下成功的步骤: 1. 直接在项目目录下: cnpm install npm run ...
- Spring Boot 2.X(四):Spring Boot 自定义 Web MVC 配置
0.准备 Spring Boot 不仅提供了相当简单使用的自动配置功能,而且开放了非常自由灵活的配置类.Spring MVC 为我们提供了 WebMvcConfigurationSupport 类和一 ...