MYSQL之B+TREE索引原理
1.什么是索引?
索引:加速查询的数据结构。
2.索引常见数据结构
- 顺序查找: 最基本的查询算法-复杂度O(n),大数据量此算法效率糟糕。
- 二叉树查找:(binary tree search): O(log2n) ,二叉查找树根节点固定,非平衡。树高度深,高度决定io次数,io耗时大。
- hash索引 无法满足范围查找。
- 二叉树、红黑树 :导致树高度非常高(平衡二叉树一个节点只能有左子树和右子树),逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,IO次数多查找慢,效率低。todo 逻辑上相邻节点没法直接通过顺序指针关联,可能需要迭代回到上层节点重复向下遍历找到对应节点,效率低。
- B-Tree:结构:B-TREE 每个节点都是一个二元数组: [key, data],所有节点都可以存储数据。key为索引key,data为除key之外的数据。
检索原理:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或未找到节点返回null指针。
缺点:1.插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质。造成IO操作频繁。2.区间查找可能需要返回上层节点重复遍历,IO操作繁琐。
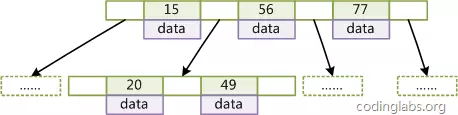
- B+Tree:B-Tree的变种,与B-Tree相比,B+Tree有以下不同点:非叶子节点不存储data,只存储索引key;只有叶子节点才存储data。
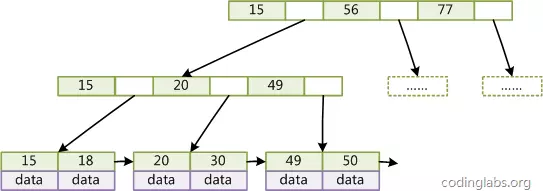
Mysql中B+Tree:在经典B+Tree的基础上进行了优化,增加了顺序访问指针。在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。这样就提高了区间访问性能:如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率(无需返回上层父节点重复遍历查找减少IO操作)。
结构如下:
3.为什么Mysql选择B+TREE索引? B+TREE索引有什么好处?
索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数,提升索引效率。
磁盘存取原理:
索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。与主存不同,磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的。
4.B-/+Tree索引的性能优势: 一般使用磁盘I/O次数评价索引优劣。
- 1.结合操作系统存储结构优化处理: mysql巧妙运用操作系统存储结构(一个节点分配到一个存储页中->尽量减少IO次数) & 磁盘预读(缓存预读->加速预读马上要用到的数据).
- 2.B+Tree 单个节点能放多个子节点,相同IO次数,检索出更多信息。
- 3.B+TREE 只在叶子节点存储数据 & 所有叶子结点包含一个链指针 & 其他内层非叶子节点只存储索引数据。只利用索引快速定位数据索引范围,先定位索引再通过索引高效快速定位数据。
- B-Tree索引、B+Tree索引: 单个节点能放多个子节点,查询IO次数相同(mysql查询IO次数最多3-5次-所以需要每个节点需要存储很多数据)
- B+TREE 只在叶子节点存储数据 & 所有叶子结点包含一个链指针 & 其他内层非叶子节点只存储索引数据。只利用索引快速定位数据索引范围,先定位索引再通过索引高效快速定位数据。
- B+Tree更适合外存索引,原因和内节点出度d有关。从上面分析可以看到,d越大索引的性能越好,而出度的上限取决于节点内key和data的大小:
- B+Tree内节点去掉了data域,因此可以拥有更大的出度,拥有更好的性能。只利用索引快速定位数据索引范围,先定位索引再通过索引高效快速定位数据。
5.B+树(平衡多路查找树)
B+树是为了磁盘或其它直接存取设备设计的一种平衡多路查找树。在B+树里是,所以记录节点都是键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接。
B+树索引在数据库中有高扇出性的特点,因此在数据库中,B+树的高度一般在2~4层,也就是说查找某一键值的行记录时最多只需要2~4次IO.
数据库中的B+树索引可以分为聚集索引和辅助索引,其内部都是B+树的,高度平衡,叶子节点存放着数据。
聚集索引和辅助索引不同的是,叶子节点存放的是否是一整行的信息。
MYSQL之B+TREE索引原理的更多相关文章
- MySQL数据库篇之索引原理与慢查询优化之一
主要内容: 一.索引的介绍 二.索引的原理 三.索引的数据结构 四.聚集索引与辅助索引 五.MySQL索引管理 六.测试索引 七.正确使用索引 八.联合索引与覆盖索引 九.查询优化神器--explai ...
- MySQL系列(九)--InnoDB索引原理
InnoDB在MySQL5.6版本后作为默认存储引擎,也是我们大部分场景要使用的,而InnoDB索引通过B+树实现,叫做B-tree索引.我们默认创建的 索引就是B-tree索引,所以理解B-tree ...
- MySQL数据库篇之索引原理与慢查询优化之二
接上篇 7️⃣ 正确使用索引 一.索引未命中 并不是说我们创建了索引就一定会加快查询速度,若想利用索引达到预想的提高查询速度的效果, 我们在添加索引时,必须遵循以下问题: #1 范围问题,或者说条件 ...
- Mysql的B+ Tree索引
为什么要使用索引? 最简单的方式实现数据查询:全表扫描,即将整张表的数据全部或者分批次加载进内存,由于存储的最小单位是块或者页,它们是由多行数据组成,然后逐块逐块或者逐页逐页地查找,这样查找的速度非常 ...
- MYSQL的B+Tree索引树高度如何计算
前一段被问到一个平时没有关注到有关于MYSQL索引相关的问题点,被问到一个表有3000万记录,假如有一列占8位字节的字段,根据这一列建索引的话索引树的高度是多少? 这一问当时就被问蒙了,平时这也只关注 ...
- 深入浅出分析MySQL MyISAM与INNODB索引原理、优缺点、主程面试常问问题详解
本文浅显的分析了MySQL索引的原理及针对主程面试的一些问题,对各种资料进行了分析总结,分享给大家,希望祝大家早上走上属于自己的"成金之路". 学习知识最好的方式是带着问题去研究所 ...
- 深入浅出分析MySQL MyISAM与INNODB索引原理、优缺点分析
本文浅显的分析了MySQL索引的原理及针对主程面试的一些问题,对各种资料进行了分析总结,分享给大家,希望祝大家早上走上属于自己的"成金之路". 学习知识最好的方式是带着问题去研究所 ...
- 数据库MySQL 之 索引原理与慢查询优化
数据库MySQL 之 索引原理与慢查询优化 浏览目录 索引介绍方法类型 聚合索引辅助索引 测试索引 正确使用索引 组合索引 注意事项 查询计划 慢查询日志 大数据量分页优化 一.索引介绍方法类型 1. ...
- MySQL之索引原理和慢查询优化
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
随机推荐
- 吉特日化MES-电子批记录普通样本
在实施吉特日化配料系统的时候,客户希望一键式生成生产过程电子批记录,由于功能的缺失以及部分设备的数据暂时还无法完全采集到,先做一个普通样本的电子批记录格式打印. 电子批记录包含如下几个部分: 1. ...
- 浅谈UART/12C/TTL的定义与区别与解析
UART/12C/TTL的定义与区别: UART:UART(Universal Asynchronous Receive Transmitter):也就是我们经常所说的串口,基本都用于调试.主机和从机 ...
- 番茄日志发布1.0.3版本-增加Kafka支持
番茄日志(TomatoLog)能做什么 可能你是第一次听说TomatoLog,没关系,我可以从头告诉你,通过了解番茄日志,希望能帮助有需要的朋友,番茄日志处理将大大降低你采集.分析.处理日志的过程. ...
- Homebrew 安装 Docker Desktop for Mac
无意中发现Homebrew现在已经支持Docker Desktop for Mac了,因此特意把原来通过 https://docs.docker.com/docker-for-mac/install/ ...
- ImageNet主要网络benchmark对比
深度神经网络繁多,各自的性能指标怎样? 实际应用中,在速度.内存.准确率等各种约束下,应该尝试哪些模型作为backbone? 有paper对各个网络模型进行了对比分析,形成了一个看待所有主要模型的完整 ...
- linux 如何初始化密码(解决mysql root用户登录不了的问题)
这是我遇到的问题 然后就想这可能是mysql安全模式的问题,解决思路:首先改变mysql的安全模式及密码校验问题,jinrumysql后在更改用户名密码. 1.首先将my.ini中加入在[mysqld ...
- Python之变量的创建过程
Python之变量的创建过程 一.变量创建过程 首先,当我们定义了一个变量name = 'Kwan'的时候,在内存中其实是做了这样一件事: 程序开辟了一块内存空间,将'Kwan'存储进去,再让变量名n ...
- 深度解密Go语言之 scheduler
目录 前置知识 os scheduler 线程切换 函数调用过程分析 goroutine 是怎么工作的 什么是 goroutine goroutine 和 thread 的区别 M:N 模型 什么是 ...
- [python]创建文本文件,并读取
代码如下: # coding=gbk import os fname = raw_input("Please input the file name: ") print if os ...
- 2019dx#4
Solved Pro.ID Title Ratio(Accepted / Submitted) 1001 AND Minimum Spanning Tree 31.75%(1018/3206) ...