为什么建立数据仓库需要使用ETL工具?
在做项目时是不是时常让客户有这样的困扰:
1、开发时间太长
2、花费太多
3、需要太多资源
4、集成多个事务系统数据总是需要大量人力成本
5、找不到合适的技能和经验的人
6、一旦建立,数据仓库无法足够迅速地应对变化
7、一直达不到客户的期望
8、业务人员很难获得数据仓库的数据
9、传统构建数据仓库费用极其可怕地保持运行后建立架构和设计不足,缺乏项目文档和团队支持
10、数据仓库有太多太复杂的工具和技术,不好分辨那个工具是实用的
11、构建数据仓库一直以来是一个高风险的任务
选择ETL工具的维度有很多都可以影响你的决策,如时间、成本、易用性、云能力、未来需求变化的应对能力等等。当有一个工具能够在同一时间解决这些困扰你的因素你会选择么?在寻找ETL工具之前其实更好的方式是总结数据仓库构建过程中真正导致失败的原因:
- 缺乏强有力的执行团队
- 不完整的企业级数据仓库体系结构和文档
- 缺乏数据仓库设计思维
- 执行团队未获知完整的需求
- 分析过程没有及时验证原型
- 企业级数据仓库数据库设计没有可扩展性和适应性
- 执行团队从来没有构建数据仓库
- 需求采集不懂业务
- 没有专业技术团队协同开发的工具
- 数据集成证明比预期的更困难
一个好的数据仓库解决方案可以给你节省大量时间和成本,易用性的工具可以让企业不在困扰没有足够强大的技术团队项目后期。你可能觉得在寻找一个能够轻松应对客户需求变化的ETL工具很困难,甚至可能没有这样的ETL工具可以解决这些问题。其实有技术平台可以做到,这个平台就是SEDWA高效数据仓库搭建平台。

SEDWA高效数据仓库搭建平台就是可以解决这些困扰的数据仓库解决方案,它是《数据仓库工具箱-维度建模权威指南》一书中提到的34个子系统的具体实践。它以其创新的设计和先进的功能,可以在最短时间快速构建和管理企业的数据。
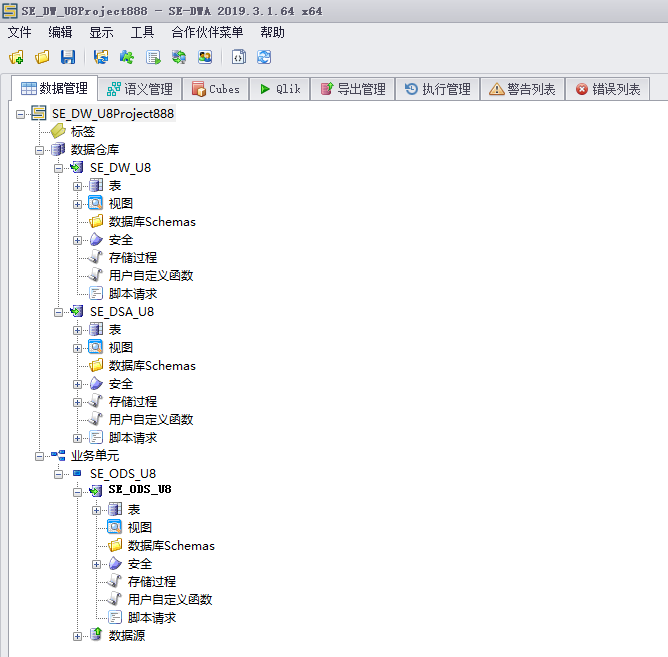
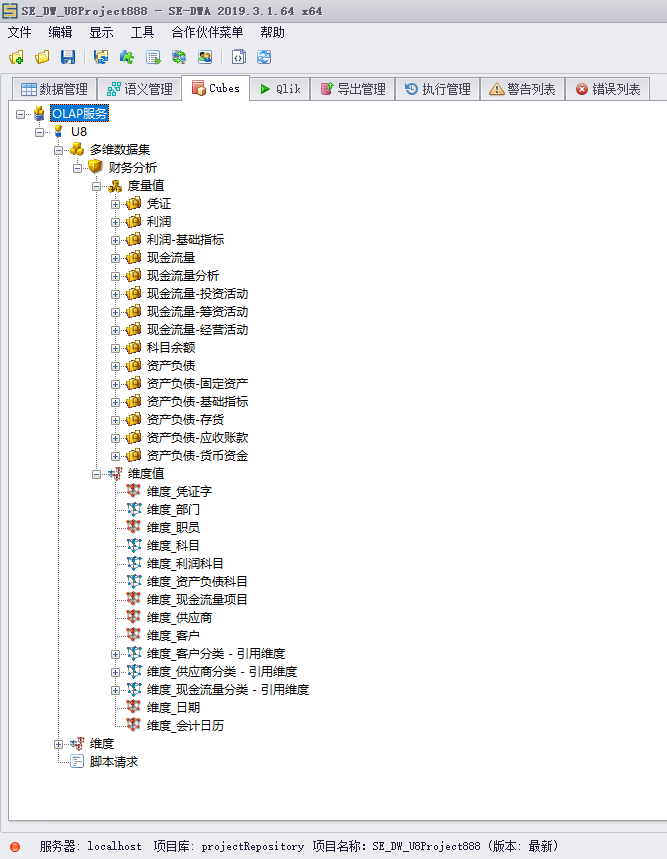
首先我们来看一下SEDWA独特的技术核心
SEDWA有众多的关键特性,这里我们先看一下其中三个主要组件:数据交换区,数据仓库和语义层。 这样分层数据架构可以让SEDWA轻松应对不同企业,更好的管理企业数据。
数据交换区作为数据管理中心,负责数据存储库管理和存储所有数据的流入和流出。 数据交换区连接所有的数据来源和收集数据不会进行清洗数据。 这允许连接日益增长和不断变化的数据来源。
数据仓库可以自由建模数据驻留在数据交换区,连同其他表的数据在本地使用,可以方便跨库取数。数据仓库可以清洗数据,保证数据质量。 这为核心优化数据分析。数据仓库还保存历史数据,进行历史数据记录的分析。
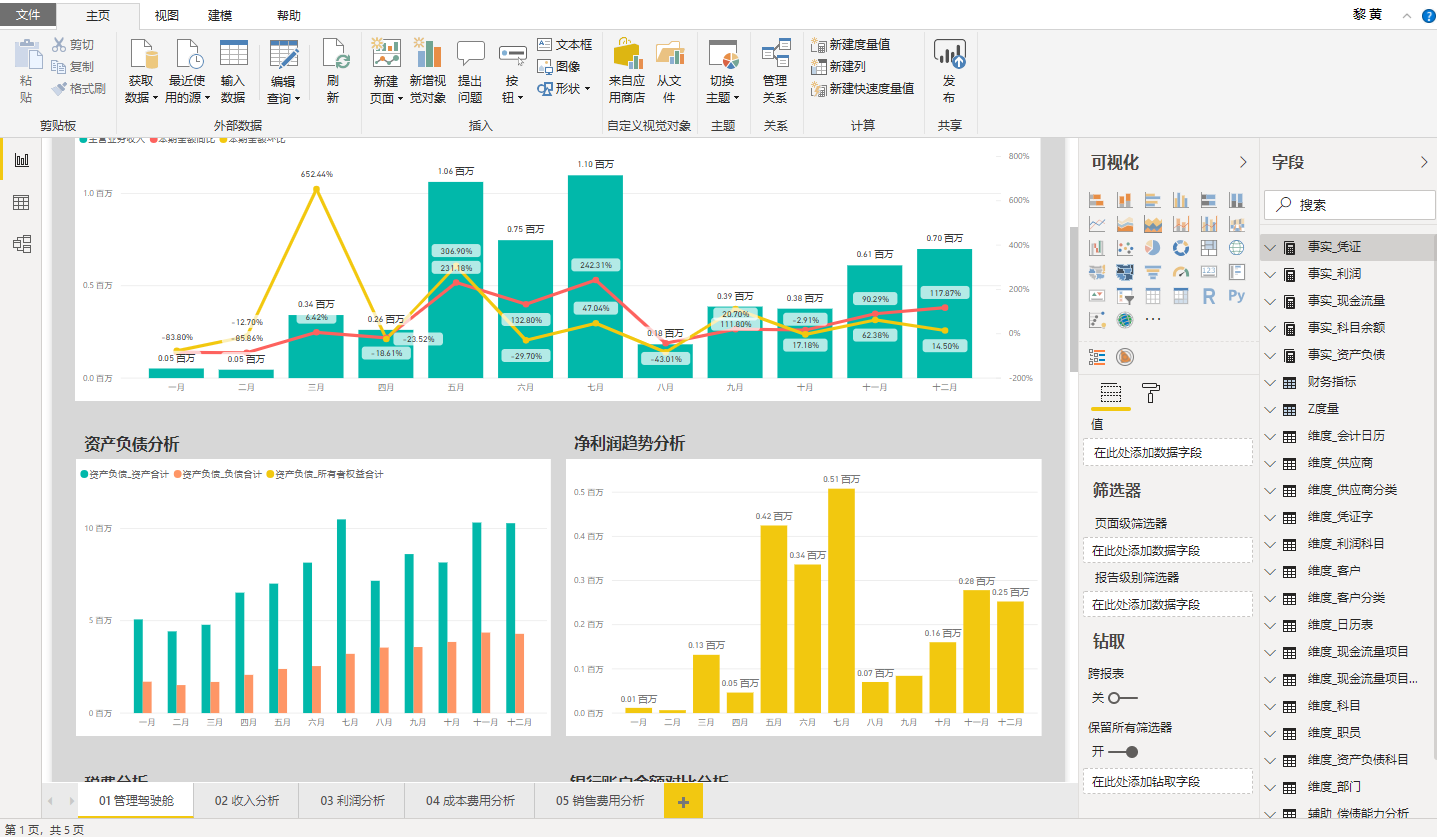
语义层建模提供简单的访问和控制相关的数据,提供给某个特定的部门或个人。 它转换数据后,业务用户可以很容易地理解和正确地解释数据。只需要定义一次语义转换的规则,然后就自动使用正确的形式和内容将数据传送到任何数据可视化工具,包括PowerBI、Tableau、Qlik等主流可视化工具。
SEDWA加快工作效率,从而节省成本!而其他工具需要大量时间手工处理工具和供应商数据集成、数据准备和文档,SEDWA是一个高效数据仓库搭建平台,利用高效数据处理节省大量的时间和金钱。让我们看一看数据仓库的主要成本。
下面列出的项目约占80%的原因,一直以来失败或超过预算或错过预定的目标。SEDWA可以轻松应对这些问题,并使实现和维护数据仓库成本降低80%,相比使用传统的数据仓库工具和技术。
1、数据仓库ETL开发包含多达70%的初始开发成本。SEDWA减少了时间来开发、测试和实施ETL高达80%。ETL的变化通常是非常耗时和昂贵的。 SEDWA允许ETL迅速而简易地进行更改。
2、SEDWA的更改数据库设计由于新的需求或范围变化是一个主要因素。 这有一个涟漪效应导致的变化,ETL、数据库和OLAP设计。采用传统的方法,这可能会导致延迟数周或数月。SEDWA任何变更只需要部署执行可以快速重新生成模型。
3、团队未能提供用户想要的东西。 这主要是由于使用传统方法所花费的时间为最终用户创建原型来验证。 SEDWA的原型和概念证明是快速、轻松地开发的。 终端用户和中软数据员工可以坐在开发一个原型在几分钟内。
4、发布新版本需要大量的时间和资源去迁移生产环境。 在这里,SEDWA,只需几次点击,差异化部署和版本控制轻松应对开发环境到测试环境,再过渡到生产环境。
5、使用传统方法保持历史数据仓库维度需要大量的开发和测试。 SEDWA可以这样做只需要点击几下。开启缓慢渐变功能,跟踪历史变化
6、大多数数据仓库缺乏全面、最新的文档。 这可能是一个严重的问题,当把新开发伙伴加入到项目。 中软数据的SEDWA提供完整的元数据字典,可以告诉你特定的数据从何而来,他的血统是什么和其他元素有什么关系。 每次修改或者添加了SEDWA数据仓库的元数据存储库更新,以反映数据仓库项目的具体状态。
大多数数据仓库项目期间没有设计维护数据仓库后期需求变更。 使用传统方法,改进和维护往往是巨大的成本。数据仓库使用技术来获得效率和改善数据仓库流程的有效性。 高效的数据仓库不仅仅是单纯的开发过程简单,易用。 它包含所有的数据仓库的核心过程,包括设计、开发、测试、部署、操作、影响分析、变更管理。SEDWA高效数据仓库搭建平台一切为时间服务!
想要了解更多请访问:中软数据官网
欢迎加入PowerBI高效数据处理ETL交流群:684598807
为什么建立数据仓库需要使用ETL工具?的更多相关文章
- 六种 主流ETL 工具的比较(DataPipeline,Kettle,Talend,Informatica,Datax ,Oracle Goldengate)
六种 主流ETL 工具的比较(DataPipeline,Kettle,Talend,Informatica,Datax ,Oracle Goldengate) 比较维度\产品 DataPipeline ...
- 数据仓库系列之ETL过程和ETL工具
上周因为在处理很多数据源集成的事情一直没有更新系列文章,在这周后开始规律更新.在维度建模中我们已经了解数据仓库中的维度建模方法以及基本要素,在这篇文章中我们将学习了解数据仓库的ETL过程以及实用的ET ...
- Dynamics AX 2012 在BI分析中建立数据仓库的必要性
AX系统已有的BI分析架构 对于AX 的BI分析架构,相信大家都了解,可以看Reinhard之前的译文[译]Dynamics AX 2012 R2 BI系列-分析的架构 . AX 的BI分析架构的优势 ...
- 基于两种架构的ETL实现及ETL工具选型策略
企业信息化建设过程中,业务系统各自为政.相互独立造成的"数据孤岛"现象尤为普遍,业务不集成.流程不互通.数据不共享--.这给企业进行数据的分析利用.报表开发等带来了巨大困难.在此情 ...
- 集团公司(嵌入ETL工具)财务报表系统解决方案
集团公司(嵌入ETL工具)财务报表系统解决方案 一.项目背景: 某集团公司是一家拥有100多家子公司的大型集团公司,旗下子公司涉及各行各业,包括:金矿.铜矿.房产.化纤等.由于子公司在业务上的差异,子 ...
- 开源ETL工具之Kettle介绍
What 起源 Kettle是一个Java编写的ETL工具,主作者是Matt Casters,2003年就开始了这个项目,最新稳定版为7.1. 2005年12月,Kettle从2.1版本开始进入了开源 ...
- Kettle实现数据抽取、转换、装入和加载数据-数据转移ETL工具
原文地址:http://www.xue51.com/soft/5341.html Kettle是来自国外的一款开源的ETL工具,纯java编写,可以在Window.Linux.Unix上运行,绿色无需 ...
- 【转】ETL介绍与ETL工具比较
本文转载自:http://blog.csdn.net/u013412535/article/details/43462537 ETL,是英文 Extract-Transform-Load 的缩写,用来 ...
- 【转】阿里出品的ETL工具dataX初体验
原文链接:https://www.imooc.com/article/15640 来源:慕课网 我的毕设选择了大数据方向的题目.大数据的第一步就是要拿到足够的数据源.现实情况中我们需要的数据源分布在不 ...
随机推荐
- HDU 5775:Bubble Sort(树状数组)
http://acm.hdu.edu.cn/showproblem.php?pid=5775 Bubble Sort Problem Description P is a permutation ...
- django基础知识之ORM简介:
ORM简介 MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库 ORM是“对象-关系-映射”的简称 ...
- Profibus 接线
无论是组成MPI还是RPOFIBUS-DP网络,用到的主要部件都是一样的: PROFIBUS电缆:电缆型号有多种,其中最基本的是PROFIBUS FC(Fast Connect快速连接)Standar ...
- scala刷LeetCode--26 删除排序数组中的重复项
一.题目描述 给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度. 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完 ...
- 19.linux文件属性
1.linux文件属性 ls -lih i查看文件inode,h查看文件大小 文件总共10个属性 inode索引节点编号(唯一的) 文件类型和权限,第一个字符为类型,后面字符为权限 硬链接的数量 文件 ...
- 关系型数据库MySql简介
什么是关系型数据库? 数据库就是用来存储数据的仓库,是一种特殊的文件. 根据存储的数据不同,划分为关系型数据库和非关系型数据库. 关系型数据库就是指 建立在关系模型基础上的数据库,通俗来讲这种数据库就 ...
- shell_链接命令ln与nohup命令使用方法
ln命令是一个链接命令,工作中用的比较多的就是对一个文件或者是目录建立起软连接.软连接的概念类似于windows下的快捷方式.比如,在win下,我们经常在安装完word.ppt等office程序后,在 ...
- thread学习笔记--BackgroundWorker 类
背景: 在 WinForms 中,有时要执行耗时的操作,比如统计某个磁盘分区的文件夹或者文件数目,如果分区很大或者文件过多的话,处理不好就会造成“假死”的情况,或者报“线程间操作无效”的异常,或者在该 ...
- Leetcode solution 291: Word Pattern II
Problem Statement Given a pattern and a string str, find if str follows the same pattern. Here follo ...
- Excel催化剂开源第42波-与金融大数据TuShare对接实现零门槛零代码获取数据
在金融大数据功能中,使用了TuShare的数据接口,其所有接口都采用WebAPI的方式提供,本来还在纠结着应该搬那些数据接口给用户使用,后来发现,所有数据接口都有其通用性,结合Excel灵活友好的输入 ...