大数据学习笔记——Hbase高可用+完全分布式完整部署教程
Hbase高可用+完全分布式完整部署教程
本篇博客承接上一篇sqoop的部署教程,将会详细介绍完全分布式并且是高可用模式下的Hbase的部署流程,废话不多说,我们直接开始!
1. 安装准备
部署Hbase时,我们使用的版本为1.2.8

2. 正式安装
1. 将hbase-1.2.8-bin.tar.gz文件使用远程传输软件放到s101的/home/centos/downloads下
2. 将hbase-1.2.8-bin.tar.gz解压缩至/soft下
tar -xzvf /home/centos/downloads/hbase-1.2.8-bin.tar.gz -C /soft
3. 进入/soft目录,建立hbase的符号链接
cd /soft
ln -s hbase-1.2.8 hbase
4. 修改并生效环境变量
nano /etc/profile
在文件末尾添加以下代码:
#hbase环境变量
export HBASE_HOME=/soft/hbase
export PATH=$PATH:$HBASE_HOME/bin
生效环境变量后保存退出
source /etc/profile
5. 分发hbase以及hbase的符号链接到其他所有的节点
xsync.sh /soft/hbase-1.2.8
然后在其他每个节点上输入命令:
cd /soft
ln -s hbase-1.2.8 hbase
6. 同步环境变量
xsync.sh /etc/profile
然后在每个节点上生效环境变量:
xcall.sh source /etc/profile
7. 先只在s101节点上修改配置文件regionservers,类似于部署Hadoop时修改的slaves文件
nano /soft/hbase/conf/regionservers
添加以下代码:
s102
s103
s104
8. 在s101上修改配置文件hbase-env.sh
nano /soft/hbase/conf/hbase-env.sh
因为HBase自带的就有zookeeper,因此我们需要将下面这个设置成false,从而可以使用我们自己的zookeeper配置
修改:export HBASE_MANAGES_ZK=false
export JAVA_HOME=/soft/jdk
9. 在s101上修改配置文件hbase-site.xml
nano /soft/hbase/conf/hbase-site.xml
添加以下配置即可:
<configuration>
<!-- 启动hbase分布式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- hbase工作目录 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/user/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/centos/zk</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>s102:2181,s103:2181,s104:2181</value>
</property>
</configuration>
10. 在s101上将hadoop配置文件core-site.xml和hdfs-site.xml放置在/soft/hbase/conf下
cp /soft/hadoop/etc/hadoop/core-site.xml /soft/hbase/conf/
cp /soft/hadoop/etc/hadoop/hdfs-site.xml /soft/hbase/conf/
11. s101上的配置文件均已配置完毕,现在进行同步
xsync.sh /soft/hbase/conf/
12. 高可用配置:在/soft/hbase/conf/下添加backup-masters文件
nano /soft/hbase/conf/backup-masters
添加:s105
13. 全部配置完毕,启动hbase
由于hbase是架构在HDFS文件系统上的,因此需要先启动zookeeper和HDFS
xzk.sh start
start-dfs.sh
最后再启动hbase:
start-hbase.sh
14. 验证启动是否成功
hbase version,出现下面的画面:

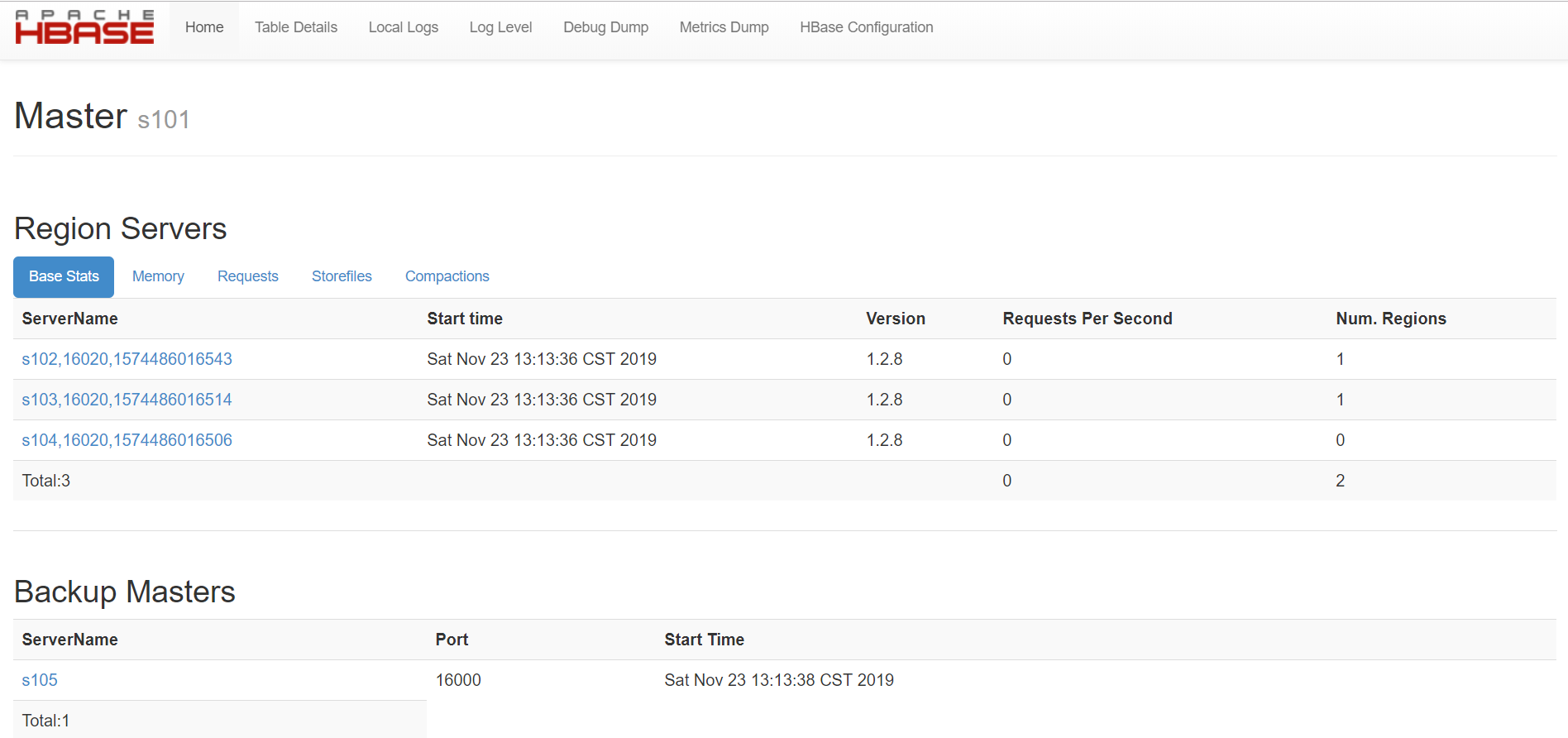
查看WebUI:s101:16010,发现Master和备份Master还有Region Servers都已经启动,配置大功告成!!!
大数据学习笔记——Hbase高可用+完全分布式完整部署教程的更多相关文章
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- 大数据学习笔记——HBase使用bulkload导入数据
HBase使用bulkload批量导入数据 HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此本篇博客将会整理提高批量导 ...
- 大数据Hadoop的HA高可用架构集群部署
1 概述 在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持N ...
- spring cloud(学习笔记)高可用注册中心(Eureka)的实现(二)
绪论 前几天我用一种方式实现了spring cloud的高可用,达到两个注册中心,详情见spring cloud(学习笔记)高可用注册中心(Eureka)的实现(一),今天我意外发现,注册中心可以无限 ...
- hbase学习(二)hbase单机和高可用完全分布式安装部署
hbase版本 2.0.4 与hadoop兼容表http://hbase.apache.org/book.html#hadoop 我的 hadoop版本是3.1 1.单机版hbase 1.1解 ...
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习笔记——Linux基本知识及指令(理论部分)
Linux学习笔记整理 上一篇博客中,我们详细地整理了如何从0部署一套Linux操作系统,那么这一篇就承接上篇文章,我们仔细地把Linux的一些基础知识以及常用指令(包括一小部分高级命令)做一个梳理, ...
随机推荐
- nyoj 16-矩形嵌套(贪心 + 动态规划DP)
16-矩形嵌套 内存限制:64MB 时间限制:3000ms Special Judge: No accepted:13 submit:28 题目描述: 有n个矩形,每个矩形可以用a,b来描述,表示长和 ...
- rsync同步基本用法
...
- 力扣(LeetCode)移除链表元素 个人题解
删除链表中等于给定值 val 的所有节点. 这题粗看并不困难,链表的特性让移除元素特别轻松,只用遇到和val相同的就跳过,将指针指向下一个,以此类推. 但是,一个比较麻烦的问题是,当链表所有元素都和v ...
- A Lot of Games(Trie树 + 博弈)
题目链接:http://codeforces.com/contest/455/problem/B 题意:n, k 分别表示 字符串组数 和 比赛次数. 从一个空单词开始, a,b二人分别轮流往单词后 ...
- 在lldb调试中调用c++函数
在lldb调试时,调用oc对象的方法不足为奇,因为msgSend是有原型导出的,oc对象的方法都运行期绑定的,绑定信息都在objc_class中.只要在调试中[receiver sel]之类,lldb ...
- GitHub注册失败,卡在第一步
同事说他无法注册GitHub,我一开始以为GitHub又无法登录进去,我就登录了自己的GitHub账号,没有问题,可以登录啊,见第一个标签页.同一局域网,不可能我能登录,你无法完成注册啊.于是,我就在 ...
- GitHub远程库的搭建以及使用
GitHub远程库的搭建 一).配置SSH 步骤: 1).注册GitHub账号 2).本地git仓库与远程的GitHub仓库的传输要通过SSH进行加密 3).创建SSH key 1.检查在用户主目 ...
- Java并发之volatile关键字
引言 说到多线程,我觉得我们最重要的是要理解一个临界区概念. 举个例子,一个班上1个女孩子(临界区),49个男孩子(线程),男孩子的目标就是这一个女孩子,就是会有竞争关系(线程安全问题).推广到实际场 ...
- 万恶之源-python基本数据类型
万恶之源-基本数据类型(dict) 本节主要内容: 字典的简单介绍 字典增删改查和其他操作 3. 字典的嵌套 ⼀一. 字典的简单介绍 字典(dict)是python中唯⼀一的⼀一个映射类型.他是以{ ...
- 在React旧项目中安装并使用TypeScript的实践
前言 本篇文章默认您大概了解什么是TypeScript,主要讲解如何在React旧项目中安装并使用TypeScript. 写这个的目的主要是网上关于TypeScript这块的讲解虽然很多,但都是一些语 ...