Python学习日记(五) 编码基础
初始编码
ASCII最开始为7位,一共128字符。最后确定8位,一共256个字符,最左边的为拓展位,为以后的开发做准备。
ASCII码的最左边的一位为0。
基本换算:8位(bit) = 1字节(byte)
1024byte = 1 KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
电脑的传输还有存储实际上都是以二进制的形式进行的。
Unicode:美国最初是使用ASCII编码,后来为了解决全球化的文字问题,创建了万国码(Unicode)
开端:
一个中文最初给两个字节(16位)来表示,后来发现中文就将近十万字,不够,所以之后Unicode用4个字节(32位)来表示一个中文。
一个英文给四个字节(32位)来表示。
升级后:
UTF-8:
一个中文用3个字节(24位)表示
一个英文用1个字节(8位)表示
一个欧洲文字用2个字节(16位)表示
国内使用编码:
GBK:
一个中文用2个字节(16位)表示
一个英文用1个字节(8位)表示
(1)各个编码之间的二进制是不能互相是别的,会产生乱码
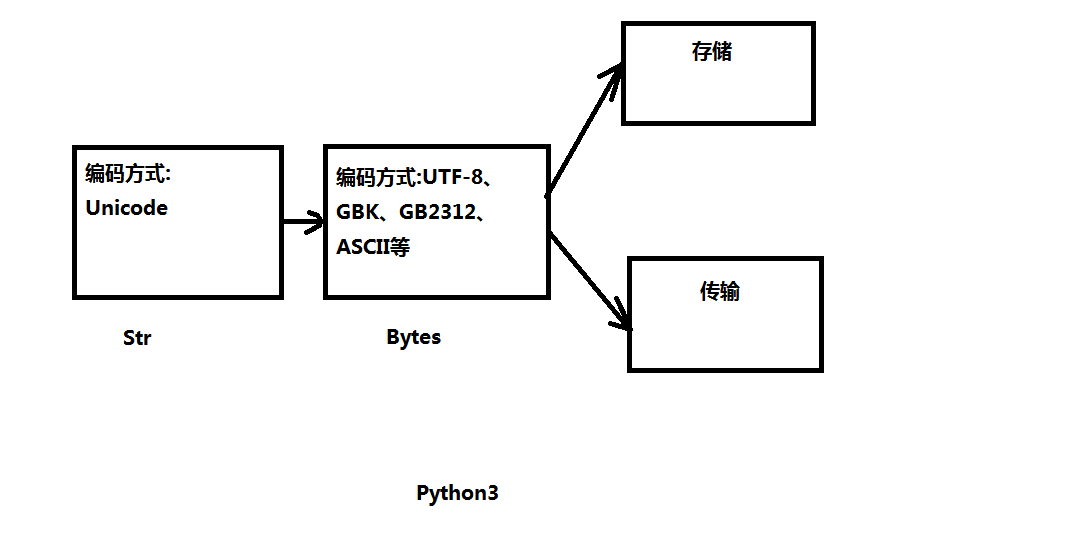
(2)Unicode 的字符要用4个字节(32位)来表示,占用了太多内存。因此文件的储存、传输不能是Unicode类型,只能是UTF-8、UTF-16、GBK、GB2312、ASCII等类型
UTF-8和GBK的转变要借助Unicode
(3)在Python3中str在内存中是用Unicode存储的
而bytes类型是以(UTF-8、GB2312等编码)
对于英文:
str的表现形式:
s = 'abc'
str的编码方式:
以Unicode的01010101形式
bytes的表现形式:
b_s = b'abc'
bytes的编码方式:
以UTF-8、GBK等的01010101形式
对于中文:
str的表现形式:
s = '中国'
str的编码方式:
以Unicode的01010101形式
bytes的表现形式:
以UTF-8的b'\xe4\xb8\xad\xe5\x9b\xbd'形式
bytes的编码方式:
以UTF-8、GBK等的01010101形式
编码(将str->bytes):
中文:
s1= '中国'
s2 = s1.encode('utf-8')
print(s2) #b'\xe4\xb8\xad\xe5\x9b\xbd'
s2 = s1.encode('gbk')
print(s2) #b'\xd6\xd0\xb9\xfa'
英文:
s1 = 'abc'
s2 = s1.encode('utf-8')
print(s2) #b'abc'
s2 = s1.encode('gbk')
print(s2) #b'abc'
解码(将bytes->str):
b = b'\xe4\xb8\xad\xe5\x9b\xbd'
s = b.decode('utf-8')
print(s) #中国
b = b'abc'
s = b.decode('utf-8')
print(s) #abc
其他:
1.Python2和Python3的区别:
Python2 Python3
<1>.print 可以加括号,也可以不加括号
print('abc') print('abc')
print 'abc'
<2>.xrange()生成器 range()
range()
<3>.raw_input() input()
2.
= 是赋值
is 是比较内存地址
== 比较值是否相等
id(内容)
3.小数据池
在Python中数字和字符串存在着小数据池,它的作用是在一个数据范围内节省内存空间,共用一个内存地址
list、dict、set、tuple没有小数据池这一概念
int:
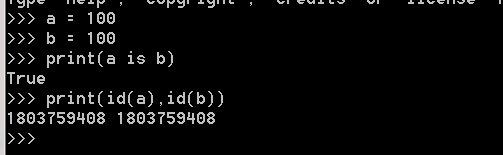
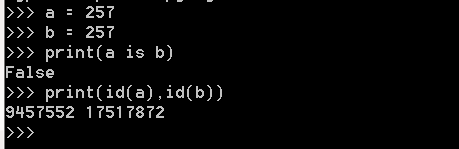
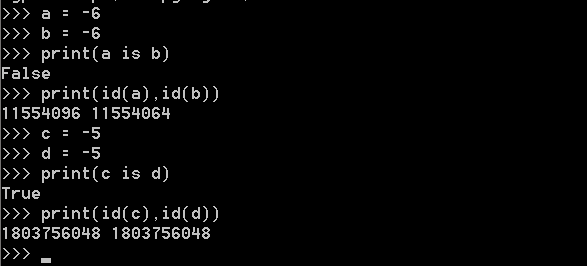
只要数值在范围(-5 - 256),它们都共用一个相同的内存地址
例1:
例2:
例3:
str:
<1>.当字符串长度为0或1时默认使用小数据池,当长度大于1时且没有含有特殊字符(包括加减乘除)时也将使用小数据池


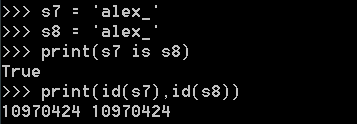
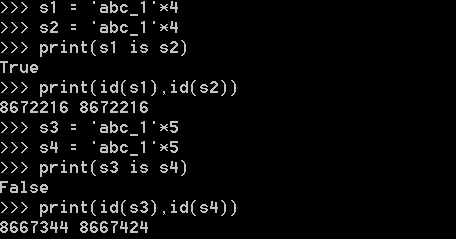
<2>.一个字符串长度小于等于20用的还是同一个内存地址,长度大于20以后用的是2个内存地址
当乘数为1时:
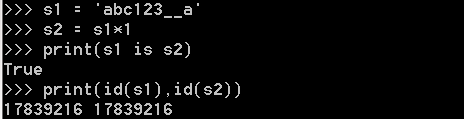
仅含字符串、数字、下划线,默认使用小数据池:
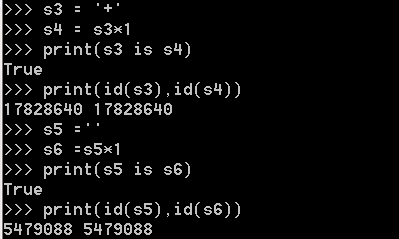
含其他字符,长度<=1时,默认使用小数据池
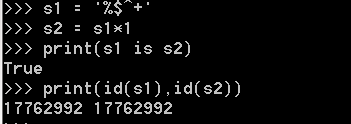
含其他字符,长度>1时,默认使用小数据池
当乘数大于1时:
字符长度小于等于20将使用小数据池
Python学习日记(五) 编码基础的更多相关文章
- python学习日记(编码再回顾)
当想从一种编码方式转换为另一种编码方式时,执行的就是以上步骤. 在python3里面,默认编码方式是unicode,所以无需解码(decode),直接编码(encode)成你想要的编码方式就可以了. ...
- python学习日记(基础数据类型及其方法01)
数字 int 主要是用于计算的,常用的方法有一种 #既十进制数值用二进制表示时,最少使用的位数i = 3#3的ASCII为:0000 0011,即两位 s = i.bit_length() print ...
- python学习之路-day2-pyth基础2
一. 模块初识 Python的强大之处在于他有非常丰富和强大的标准库和第三方库,第三方库存放位置:site-packages sys模块简介 导入模块 import sys 3 sys模 ...
- Python 学习日记(第三周)
知识回顾 在上一周的学习里,我学习了一些学习Python的基础知识下面先简短的回顾一些: 1Python的版本和和安装 Python的版本主要有2.x和3.x两个版本这两个版本在语法等方面有一定的区别 ...
- Python学习一:序列基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7858473.html 邮箱:moyi@moyib ...
- Python学习日记 --day2
Python学习日记 --day2 1.格式化输出:% s d (%为占位符 s为字符串类型 d为数字类型) name = input('请输入姓名') age = int(input('请输入年龄 ...
- Python学习二:词典基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7862377.html 邮箱:moyi@moyib ...
- python学习第五次笔记
python学习第五次笔记 列表的缺点 1.列表可以存储大量的数据类型,但是如果数据量大的话,他的查询速度比较慢. 2.列表只能按照顺序存储,数据与数据之间关联性不强 数据类型划分 数据类型:可变数据 ...
- Python学习第五堂课
Python学习第五堂课推荐电影:华尔街之狼 被拯救的姜哥 阿甘正传 辛德勒的名单 肖申克的救赎 上帝之城 焦土之城 绝美之城 #上节内容: 变量 if else 注释 # ""& ...
随机推荐
- [转]Vue CLI 3搭建vue+vuex 最全分析
原文地址:https://my.oschina.net/wangnian/blog/2051369 一.介绍 Vue CLI 是一个基于 Vue.js 进行快速开发的完整系统.有三个组件: CLI:@ ...
- 【tensorflow基础】TensorFlow查看GPU信息
re 1. TensorFlow查看GPU信息; end
- InfluxDB入门
InfluxDB是一个用于存储和分析时间序列数据的开源数据库 时序数据是基于时间的一系列的数据 时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入.持久化.多纬度的聚合查询等基本功能 ...
- TortoiseGit,git 未能顺利结束 (退出码 1)
其中一个原因是不能把Git下所有文件全部删除,一个都没有,就会报这个错误. 注:空文件夹git定义为空,不是文件.所以只有空文件夹也会报这个错误.
- 【计算机视觉】PASCAL VOC数据集分析
PASCAL VOC数据集分析 PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge. 本文主要分析PASCAL V ...
- 【剑指offer】面试题 19. 正则表达式匹配
面试题 19. 正则表达式匹配
- Active Objects模式
实现的思路是,通过代理将方法的调用转变为向阻塞队列中添加一个请求,由一个线程取出请求后执行实际的方法,然后将结果设置到Future中 这里用到了代理模式,Future模式 /************* ...
- Prometheus入门到放弃(7)之redis_exporter部署
redis监控,prometheus需要使用redis_exporter客户端. 这里我们采用docker方式部署,既可以部署在redis所在服务器,也可以部署在其他机器: docker镜像地址:ht ...
- 『Go基础』第5节 第一个Go程序
本节我们来学习写一个最简单的Go程序: 打印 Hello Go. 第一个Go程序, 只要跟着做, 留下个印象就可以. 用Goland创建一个 hello_go.go 文件(后缀为 .go ). 文件内 ...
- Modelsim——do脚本、bat命令
一.do脚本实现自动化仿真 Modelsim是支持命令的,我们可以用 .do 文件将这些命令先写好然后在Modelsim上调用.因为我的编辑器不支持.do的语法,所以这里改用 .tcl文件,它和 .d ...