Python之特征工程-3
一、什么是特征工程?其实也是数据处理的一种方式,和前面的原始数据不一样的是,我们在原始数据的基础上面,通过提取有效特征,来预测目标值。而想要更好的去得出结果,包括前面使用的数据处理中数据特征提取,新增减少等手段都是特征功能的一种,这里为什么要单独提出来讲特征工程,而不是数据处理呢?
二、数据处理的方式有很多种方式,合并等。这里讲特征工程主要是讲转换器,为啥这样说呢,因为我们在使用数据的时候,比如:文本,那我们通过文本的方式去计算,这个方式不利于数学公式的发挥。那么问题来了,想要更好的使数据达到预测的效果,那数据的转换是很有必要的。
简单理解就是:将原本比如文本型的数据,进行中文分词过后,在将文本变换成数字,具体为一个二维的矩阵数据。
三、fit、transform、fit_transform
1)在转换其中存在三个函数分别为fit、transform、fit_transform,翻译为:学习,转换,学习和转换
2)fit中存在两个参数:X,y:即特征值,目标值。只传X,即为无监督学习。X,y都传,即监督学习(有意识的去靠近目标)
3)transform,按照学习后的方式,进行其他数据的学习。有点像吧学习好的方式,套用到其他数据集得出结果。
4)fit_transform,两种方式的结合。
四、转换器
1)字典(JSON)转换器
from sklearn.feature_extraction import DictVectorizer # 字典特征提取
def dict_data():
# sparse=False:one-hot, True:矩阵
dict = DictVectorizer(sparse=True)
data = dict.fit_transform([{"city": "四川", "temperature": 20}, {"city": "北京", "temperature": 30}])
# 转换成矩阵
print(data.toarray())
# 特征名称
print(dict.get_feature_names())
# 逆向转换成字典
print(dict.inverse_transform(X=data))
结果:

说明:可以看出,特征名称,是将不是数据的类型分开,通过0表示没有,1表示存在的方式形成矩阵数据
2)文本特征提取转换器
import jieba
from sklearn.feature_extraction.text import CountVectorizer # 文本特征提取
def count_data():
cv = CountVectorizer()
# data = cv.fit_transform(["I love you", "I like you"])
# data = cv.fit_transform(["人生 苦短 我 喜欢 Python", "人生 漫长 我 讨厌 Python"])
# 中文文字分词
data = cv.fit_transform([' '.join(jieba.cut("人生苦短,我喜欢Python")), ' '.join(jieba.cut("人生漫长,我讨厌Python"))])
print(data.toarray())
print(cv.get_feature_names())if __name__ == '__main__':
count_data()
结果:

说明:文本特征提取的方式一般是通过中文分词的方式来处理的,因为英文默认是分开的所以好处理,但是中文需要分词器来处理。结果也是用0,1表示数据在样本中的数量。
3)tf_idf(term frequency and inverse document frequency)词的频率和逆文档频率。(逆文档频率公式:log(总文档数量/改词频率))
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer # term frequency(词出现的频率) and inverse document frequency(log(总文档数量/改词频率))
def tf_idf_data():
cv = TfidfVectorizer()
# data = cv.fit_transform(["I love you", "I like you"])
# data = cv.fit_transform(["人生 苦短 我 喜欢 Python", "人生 漫长 我 讨厌 Python"])
data = cv.fit_transform([' '.join(jieba.cut("人生苦短,我喜欢Python")), ' '.join(jieba.cut("人生漫长,我讨厌Python"))])
print(data.toarray())
# 特征名称
print(cv.get_feature_names())
结果:

说明:单文字不做计算,他是通过文章中出现的词的频率越少,确认他的权重越高。tf-idf具体计算过程可以参考:https://baike.baidu.com/item/tf-idf/8816134?fr=aladdin
4)归一化
a、公式:
x - min
x' = —————————
max - min x" = x'(mx - mi) + mi
(default mx = 1, mi = 0)
mi, mx为区间,min, max为一中特征总的最小最大值。x为实际值,x"为最终结果
b、代码实现
from sklearn.preprocessing import MinMaxScaler # 归一化
def normalize_data():
"""
数据:
30 10 20
70 30 50
110 50 35
公式:
x - min
x' = —————————
max - min x" = x'(mx - mi) + mi
(default mx = 1, mi = 0)
mi, mx为区间,min, max为一中特征总的最小最大值。x为实际值,x"为最终结果
"""
# feature_range指数据区间默认(0, 1)
mms = MinMaxScaler(feature_range=(2, 3))
data = mms.fit_transform([[30, 10, 20], [70, 30, 50], [110, 50, 35]])
print(data)
c、结果:
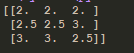
d、说明:归一化的目的是将数据,按照比例的方式缩小,以减少,由于某个特征值,特别大引起权重的变化。
e、缺点:容易受到单个特征值的影响,在公式中x'为计算结果,如果max是异常点很大,那么其他数据结果,值就会特别小。会让数据的权重值下降。所以一般不采用这种方式。
5)标准化
a、公式
方差:
(x1 - avg)^2 + (x2 - avg)^2 + ...
var = —————————————————————————————————
n
标准差:
___
a = √var
x - avg
x' = ————————
a
avg为平均值,x'为最终结果
b、代码实现
from sklearn.preprocessing import StandardScaler # 标准化
def standard_data():
"""
公式:
方差:
(x1 - avg)^2 + (x2 - avg)^2 + ...
var = —————————————————————————————————
n
标准差:
___
a = √var
x - avg
x' = ————————
a
avg为平均值,x'为最终结果
"""
ss = StandardScaler()
data = ss.fit_transform([[30, 10, 20], [70, 30, 50], [110, 50, 35]])
print(data)
c、结果

d、说明:数据标准化会受到单个异常点的影响,但是影响不大。这种方式得出的结果,针对于数据来说比较平均,是比较常见的一种方式。标准化的目的也是为了减少实际数据中特征值的影响。当特征都区域统一权重状态。
6)降维(PCA,又称主成分分析)
a、方式:通过计算获取特征值结果,如果一个特征中的数据差异很小,就可以降维(即删除此特征)。保留有用的特征数据。
b、代码实现
import pandas
from sklearn.decomposition import PCA # 降维
def dimensionality_reduction():
# 读取数据
orders = pandas.read_csv("market/orders.csv")
prior = pandas.read_csv("market/order_products__prior.csv")
products = pandas.read_csv("market/products.csv")
aisles = pandas.read_csv("market/aisles.csv")
# 合并数据
_msg = pandas.merge(orders, prior, on=["order_id", "order_id"])
_msg = pandas.merge(_msg, products, on=["product_id", "product_id"])
merge_data = pandas.merge(_msg, aisles, on=["aisle_id", "aisle_id"])
# 交叉表(特殊分组)
# (用户ID, 类别)
cross = pandas.crosstab(merge_data["user_id"], merge_data["aisle"])
print(cross.shape)
# 降维
pca = PCA(n_components=0.9)
data = pca.fit_transform(cross)
# 查看数据量和结果
print(data.shape)
说明:n_components为数据保留率一般(90%~95%)
c、结果:
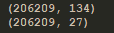
d、解释:这里的134为原始数据的特征数量,27为降维过后的特征数量,从计算上面来看,已经达到效果了。
Python之特征工程-3的更多相关文章
- Python机器学习笔记 使用sklearn做特征工程和数据挖掘
特征处理是特征工程的核心部分,特征工程是数据分析中最耗时间和精力的一部分工作,它不像算法和模型那样式确定的步骤,更多的是工程上的经验和权衡,因此没有统一的方法,但是sklearn提供了较为完整的特征处 ...
- 如何用Python做自动化特征工程
机器学习的模型训练越来越自动化,但特征工程还是一个漫长的手动过程,依赖于专业的领域知识,直觉和数据处理.而特征选取恰恰是机器学习重要的先期步骤,虽然不如模型训练那样能产生直接可用的结果.本文作者将使用 ...
- 手把手教你用Python实现自动特征工程
任何参与过机器学习比赛的人,都能深深体会特征工程在构建机器学习模型中的重要性,它决定了你在比赛排行榜中的位置. 特征工程具有强大的潜力,但是手动操作是个缓慢且艰巨的过程.Prateek Joshi,是 ...
- python 机器学习(一)机器学习概述与特征工程
一.机器学习概述 1.1.什么是机器学习? 机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测 1.2.为什么需要机器学习? 解放生产力,智能客服,可以不知疲倦的24小时作业 ...
- 2022年Python顶级自动化特征工程框架⛵
作者:韩信子@ShowMeAI 机器学习实战系列:https://www.showmeai.tech/tutorials/41 本文地址:https://www.showmeai.tech/artic ...
- python 机器学习库 —— featuretools(自动特征工程)
文档:https://docs.featuretools.com/#minute-quick-start 所谓自动特征工程,即是将人工特征工程的过程自动化.以 featuretools 为代表的自动特 ...
- 【Python数据挖掘】第六篇--特征工程
一.Standardization 方法一:StandardScaler from sklearn.preprocessing import StandardScaler sds = Standard ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- AI学习---特征工程【特征抽取、特征预处理、特征降维】
学习框架 特征工程(Feature Engineering) 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已 什么是特征工程: 帮助我们使得算法性能更好发挥性能而已 sklearn主 ...
随机推荐
- h2的时间类型和函数
H2时间类型: (时间)TIME: 格式为 hh:mm:ss.对应到Java类型:java.sql.Time. (日期)DATE: 格式为 yyyy-MM-dd.对应到Java类型: java.sql ...
- 产品经理 写SQL
产品经理必备技能:写SQL - 云+社区 - 腾讯云https://cloud.tencent.com/developer/news/3177 产品经理学SQL(一)一个小时上手SQL | 人人都是产 ...
- vim卡死
使用vim时,如果你不小心按了 Ctrl + s后,你会发现不能输入任何东西了,像死掉了一般,其实vim并没有死掉,这时vim只是停止向终端输出而已,要想退出这种状态,只需按Ctrl + q 即可恢复 ...
- python链接mysql pymysql
python链接mysql import pymysql conn = pymysql.connect(user=', database='gbt2019', charset='utf8') curs ...
- invalid application of ‘sizeof’ to incomplete type
sizeof 后面所跟的数据类型没有定义,或者找不到定义的地方 eg: 头文件中定义结构体如下: struct PersonaL{ char name[]; int age; }; 但是在cpp中使 ...
- nginx通过robots.txt禁止所有蜘蛛访问(禁止搜索引擎收录)
在server {} 块中添加下面的配置 location =/robots.txt { default_type text/html; add_header Content-Type "t ...
- windows10 环境下的RabbitMQ安装步骤(图文)
第一步:下载并安装erlang 原因:RabbitMQ服务端代码是使用并发式语言Erlang编写的,安装Rabbit MQ的前提是安装Erlang. 下载地址:http://www.erlang.or ...
- easyui datagrid 让某行复选框置灰不能选
easyui中datagrid 让某行复选框置灰不能进行选中操作,以下为主要部分的code. //加载完毕后获取所有的checkbox遍历 onLoadSuccess: function(data){ ...
- 常见问题:MySQL/索引
普通索引 最常用,没有任何限制. 唯一索引 必须唯一,但允许空值,如果是组合索引,列值的组合必须唯一. 组合索引 由于MySQL查询时,只能使用一个索引,因此建立组合索引在组合查询的场景下更加有效.组 ...
- oracle 存储过程详细介绍(创建,删除存储过程,参数传递等)
这篇文章主要介绍了oracle 创建,删除存储过程,参数传递,创建,删除存储函数,存储过程和函数的查看,包,系统包等相关资料,需要的朋友可以参考下 oracle 创建,删除存储过程,参数传递,创建 ...