Flink入门介绍
什么是Flink
Apache Flink是一个分布式大数据处理引擎,可以对有限数据流和无限数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
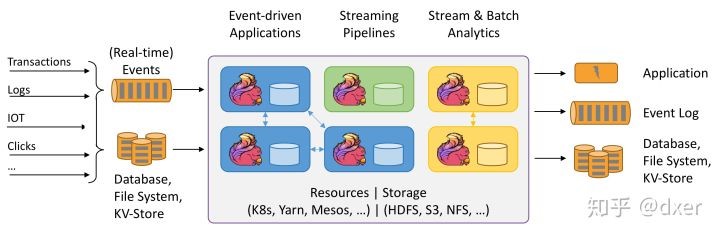
Flink特性
- 支持高吞吐、低延迟、高性能的流式数据处理,而不是用批处理模拟流式处理。
- 支持多种时间窗口,如事件时间窗口、处理时间窗口
- 支持exactly-once语义
- 具有轻量级容错机制
- 同时支持批处理和流处理
- 在JVM层实现内存优化与管理
- 支持迭代计算
- 支持程序自动优化
- 不仅提供流式处理API,批处理API,还提供了基于这两层API的高层的数据处理库
Flink体系架构
Flink运行时主要由JobManager和TaskManager两个组件组成,Flink架构也遵循主从架构设计原则,JobManager为Master节点,TaskManager为Worker节点。所有组件之间的通信是通过Akka完成,包括任务的状态以及Checkpoint触发等信息。
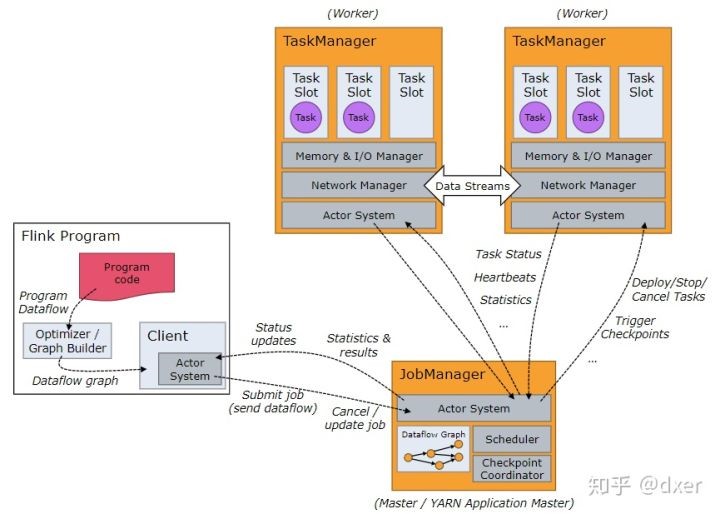
JobManager
JobManager是Flink主从架构中的Master。
JobManager负责分布式任务管理,如任务调度、检查点、故障恢复等。在高可用分布式部署时,系统中可以有多个JobManager,但是只有一个Leader,其他都是Standby。
TaskManager
TaskManager是Flink主从架构中的worker。
TaskManager负责具体的任务执行和对应任务在每个节点上的资源申请与管理。Flink在运行时至少会存在一个TaskManager。每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候会将资源的状态汇报给JobManager。
TaskManager是在JVM中的一个或多个线程中执行任务的工作节点。任务执行的并行度由每个TaskManager上可用的任务槽决定。每个任务代表分给任务槽的一组资源。可以在任务槽中运行一个或多个线程。同一个插槽中的线程共享相同的JVM。同一JVM中的任务共享TCP连接和心跳消息。TaskManager的一个slot代表一个可用线程,该线程具有固定的内存。Flink允许子任务共享Slot,即使它们是不同的task的subtask,只要它们来自相同的job就可以。这种共享可以更好的利用资源。
Client
当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager,Client会将用户提交的Flink程序组装成一个JobGraph,并且是以JobGraph的形式提交。一个JobGraph是一个Flink Dataflow,它是由多个JobVertex组成的DAG。其中,一个JobGraph包含了一个Flink程序的如下信息:JobID、Job名称、配置信息、一组JobVertex等。
客户端通过将编写好的Flink应用编译打包,提交到JobManager,然后JobManager会根据已经注册在JobManager中TaskManager的资源情况,将任务分配给有资源的TaskManager节点,然后启动并与运行任务。TaskManager从JobManager接收需要部署的任务,然后使用Slot资源启动Task,建立数据接入的网络连接,接收数据并开始数据处理。同时TaskManager之间的数据交互都是通过数据流的方式进行的。
Flink组件栈
Flink是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。Flink分层的组件栈如下图所示:
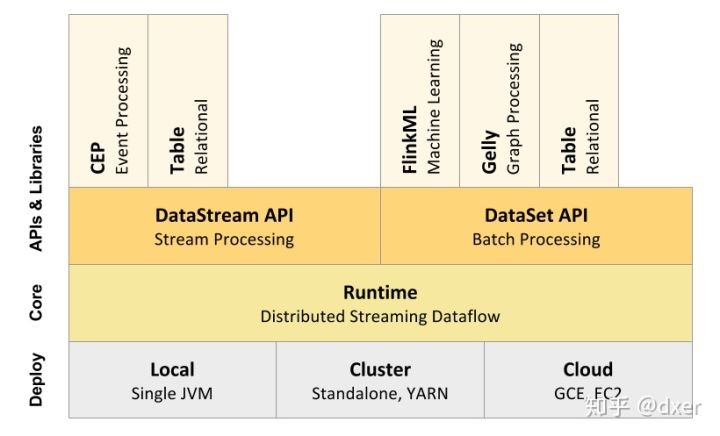
Deployment层
Deployment层主要涉及了Flink的部署模式,Flink支持多种部署模式:
- 本地模式
- 集群模式(Standalone、YARN)
- 云(GCE/EC2)
Runtime层
Runtime层提供了支持Flink计算的全部核心实现,如:
- 支持分布式Stream处理
- JobGraph到ExecutionGraph的映射、调度等,为上层API层服提供基础服务
API层
API层主要实现了面向无界Stream的流出来和面向Batch的批处理API。
其中面向流处理对应DataStream API,面向批处理对应DataSet API。
Libraries层
Libraries层也可以称为Flink应用框架层,根据API层的划分,在API层上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。
- 面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作)
- 面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
Flink编程模型
流处理与批处理
在大数据领域,批处理任务与流处理任务一般被认为是两种不同的任务,一个大数据框架一般会被设计为只能处理其中一种任务。例如Storm只支持流处理任务,而MapReduce、Spark支持吃批处理任务。Spark Streaming是Spark之上支持流处理任务的子系统,看似是一个特例,其实Spark Streaming采用的是micro-batch的架构,即把输入的数据流切分成细粒度的batch,并为每一个batch数据提交一个批处理的Spark任务,所以Spark Streaming本质上还是基于Spark批处理系统对流式数据进行处理,和Storm等完全流式的数据处理方式完全不同。
Flink通过灵活的执行引擎,能够同时支持批处理和流处理任务。
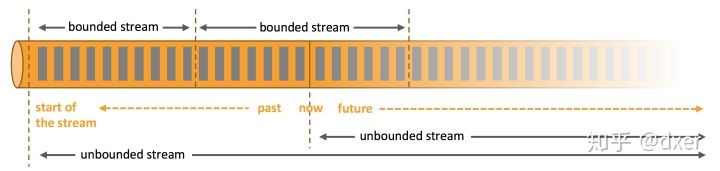
在执行引擎这一层,流处理系统与批处理系统最大的不同在于节点间的数据传输方式。
- 对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存汇总,然后立刻通过网络传输到下一个节点,由下一个节点急需处理。
- 对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。
这两种数据传输模式是两个极端,对应的是流处理系统对低延迟的要求和批处理系统对高吞吐的要求。
Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型。
Flink以固定的缓存块为单位进行网络数据传输,用户可以通过设置缓存块超时值指定缓存块的传输时机。
- 如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到的流处理系统的标准模型,此时系统可以获得最低的处理延迟。
- 如果缓存块的超时值为无限大,则Flink的数据传输方式类似上文提到批处理系统的标准模型,此时系统可以获得最高的吞吐量。
- 缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量。
Flink编程接口
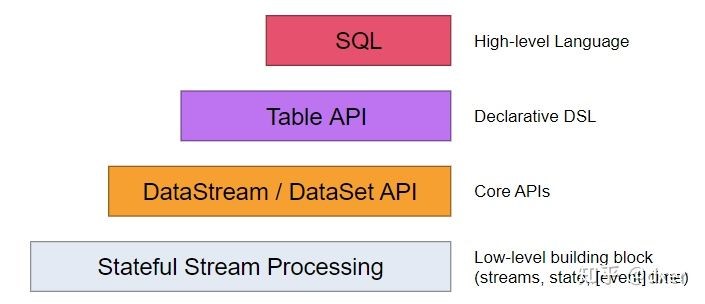
Flink根据数据及类型的不同将数据处理结构分为两大类:
- 支持批处理的计算接口DataSet API
- 支持流计算的计算接口DataStream API
Flink将数据处理接口抽象成四层:
- SQL API:由于SQL语言具有比较低的学习成本,能够让数据分析人员和开发人员快速上手,帮助其更加专注业务本身而不受限于复杂的编程接口,可以通过SQL API完成对批计算和流计算的处理。
- Table API:Table API将内存中DataStream和DataSet数据库在原有的基础上增加Schema信息,将数据类型统一抽象成表结构,然后通过Table API提供的接口处理对应的数据集。
- DataStream/DataSet API:主要面向具有开发经验的用户,用户可以根据API去处理无界流数据和批量数据。
- Stateful Stream Processing:Stateful Stream Processing是Flink中处理Stateful Stream最底层的接口,可以使用Stateful Stream Processing接口操作状态、时间等底层数据。Stateful Stream Processing接口很灵活,可以实现非常复杂的流式计算逻辑。
Flink程序结构
下面看下scala写的Flink wordcount例子:
// 配置执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 指定数据源地址,读取输入数据
val text = env.readTextFile("/path/to/file")
// 对数据集指定转换操作逻辑
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
// 指定计算结果输出位置
counts.writeAsCsv(outputPath, "\n", " ")
// 指定名称并处罚流式任务
env.execute("Flink WordCount")
从上面可以看出,Flink应用程序基本包含以下5个步骤:
- 配置Flink的执行环境
- 创建和加载数据集
- 对数据集指定转换操作逻辑、
- 指定计算结果输出位置
- 调用execute方法触发程序执行
Flink程序与数据流
Flink程序是由Stream和Transformation这两个基本构建块组成,其中Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输出Stream进行计算处理,输出一个或多个结果Stream。
当一个Flink程序被执行的时候,它会映射为Streaming Dataflow。
一个Streaming Dataflow是由一组Stream和Transformation Operator组成,类似一个DAG图,在启动的时候从一个或多个Source Operator开始,结束于一个或多个Sink Operator。
一个由Flink程序映射为Streaming Dataflow的示意图,如下所示:
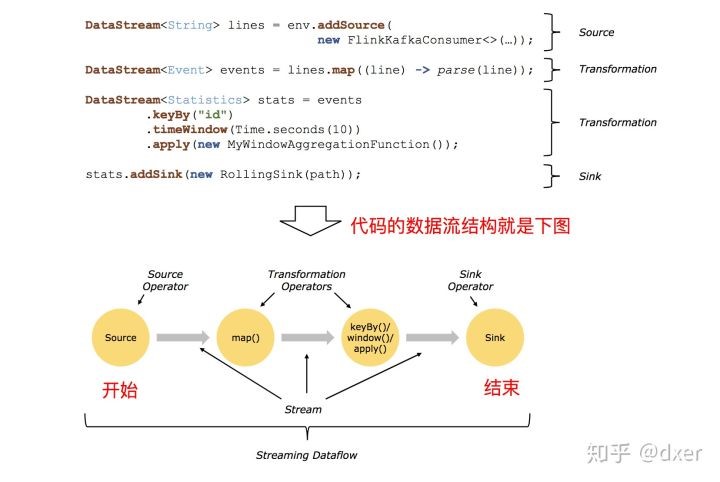
FlinkKafkaConsumer是一个Source Operator
map、keyBy、timeWindow、apply是Transformation Operator
RollingSink是一个Sink Operator
Flink应用场景分析
- 优化电商网站的实时搜索结果 阿里巴巴的基础设置团队使用Flink实时更新产品细节和库存信息
- 针对数据分析团队提供实时流处理服务 通过Flink数据分析凭条提供实时数据分析服务,及时发现问题
- 网络/传感器检测和错误检测 Bouygues电信公司,使用Flink监控其有线和无线网络,实现快速故障响应
- 商业智能分析ETL Zalando使用Flink转换数据以便于加载到数据仓库,将复杂的转换操作转化为相对简单的并确保分析终端用户可以更快的访问数据(实时ETL)
Flink入门介绍的更多相关文章
- Flink入门(二)——Flink架构介绍
1.基本组件栈 了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富 ...
- 《从0到1学习Flink》—— 介绍Flink中的Stream Windows
前言 目前有许多数据分析的场景从批处理到流处理的演变, 虽然可以将批处理作为流处理的特殊情况来处理,但是分析无穷集的流数据通常需要思维方式的转变并且具有其自己的术语(例如,"windowin ...
- Flink入门(三)——环境与部署
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行,包括本地调试环境,集群 ...
- Flink入门(四)——编程模型
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink的编程模型. 数据集类型: 无穷数据集:无穷的持续集成的数据集合 有界数据集:有 ...
- Flink入门(五)——DataSet Api编程指南
Apache Flink Apache Flink 是一个兼顾高吞吐.低延迟.高性能的分布式处理框架.在实时计算崛起的今天,Flink正在飞速发展.由于性能的优势和兼顾批处理,流处理的特性,Flink ...
- 不一样的Flink入门教程
前言 微信搜[Java3y]关注这个朴实无华的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创 ...
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
- C# BackgroundWorker组件学习入门介绍
C# BackgroundWorker组件学习入门介绍 一个程序中需要进行大量的运算,并且需要在运算过程中支持用户一定的交互,为了获得更好的用户体验,使用BackgroundWorker来完成这一功能 ...
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
随机推荐
- javascript原型深入解析1-prototype 和原型链、js面向对象
1.用prototype 封装类 创建的每个函数都有一个prototype(原型属性),他是个指针,指向的对象,这个对象的用途就是包含了这个类型所有实例共享的属性和方法. 回味这句,想想java或者C ...
- dubbo循序渐进 - 使用Docker安装Nexus
docker search nexus docker pull docker.io/sonatype/nexus3 mkdir -p /usr/local/nexus3/nexus-data /usr ...
- Cheat Engine 自动注入
打开游戏 引用自动注入 选择跳转地址 CEAA脚本自动生成 红色部分就是添加代码的地方 添加代码 让阳光每次减少0,并且分配到作弊表 进行激活测试 发现阳光果然只增不减了
- tp5 宝塔open_basedir restriction in effect 错误; IIS open_basedir restriction in effect
很久前做过的一个微信项目,客户突然找到我说换了部署环境后网站报错,再跟客户确定了php版本,伪静态设置后,网站依旧打不开,官网手册这样解释: 然而因为客户是iis8的表示该文档一点鸡毛用都米有哇,求助 ...
- Linux装B命令
原文:https://mp.weixin.qq.com/s/CNmMRjl0iZ8EBPq5VgJHsA 1.空心字体 yum install -y figlet figlet happy 1.0 2 ...
- Odoo销售模块
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/10825988.html 一:销售模块 销售模块的用途: 1)管理销售团队.销售人员:维护销售产品: 2)管理 ...
- Centos 7.3 镜像制作
1.在KVM环境上准备虚拟机磁盘 [root@localhost ~]# qemu-img create -f qcow2 -o size=50G /opt/CentOS---x86_64_50G.q ...
- X509Certificate 类
地址:https://docs.microsoft.com/zh-cn/dotnet/api/system.security.cryptography.x509certificates.x509cer ...
- 洛谷 P1330 封锁阳光大学题解
题目描述 曹是一只爱刷街的老曹,暑假期间,他每天都欢快地在阳光大学的校园里刷街.河蟹看到欢快的曹,感到不爽.河蟹决定封锁阳光大学,不让曹刷街. 阳光大学的校园是一张由N个点构成的无向图,N个点之间由M ...
- django项目后台权限管理功能。
对后台管理员进行分角色,分类别管理,每个管理员登录账号后只显示自己负责的权限范围. 创建后台管理数据库 models.py文件内 # 管理员表 class Superuser(models.Model ...