Spark ML协同过滤推荐算法
一.简介
协同过滤算法【Collaborative Filtering Recommendation】算法是最经典、最常用的推荐算法。该算法通过分析用户兴趣,在用户群中找到指定用户的相似用户,综合这些相似用户对某一信息的评价,形成系统关于该指定用户对此信息的喜好程度预测。
二.步骤
1.收集用户偏好。
2.找到相似的用户或物品。
3.计算推荐。
三.用户评分
从用户的行为和偏好中发现规律,并基于此进行推荐,所以收集用户的偏好信息成为系统推荐效果最基础的决定因素。
数据预处理:
1.减噪
因为用户数据在使用过程中可能存在大量噪声和误操作,所以需要过滤掉这些噪声。
2.归一化
不同行为数据的差别比较大,通过归一化,数据归于大致均衡,计算时才能减少异常数据产生的影响。
组合不同用户行为方式:
1.将不同的行为分组
2.对不同行为进行加权
四.相似度计算
对用户的行为分析得到用户的偏好后,可以根据用户的偏好计算相似用户和物品,然后可以基于相似用户或相似物品进行推荐。我们可以将用户对所有物品的偏好作为一个矩阵来计算用户之间的相似度,或者将所有用户对物品的偏好作为一个矩阵来计算物品之间的相似度。
1.同现相似度
指在喜爱物品A的前提下,喜爱物品B的概率。当物品B喜爱率较高时可以使用(A交B)/sqrt(A或B)。
2.欧式距离
1/(1+d(x,y))
备注:d(x,y) 欧式距离
3.皮尔逊相关系数
皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值为【-1~1】之间。
4.Cosine相似度【余弦相似度】
Cosine相似度广泛应用于计算文档数据的相似度。
5.Tanimoto系数
Tanimoto系数也被称为Jaccard系数,是Cosine相似度的扩展,也多用于计算文档数据的相似度。
五.代码实现
package big.data.analyse.ml import _root_.breeze.numerics.sqrt
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.rdd.RDD /**
* 用户评分
* @param userid 用户
* @param itemid 物品
* @param pref 评分
*/
case class ItemPref(val userid : String,val itemid : String, val pref : Double) extends Serializable /**
* 相似度
* @param itemid_1 物品
* @param itemid_2 物品
* @param similar 相似度
*/
case class ItemSimilar(val itemid_1 : String, val itemid_2 : String, val similar : Double) extends Serializable /**
* 给用户推荐物品
* @param userid 用户
* @param itemid 物品
* @param pref 推荐系数
*/
case class UserRecommend(val userid : String, val itemid : String, val pref : Double) extends Serializable /**
* 相似度计算
*/
class ItemSimilarity extends Serializable{
def Similarity(user : RDD[ItemPref], stype : String) : RDD[ItemSimilar] = {
val similar = stype match{
case "cooccurrence" => ItemSimilarity.CooccurenceSimilarity(user) // 同现相似度
//case "cosine" => // 余弦相似度
//case "euclidean" => // 欧式距离相似度
case _ => ItemSimilarity.CooccurenceSimilarity(user)
}
similar
}
} object ItemSimilarity{
def CooccurenceSimilarity(user : RDD[ItemPref]) : (RDD[ItemSimilar]) = {
val user_1 = user.map(r => (r.userid, r.itemid, r.pref)).map(r => (r._1, r._2))
/**
* 内连接,默认根据第一个相同字段为连接条件,物品与物品的组合
*/
val user_2 = user_1.join(user_1) /**
* 统计
*/
val user_3 = user_2.map(r => (r._2, 1)).reduceByKey(_+_) /**
* 对角矩阵
*/
val user_4 = user_3.filter(r => r._1._1 == r._1._2) /**
* 非对角矩阵
*/
val user_5 = user_3.filter(r => r._1._1 != r._1._2) /**
* 计算相似度
*/
val user_6 = user_5.map(r => (r._1._1, (r._1._1,r._1._2,r._2)))
.join(user_4.map(r => (r._1._1, r._2))) val user_7 = user_6.map(r => (r._2._1._2, (r._2._1._1, r._2._1._2, r._2._1._3, r._2._2)))
.join(user_4.map(r => (r._1._1, r._2))) val user_8 = user_7.map(r => (r._2._1._1, r._2._1._2, r._2._1._3, r._2._1._4, r._2._2))
.map(r => (r._1, r._2, (r._3 / sqrt(r._4 * r._5)))) user_8.map(r => ItemSimilar(r._1, r._2, r._3))
}
} class RecommendItem{
def Recommend(items : RDD[ItemSimilar], users : RDD[ItemPref], number : Int) : RDD[UserRecommend] = {
val items_1 = items.map(r => (r.itemid_1, r.itemid_2, r.similar))
val users_1 = users.map(r => (r.userid, r.itemid, r.pref)) /**
* i行与j列join
*/
val items_2 = items_1.map(r => (r._1, (r._2, r._3))).join(users_1.map(r => (r._2, (r._1, r._3)))) /**
* i行与j列相乘
*/
val items_3 = items_2.map(r => ((r._2._2._1, r._2._1._1), r._2._2._2 * r._2._1._2)) /**
* 累加求和
*/
val items_4 = items_3.reduceByKey(_+_) /**
* 过滤已存在的物品
*/
val items_5 = items_4.leftOuterJoin(users_1.map(r => ((r._1, r._2), 1))).filter(r => r._2._2.isEmpty)
.map(r => (r._1._1, (r._1._2, r._2._1))) /**
* 分组
*/
val items_6 = items_5.groupByKey() val items_7 = items_6.map(r => {
val i_2 = r._2.toBuffer
val i_2_2 = i_2.sortBy(_._2)
if(i_2_2.length > number){
i_2_2.remove(0, (i_2_2.length - number))
}
(r._1, i_2_2.toIterable)
}) val items_8 = items_7.flatMap(r => {
val i_2 = r._2
for(v <- i_2) yield (r._1, v._1, v._2)
}) items_8.map(r => UserRecommend(r._1, r._2, r._3))
}
} /**
* Created by zhen on 2019/8/9.
*/
object ItemCF {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("ItemCF")
conf.setMaster("local[2]") val sc = new SparkContext(conf) /**
* 设置日志级别
*/
Logger.getRootLogger.setLevel(Level.WARN) val array = Array("1,1,0", "1,2,1", "1,4,1", "2,1,0", "2,3,1", "2,4,0", "3,1,0", "3,2,1", "4,1,0", "4,3,1")
val cf = sc.parallelize(array) val user_data = cf.map(_.split(",")).map(r => (ItemPref(r(0), r(1), r(2).toDouble))) /**
* 建立模型
*/
val mySimilarity = new ItemSimilarity()
val similarity = mySimilarity.Similarity(user_data, "cooccurrence") val recommend = new RecommendItem()
val recommend_rdd = recommend.Recommend(similarity, user_data, 30) /**
* 打印结果
*/
println("物品相似度矩阵:" + similarity.count())
similarity.collect().foreach(record => {
println(record.itemid_1 +","+ record.itemid_2 +","+ record.similar)
}) println("用户推荐列表:" + recommend_rdd.count())
recommend_rdd.collect().foreach(record => {
println(record.userid +","+ record.itemid +","+ record.pref)
})
}
}
六.结果
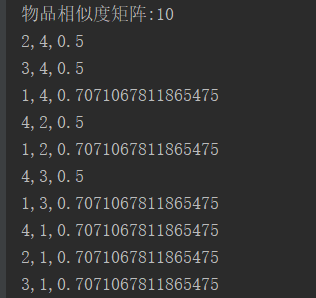

Spark ML协同过滤推荐算法的更多相关文章
- SparkMLlib—协同过滤推荐算法,电影推荐系统,物品喜好推荐
SparkMLlib-协同过滤推荐算法,电影推荐系统,物品喜好推荐 一.协同过滤 1.1 显示vs隐式反馈 1.2 实例介绍 1.2.1 数据说明 评分数据说明(ratings.data) 用户信息( ...
- SimRank协同过滤推荐算法
在协同过滤推荐算法总结中,我们讲到了用图模型做协同过滤的方法,包括SimRank系列算法和马尔科夫链系列算法.现在我们就对SimRank算法在推荐系统的应用做一个总结. 1. SimRank推荐算法的 ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 基于MapReduce的(用户、物品、内容)的协同过滤推荐算法
1.基于用户的协同过滤推荐算法 利用相似度矩阵*评分矩阵得到推荐列表 已经推荐过的置零 2.基于物品的协同过滤推荐算法 3.基于内容的推荐 算法思想:给用户推荐和他们之前喜欢的物品在内容上相似的物品 ...
- 基于局部敏感哈希的协同过滤推荐算法之E^2LSH
需要代码联系作者,不做义务咨询. 一.算法实现 基于p-stable分布,并以‘哈希技术分类’中的分层法为使用方法,就产生了E2LSH算法. E2LSH中的哈希函数定义如下: 其中,v为d维原始数据, ...
- 用Spark学习矩阵分解推荐算法
在矩阵分解在协同过滤推荐算法中的应用中,我们对矩阵分解在推荐算法中的应用原理做了总结,这里我们就从实践的角度来用Spark学习矩阵分解推荐算法. 1. Spark推荐算法概述 在Spark MLlib ...
- Spark的协同过滤.Vs.Hadoop MR
基于物品的协同过滤推荐算法案例在TDW Spark与MapReudce上的实现对比,相比于MapReduce,TDW Spark执行时间减少了66%,计算成本降低了40%. 原文链接:http://w ...
- 推荐系统| ② 离线推荐&基于隐语义模型的协同过滤推荐
一.离线推荐服务 离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的,变更的频率取决于算法调度的频率. 离线推 ...
- Mahout之(二)协同过滤推荐
协同过滤 —— Collaborative Filtering 协同过滤简单来说就是根据目标用户的行为特征,为他发现一个兴趣相投.拥有共同经验的群体,然后根据群体的喜好来为目标用户过滤可能感兴趣的内容 ...
随机推荐
- Kinect for Windows V2开发教程
教程 https://blog.csdn.net/openbug/article/details/80921437 Windows版Kinect SDK https://docs.microsoft. ...
- Windbg的快捷键
窗口切换 可以使用以下键盘快捷方式窗口之间进行切换. 项 效果 CTRL+TAB 调试信息窗口之间切换. 通过重复使用此密钥,你可以扫描通过的所有窗口,而不考虑是否浮动. 停靠本身,或选项卡式停靠窗口 ...
- Vue 实现点击展开收起
Vue 展开收起功能实现 之前写项目的时候提到了一个需求 展开/收起 所有内容的需求 .因之前一值是重构,自己写功能还是比较少的,于是网上搜了一下,发现很多东西其实是jq的功能 虽然可以拿过来用,但是 ...
- ESA2GJK1DH1K基础篇: 阿里云物联网平台: 测试MQTT客户端接收云平台的数据
前言 有时候想想可能直接连接现成的感觉比较方便吧! 这种东西考验的是你底子是否够好,是否有很强的学习能力 因为咱就是看文档,理解文档.用文档. 测这节会感觉:这是啥呀...下一节更精彩,但是必须看这节 ...
- 7-STM32物联网开发WIFI(ESP8266)+GPRS(Air202)系统方案安全篇(GPRS模块SSL连接MQTT)
6-STM32物联网开发WIFI(ESP8266)+GPRS(Air202)系统方案安全篇(Wi-Fi模块SSL连接MQTT) 由于GPRS是直接和GPRS基站进行连接,其实对于GPRS而言,即使不加 ...
- 虚方法(virtual)\抽象方法(abstract)\接口(interface)的区别
转自:https://www.cnblogs.com/fantaohaoyou/p/9402657.html 虚方法和抽象方法都可以供派生类重写,它们之间有什么区别呢? 1. 虚方法必须有实现部分,抽 ...
- 重置jenkins用户名密码
忘记用户名密码(如图)不管是忘记用户名密码还是误删jenkins目录下的users文件都可以使用下面的方式找回密码,我的版本是Jenkins 2.134 1. 进入jenkins安装目录,我的 ...
- sts问题合集
背景:用来记录在使用sts过程中遇到的相关问题 Version 当前jdk版本号 of the JVM is not suitable for the this product.Version:1.8 ...
- C基础 带你手写 redis adlist 双向链表
引言 - 导航栏目 有些朋友可能对 redis 充满着数不尽的求知欲, 也许是 redis 属于工作, 交流(面试)的大头戏, 不得不 ... 而自己当下对于 redis 只是停留在会用层面, 细节层 ...
- trie、FSA、FST(转)
add by zhj: 在学习Lucene的存储结构时,看到其使用了FST,这篇文章写的不错. trie,FSA,FST都是用来解决有限状态机的存储,trie是树,它进一步演化为FSA和FST,这两者 ...