Spark Partition
分区的意义
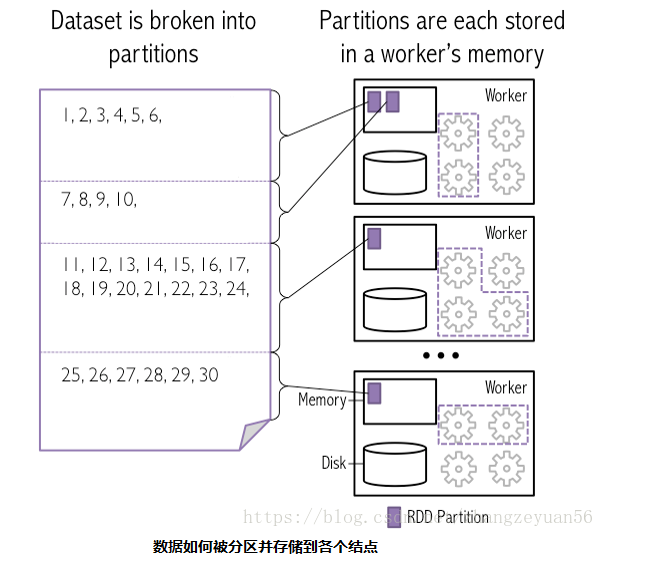
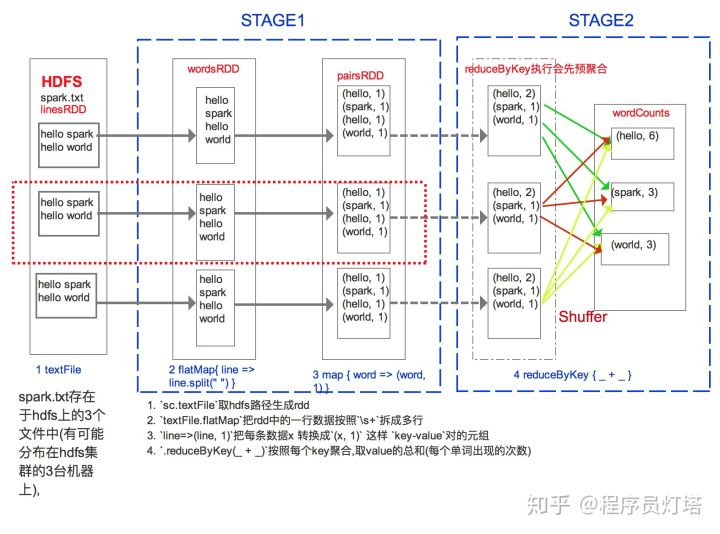
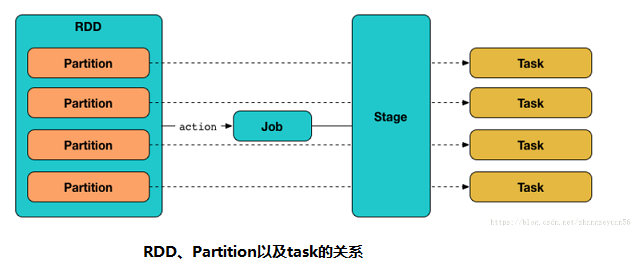
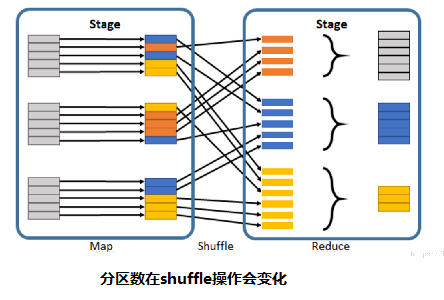
Spark RDD 是一种分布式的数据集,由于数据量很大,因此它被切分成不同分区并存储在各个Worker节点的内存中。从而当我们对RDD进行操作时,实际上是对每个分区中的数据并行操作。Spark根据字段进行partition类似于关系型数据库中的分区,可以加大并行度,提高执行效率。Spark从HDFS读入文件的分区数默认等于HDFS文件的块数(blocks),HDFS中的block是分布式存储的最小单元。
1. RDD repartition和partitionBy的区别
spark中RDD两个常用的重分区算子,repartition 和 partitionBy 都是对数据进行重新分区,默认都是使用 HashPartitioner,区别在于partitionBy 只能用于 PairRdd(key-value类型的数据),但是当它们同时都用于 PairRdd时,效果也是不一样的。reparation的分区比较的随意,没有什么规律,而partitionBy把相同的key都分到了同一个分区。
val parRDD = pairRDD.repartition(10) //重分区为10;
val parRDD = pairRDD.partitionBy(new HashPartitioner(10)) //重分区为10;
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext, TaskContext}
import org.apache.spark.rdd.RDD
object PartitionDemo {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("localTest").setMaster("local[4]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List("hello", "jason", "what", "are", "you", "doing","hi","jason","do","you","eat","dinner",
"hello","jason","do","you","have","some","time","hello","jason","time","do","you","jason","jason"),4) //设置4个分区;
val word_count = rdd.flatMap(_.split(",")).map((_,1))
val repar = word_count.repartition(10) //重分区为10;
val parby = word_count.partitionBy(new HashPartitioner(10)) //重分区为10;
print(repar)
print(parby)
}
def print(rdd : RDD[(String, Int)]) = {
rdd.foreachPartition(pair=>{
println("partion " + TaskContext.get.partitionId + ":")
pair.foreach(p=>{ println(" " + p) })
})
println
}
}
partitionBy的三种分区方式:
1、HashPartitioner
val parRDD= pairRDD.partitionBy(new HashPartitioner(3))
HashPartitioner确定分区的方式:partition = key.hashCode () % numPartitions
2、RangePartitioner
val parRDD= pairRDD.partitionBy(new RangePartitioner(3,counts))
RangePartitioner会对key值进行排序,然后将key值被划分成3份key值集合。
3、CustomPartitioner
CustomPartitioner可以根据自己具体的应用需求,自定义分区。
class CustomPartitioner(numParts: Int) extends Partitioner {
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int =
{
if(key==1)){ 0 }
else if (key==2){ 1}
else{ 2 }
}
}
val parRDD = pairRDD.partitionBy(new CustomPartitioner(3))
2. DataFrame分区
1. repartition:根据字段分区
val regionDf = peopleDf.repartition($"region")
2. coalesce: coalesce一般用于合并/减少分区,将数据从一个分区移到另一个分区。
val peopleDF2= peopleDF.coalesce(2) // 原来分区为4,减少到2, 无法增加分区数,例如peopleDF.coalesce(6)执行完分区还是4
二者区别:The repartition algorithm does a full shuffle of the data and creates equal sized partitions of data. coalesce combines existing partitions to avoid a full shuffle.
为什么使用repartition而不用coalesce? A full data shuffle is an expensive operation for large data sets, but our data puddle is only 2,000 rows. The repartition method returns equal sized text files, which are more efficient for downstream consumers. (non-partitioned) It took 241 seconds to count the rows in the data puddle when the data wasn’t repartitioned (on a 5 node cluster). (partitioned) It only took 2 seconds to count the data puddle when the data was partitioned — that’s a 124x speed improvement!
3. DataFrameWriter 分段和分区
1. bucketBy:分段和排序仅适用于持久表。 对于基于文件的数据源,可以对输出进行分类。
peopleDF.write.bucketBy(42, "name").sortBy("age").saveAsTable("people_bucketed")
2. partitionBy:分区则可以同时应用于save和saveAsTable
peopleDF.write.partitionBy("region").format("parquet").save("people_partitioned.parquet")
saveAsTable 保存数据并持久化表
DataFrame可以使用saveAsTable 命令将其作为持久表保存到Hive Metastore中。Spark将为您创建一个默认的本地Hive Metastore(使用Derby)。与createOrReplaceTempView命令不同的是, saveAsTable将实现DataFrame的内容并创建指向Hive Metastore中的数据的指针。即使您的Spark程序重新启动后,永久性表格仍然存在,只要您保持与同一Metastore的连接即可。用于持久表的DataFrame可以通过使用表的名称调用tablea方法来创建SparkSession。
持久化表时您可以自定义表格路径 ,例如df.write.option("path", "/some/path").saveAsTable("t")。当表被删除时,自定义表路径将不会被删除,表数据仍然存在。如果没有指定自定义表格路径,Spark会将数据写入仓库目录下的默认表格路径。当表被删除时,默认的表路径也将被删除。
4. JDBC partition
Spark提供jdbc方法操作数据库,每个RDD分区都会建立一个单独的JDBC连接。 尽管用户可以设置RDD的分区数目,在一些分布式的shuffle操作(例如reduceByKey 和join)之后,RDD又会变成默认的分区数spark.default.parallelism,这种情况下JDBC连接数可能超出数据库的最大连接。Spark 2.1提供numPartitions 参数来设置JDBC读写时的分区数,可以解决前面说的问题。如果写数据时的分区数超过最大值,我们可以在写之前使用方法coalesce(numPartitions)来减少分区数。
val userDF = spark.read.format("jdbc").options(Map("url" -> url, "dbtable" -> sourceTable, "lowerBound"->"1", "upperBound"->"886500", "partitionColumn"->"user_id", "numPartitions"->"10")).load()
userDF.write.option("maxRecordsPerFile", 10000).mode("overwrite").parquet(outputDirectory)
userDF.repartition(10000).write.mode("overwrite").parquet(outputDirectory)
分区案例
val df = spark.read.format("jdbc").options(Map("url" -> url, "dbtable" -> sourceTable, "lowerBound"->"1", "upperBound"->"825485207", "partitionColumn"->"org_id", "numPartitions"->"10")).load()
(1) jdbc partition: df.write.format("com.databricks.spark.csv").mode("overwrite").save(s"$filePath/$filename"+"_readpar")
(2) maxRecordsPerFile: df.write.option("maxRecordsPerFile", 10000).format("com.databricks.spark.csv").mode("overwrite").save(s"$filePath/$filename"+"_maxRecd")
(3) repartition: df.repartition(4).write.format("com.databricks.spark.csv").mode("overwrite").save(s"$filePath/$filename"+"_repar")
(4) rdd key-value partitionBy: df.rdd.map(r => (r.getInt(1), r)).partitionBy(new HashPartitioner(10)).values.saveAsTextFile(s"$filePath/$filename"+"_rddhash")
(1) jdbc partition: 数据分布不均匀,有些分区数据多有的少; key是有序的,根据bound区间将key分成不同分区


(2) maxRecordsPerFile: 同上,当一个分区条数超过maxRecordsPerFile,会被拆分成多个子分区,同一个Key可能因此被分到不同分区
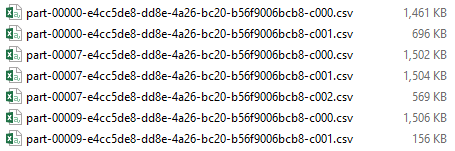
(3) repartition: 分成同等大小的分区(不能保证每个分区的条数是一样的); key是无序的,同样的key可能在不同分区

(4) rdd key-value partitionBy: 使用partition方法将数据按照一定规则分区,可以自定义分区规则

---------------------
作者:zhangzeyuan56
来源:CSDN
原文:https://blog.csdn.net/zhangzeyuan56/article/details/80935034
版权声明:本文为博主原创文章,转载请附上博文链接!
---------------------
作者:junzhou134
来源:CSDN
原文:https://blog.csdn.net/m0_37138008/article/details/78936029
版权声明:本文为博主原创文章,转载请附上博文链接!
---------------------
作者:JasonLeeblog
来源:CSDN
原文:https://blog.csdn.net/xianpanjia4616/article/details/84328928
版权声明:本文为博主原创文章,转载请附上博文链接!
Spark Partition的更多相关文章
- spark partition 理解 / coalesce 与 repartition的区别
一.spark 分区 partition的理解: spark中是以vcore级别调度task的. 如果读取的是hdfs,那么有多少个block,就有多少个partition 举例来说:sparksql ...
- Spark on Yarn遇到的几个问题
1 概述 Spark的on Yarn模式,其资源分配是交给Yarn的ResourceManager来进行管理的,但是目前的Spark版本,Application日志的查看,只能通过Yarn的yarn ...
- Spark on Yarn遇到的问题及解决思路
原文:http://www.aboutyun.com/thread-9425-1-1.html 问题导读1.Connection Refused可能原因是什么?2.如何判断内存溢出,该如何解决?扩展: ...
- spark RDD的元素顺序(ordering)测试
通过实验发现: foreach()遍历的顺序是乱的 但: collect()取到的结果是依照原顺序的 take()取到的结果是依照原顺序的 为什么呢???? 另外,可以发现: take()取到了指定数 ...
- 从物理执行的角度透视spark Job
本博文主要内容: 1.再次思考pipeline 2.窄依赖物理执行内幕 3.宽依赖物理执行内幕 4.Job提交流程 一:再次思考pipeline 即使采用pipeline的方式,函数f对依赖的RDD中 ...
- Spark提高篇——RDD/DataSet/DataFrame(二)
该部分分为两篇,分别介绍RDD与Dataset/DataFrame: 一.RDD 二.DataSet/DataFrame 该篇主要介绍DataSet与DataFrame. 一.生成DataFrame ...
- Spark RDD Action 简单用例(一)
collectAsMap(): Map[K, V] 返回key-value对,key是唯一的,如果rdd元素中同一个key对应多个value,则只会保留一个./** * Return the key- ...
- Spark Streaming中空batches处理的两种方法(转)
原文链接:Spark Streaming中空batches处理的两种方法 Spark Streaming是近实时(near real time)的小批处理系统.对给定的时间间隔(interval),S ...
- 【转】Spark on Yarn遇到的几个问题
本文转自 http://www.cnblogs.com/Scott007/p/3889959.html 1 概述 Spark的on Yarn模式,其资源分配是交给Yarn的ResourceManage ...
随机推荐
- BJFU-218-基于链式存储结构的图书信息表的最贵图书的查找
如果编译不通过,可以将C该为C++ #include<stdio.h> #include<stdlib.h> #define MAX 100 //创建节点 typedef st ...
- C语言:求π
1835: 圆的面积 本题的关键在于如何求π: 今天先给给大家介绍一种针对本题的方法——利用反三角函数求π. 在高数中arcsin(0)=arccos(1)=π,不过编译器中并没有arcsin和arc ...
- python 递归\for循环_斐波那契数列
# 递归 def myAdd(a, b): c = a + b print(c) if c > 100: return return myAdd(a + 1, c) #最大递归深度是1000 m ...
- python_进程池以及线程池
可以重复利用的线程 直接上代码 from threading import Thread, current_thread from queue import Queue # 重写线程类 class M ...
- 【题解】Luogu P5337 [TJOI2019]甲苯先生的字符串
原题传送门 我们设计一个\(26*26\)的矩阵\(A\)表示\(a~z\)和\(a~z\)是否能够相邻,这个矩阵珂以由\(s1\)得出.答案显然是矩阵\(A^{len_{s2}-1}\)的所有元素之 ...
- DevExpress中GridColumnCollection实现父子表数据绑定
绑定数据: 父表: DataTable _parent = _dvFlt.ToTable().Copy(); 子表: DataTable _child = _dvLog.ToTable().Copy( ...
- AS shortcuts
stl => statelessstf => statefulalt+enter, select element => add pading or somethingselect c ...
- 常用方法装windows
1.通过制作启动盘来进行安装 (1)简单的启动盘制作工具 通过百度”启动盘“,会发现有很多制作启动盘的工具. 这些工具操作都比较简单,易于上手,功能强大,不仅能装系统,而且还能维修. 具体使用方法,官 ...
- SQL Server 用一张表的数据更新另一张表的数据(转载)
文章一:SQL Server中如何基于一个表的数据更新另一个表的对应数据的SQL语句脚本 https://codedefault.com/2017/sql-server-update-from-a-s ...
- Linq 等式运算符:SequenceEqual(转载)
https://www.bbsmax.com/A/nAJvbKywJr/ 引用类型比较的是引用,需要自己实现IEqualityComparer 比较器. IList<string> str ...