postgres主从基于流复制
环境: CentOS Linux release 7.6.1810 (Core) 内核版本:3.10.0-957.10.1.el7.x86_64
node1:192.168.216.130
node2:192.168.216.132
node3:192.168.216.134
一、首先在3个节点分别安装postgres,这里由于线上环境使用9.5.3,故本人直接使用9.5.3用于实验测试,其他版本的编译安装方式是相同的
yum install gcc readline-devel zlib-devel
cd /tmp/
wget https://ftp.postgresql.org/pub/source/v9.5.3/postgresql-9.5.3.tar.gz
tar -xf postgresql-9.5.3.tar.gz
useradd postgres
./configure --prefix=/usr/local/postgresql
make -j2
make install
chown -R postgres:postgres /usr/local/postgresql/
二、 在2个节点上分别配置环境变量并执行初始化操作
1、切换用户
su - postgres
2、配置环境变量
vi .bash_profile [postgres@localhost ~]$ cat .bash_profile
# .bash_profile # Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi # User specific environment and startup programs
PGHOME=/usr/local/postgresql
export PGHOME
PGDATA=/usr/local/postgresql/data
export PGDATA
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$PGHOME/bin export PATH
3、使上述环境立即变量生效
source .bash_profile
4、验证环境变量是否配置成功(查询postgres数据库版本号)
[postgres@localhost ~]$ psql -V
psql (PostgreSQL) 9.5.3
4、执行初始化:
initdb
三、编辑node1节点上的postgresql.conf配置文件
仅供参考,以下参数请根据需求进行合理配置修改
listen_addresses = '*'
port = 5432
wal_level = logical
archive_mode = on
max_wal_senders = 10
hot_standby = on
log_destination = 'csvlog'
logging_collector = on
log_directory = 'pg_log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_rotation_age = 1d
log_rotation_size = 20MB
四、编辑node1节点上的pg_hba.conf配置文件
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only
local all postgres trust
host all all 0.0.0.0/0 md5
# IPv4 local connections:
host all postgres 127.0.0.1/32 trust
# IPv6 local connections:
host all postgres ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication replicator trust
host replication replicator 0.0.0.0/0 md5
host replication postgres 127.0.0.1/32 trust
#host replication postgres ::1/128 trust
五、启动node1节点的数据库服务,并连接主库
pg_ctl -D /usr/local/postgresql/data start
验证主库是否正常
执行创建一个测试库sql语句,用于测试主库
create database test;
下图是我已经执行过的

执行sql语句创建基于流复制的用户,后面会用到,这里所创建的replicator用户名注意和上文的pg_hba.conf配置文件中的用户保持一致
create user replicator replication login encrypted password '1qaz2wsx';
六、创建物理复制槽,分别对应node2,node3
select * from pg_create_physical_replication_slot('pgsql95_132');
select * from pg_create_physical_replication_slot('pgsql95_134');
七、在node2、node3节点上清空初始化后的data数据
进入初始化目录
cd /usr/local/postgresql/data/
清空当前目录下的所有文件
rm -rf *
八、在node2、node3节点上执行基础备份,配置stream replication
./pg_basebackup -h 192.168.216.130 -D /usr/local/postgresql/data -U replicator -c fast -X stream -v -P -R
这里的密码为创建replicator用户时所指定的密码
编辑node2、node3上的recovery.conf文件,注意 recovery.conf 的 primary_slot_name 在不同节点值会不同。
node2:
[postgres@localhost data]$ cat recovery.conf
standby_mode = 'on'
recovery_target_timeline = 'latest'
primary_conninfo = 'user=replicator password=1qaz2wsx host=192.168.216.130 port=5432 sslmode=disable sslcompression=1'
primary_slot_name = 'pgsql95_132'
node3:
[postgres@localhost data]$ cat recovery.conf
standby_mode = 'on'
recovery_target_timeline = 'latest'
primary_conninfo = 'user=replicator password=1qaz2wsx host=192.168.216.130 port=5432 sslmode=disable sslcompression=1'
primary_slot_name = 'pgsql95_134'
九、分别启动node2、node3节点的postgres服务
pg_ctl -D /usr/local/postgresql/data start
此时在node1节点上执行以下sql语句,可以看到active字段由原来的“f”变为“t”

且在主库上(node1)可以看到postgres进程为wal sender状态

两个从库上node2,node3上的postgres进程为wal receiver状态

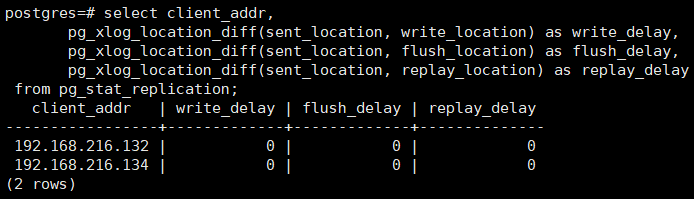
查询复制状态
select client_addr,
pg_xlog_location_diff(sent_location, write_location) as write_delay,
pg_xlog_location_diff(sent_location, flush_location) as flush_delay,
pg_xlog_location_diff(sent_location, replay_location) as replay_delay
from pg_stat_replication;
postgres主从基于流复制的更多相关文章
- mysql之 MySQL 主从基于 GTID 复制原理概述
一. 什么是GTID ( Global transaction identifiers ):MySQL-5.6.2开始支持,MySQL-5.6.10后完善,GTID 分成两部分,一部分是服务的UUid ...
- mysql之 MySQL 主从基于position复制原理概述
1 .主从复制简介MySQL 主从复制就是将一个 MySQL 实例(Master)中的数据实时复制到另一个 MySQL 实例(slave)中,而且这个复制是一个异步复制的过程.实现整个复制操作主要由三 ...
- postgres配置主从流复制
postgres主从流复制 postgres在9.0之后引入了主从的流复制机制,所谓流复制,就是从库通过tcp流从主库中同步相应的数据.postgres的主从看过一个视频,大概效率为3w多事务qps. ...
- 再不了解PostgreSQL,你就晚了之PostgreSQL主从流复制部署
前言 在MySQL被收购之后,虽然有其替代品为: MariaDB,但是总感觉心里有点膈应.大家发现了另一款开源的数据库: PostgreSQL. 虽然centos自带版本9.2也可以用,但是最近的几次 ...
- PostgreSQL异步主从流复制搭建
1 总体规划 Master库 Slave库 操作系统 CentOS Linux release 7.5.1804 CentOS Linux release 7.5.1804 处理器 1 1 内存 ...
- 使用 Bitnami PostgreSQL Docker 镜像快速设置流复制集群
bitnami-docker-postgresql 仓库 源码:bitnami-docker-postgresql https://github.com/bitnami/bitnami-docker- ...
- PostgreSQL 流复制+高可用
QA PgPool-II 同步 Postgresql X1 服务器准备 192.168.59.121 PostgreSQL10 192.168.59.120 PGPool-II 3.7 X2 安装Po ...
- 数据库周刊28│开发者最喜爱的数据库是什么?阿里云脱口秀聊程序员转型;MySQL update误操作;PG流复制踩坑;PG异机归档;MySQL架构选型;Oracle技能表;Oracle文件损坏处理……
热门资讯 1.Stackoverflow 2020年度报告出炉!开发者最喜爱的数据库是什么?[摘要]2020年2月,近6.5万名开发者参与了 Stackoverflow 的 2020 年度调查,这份报 ...
- postgresSQL主从流复制安装
命令行运维: https://blog.csdn.net/zhangzeyuaaa/article/details/77941039 安装流程: 先准备类库: yum -y install readl ...
随机推荐
- [转] 浅谈 OpenResty
一.前言 我们都知道Nginx有很多的特性和好处,但是在Nginx上开发成了一个难题,Nginx模块需要用C开发,而且必须符合一系列复杂的规则,最重要的用C开发模块必须要熟悉Nginx的源代码,使得开 ...
- zuul网关路由作用
为了方便客户端调用微服务,所以设计出了网关.在微服务实例地址发生改变的情况下,客户端调用服务要能够不受影响. 网关可以完成的功能:路由,反向代理,日志记录,权限控制,限流 在本例子中 Eureka ...
- 23 SVN---版本控制系统
1.SVN介绍 SVN是Subversion的简称,是一个自由开源的版本控制系统. Subversion将文件存放在中心版本库里,这个版本库很像一个普通的文件服务器,不同的是,它可以记录每一次文件和目 ...
- 玩转 SpringBoot 2 快速整合 Filter
概述 SpringBoot 中没有 web.xml, 我们无法按照原来的方式在 web.xml 中配置 Filter .但是我们可以通过 JavaConfig(@Configuration +@Bea ...
- 通过Fastdfs进行文件上传服务(文件和图片的统一处理)
1.文件上传简单流程分析图: 2.Fastdfs介绍: Fastdfs由两个角色组成: Tracker(集群):调度(帮你找到有空闲的Storage) Storage(集群):文件存储(帮你保存文件或 ...
- Listener学习
监听器Listener用于监听web应用中某些对象.信息的创建.销毁.增加,修改,删除等动作的发生,然后作出相应的响应处理.当范围对象的状态发生变化的时候,服务器自动调用监听器对象中的方法.常用于统计 ...
- 通过werkzeug了解wsgi
Django有wsgi当做socket,而flask自身是没有wsgi的,他是通过werkzeug来实现的. 看源码 下面看下源码是如何实现的: #这是我们写的flask代码from flask im ...
- 论文笔记 : NCF( Neural Collaborative Filtering)
ABSTRACT 主要点为用MLP来替换传统CF算法中的内积操作来表示用户和物品之间的交互关系. INTRODUCTION NeuCF设计了一个基于神经网络结构的CF模型.文章使用的数据为隐式数据,想 ...
- windows桌面远程连接突然不能双向复制文件
远程桌面连接windows 2008,突然无法在本地和服务器之间互相复制文件.根据微软的说明,由rdpclip.exe进程来控制,打开远程服务器的任务管理器,看到rdpclip.exe进程存在,即可进 ...
- Linux 服务器 关闭FTP匿名访问
service vsftpd status //查看FTP运行状态 vim /etc/vsftpd/vsftpd.conf //修改配置文件 找到vsftpd.conf中的 anonymous_ena ...