day31_8.12并发编程二线程
一。进程间的通信
在进程中,可以通过Queue队列进行通信,队列有两个特点:
1.先进先出。(先来的数据先被取出)
2.管道式存取。(数据取出一次后就不会在有了)
在python中有以下方法来操作数据。
from multiprocessing import Queue q = Queue(5)
for i in range(5):
q.put(i)
print(q.empty())
print(q.full())
for i in range(5):
print(q.get())
print(q.get_nowait())
print(q.empty())
其中put()就是在其中放入数据。
get()从该队列中取出数据,如果队列中没有了数据,程序就会阻塞在这。
empty()判断这个对列是否为空。
full()判断这个数据是否为满
get_nowait()非阻塞获取数据。也就是当队列中没有数据时就抛出异常
这3个方法在多进程中不会常用,因为,是根据当前状态判断数据和获取数据。
二。进程之间使用队列
在各个子进程之间的数据传输,可使用队列+锁(ipc机制)进行传输,将对列作为参数传入子进程函数:
from multiprocessing import Queue,Process def producer(q):
for i in range(5):
q.put(i) def consumer(q):
for i in range(5):
print(q.get()) if __name__ == '__main__':
q = Queue(5)
p1 = Process(target=producer,args=(q,))
p2 = Process(target=consumer, args=(q,))
p1.start()
p2.start()
print('end')
#end
#
#
#
#
#
三。生产者与消费者模型
在python中,可以模拟生产者与消费者模型,创建一个名为producer的作为生产者。
创建一个名为consumer的作为消费者。
生产者输出一定的数据,消费者持续不断的接受数据。
两个进程之间使用队列进行数据交互:
def producer(name,thing,q):
for i in range(10):
data = '%s生产了%s%s'%(name,thing,i)
time.sleep(random.random())
q.put(data)
print(data) def consumer(name,q):
while True:
data = q.get()
time.sleep(random.random())
print('%s获取了%s'%(name,data)) if __name__ == '__main__':
q = Queue()
p = Process(target=producer,args=('zzj','手机',q))
c = Process(target=consumer,args=('zzp',q))
p.start()
c.start()
这种模型有一种缺陷,会在程序的最后卡住,因为最后执行消费者的语句中没有终止条件,所以会一直索要数据,所以要对这个模型进行改进。
def producer(name,thing,q):
for i in range(10):
data = '%s生产了%s%s'%(name,thing,i)
time.sleep(random.random())
q.put(data)
print(data) def consumer(name,q):
while True:
data = q.get()
time.sleep(random.random())
if data == None:
break
print('%s获取了%s'%(name,data)) if __name__ == '__main__':
q = Queue()
p = Process(target=producer,args=('zzj','手机',q))
c = Process(target=consumer,args=('zzp',q))
p.start()
c.start()
p.join()
q.put(None)
先添加一个生产者生产完毕的阻塞p.join,当所有的数据生产完毕后,像队列中添加一个None,再从消费者里添加判断,当消费者获取到了None之后,代表之后不会再生产数据了就跳出while循环。
当然,这样的模型在实际使用时,会遇到多个进程的情况,就要多次使用put(None)方法。
使用JoinableQueue队列就可以使用其中的task_done()计算消费者消费了多少数据。其中的join阻塞的是,当队列中的数据被全部取空的时候,继续执行以下的程序
def producer(name,thing,q):
for i in range(10):
data = '%s生产了%s%s'%(name,thing,i)
time.sleep(random.random())
q.put(data)
print(data) def consumer(name,q):
while True:
data = q.get()
time.sleep(random.random())
print('%s获取了%s'%(name,data))
q.task_done() if __name__ == '__main__':
q = JoinableQueue()
p = Process(target=producer,args=('zzj','手机',q))
p1 = Process(target=producer, args=('zzj2', '手机2', q))
c = Process(target=consumer,args=('zzp',q))
c1 = Process(target=consumer, args=('zzp2', q))
p.start()
p1.start()
c.daemon = True
c1.daemon = True
c1.start()
c.start()
p.join()
p1.join()
q.join()
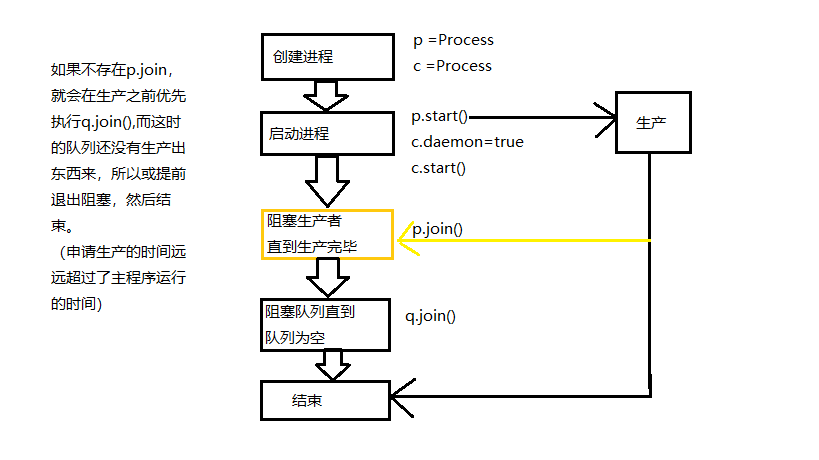
其工作流程如下:
1.首先创建两个生产者。
2.创建两个消费者。
3.开始所有工作,如果没有阻塞的情况,在下达生产的指令后,就立即结束主进程,消费者会随着守护进程一起与主进程结束,所以只有生产没有消费。
4.将生产者程序阻塞,当所有生产结束时,再执行以下代码,其中消费者在不断消费。
5.最后通过队列的阻塞,确保消费者消费了生产者的所有数据,再继续以下程序。
四。线程
1.什么是线程
进程:资源单位
线程:执行单位
将内存比如成工厂,那么进程就相当于是工厂里面的车间,而你的线程就相当于是车间里面的流水线
ps:每个进程都自带一个线程,线程才是真正的执行单位,进程只是在线程运行过程中提供代码运行所需要的资源
2.为什么要有线程
开进程
1.申请内存空间 耗资源
2."拷贝代码" 耗资源
开线程
一个进程内可以起多个线程,并且线程与线程之间数据是共享的
ps:开启线程的开销要远远小于开启进程的开销
五。如何使用线程
线程的使用方式与进程的使用相差无几,区别在于,线程可以不在main函数中使用,但是还是习惯于在main函数创建线程。
from threading import Thread
import time def text(name):
print('start%s'%name)
time.sleep(2)
print('end%s'%name) t = Thread(target=text,args=('lzx',))
t.start()
print('zhu')
#startlzx
#zhu
#endlzx
值得注意的是,在线程中,有很大概率先运行线程中的程序,因为线程的启动远比进程的启动早,所有会比主程序快一点。
线程中的一些方法
线程中的方法与进程中的方法有相似之处,他们的启动都是差不多。
import os
from threading import Thread,current_thread,active_count
import time def text(name):
print('start%s'%name)
print('子',current_thread().name)
print('子',os.getpid())
time.sleep(2)
print('end%s'%name) if __name__ == '__main__':
t = Thread(target=text,args=('lzx',))
t2 = Thread(target=text, args=('lzx1',))
print('主', current_thread().name)
print('主', os.getpid())
t.start()
t2.start()
print('当前运行线程的个数',active_count())
print('zhu') #主 MainThread
#主 28364
#startlzx
#子 Thread-1
#子 28364
#startlzx1
#子 Thread-2
#子 28364
#当前运行线程的个数 3
#zhu
#endlzx
#endlzx1
os.getpid()查看线程的线程号
current_thread()线程对象,可以通过name查看该线程的线程号。一个进程下的线程号都是一样的
active_count()查看当前正在运行的线程的个数。注意,主线程也是一个正在运行的线程
ps:线程没有主次之分。
六。守护线程
在线程中也有daemon方法,将线程设置成主线程的守护线程。
def text(name):
print('子线程%s'%name)
time.sleep(2)
print('end') t = Thread(target=text,args=('lzx',))
t.start()
print('主')
普通线程中,主线程总是会在子线程结束之后才会结束,除了守护线程
主线程的结束意味着进程的结束
(子线程在运行的时候需要使用进程中的资源,而主线程一旦结束了资源也就销毁了)
def text(name):
print('子线程%s'%name)
time.sleep(2)
print('end') t = Thread(target=text,args=('lzx',))
t.daemon = True
t.start()
print('主')
当一个线程需要较长的时间运行时(大于主线程的时间),而这个线程是一个守护线程,则它不会运行完。
如上,end就永远不会被打印。
七。线程之间的通信
from threading import Thread money = 666 def task():
global money
money = 999 t = Thread(target=task)
t.start()
t.join()
print(money)
在一个进程中,多个线程使用的是同一个数据,所以,线程与线程之间的数据是互通的。
使用join等待数据完完全全改变后打印该数据,发现它已经通过线程改变了。
八。互斥锁的应用
在线程中,也有互斥锁的概念,该功能是将并行操作变成串行操作。
import time
from threading import Thread,Lock n = 100 def text(sock):
global n
tmp = n
time.sleep(0.1)
n = tmp -1 t_list = []
sock = Lock()
for i in range(100):
t = Thread(target=text,args=(sock,))
t.start()
t_list.append(t) for i in t_list:
i.join() print(n)
上定义了100个线程,将所有线程启动后添加至线程列表,再将他们阻塞,也就是当所有的线程执行-操作结束后再输出结果
注意不能直接对原数据-1,否则会直接为0.
为了体现线程的并行性,可以对其先进行赋值tmp,再将元数据变成该值的-1
如果是串行操作,会直接为0。
结果显然不是,因为所有线程一起获得了数据100,0.1秒后再将100-1赋值给n,结果就是n被赋值99,100次。
加上锁后,就不会出现这样的效果。
import time
from threading import Thread,Lock n = 100 def text(sock):
global n
sock.acquire()
tmp = n
time.sleep(0.1)
n = tmp -1
sock.release() t_list = []
sock = Lock()
for i in range(100):
t = Thread(target=text,args=(sock,))
t.start()
t_list.append(t) for i in t_list:
i.join() print(n)
九。小例子
from threading import Thread
from multiprocessing import Process
import time
def foo():
print(123)
time.sleep(1)
print("end123") def bar():
print(456)
time.sleep(3)
print("end456") if __name__ == '__main__':
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon=True
t1.start()
t2.start()
print("main-------")
#
#
#main-------
#end123
#end456
day31_8.12并发编程二线程的更多相关文章
- Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 并发编程 13—— 线程池的使用 之 配置ThreadPoolExecutor 和 饱和策略
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- Java并发编程:线程池的使用(转)
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 六星经典CSAPP-笔记(12)并发编程(上)
六星经典CSAPP-笔记(12)并发编程(上) 1.并发(Concurrency) 我们经常在不知不觉间就说到或使用并发,但从未深入思考并发.我们经常能"遇见"并发,因为并发不仅仅 ...
- Java并发编程:线程池的使用(转载)
转载自:https://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- Java并发编程:线程池的使用(转载)
文章出处:http://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- [转]Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 【转】Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 19、Java并发编程:线程间协作的两种方式:wait、notify、notifyAll和Condition
Java并发编程:线程间协作的两种方式:wait.notify.notifyAll和Condition 在前面我们将了很多关于同步的问题,然而在现实中,需要线程之间的协作.比如说最经典的生产者-消费者 ...
随机推荐
- Centos7 yum安装MySQL5.7.25
1 下载并安装MySQL官方的 Yum Repository[root@localhost ~]# wget -i -c http://dev.mysql.com/get/mysql57-commun ...
- 原生javascript 共享onload事件
在工作时,我们给一个元素绑定了事件,如果dom还没加载完成,就执行了js代码,就不会绑定成功.常规解决方案就是用: window.onload = EventFunction; 可是如果有两个 事件, ...
- YY工具隐私政策
YY工具(以下简称“我们”)深知个人信息对您的重要性,并会尽全力保护您的个人信息安全可靠.我们致力于维持您对我们的信任,恪守以下原则,保护您的个人信息:权责一致原则.目的明确原则.选择同意原则.最少够 ...
- docker安装和配置Grafana
目录 安装 docker 启动 配置 配置域名和端口 配置ldap 配置邮箱 添加数据源 创建dashboard 配置alert 安装 docker 启动 先普通启动,然后把配置文件导出来,修改配置文 ...
- VOC数据集 目标检测
最近在做与目标检测模型相关的工作,很多都要求VOC格式的数据集. PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛, P ...
- C#,二分法,BinarySearch()
static int BinarySearch(int[] arr,int key,int low,int high) { low = 0;high = arr.Length - 1; while(l ...
- ASP.NET Core 进程外(out-of-process)托管
ASP.NET Core 进程外(out-of-process)托管 在本节中,我们将讨论 ASP.NET Core 中的Out Of Process Hosting. ASP.NET Core 进程 ...
- .net Dapper 学习系列(1) ---Dapper入门
目录 写在前面 为什么选择Dapper 在项目中安装Dapper 在项目中使用Dapper 在项目中使用Dapper 进行单表增删改数据操作 总结 写在前面 Dapper 是一款轻量级ORM架构.为解 ...
- Dev控件使用CheckedListBoxControl获取items.count为0 的解决方法
CheckedListBoxControl,我使用DataSource属性,给其绑定了一个List对象.界面显示都挺正常的,当若干个项的复选框被选中的后,它的checkedListBoxControl ...
- MySQL基础(三)(操作数据表中的记录)
1.插入记录INSERT 命令:,expr:表达式 注意:如果给主键(自动编号的字段)赋值的话,可以赋值‘NULL’或‘DEFAULT’,主键的值仍会遵守默认的规则:如果省略列名的话,所有的字段必须一 ...