Flink Flow

1. Create environment for stream computing
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().disableSysoutLogging();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.enableCheckpointing(5000); // create a checkpoint every 5 seconds
env.getConfig().setGlobalJobParameters(parameterTool); // make parameters available in the web interface
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
public static StreamExecutionEnvironment getExecutionEnvironment() {
if (contextEnvironmentFactory != null) {
return contextEnvironmentFactory.createExecutionEnvironment();
}
// because the streaming project depends on "flink-clients" (and not the other way around)
// we currently need to intercept the data set environment and create a dependent stream env.
// this should be fixed once we rework the project dependencies
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
if (env instanceof ContextEnvironment) {
return new StreamContextEnvironment((ContextEnvironment) env);
} else if (env instanceof OptimizerPlanEnvironment || env instanceof PreviewPlanEnvironment) {
return new StreamPlanEnvironment(env);
} else {
return createLocalEnvironment();
}
}
2. Now we need to add the data source for further computing
DataStream<KafkaEvent> input = env
.addSource( new FlinkKafkaConsumer010<>(
parameterTool.getRequired("input-topic"),
new KafkaEventSchema(),
parameterTool.getProperties()).assignTimestampsAndWatermarks(new CustomWatermarkExtractor()))
.keyBy("word")
.map(new RollingAdditionMapper());
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function) {
return addSource(function, "Custom Source");
}
@SuppressWarnings("unchecked")
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo) {
if (typeInfo == null) {
if (function instanceof ResultTypeQueryable) {
typeInfo = ((ResultTypeQueryable<OUT>) function).getProducedType();
} else {
try {
typeInfo = TypeExtractor.createTypeInfo(
SourceFunction.class,
function.getClass(), 0, null, null);
} catch (final InvalidTypesException e) {
typeInfo = (TypeInformation<OUT>) new MissingTypeInfo(sourceName, e);
}
}
}
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
StreamSource<OUT, ?> sourceOperator;
if (function instanceof StoppableFunction) {
sourceOperator = new StoppableStreamSource<>(cast2StoppableSourceFunction(function));
} else {
sourceOperator = new StreamSource<>(function);
}
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName);
}
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper) {
TypeInformation<R> outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(), true);
return transform("Map", outType, new StreamMap<>(clean(mapper)));
}
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operator,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({ "unchecked", "rawtypes" })
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
@Internal
public void addOperator(StreamTransformation<?> transformation) {
Preconditions.checkNotNull(transformation, "transformation must not be null.");
this.transformations.add(transformation);
}
protected final List<StreamTransformation<?>> transformations = new ArrayList<>();
public KeyedStream<T, Tuple> keyBy(String... fields) {
return keyBy(new Keys.ExpressionKeys<>(fields, getType()));
}
private KeyedStream<T, Tuple> keyBy(Keys<T> keys) {
return new KeyedStream<>(this, clean(KeySelectorUtil.getSelectorForKeys(keys,
getType(), getExecutionConfig())));
}
3. The data from data source will be streamed into Flink Distributed Computing Runtime and the computed result will be transfered to data Sink.
input.addSink( new FlinkKafkaProducer010<>(
parameterTool.getRequired("output-topic"),
new KafkaEventSchema(),
parameterTool.getProperties()));
public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// configure the type if needed
if (sinkFunction instanceof InputTypeConfigurable) {
((InputTypeConfigurable) sinkFunction).setInputType(getType(), getExecutionConfig());
}
StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction));
DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator);
getExecutionEnvironment().addOperator(sink.getTransformation());
return sink;
}
@Internal
public void addOperator(StreamTransformation<?> transformation) {
Preconditions.checkNotNull(transformation, "transformation must not be null.");
this.transformations.add(transformation);
}
protected final List<StreamTransformation<?>> transformations = new ArrayList<>();
4. The last step is to start executing.
env.execute("Kafka 0.10 Example");
The mapper computing template is defined as blow.
private static class RollingAdditionMapper extends RichMapFunction<KafkaEvent, KafkaEvent> {
private static final long serialVersionUID = 1180234853172462378L;
private transient ValueState<Integer> currentTotalCount;
@Override
public KafkaEvent map(KafkaEvent event) throws Exception {
Integer totalCount = currentTotalCount.value();
if (totalCount == null) {
totalCount = 0;
}
totalCount += event.getFrequency();
currentTotalCount.update(totalCount);
return new KafkaEvent(event.getWord(), totalCount, event.getTimestamp());
}
@Override
public void open(Configuration parameters) throws Exception {
currentTotalCount = getRuntimeContext().getState(new ValueStateDescriptor<>("currentTotalCount", Integer.class));
}
}
http://www.debugrun.com/a/LjK8Nni.html
Flink Flow的更多相关文章
- 在 Cloudera Data Flow 上运行你的第一个 Flink 例子
文档编写目的 Cloudera Data Flow(CDF) 作为 Cloudera 一个独立的产品单元,围绕着实时数据采集,实时数据处理和实时数据分析有多个不同的功能模块,如下图所示: 图中 4 个 ...
- Flink Internals
https://cwiki.apache.org/confluence/display/FLINK/Flink+Internals Memory Management (Batch API) In ...
- Peeking into Apache Flink's Engine Room
http://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html Join Processin ...
- Flink - Juggling with Bits and Bytes
http://www.36dsj.com/archives/33650 http://flink.apache.org/news/2015/05/11/Juggling-with-Bits-and-B ...
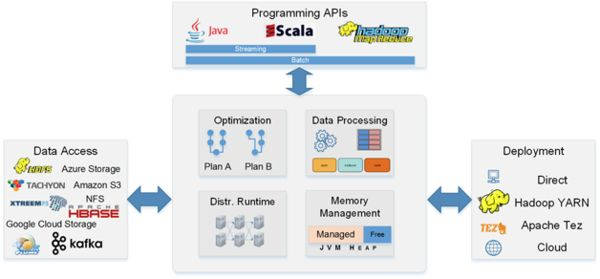
- Flink资料(3)-- Flink一般架构和处理模型
Flink一般架构和处理模型 本文翻译自General Architecture and Process Model ----------------------------------------- ...
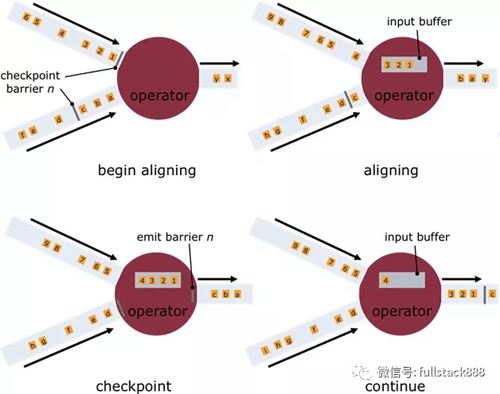
- Flink资料(2)-- 数据流容错机制
数据流容错机制 该文档翻译自Data Streaming Fault Tolerance,文档描述flink在流式数据流图上的容错机制. ------------------------------- ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- [Note] Apache Flink 的数据流编程模型
Apache Flink 的数据流编程模型 抽象层次 Flink 为开发流式应用和批式应用设计了不同的抽象层次 状态化的流 抽象层次的最底层是状态化的流,它通过 ProcessFunction 嵌入到 ...
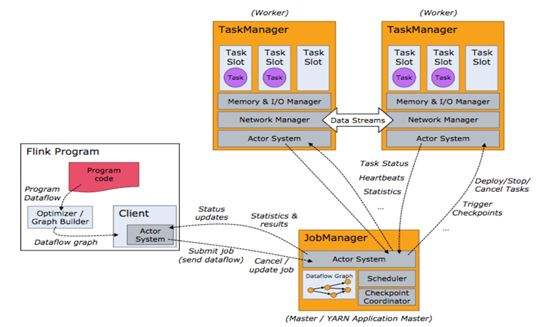
- Apache Flink 分布式执行
Flink 的分布式执行过程包含两个重要的角色,master 和 worker,参与 Flink 程序执行的有多个进程,包括 Job Manager,Task Manager 以及 Job Clien ...
随机推荐
- 安装Telerik JustMock插件后启动不成功
1.打开Telerik JustMock Configuration 勾选所有框 2.到C:\Program Files (x86)\Progress\Telerik JustMock\Librari ...
- 问题记录——com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
最近在搞一个Spring boot + Mybatis + Mysql的项目,用Mybatis访问数据库时,报了如下的错误,先在网上搜索了,试了各种办法都不行, 奇葩的是,连接另外1个数据库又没问题. ...
- EF 连接到 Azure-SQL
using Autofac; using Autofac.Integration.Mvc; using System; using System.Collections.Generic; using ...
- 【c++】常识易混提示
1. struct 和 class 唯一的区别:默认的成员保护级别和默认的派生保护级别不同(前者为public,后者为private). 2. int *p = new int[23]; de ...
- [LNMP]——LNMP环境配置
LNMP=Linux+Nginx+Mysql+PHP Install Nginx //安装依赖包 # yum install openssl openssl-devel zlib-devel //安装 ...
- CVE-2017-6920 Drupal远程代码执行漏洞学习
1.背景介绍: CVE-2017-6920是Drupal Core的YAML解析器处理不当所导致的一个远程代码执行漏洞,影响8.x的Drupal Core. Drupal介绍:Drupal 是一个由 ...
- FastReport打印table
经过验证是对的. table第一行添加标题,也就是拖过来的文本label,第二行开始绑定数据源的字段. 先设计报表的静态部分,再用代码注册数据源,然后设计,添加注册的数据源,绑定字段. var rep ...
- C# WinForm API 改进单实例运行
在普通的单实例中,第二次点击软件快捷方式的时候,往往简单提示"系统已经运行",而不是把第一次打开的软件主窗体显示出来,下面演示如果主窗体已经打开则把第一次打开的主窗体放置到最前面; ...
- Centos 从零开始 (二)
因为我是搞 nodejs的 所以以后会安装一些依赖于node的 比如mongodb数据库等. 6:安装nodejs 安装的时候遇到个小问题.yum install nodejs 报错 说没有这个包.然 ...
- access 2010
access 2010(表4.1---4.5) 数据表视图创建表:创建----改ID一行的内容(字段----格式----数据类型----格式----字段大小)----完成. 设计视图创建表:创建--- ...