Deep Learning基础--线性解码器、卷积、池化
本文主要是学习下Linear Decoder已经在大图片中经常采用的技术convolution和pooling,分别参考网页http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial中对应的章节部分。
Linear Decoders:
以三层的稀疏编码神经网络而言,在sparse autoencoder中的输出层满足下面的公式:
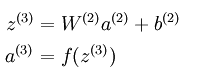
从公式中可以看出,a3的输出值是f函数的输出,而在普通的sparse autoencoder中f函数一般为sigmoid函数,所以其输出值的范围为(0,1),所以可以知道a3的输出值范围也在0到1之间。另外我们知道,在稀疏模型中的输出层应该是尽量和输入层特征相同,也就是说a3=x1,这样就可以推导出x1也是在0和1之间,那就是要求我们对输入到网络中的数据要先变换到0和1之间,这一条件虽然在有些领域满足,比如前面实验中的MINIST数字识别。但是有些领域,比如说使用了PCA Whitening后的数据,其范围却不一定在0和1之间。因此Linear Decoder方法就出现了。Linear Decoder是指在隐含层采用的激发函数是sigmoid函数,而在输出层的激发函数采用的是线性函数,比如说最特别的线性函数——等值函数。此时,也就是说输出层满足下面公式:

这样在用BP算法进行梯度的求解时,只需要更改误差点的计算公式而已,改成如下公式:
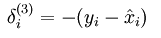
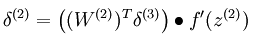
Convolution:
在了解convolution前,先认识下为什么要从全部连接网络发展到局部连接网络。在全局连接网络中,如果我们的图像很大,比如说为96*96,隐含层有要学习100个特征,则这时候把输入层的所有点都与隐含层节点连接,则需要学习10^6个参数,这样的话在使用BP算法时速度就明显慢了很多。
所以后面就发展到了局部连接网络,也就是说每个隐含层的节点只与一部分连续的输入点连接。这样的好处是模拟了人大脑皮层中视觉皮层不同位置只对局部区域有响应。局部连接网络在神经网络中的实现使用convolution的方法。它在神经网络中的理论基础是对于自然图像来说,因为它们具有稳定性,即图像中某个部分的统计特征和其它部位的相似,因此我们学习到的某个部位的特征也同样适用于其它部位。
下面具体看一个例子是怎样实现convolution的,假如对一张大图片Xlarge的数据集,r*c大小,则首先需要对这个数据集随机采样大小为a*b的小图片,然后用这些小图片patch进行学习(比如说sparse autoencoder),此时的隐含节点为k个。因此最终学习到的特征数为:
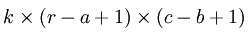
此时的convolution移动是有重叠的。
Pooling:
虽然按照convolution的方法可以减小不少需要训练的网络参数,比如说96*96,,100个隐含层的,采用8*8patch,也100个隐含层,则其需要训练的参数个数减小到了10^3,大大的减小特征提取过程的困难。但是此时同样出现了一个问题,即它的输出向量的维数变得很大,本来完全连接的网络输出只有100维的,现在的网络输出为89*89*100=792100维,大大的变大了,这对后面的分类器的设计同样带来了困难,所以pooling方法就出现了。
为什么pooling的方法可以工作呢?首先在前面的使用convolution时是利用了图像的stationarity特征,即不同部位的图像的统计特征是相同的,那么在使用convolution对图片中的某个局部部位计算时,得到的一个向量应该是对这个图像局部的一个特征,既然图像有stationarity特征,那么对这个得到的特征向量进行统计计算的话,所有的图像局部块应该也都能得到相似的结果。对convolution得到的结果进行统计计算过程就叫做pooling,由此可见pooling也是有效的。常见的pooling方法有max pooling和average pooling等。并且学习到的特征具有旋转不变性(这个原因暂时没能理解清楚)。
从上面的介绍可以简单的知道,convolution是为了解决前面无监督特征提取学习计算复杂度的问题,而pooling方法是为了后面有监督特征分类器学习的,也是为了减小需要训练的系统参数(当然这是在普遍例子中的理解,也就是说我们采用无监督的方法提取目标的特征,而采用有监督的方法来训练分类器)。
参考资料:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
http://www.cnblogs.com/tornadomeet/archive/2013/03/25/2980766.html
Deep Learning基础--线性解码器、卷积、池化的更多相关文章
- Deep Learning基础--理解LSTM/RNN中的Attention机制
导读 目前采用编码器-解码器 (Encode-Decode) 结构的模型非常热门,是因为它在许多领域较其他的传统模型方法都取得了更好的结果.这种结构的模型通常将输入序列编码成一个固定长度的向量表示,对 ...
- Deep Learning基础--CNN的反向求导及练习
前言: CNN作为DL中最成功的模型之一,有必要对其更进一步研究它.虽然在前面的博文Stacked CNN简单介绍中有大概介绍过CNN的使用,不过那是有个前提的:CNN中的参数必须已提前学习好.而本文 ...
- Deep Learning基础--参数优化方法
1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Preprocessing) ...
- tensorflow 卷积/反卷积-池化/反池化操作详解
Plese see this answer for a detailed example of how tf.nn.conv2d_backprop_input and tf.nn.conv2d_bac ...
- Deep Learning基础--26种神经网络激活函数可视化
在神经网络中,激活函数决定来自给定输入集的节点的输出,其中非线性激活函数允许网络复制复杂的非线性行为.正如绝大多数神经网络借助某种形式的梯度下降进行优化,激活函数需要是可微分(或者至少是几乎完全可微分 ...
- Deep Learning基础--各个损失函数的总结与比较
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好.损失函数是经验 ...
- Deep Learning基础--理解LSTM网络
循环神经网络(RNN) 人们的每次思考并不都是从零开始的.比如说你在阅读这篇文章时,你基于对前面的文字的理解来理解你目前阅读到的文字,而不是每读到一个文字时,都抛弃掉前面的思考,从头开始.你的记忆是有 ...
- (2)Deep Learning之线性单元和梯度下降
往期回顾 在上一篇文章中,我们已经学会了编写一个简单的感知器,并用它来实现一个线性分类器.你应该还记得用来训练感知器的『感知器规则』.然而,我们并没有关心这个规则是怎么得到的.本文通过介绍另外一种『感 ...
- Deep Learning基础--SVD奇异值分解
矩阵奇异值的物理意义是什么?如何更好地理解奇异值分解?下面我们用图片的例子来扼要分析. 矩阵的奇异值是一个数学意义上的概念,一般是由奇异值分解(Singular Value Decomposition ...
随机推荐
- bzoj1835[ZJOI2010]基站选址
主席树+决策单调,重写一遍比之前短多了……题解:http://www.cnblogs.com/liu-runda/p/6051422.html #include<cstdio> #incl ...
- [BZOJ4036] [HAOI2015]按位或
传送门:https://lydsy.com/JudgeOnline/problem.php?id=4036 Description 刚开始你有一个数字0,每一秒钟你会随机选择一个[0,2^n-1]的数 ...
- [洛谷P4900]食堂
题目大意:$n(n\leqslant10^6)$组询问,每组询问给出$l,r(l,r\leqslant10^6)$,求($\{\dfrac ij\}$表示$\dfrac ij$的小数部分): $$\s ...
- BZOJ2830 & 洛谷3830:[SHOI2012]随机树——题解
https://www.luogu.org/problemnew/show/P3830#sub <-题面看这里~ https://www.lydsy.com/JudgeOnline/prob ...
- BZOJ1090:[SCOI2003]字符串折叠——题解
http://www.lydsy.com/JudgeOnline/problem.php?id=1090 Description 折叠的定义如下: 1. 一个字符串可以看成它自身的折叠.记作S=S 2 ...
- BZOJ3709 [PA2014]Bohater 【贪心】
题目链接 BZOJ3709 题解 贪心很显然 我们先干掉能回血的怪,当然按照\(d\)升序顺序,因为打得越多血越多,\(d\)大的尽量往后打 然后再干掉会扣血的怪,当然按照\(a\)降序顺序,因为最后 ...
- BZOJ2761 不重复的数字 【treap】
2761: [JLOI2011]不重复数字 Time Limit: 10 Sec Memory Limit: 128 MB Submit: 5517 Solved: 2087 [Submit][S ...
- HDOJ.1342 Lotto (DFS)
Lotto [从零开始DFS(0)] 点我挑战题目 从零开始DFS HDOJ.1342 Lotto [从零开始DFS(0)] - DFS思想与框架/双重DFS HDOJ.1010 Tempter of ...
- rocketmq单机搭建
RocketMQ 是alibaba开源的消息队列. 本文使用的是开源版本v3.18 系统: centos6.x最小化安装 需要用到的软件包: jdk-7u67-linux-x64.tar.gz ali ...
- ZooKeeper管理员指南(九)
部署 这部分包含了部署ZooKeeper的信息和覆盖这些话题 系统要求 集群(多服务)安装 单服务和开发者安装 前两部分假定你对在例如数据中心的生产环境安装ZooKeeper有兴趣.最后一部分包含你在 ...