HTML文档解析和DOM树的构建
浏览器解析HTML文档生成DOM树的过程,以下是一段HTML代码,以此为例来分析解析HTML文档的原理
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<script src="script.js"></script>
<link rel="stylesheet" type="text/css" href="style.css">
<title></title>
</head>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>picture:</p>
<img src="example.png"/>
</div>
<div>
<p>A paragraph of explanatory text...</p>
</div>
</div>
</body>
</html>
豌豆资源搜索网站 https://55wd.com
浏览器解析HTML文档,在<head>中发现了<script>和<link>引入文件,于是向服务器请求文件,在请求和下载文件过程中将继续向下解析HTML,当引入文件下载完成后会通知浏览器回头来解析css和script文件。
如果浏览器在代码中发现一个<img>标签引用了一张图片,向服务器发出请求。此时浏览器同样不会等到图片下载完,而是继续渲染后面的代码;
现在进入正题,讲讲自己对解析HTML文档构建DOM树的理解:
此过程可分为两个主要模块构成,即
- 标签解析
- DOM树构建
1. 标签解析
这部分完成从HTML字符串中解析出标签的功能。主要使用标记化算法。
标记化算法的输入结果是HTML标记,使用状态机表示。状态机一共有4个状态:数据状态(Data)、标记打开状态(Tag open)、标记名称状态(Tag name)、关闭标记打开状态(Close tag open state)。
初始状态是数据状态。
当标记是处于数据状态时,
1)遇到字符<时,状态更改为“标记打开状态”:
a. 接收一个a-z字符会创建“起始标记”,状态更改为“标记名称状态”,并保持到接收>字符。此期间的字符串会形成一个新的标记名称。接收到>标记后,将当前的新标记发送给树构造器,状态改回“数据状态”
b. 接收下一个输入字符/时,会创建关闭标记打开状态,并更改为“标记名称状态”。直到接收>字符,将当前的新标记发送给树构造器,并改回“数据状态”。
2)遇到a-z字符时,会将每个字符创建成字符标记,并发送给树构造器。
2. DOM树构建
当标签解析器解析出标签后会发送到DOM树构建器,我们可以认为DOM树构建器主要有以下两部分组成:
- DOM树
- 一个存放标签名的栈
用如下代码演示生成DOM树的过程:
<html>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>picture:</p>
<img src="example.png"/>
</div>
<div>
<p>A paragraph of explanatory text...</p>
</div>
</div>
</body>
</html>
<span><span class="tag"></span></span>
首先树构建器接收到标签解析器发来的起始标签名后,会加入到栈中,图1是解析到<h1>标签的栈中压入的内容,共有<html><body><h1>三个标签,此时还未向DOM树中添加任何结点(图中黑色实线框代表开始标签,红色虚线框代表结束标签,结束标签不会入栈)。
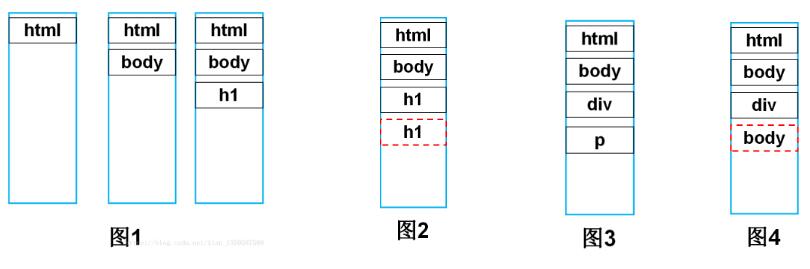
继续向下解析,接收到一个</h1>结束标签,此时查询栈顶元素,如果和传入的结束标签属于同种类型的p标签(如图2),则将栈顶元素弹出,向DOM树中加入此节点,然后继续向下解析(如图3)。
如果遇到的是没有封闭标签的元素如<img/>,则直接加入DOM树中即可,无需入栈。
依次向下解析,当栈为空,即<html>根节点也加入到DOM树中,DOM树构建完毕。
这里需要指出的是,当某个元素缺失结束标签时,假如上述代码中第一个<div>标签缺失了</div>结束标签,即:
<html>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>picture:</p>
<img src="example.png"/>
</div>
<div>
<p>A paragraph of explanatory text...</p>
</div> </body>
</html>
那么,此时的栈如图4所示。即此时传来的结束标签是</body>,而栈顶元素是<div>,两者不是同一种标签,说明div缺少了结束标签,这种情况也将栈顶<div>元素弹出,加入到DOM树中。相当于给<div>补了一个</div>结束标签。
HTML文档解析和DOM树的构建的更多相关文章
- JavaScript : DOM文档解析详解
JavaScript DOM 文档解析 1.节点(node):来源于网络理论,代表网络中的一个连接点.网络是由节点构成的集合 <p title=“a gentle reminder”> ...
- 第一百一十三节,JavaScript文档对象,DOM基础
JavaScript文档对象,DOM基础 学习要点: 1.DOM介绍 2.查找元素 3.DOM节点 4.节点操作 DOM(Document Object Model)即文档对象模型,针对HTML和XM ...
- iOS网络编程笔记——XML文档解析
今天利用多余时间研究了一下XML文档解析,虽然现在移动端使用的数据格式基本为JSON格式,但是XML格式毕竟多年来一直在各种计算机语言之间使用,是一种老牌的经典的灵活的数据交换格式.所以我认为还是很有 ...
- Android XML文档解析(一)——SAX解析
---------------------------------------------------------------------------------------------------- ...
- 第一百一十四节,JavaScript文档对象,DOM进阶
JavaScript文档对象,DOM进阶 学习要点: 1.DOM类型 2.DOM扩展 3.DOM操作内容 DOM自身存在很多类型,在DOM基础课程中大部分都有所接触,比如Element类型:表示的是元 ...
- ios-XML文档解析之SAX解析
首先SAX解析xml *xml文档的格式特点是节点,大体思路是把每个最小的子节点作为对象的属性,每个最小子节点的'父'节点作为对象,将节点转化为对象,输出. 每个节点都是成对存在的,有开始有结束.有始 ...
- jsoup -- xml文档解析
jsoup -- xml文档解析 修改 https://jsoup.org/cookbook/modifying-data/set-attributes https://jsoup.org/cookb ...
- (二)发布第一个WebService服务与DSWL文档解析
1. 编写接口 package service; import javax.jws.WebService; /** * 第一个webservice服务, * @WebService注解表示这是一个we ...
- 读取EXCEL文档解析工具类
package test;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException ...
随机推荐
- Java实现 蓝桥杯 算法提高 成绩排序
试题 算法提高 成绩排序 资源限制 时间限制:1.0s 内存限制:256.0MB 问题描述 给出n个学生的成绩,将这些学生按成绩排序, 排序规则,优先考虑数学成绩,高的在前:数学相同,英语高的在前:数 ...
- CGLIB动态代理机制,各个方面都有写到
CGLIB库介绍 代理提供了一个可扩展的机制来控制被代理对象的访问,其实说白了就是在对象访问的时候加了一层封装.JDK从1.3版本起就提供了一个动态代理,它使用起来非常简单,但是有个明显的缺点:需要目 ...
- 给Linux小白的CentOS8.1基本安装说明
写在前面的话:用过Linux的同学应该都会觉得Linux安装是件非常简单的事情,根本不值得用博客记下来!但是我发现,其实没接触过Linux的同学还真不一定会装,就像在IT行业工作过几年但一直用Wind ...
- 聊一聊高并发高可用那些事 - Kafka篇
目录 为什么需要消息队列 1.异步 :一个下单流程,你需要扣积分,扣优惠卷,发短信等,有些耗时又不需要立即处理的事,可以丢到队列里异步处理. 2.削峰 :按平常的流量,服务器刚好可以正常负载.偶尔推出 ...
- Koa源码解析,带你实现一个迷你版的Koa
前言 本文是我在阅读 Koa 源码后,并实现迷你版 Koa 的过程.如果你使用过 Koa 但不知道内部的原理,我想这篇文章应该能够帮助到你,实现一个迷你版的 Koa 不会很难. 本文会循序渐进的解析内 ...
- 循序渐进VUE+Element 前端应用开发(9)--- 界面语言国际化的处理
我们开发的系统,一般可以不用考虑语言国际化的问题,大多数系统一般是给本国人使用的,而且直接使用中文开发界面会更加迅速 一些,不过框架最好能够支持国际化的处理,以便在需要的时候,可以花点时间来实现多语言 ...
- 使用 UniApp 实现小程序的微信登录
微信登录思路: 在main.js 中封装公共函数,用于判断用户是否登录 在main.js 中分定义全局变量,用于存储接口地址 如果没有登录.则跳转至登录页面 进入登录页面 通过 wx.login 获取 ...
- 3.vue计算属性
1.计算属性 再vue中如果出现表达式过长或者逻辑比较复杂,这时会导致代码不清晰,臃肿,难以维护所以我们会使用计算属性进行书写 再计算属性中可以放负责的逻辑,可以是函数,表达式等,但最终会返回一个 ...
- Uint47 calculator【map数组+快速积+各种取余公式】
Uint47 calculator 题目链接(点击) In the distant space, there is a technologically advanced planet. One day ...
- 淘宝官网css初始化
body, h1, h2, h3, h4, h5, h6, hr, p, blockquote, dl, dt, dd, ul, ol, li, pre, form, fieldset, legend ...