字符串编码研究:Unicode
Unicode
Unicode 编码系统可分为编码方式和实现方式两个层次。
1、编码方式
Unicode字符平面映射定义了所有的Unicode字符集。
2、实现方式(UTF8,UTF16)
UTF-8使用一至六个字节为每个字符编码(尽管如此,2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,也就是说最多四个字节):
- 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
- 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要两个字节编码(Unicode范围由U+0080至U+07FF)。
- 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字,如大部分的汉字)使用三个字节编码(Unicode范围由U+0800至U+FFFF)。
- 其他极少使用的Unicode 辅助平面的字符使用四至六字节编码(Unicode范围由U+10000至U+1FFFFF使用四字节,Unicode范围由U+200000至U+3FFFFFF使用五字节,Unicode范围由U+4000000至U+7FFFFFFF使用六字节
- UTF8为了兼容ASNI所要付出的代价,请查看上表,UTF8下是完全兼容asni,也就是asni标准的下的文档,在UTF8下显示完全不是问题(因为ASNI存储字节值和UTF8是一样的)。字符都是一个一个字节存储的,UTF8肯定是一个一个字节的读取,那么UTF8怎么在完全兼容ASNI前提下,是怎么知道某个字符是需要额外字节信息的?UTF8只有固定前几位二进制来决定这个字符需要以后的几个字节,又因为为了兼容ASNI,所以额外字节也需要固定前2位"10xxxxxx",来决定这个字节值不是代表ASNI字符。ASNI的格式是“0xxxxxxx”。
3、UTF-8编码字节含义
- 对于UTF-8编码中的任意字节B,如果B的第一位为0,则B独立的表示一个字符(ASCII码);
- 如果B的第一位为1,第二位为0,则B为一个多字节字符中的一个字节(非ASCII字符);
- 如果B的前两位为1,第三位为0,则B为两个字节表示的字符中的第一个字节;
- 如果B的前三位为1,第四位为0,则B为三个字节表示的字符中的第一个字节;
- 如果B的前四位为1,第五位为0,则B为四个字节表示的字符中的第一个字节;
因此,对UTF-8编码中的任意字节,根据第一位,可判断是否为ASCII字符;根据前二位,可判断该字节是否为一个字符编码的第一个字节;根据前四位(如果前两位均为1),可确定该字节为字符编码的第一个字节,并且可判断对应的字符由几个字节表示;根据前五位(如果前四位为1),可判断编码是否有错误或数据传输过程中是否有错误。
4、UTF-8的设计有以下的多字符组序列的特质:
- 单字节字符的最高有效比特永远为0。
- 多字节序列中的首个字符组的几个最高有效比特决定了序列的长度。最高有效位为
110的是2字节序列,而1110的是三字节序列,如此类推。 - 多字节序列中其余的字节中的首两个最高有效比特为
10。

5、UTF16

UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节(2字节)存储,但UTF-16却无法兼容于ASCII编码。
6、字节顺序标记(BOM)
在UTF-8+BOM格式文件的开首,很多时都放置一个U+FEFF字符(UTF-8以EF,BB,BF代表),以显示这个文本文件是以UTF-8编码。
不知道你有没有注意到,在UTF16下的这张图,地址第0,第1位是"FF FE"

对应的UTF8如下:

这就是BOM,通过FF FE或者FE FF来告诉解释器是那种字节序。
那么你也许会问,为什么UTF8没有字节序呢?那是因为UTF8是以字节为单位,一个一个字节读取。UTF16是以字为单位,一个一个字符(2个字节或者4个字节)读取,这样就会涉及先读取第一个或者第二个字节的情况。
希望这篇文章从存储字节角度看UTF8和UTF16会为给你带来不一样的感觉。
7、 Example


确实是一致的,但是这个UTF8的码是如何算出来的呢?
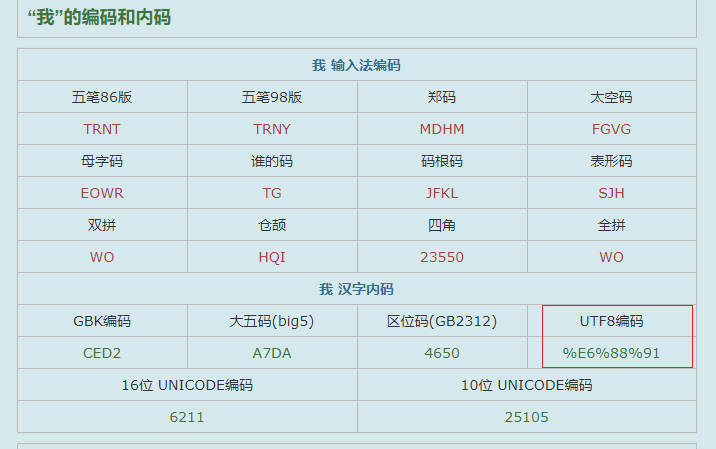
通过计算器可以看到,25105确实按照上表的方式编码为了UTF8

但是如果让我来写底层实现这个转换的代码?应该如何写呢?
windows下多字节和宽字节转换
多字节和宽字节
多字节是指使用多个字节(1-3)表示一个字符。比如gbk使用英文占一个字节,中文占2个,这个就是多字节了。utf-8是使用1-3个字节表示字符。还有big5等等。
宽字节一般是固定使用2个字节表示一个字符,utf-16(一般就是指unicode)。
1、MultiByteToWideChar 多字节转宽字节
2、WideCharToMultiByte 宽字节转多字节
3、和utf8有关的字符转换,代码页CodePage=CP_UTF8。
4、代码页CodePage=CP_ACP,一般使用系统当前使用的代码页。比如在简体中文(中国等)区域下,CP_ACP表示gbk编码的936代码页。在繁体中文(台湾),CP_ACP表示big5编码的950代码页。

5、CodePage代码页一般填写的是多字节代码页。
在程序中,一般最好使用unicode字符集显示字符,Windows的内核就是用unicode编码的,unicode字符集包含了世上大多数字符。unicode在windows下的不同本地环境下都能是正常显示。
但是在使用字符串和其他程序进程(本地进程或者远端进程)进行交互时,最好使用utf8编码字符。
原因是:utf8可以表示最多的字符,所有系统通用,且不像宽字节一样每个字符都要两个字节表示,数字和字母等都是使用一个字节表示,有时可以节省大量字符串流。
Tips: Vs显示Debug窗口显示字符的时候,应该是使用系统代码页进行解码,所有UTF8无法正常展示
“我是谁“存储的就是字符的Unicode的16位编码。


现在我将“我是谁”转换为Windows的多字节,注意这个地方展示的编码方式是CP_ACP, 也就是采用GBK编码, 可以看到Vs的监视窗口是可以展示这个字符串的。

但是如果采用CP_UTF8,就无法正确显示字符。

所以问题就清楚了VS的调试器的监视窗口:
1、如果是宽字节可以正常展示;
2、如果是多字节, 编码是GBK也就是和当前系统的代码页一致,就可以显示,如果是UTF8则是乱码;
3、Notepad++也是根据编码方式获得对应的Unicode码,然后在从字符集里面取出对应的字行进行展示的;
Reference
字符串编码研究:Unicode的更多相关文章
- 字符串 编码 utf-8 unicode asicc
http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/00138681919628358 ...
- Python字符串编码——Unicode
ASCII码 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串.每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte).也就是 ...
- python知识:json格式文本;异常处理;字符串处理;unicode类型和str类型转换
python进程中的实例和json格式的字符串之间的映射关系是非常直接的,相当于同一个概念被编码成不同的表示: stream in json form ----json.loads(str)----- ...
- js 字符串编码转换函数
escape 方法 对 String 对象编码以便它们能在所有计算机上可读, escape(charString) 必选项 charstring 参数是要编码的任意 String 对象或文字. 说明 ...
- 一篇文章助你理解Python2中字符串编码问题
前几天给大家介绍了unicode编码和utf-8编码的理论知识,没来得及上车的小伙伴们可以戳这篇文章:浅谈unicode编码和utf-8编码的关系.下面在Python2环境中进行代码演示,分别Wind ...
- decode 函数将字符串从某种编码转为 unicode 字符
环境:Ubuntu, Python 2.7 基础知识 这个程序涉及到的知识点有几个,在这里列出来,不详细讲,有疑问的直接百度会有一堆的. 1.urllib2 模块的 request 对像来设置 HTT ...
- String 字符串中含有 Unicode 编码时,转为UTF-8
1.单纯的Unicode 转码 String a = "\u53ef\u4ee5\u6ce8\u518c"; a = new String(a.getBytes("UTF ...
- python3 之 字符串编码小结(Unicode、utf-8、gbk、gb2312等)
python3 解释器默认编码为Unicode,由str类型进行表示.二进制数据使用byte类型表示. 字符串通过编码转换成字节串,字节码通过解码成为字符串. encode:str-->byte ...
- python中的字符串编码问题——2.理解ASCII码、ANSI码、Unicode编码、UTF-8编码
ASCII码:全名是American Standard Code for Information Interchange,ASCII码中,一个英文字母(不分大小写)占一个字节的空间,范围0x00~0x ...
随机推荐
- 使用JavaScript实现一个简单的编译器
在前端开发中也会或多或少接触到一些与编译相关的内容,常见的有 将ES6.7代码编译成ES5的代码 将SCSS.LESS代码转换成浏览器支持的CSS代码 通过uglifyjs.uglifycss等工具压 ...
- maven杂碎汇总
本来是想写一篇关于maven知识点的详细总结的,但需要看一本书或教材,然后再汇总一下,这样做自然是好的,这个在年前争取做完.本文是主要记录在工作和学习遇到关于maven的一些困惑.很乐意看到它 ...
- qq群的表设计探究
2018年3月21日 课题组管理就如qq的群是一样的,课题组有课题组组长:qq群有群主:课题组有组员:qq群有群人员 对于一个课题组来说,组长可以对课题组进行修改,组员只能看得见,但是不能修改.所以 ...
- 配置gem5-gpu docker版
1 安装docker:wget -qO- https://get.docker.com/ | sh,启动服务:sudo service docker start 2 把非root用户添加到docker ...
- yolov3测试自己的数据
yolov3测试自己的数据 前言 上一篇我已经介绍了利用yolov3预训练权重文件(只包含卷积层)并训练 只需要进行如下编译: ./darknet detector train cfg/voc.dat ...
- UVA - 12166 Equilibrium Mobile (修改天平)(dfs字符串表示的二叉树)
题意:问使天平平衡需要改动的最少的叶子结点重量的个数. 分析:天平达到平衡总会有个重量,这个重量可以由某个叶子结点的重量和深度直接决定. 如下例子: 假设根结点深度为0,结点6深度为1,若以该结点为基 ...
- 指令——df
df是disk free 的简称,这个指令的功能和作用是查看磁盘空间. 可以加上 -h 的选项,来提高可读性. [he@localhost ~]$ df -h文件系统(磁盘名称) 总容量 ...
- hadoop解决windows下:Failed to set permissions of path: \tmp\ \.staging to 0700
17/04/24 15:32:44 WARN util.NativeCodeLoader: Unable to load native-Hadoop library for your platform ...
- VUE- 异步等待方法嵌套
VUE- 异步等待方法嵌套 vue在一个方法执行完后执行另一个方法用Promise来实现.Promise是ES6的新特性,用于处理异步操作逻辑,用过给Promise添加then和catch函数,处理成 ...
- Flink 笔记(一)
简介 Flink是一个低延迟.高吞吐.统一的大数据计算引擎, Flink的计算平台可以实现毫秒级的延迟情况下,每秒钟处理上亿次的消息或者事件. 同时Flink提供了一个Exactly-once的一致性 ...