【tensorflow2.0】处理图片数据-cifar2分类
1、准备数据
cifar2数据集为cifar10数据集的子集,只包括前两种类别airplane和automobile。
训练集有airplane和automobile图片各5000张,测试集有airplane和automobile图片各1000张。
cifar2任务的目标是训练一个模型来对飞机airplane和机动车automobile两种图片进行分类。
我们准备的Cifar2数据集的文件结构如下所示。

在tensorflow中准备图片数据的常用方案有两种,第一种是使用tf.keras中的ImageDataGenerator工具构建图片数据生成器。
第二种是使用tf.data.Dataset搭配tf.image中的一些图片处理方法构建数据管道。
第一种方法更为简单,其使用范例可以参考以下文章。
https://zhuanlan.zhihu.com/p/67466552
第二种方法是TensorFlow的原生方法,更加灵活,使用得当的话也可以获得更好的性能。
我们此处介绍第二种方法。
import tensorflow as tf
from tensorflow.keras import datasets,layers,models BATCH_SIZE = 100 def load_image(img_path,size = (32,32)):
label = tf.constant(1,tf.int8) if tf.strings.regex_full_match(img_path,".*/automobile/.*") \
else tf.constant(0,tf.int8)
img = tf.io.read_file(img_path)
img = tf.image.decode_jpeg(img) #注意此处为jpeg格式
img = tf.image.resize(img,size)/255.0
return(img,label) # 使用并行化预处理num_parallel_calls 和预存数据prefetch来提升性能
ds_train = tf.data.Dataset.list_files("./data/cifar2/train/*/*.jpg") \
.map(load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE) \
.shuffle(buffer_size = 1000).batch(BATCH_SIZE) \
.prefetch(tf.data.experimental.AUTOTUNE) ds_test = tf.data.Dataset.list_files("./data/cifar2/test/*/*.jpg") \
.map(load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE) \
.batch(BATCH_SIZE) \
.prefetch(tf.data.experimental.AUTOTUNE)

for x,y in ds_train.take(1):
print(x.shape,y.shape)
(100, 32, 32, 3) (100,)
2、定义模型
使用Keras接口有以下3种方式构建模型:使用Sequential按层顺序构建模型,使用函数式API构建任意结构模型,继承Model基类构建自定义模型。
此处选择使用函数式API构建模型。
tf.keras.backend.clear_session() #清空会话 inputs = layers.Input(shape=(32,32,3))
x = layers.Conv2D(32,kernel_size=(3,3))(inputs)
x = layers.MaxPool2D()(x)
x = layers.Conv2D(64,kernel_size=(5,5))(x)
x = layers.MaxPool2D()(x)
x = layers.Dropout(rate=0.1)(x)
x = layers.Flatten()(x)
x = layers.Dense(32,activation='relu')(x)
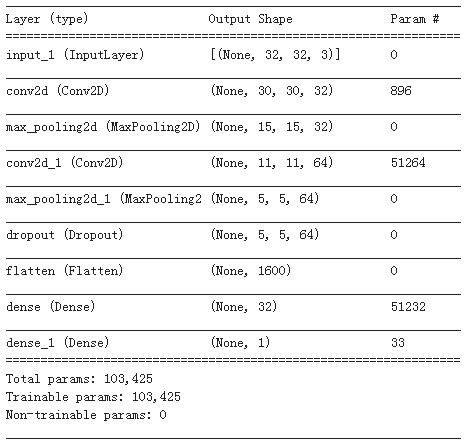
outputs = layers.Dense(1,activation = 'sigmoid')(x) model = models.Model(inputs = inputs,outputs = outputs) model.summary()
3、训练模型
训练模型通常有3种方法,内置fit方法,内置train_on_batch方法,以及自定义训练循环。此处我们选择最常用也最简单的内置fit方法。
import datetime
logdir = "./data/keras_model/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.binary_crossentropy,
metrics=["accuracy"]
)
history = model.fit(ds_train,epochs= 10,validation_data=ds_test,
callbacks = [tensorboard_callback],workers = 4)
Epoch 1/10
100/100 [==============================] - 2205s 22s/step - loss: 0.4632 - accuracy: 0.7786 - val_loss: 0.3375 - val_accuracy: 0.8620
Epoch 2/10
100/100 [==============================] - 11s 110ms/step - loss: 0.3346 - accuracy: 0.8565 - val_loss: 0.2617 - val_accuracy: 0.8965
Epoch 3/10
100/100 [==============================] - 11s 111ms/step - loss: 0.2687 - accuracy: 0.8883 - val_loss: 0.2183 - val_accuracy: 0.9165
Epoch 4/10
100/100 [==============================] - 11s 110ms/step - loss: 0.2171 - accuracy: 0.9128 - val_loss: 0.1811 - val_accuracy: 0.9280
Epoch 5/10
100/100 [==============================] - 11s 114ms/step - loss: 0.1860 - accuracy: 0.9268 - val_loss: 0.1798 - val_accuracy: 0.9265
Epoch 6/10
100/100 [==============================] - 11s 112ms/step - loss: 0.1646 - accuracy: 0.9358 - val_loss: 0.1818 - val_accuracy: 0.9260
Epoch 7/10
100/100 [==============================] - 11s 113ms/step - loss: 0.1443 - accuracy: 0.9426 - val_loss: 0.1740 - val_accuracy: 0.9290
Epoch 8/10
100/100 [==============================] - 11s 113ms/step - loss: 0.1301 - accuracy: 0.9469 - val_loss: 0.1635 - val_accuracy: 0.9325
Epoch 9/10
100/100 [==============================] - 11s 112ms/step - loss: 0.1096 - accuracy: 0.9585 - val_loss: 0.1758 - val_accuracy: 0.9315
Epoch 10/10
100/100 [==============================] - 11s 113ms/step - loss: 0.0961 - accuracy: 0.9628 - val_loss: 0.1595 - val_accuracy: 0.9415
4、评估模型
# %load_ext tensorboard
# %tensorboard --logdir ./data/keras_model
from tensorboard import notebook
notebook.list()
# 在tensorboard中查看模型
notebook.start("--logdir ./data/keras_model")

或者我们自己绘图:首先我们构造数据
import pandas as pd
dfhistory = pd.DataFrame(history.history)
dfhistory.index = range(1,len(dfhistory) + 1)
dfhistory.index.name = 'epoch'
dfhistory

然后绘制:
%matplotlib inline
%config InlineBackend.figure_format = 'svg' import matplotlib.pyplot as plt def plot_metric(history, metric):
train_metrics = history.history[metric]
val_metrics = history.history['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(history,"loss")
plot_metric(history,"accuracy")


评估模型:
# 可以使用evaluate对数据进行评估
val_loss,val_accuracy = model.evaluate(ds_test,workers=4)
print(val_loss,val_accuracy)
20/20 [==============================] - 2s 80ms/step - loss: 0.1595 - accuracy: 0.9415
0.15954092144966125 0.9415000081062317
5、使用模型
可以使用model.predict(ds_test)进行预测。
也可以使用model.predict_on_batch(x_test)对一个批量进行预测。
model.predict(ds_test)
array([[1.1052408e-01],
[3.4282297e-02],
[2.7046111e-04],
...,
[2.7544077e-03],
[3.4654222e-04],
[9.9993896e-01]], dtype=float32)
for x,y in ds_test.take(1):
print(model.predict_on_batch(x[0:20]))
[[9.8728174e-01]
[2.0267103e-02]
[9.0806475e-03]
[9.9996555e-01]
[4.5376007e-02]
[1.2818890e-03]
[1.8698535e-03]
[2.2900696e-03]
[8.6169255e-01]
[6.2768459e-06]
[1.2383183e-02]
[4.3949869e-02]
[7.9778886e-01]
[9.9822074e-01]
[9.9993134e-01]
[8.6685091e-02]
[3.7480664e-02]
[9.9652690e-01]
[9.2210865e-01]
[1.6160560e-03]]
6、保存模型
推荐使用TensorFlow原生方式保存模型。
# 保存权重,该方式仅仅保存权重张量
model.save_weights('./data/tf_model_weights.ckpt',save_format = "tf")
# 保存模型结构与模型参数到文件,该方式保存的模型具有跨平台性便于部署 model.save('./data/tf_model_savedmodel', save_format="tf")
print('export saved model.') model_loaded = tf.keras.models.load_model('./data/tf_model_savedmodel')
model_loaded.evaluate(ds_test)
参考:
开源电子书地址:https://lyhue1991.github.io/eat_tensorflow2_in_30_days/
GitHub 项目地址:https://github.com/lyhue1991/eat_tensorflow2_in_30_days
【tensorflow2.0】处理图片数据-cifar2分类的更多相关文章
- 【tensorflow2.0】数据管道dataset
如果需要训练的数据大小不大,例如不到1G,那么可以直接全部读入内存中进行训练,这样一般效率最高. 但如果需要训练的数据很大,例如超过10G,无法一次载入内存,那么通常需要在训练的过程中分批逐渐读入. ...
- colab上基于tensorflow2.0的BERT中文多分类
bert模型在tensorflow1.x版本时,也是先发布的命令行版本,随后又发布了bert-tensorflow包,本质上就是把相关bert实现封装起来了. tensorflow2.0刚刚在2019 ...
- 【tensorflow2.0】处理结构化数据-titanic生存预测
1.准备数据 import numpy as np import pandas as pd import matplotlib.pyplot as plt import tensorflow as t ...
- 【tensorflow2.0】处理时间序列数据
国内的新冠肺炎疫情从发现至今已经持续3个多月了,这场起源于吃野味的灾难给大家的生活造成了诸多方面的影响. 有的同学是收入上的,有的同学是感情上的,有的同学是心理上的,还有的同学是体重上的. 那么国内的 ...
- [TensorFlow2.0]-手写神经网络实现鸢尾花分类
本人人工智能初学者,现在在学习TensorFlow2.0,对一些学习内容做一下笔记.笔记中,有些内容理解可能较为肤浅.有偏差等,各位在阅读时如有发现问题,请评论或者邮箱(右侧边栏有邮箱地址)提醒. 若 ...
- Google工程师亲授 Tensorflow2.0-入门到进阶
第1章 Tensorfow简介与环境搭建 本门课程的入门章节,简要介绍了tensorflow是什么,详细介绍了Tensorflow历史版本变迁以及tensorflow的架构和强大特性.并在Tensor ...
- TensorFlow2.0(11):tf.keras建模三部曲
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 一文上手Tensorflow2.0之tf.keras(三)
系列文章目录: Tensorflow2.0 介绍 Tensorflow 常见基本概念 从1.x 到2.0 的变化 Tensorflow2.0 的架构 Tensorflow2.0 的安装(CPU和GPU ...
- tensorflow2.0学习笔记
今天我们开始学习tensorflow2.0,用一种简单和循循渐进的方式,带领大家亲身体验深度学习.学习的目录如下图所示: 1.简单的神经网络学习过程 1.1张量生成 1.2常用函数 1.3鸢尾花数据读 ...
随机推荐
- JZOJ 5328. 【NOIP2017提高A组模拟8.22】世界线
5328. [NOIP2017提高A组模拟8.22]世界线 (File IO): input:worldline.in output:worldline.out Time Limits: 1500 m ...
- JZOJ 5305. 【NOIP2017提高A组模拟8.18】C (Standard IO)
5305. [NOIP2017提高A组模拟8.18]C (Standard IO) Time Limits: 1000 ms Memory Limits: 131072 KB Description ...
- Tomcat服务自动启动以隐藏start.bat命令窗口
该方法注意先要配置好CATALINA_HOME和path等环境变量.接着主要命令有:cmd命令符下进入tomcat/bin目录,输入:service.bat install (自定义的tomcat版本 ...
- 关于使用layui中的tree的一个坑
最近几天,因为项目需要,所以自学了下layui,在使用之前就对其比较感兴趣,毕竟封装的东西也不错(个人见解),在接触到layui之后,现在有个需要就是将部门做成tree的样子,开始觉得不怎么难,毕竟都 ...
- CORS(cross-origin-resource-sharing)跨源资源共享
其实就是跨域请求.我们知道XHR只能访问同一个域中的资源,这是浏览器的安全策略所限制,但是开发中合理的跨域请求是必须的.CORS是W3的一个工作草案,基本思想就是:使用自定义的HTTP头部让浏览器与服 ...
- redis 出现(error) MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details
如果在ubuntu安装的redis含端口使用,但是某些时候常常出现 (error) MISCONF Redis is configured to save RDB snapshots, but is ...
- iview admin template 基础模板架子
https://github.com/iview/iview-admin/tree/template
- Kafka 详解(转)
转载自:https://blog.csdn.net/lingbo229/article/details/80761778 Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区 ...
- Java并发编程之验证volatile不能保证原子性
Java并发编程之验证volatile不能保证原子性 通过系列文章的学习,凯哥已经介绍了volatile的三大特性.1:保证可见性 2:不保证原子性 3:保证顺序.那么怎么来验证可见性呢?本文凯哥(凯 ...
- java -输入年龄判断是否符合范围。
//创建的一个包名. package demo3; //定义一个类. public class Test { //公共静态的主方法. public static void main(String[] ...