pandas速成笔记(4)-数据图表
接上篇继续,做数据分析,各种数据图表是必不可少的,还是以下面这张表为例:
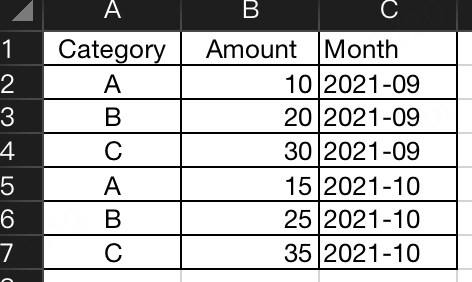
一、单列柱状图
假设要把9月份,A、B这2个分类的Amount提取出来画一个柱状图,可以这么做:
import pandas as pd
import matplotlib.pyplot as plt df = pd.read_excel("./data/test.xlsx") # 过滤出9月份的,A,B二个分类的数据
df = df.loc[df.Month.apply(lambda m: m == '2021-09')] \
.loc[df.Category.apply(lambda c: c in ['A', 'B'])] # 如果希望柱状图按从高到低排好,必须先把数据排好序
df.sort_values(by="Amount", inplace=True, ascending=False) # 用DataFrame的plot来绘图
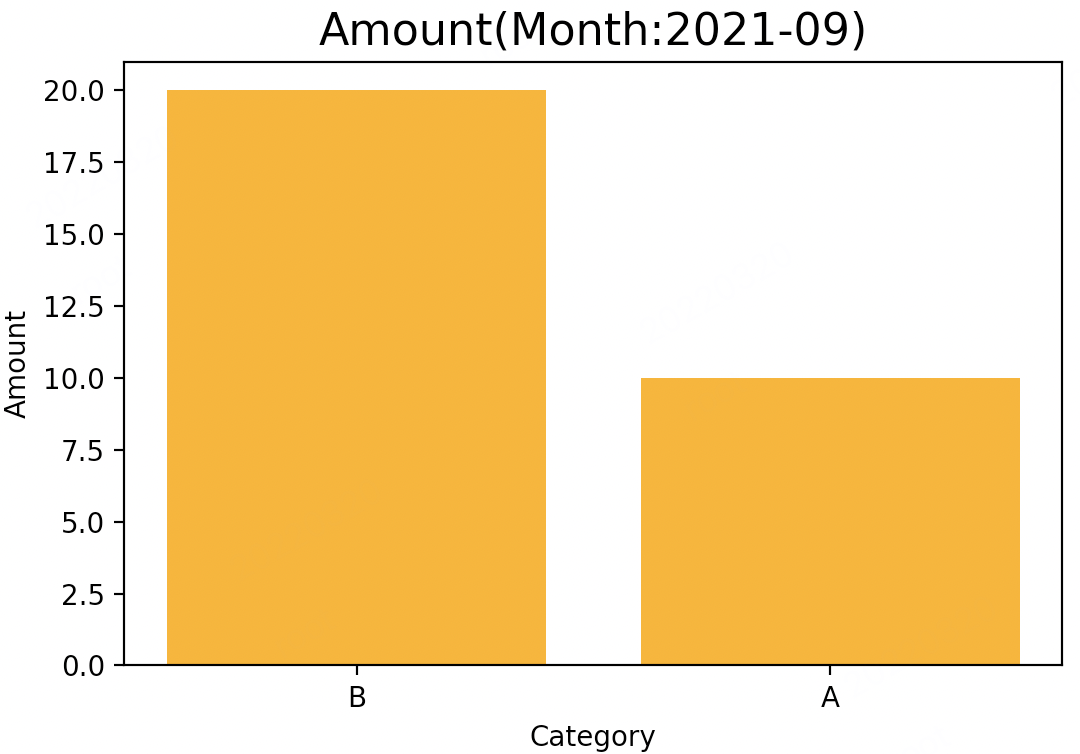
df.plot.bar(x="Category", y="Amount", color="Orange", title="Amount(Month:2021-09)")
plt.tight_layout()
plt.show()
效果如下:

DateFrame自带的plot虽然能画图,但是如果希望能控制更灵活,比如:设置title的字体大小,x轴的标签不希望横着放(或旋转指定角度)等,还可以直接调用plt底层的方法
import pandas as pd
import matplotlib.pyplot as plt df = pd.read_excel("./data/test.xlsx") # 过滤出9月份的,A,B二个分类的数据
df = df.loc[df.Month.apply(lambda m: m == '2021-09')] \
.loc[df.Category.apply(lambda c: c in ['A', 'B'])] # 如果希望柱状图按从高到低排好,必须先把数据排好序
df.sort_values(by="Amount", inplace=True, ascending=False) # 也可以用plt原生的画图方法来实现,有更多控制选项
plt.bar(df.Category, df.Amount, color="Orange")
plt.xticks(df.Category, rotation="0")
plt.xlabel("Category")
plt.ylabel("Amount")
plt.title("Amount(Month:2021-09)", fontsize="16")
plt.tight_layout()
plt.show()
效果一样:
二、多列对比柱状图
假设数据长这样,想对比看看9、10这2个月,各Category的值对比:
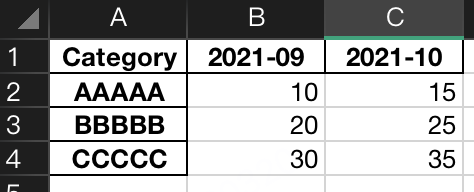
import pandas as pd
import matplotlib.pyplot as plt df = pd.read_excel("./data/test_group.xlsx")
df.sort_values(by=["2021-10"], ascending=False, inplace=True) # 核心部分
df.plot.bar(x="Category", y=["2021-09", "2021-10"], color=["orange", "red"]) # 设置标题、x,y轴文本及字体
plt.title("Amount of 2021-09 ~ 2021-10", fontsize="16", fontweight="bold")
plt.xlabel("Category", fontweight="bold")
plt.ylabel("Amount", fontweight="bold")
# get current axis
ax = plt.gca()
# ha = horizontal align
# x轴标签,旋转45度,水平对齐方式为right
ax.set_xticklabels(df.Category, rotation=45, ha="right") # get current figure
f = plt.gcf()
# 设置左边留20%空白,底部留20%空白
f.subplots_adjust(left=0.2, bottom=0.2)
# plt.tight_layout()
plt.show()
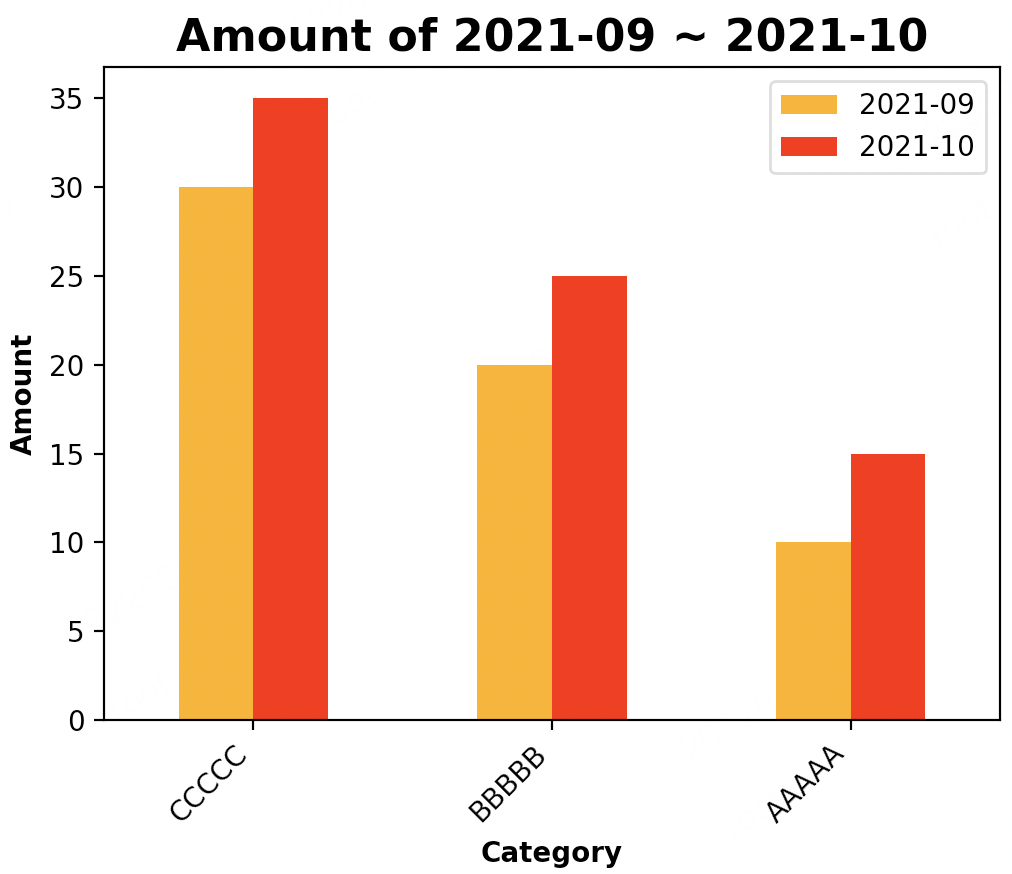
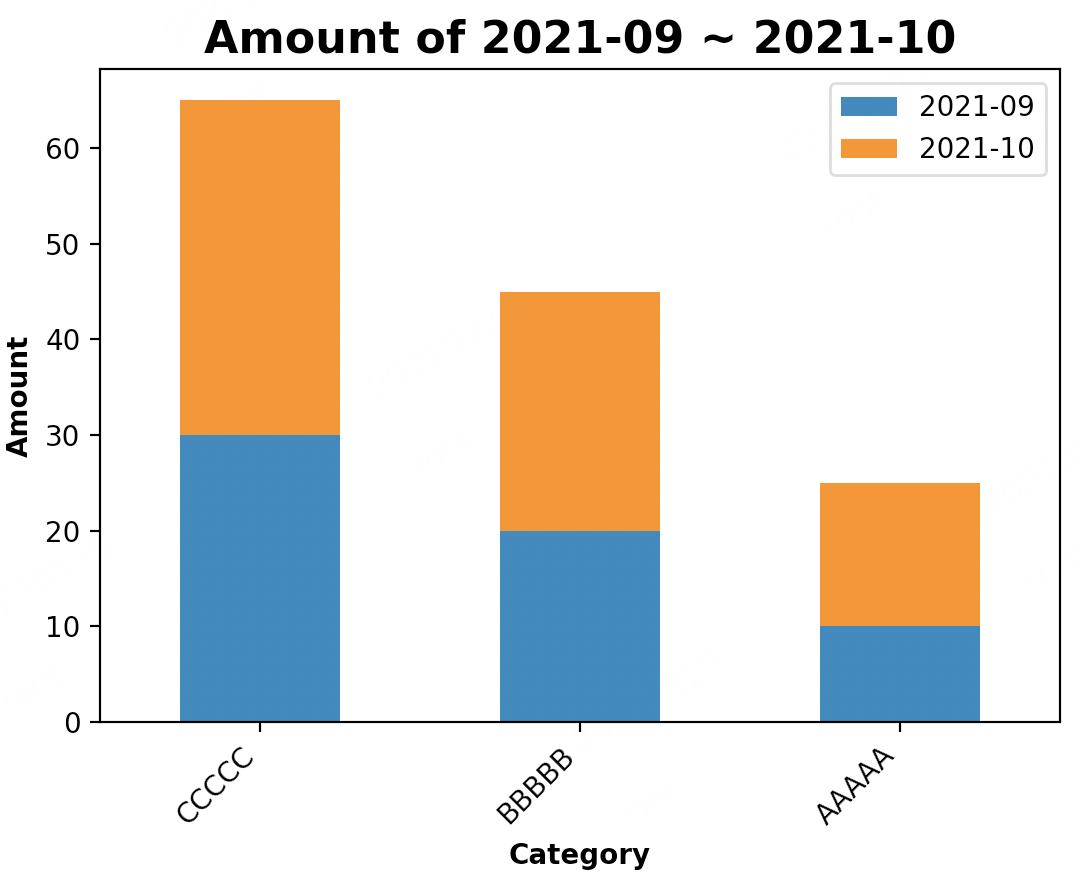
三、叠加柱状图
还是刚才的数据,只要加一个参数stacked=True,就变成了叠加柱状图
import pandas as pd
import matplotlib.pyplot as plt df = pd.read_excel("./data/test_group.xlsx") # 加上stacked=True后,将变成叠加柱状图
df.plot.bar(x="Category", y=["2021-09", "2021-10"], stacked=True) # 下面都是美化选项
plt.title("Amount of 2021-09 ~ 2021-10", fontsize="16", fontweight="bold")
plt.xlabel("Category", fontweight="bold")
plt.ylabel("Amount", fontweight="bold")
ax = plt.gca()
ax.set_xticklabels(df.Category, rotation=45, ha="right")
f = plt.gcf()
f.subplots_adjust(left=0.15, bottom=0.20)
plt.show()
效果如下:

如果想让柱子高度从大到小排列,就不能简单的按2021-09或2021-10中的某一列来排序了!因为柱子的高度,其实是这2列值的和,所以要新增1个计算列:
...
# 新增1个计算列
df["total"] = df["2021-09"] + df["2021-10"]
df.sort_values(by="total", inplace=True, ascending=False) df.plot.bar(x="Category", y=["2021-09", "2021-10"], stacked=True)
...
效果:
叠加柱状图还可以改方向,比如:变成水平的,只需要把bar()换成barh()即可
import pandas as pd
import matplotlib.pyplot as plt df = pd.read_excel("./data/test_group.xlsx") # barh 即bar-horizontal
df.plot.barh(x="Category", y=["2021-09", "2021-10"], stacked=True) plt.title("Amount of 2021-09 ~ 2021-10", fontsize="16", fontweight="bold")
plt.xlabel("Category", fontweight="bold")
plt.ylabel("Amount", fontweight="bold")
f = plt.gcf()
f.subplots_adjust(left=0.15, bottom=0.20)
plt.show()

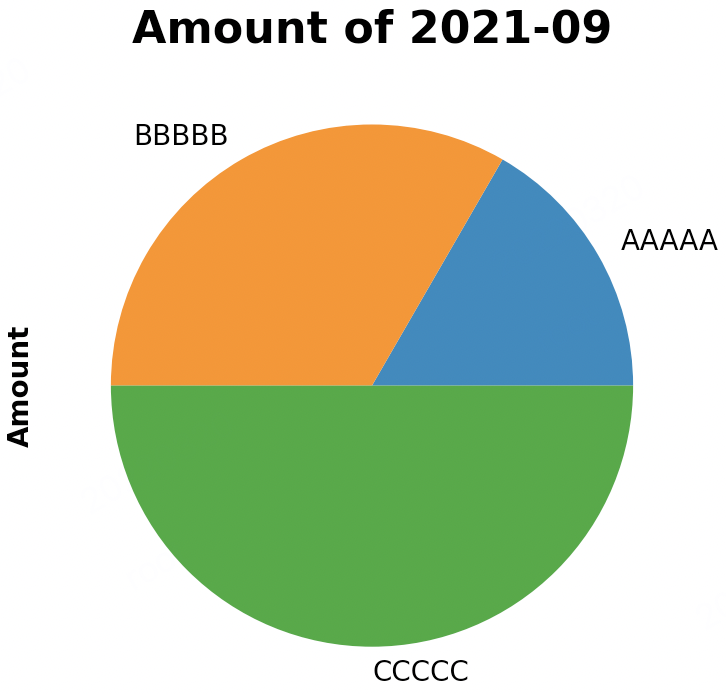
四、饼图
饼图通常只需要1列,来看该列各行值的占比
import pandas as pd
import matplotlib.pyplot as plt df = pd.read_excel("./data/test_group.xlsx", index_col="Category") # 核心部分
df["2021-09"].plot.pie() # 图表美化
plt.title("Amount of 2021-09", fontsize="16", fontweight="bold")
plt.ylabel("Amount", fontweight="bold")
f = plt.gcf()
f.subplots_adjust(left=0.15, bottom=0.20)
plt.show()
效果:
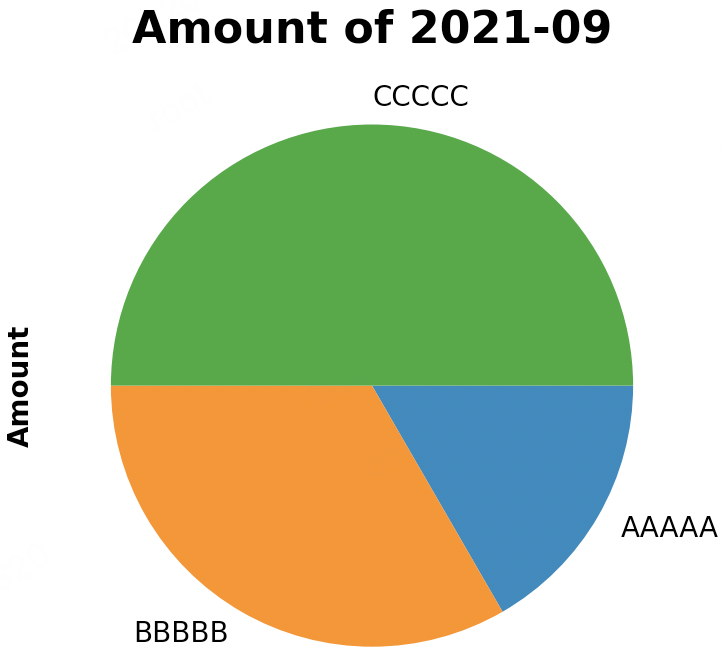
默认情况下,饼图各部分是逆时针方向的,如果想换个方向,加上counterclock=False即可
# 核心部分
df["2021-09"].plot.pie(counterclock=False)
效果:
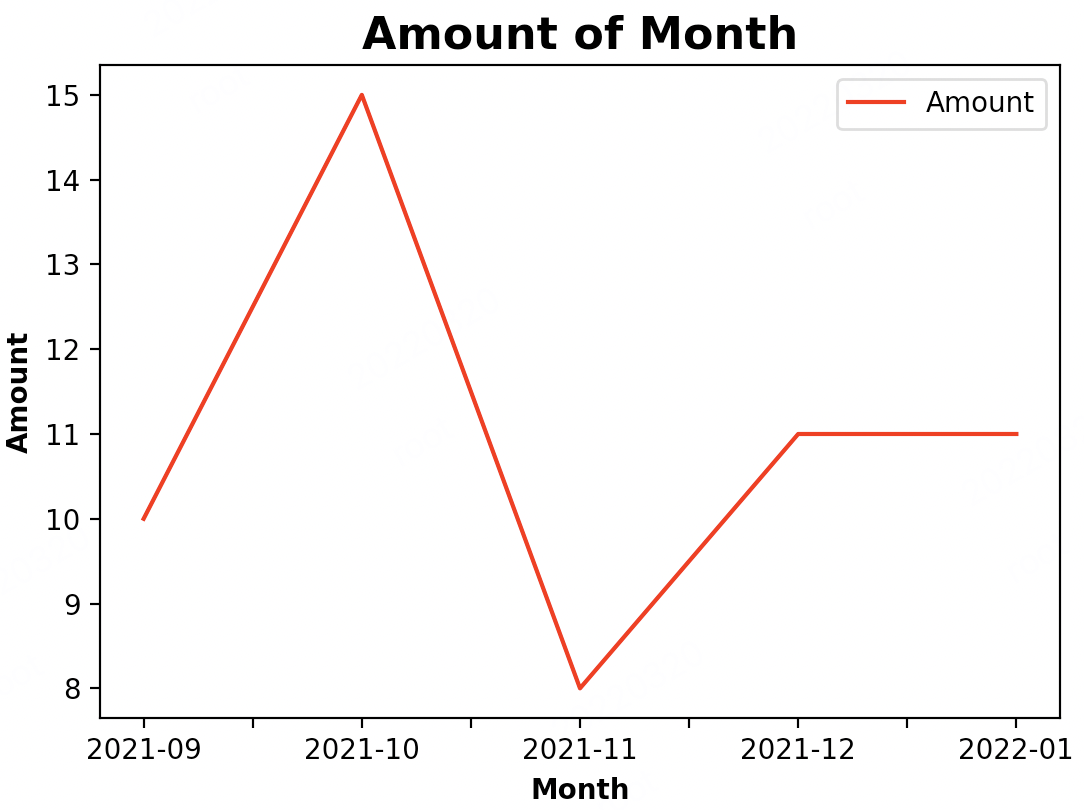
五、折线图
import pandas as pd
import matplotlib.pyplot as plt df = pd.DataFrame(columns=["Month", "Amount"], data=[['2021-09', 10],
['2021-10', 15],
['2021-11', 8],
['2021-12', 11],
['2022-01', 11]
])
df.set_index("Month", inplace=True)
print(df) # 核心部分
df.plot(y=['Amount'], color="red") # 图表美化
plt.title("Amount of Month", fontsize="16", fontweight="bold")
plt.xlabel("Month", fontweight="bold")
plt.ylabel("Amount", fontweight="bold")
f = plt.gcf()
f.subplots_adjust(left=0.15, bottom=0.20)
plt.show()
输出:
Amount
Month
2021-09 10
2021-10 15
2021-11 8
2021-12 11
2022-01 11
pandas速成笔记(4)-数据图表的更多相关文章
- 【转】Pandas学习笔记(二)选择数据
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- @1-5使用pandas保存豆瓣短评数据
使用pandas保存豆瓣短评数据 Python爬虫(入门+进阶) DC学院 本节课程的内容是介绍open函数和pandas两种保存已爬取的数据的方法,并通过实际例子使用pandas保存数据. ...
- 【转】Pandas学习笔记(七)plot画图
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(六)合并 merge
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(五)合并 concat
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(四)处理丢失值
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(三)修改&添加值
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(一)基本介绍
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 实操 | 内存占用减少高达90%,还不用升级硬件?没错,这篇文章教你妙用Pandas轻松处理大规模数据
注:Pandas(Python Data Analysis Library) 是基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.此外,Pandas 纳入了大量库和一些标准的数据模型 ...
- pandas库笔记
本笔记为自学笔记 1.pandas.DataFrame() 一种保存矩阵的数据格式 grades_df = pd.DataFrame( data={'exam1': [43, 81, 78, 75, ...
随机推荐
- Cline技术分析:prompt如何驱动大模型对本地文件实现自主变更
prompt如何驱动大模型对本地文件实现自主变更 在AI技术快速发展的今天,编程方式正在经历一场革命性的变革.从传统的"人写代码"到"AI辅助编程",再到&qu ...
- Sentinel——授权规则
授权规则 授权规则是一种通过对请求来源进行甄别的鉴权规则.规则规定了哪些请求可以通过访问,而哪些请求则是被拒绝访问的.而这些请求的设置是通过黑白名单来完成的. 无论是黑名单还是白名单,其实就是一个请求 ...
- Pandas 批量处理文本表
就是一个批量读取文件, 然后计算指标的过程. 难度到是没啥, 只是想记录一把, 毕竟这类的需求, 其实还是蛮多的. 但涉及一些数据的安全, 和指标这块也是不能透露的, 因此只能是贴上代码, 目的还是给 ...
- SQL 日常练习 (十九)
趁热打铁, 一波 SQL 继续带走 ~~ 虽然是假期, 但我也不想出去逛, 宅着也不想看书和思考人生, 除了做饭, 就更多对着电脑发呆. 时而看了下微信群, 初中小伙伴结合, 祝福寄语 和 随份子 都 ...
- WebAssembly:开启新时代的跨平台
@charset "UTF-8"; .markdown-body { line-height: 1.75; font-weight: 400; font-size: 15px; o ...
- c++并发编程实战-第4章 并发操作的同步
等待事件或等待其他条件 坐车案例 想象一种情况:假设晚上坐车外出,如何才能确保不坐过站又能使自己最轻松? 方法一:不睡觉,时刻关注自己的位置 1 #include <iostream> 2 ...
- E - Stamp
题目链接 : E - Stamp (atcoder.jp) 题意:给定长为n的s串,m的t串,和一个长度为n的x串,问你能否操作任意次数的操作, 每次操作都可以使x中长度为m的存在串变为t,最后使得变 ...
- Spring扩展接口-内置事件ContextEvent
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- Spring扩展接口-CommandLineRunner、ApplicationRunner
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- 网络策略NetworkPolicy
网络策略 在 Kubernetes 里,网络隔离能力的定义,是依靠一种专门的 API 对象来描述的,即: NetworkPolicy. Kubernetes 里的 Pod 默认都是"允许所有 ...