Transformer 代码框架
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
基于位置的前馈网络
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
改变张量的最里层维度的尺寸
ffn = PositionWiseFFN(4, 4, 8)
ffn.eval()
ffn(torch.ones((2, 3, 4)))[0]

对比不同维度的层规范化和批量规范化的效果
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# 在训练模式下计算X的均值和方差
print('layer norm:', ln(X), '\nbatch norm:', bn(X))

使用残差连接和层归一化
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
加法操作后输出张量的形状相同
add_norm = AddNorm([3, 4], 0.5)
add_norm.eval()
add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape
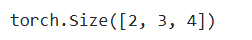
实现编码器中的一个层
class EncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,
use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
Transformer编码器中的任何层都不会改变其输入的形状
X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shape
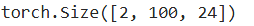
Transformer编码器
class TransformerEncoder(d2l.Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
# 因为位置编码值在-1和1之间,
# 因此嵌入值乘以嵌入维度的平方根进行缩放,
# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X
创建一个两层的Transformer编码器
encoder = TransformerEncoder(
200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape
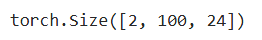
Transformer解码器也是由多个相同的层组成
class DecoderBlock(nn.Module):
"""解码器中第i个块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
# 训练阶段,输出序列的所有词元都在同一时间处理,
# 因此state[2][self.i]初始化为None。
# 预测阶段,输出序列是通过词元一个接着一个解码的,
# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),
# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(
1, num_steps + 1, device=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# 自注意力
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# 编码器-解码器注意力。
# enc_outputs的开头:(batch_size,num_steps,num_hiddens)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
编码器和解码器的特征维度都是num_hiddens
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
decoder_blk(X, state)[0].shape
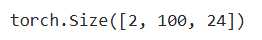
Transformer解码器
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# 解码器自注意力权重
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
训练
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)

encoder = TransformerEncoder(
len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
decoder = TransformerDecoder(
len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
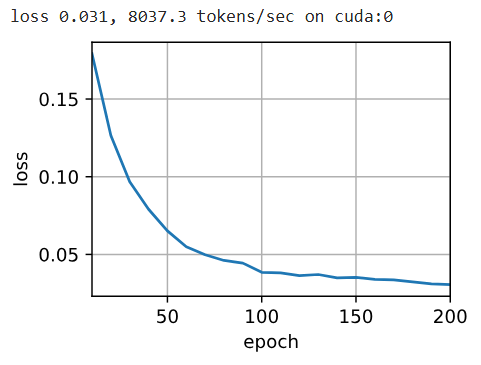
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')

enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers, num_heads,
-1, num_steps))
enc_attention_weights.shape
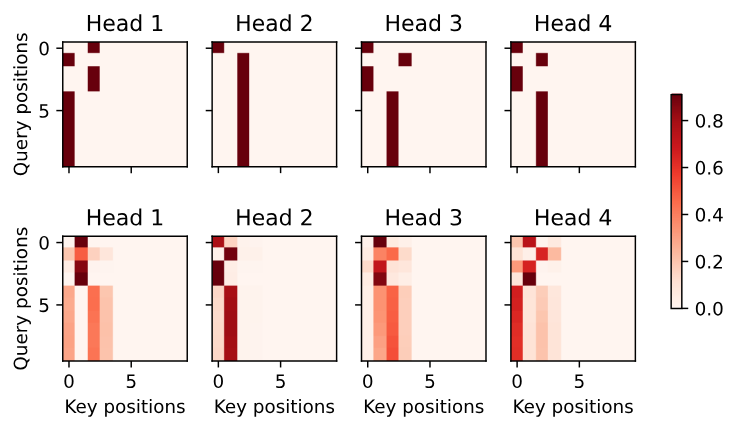
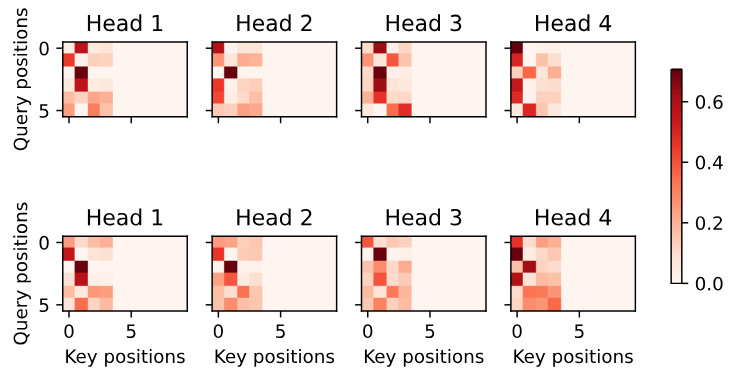
d2l.show_heatmaps(
enc_attention_weights.cpu(), xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
为了可视化解码器的自注意力权重和“编码器-解码器”的注意力权重,我们需要完成更多的数据操作工作
dec_attention_weights_2d = [head[0].tolist()
for step in dec_attention_weight_seq
for attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(
pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \
dec_attention_weights.permute(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape

# Plusonetoincludethebeginning-of-sequencetoken
d2l.show_heatmaps(
dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],
xlabel='Key positions', ylabel='Query positions',
titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))
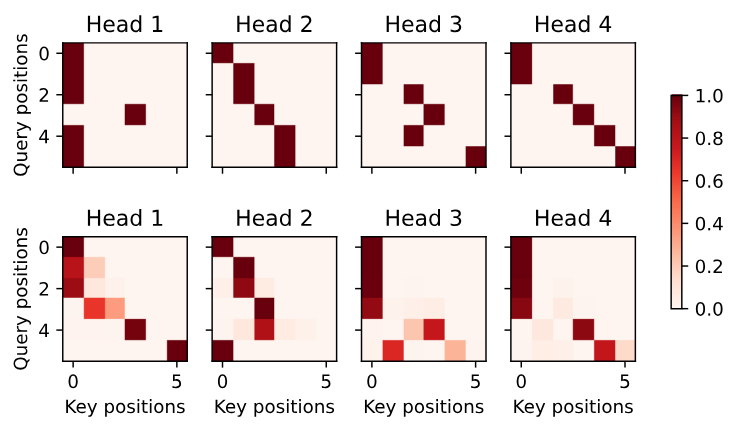
输出序列的查询不会与输入序列中填充位置的词元进行注意力计算
d2l.show_heatmaps(
dec_inter_attention_weights, xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
Transformer 代码框架的更多相关文章
- x01.CodeBuilder: 生成代码框架
根据 Assembly 生成代码框架. 这是学习 AvalonEdit 的一个副产品.学习时,照着源代码新建文件夹,新建文件,添加方法与属性,虽然只是个框架,也要花费大量时间.为什么不让它自动生成呢? ...
- twemproxy代码框架概述——剖析twemproxy代码前编
本篇将去探索twemproxy源码的主干流程,想来对于想要开始啃这份优秀源码生肉的童鞋会有不小的帮助.这里我们首先要找到 twemproxy正确的打开方式--twemproxy的文件结构,接着介绍tw ...
- [C++]Linux之多进程运行代码框架
声明:如需引用或者摘抄本博文源码或者其文章的,请在显著处注明,来源于本博文/作者,以示尊重劳动成果,助力开源精神.也欢迎大家一起探讨,交流,以共同进步- 0.0 多进程代码框架示例 /* @url: ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- DSO 代码框架
从数据流的角度讲一遍 DSO 代码框架. DSO 的入口是 FullSystem::addActiveFrame,输入的影像生成 FrameHessian 和 FrameShell 的 Object, ...
- 深入浅出etcd系列Part 1 – etcd架构和代码框架
1.绪论 etcd作为华为云PaaS的核心部件,实现了PaaS大多数组件的数据持久化.集群选举.状态同步等功能.如此重要的一个部件,我们只有深入地理解其架构设计和内部工作机制,才能更好地学习华为云Ku ...
- 自适应大邻域搜索代码系列之(1) - 使用ALNS代码框架求解TSP问题
前言 上次出了邻域搜索的各种概念科普,尤其是LNS和ALNS的具体过程更是描述得一清二楚.不知道你萌都懂了吗?小编相信大家早就get到啦.不过有个别不愿意透露姓名的热心网友表示上次没有代码,遂不过瘾啊 ...
- 使用EA生成多层次的代码框架
最近工作期间发现了一个非常棒的UML软件[Enterprise Architect UML 建模工具]简称EA,在该软件上绘制框架层面的类之间关系后,可以自动生成相关语言的代码. EA上目前支持的语言 ...
- Onvif开发之代码框架生成篇
看了前一篇的ONVIF的简单介绍应该对它的基本使用都有了一些基本的了解了吧!下面我讲一步分解向大家介绍下如何通过gsoap生成需要的代码,以及代码中需要注意的问题[基于Linux平台 C开发] 生成O ...
- OpenDaylight开发hello-world项目之代码框架搭建
OpenDaylight开发hello-world项目之开发环境搭建 OpenDaylight开发hello-world项目之开发工具安装 OpenDaylight开发hello-world项目之代码 ...
随机推荐
- 进程间通信-POSIX 信号量
POSIX 信号量 POSIX 信号量是一种 POSIX 标准中定义的进程间同步和互斥的方法.它允许进程之间通过信号量来实现临界区的互斥访问,从而避免竞争条件和死锁等问题. 信号量的P.V操作: P ...
- Sqlite3中的Join
1.概述sqlite3是一种轻便的数据库,由DDL(Data defination language),DML(Data manipulation language),TCL(Transaction ...
- 第一次blog作业
1.前言 刚接触面向对象程序设计和开始学习Java编程语言的时候,确实觉得所有的一切都很困难,所有的一切都很陌生.面对全新的概念和编程方式,感觉自己像是进入了一个完全陌生的领域,需要从头开始探索.那 ...
- EasyExcel工具类,可导出单个sheet、导出多个sheet
单个sheet导出案例 ExcelUtil.exportXlsx(response, "测试数据", "测试数据", list, TestDataPageDto ...
- java等比压缩图片工具类
工具类 package com.chinaums.abp.util; import javax.imageio.ImageIO; import java.awt.*; import java.awt. ...
- pip安装模块提示Command "python setup.py egg_info" failed with error code 1
报错详情: [root@k8s001 ~]# pip install kubernetes Collecting kubernetes Using cached https://files.pytho ...
- HTTP POST方式调用SOAP OPERATION类的接口
wsdl地址或者接口地址中有多个方法(operation) 如下是soapui测试的例子,wsdl地址下包含多个operation,但是现在我想用http的方式,只做getKnowledgeParts ...
- UFT 对文件的处理(scripting.filesystemObject)
1. 文件路劲 2. 文件大小 3.写 4. 读 5. 复制 6. 内容替换
- Alovoa - 开源隐私优先的约会平台
项目标题与描述 Alovoa是一个旨在成为首个广泛使用的免费开源约会网络平台.与其他平台不同,Alovoa具有以下核心价值: 无广告 不出售用户数据 无付费功能(无"付费超级喜欢" ...
- MySQL核心知识学习之路(2)
作为一个后端工程师,想必没有人没用过数据库,跟我一起复习一下MySQL吧,本文是我学习<MySQL实战45讲>的总结笔记的第二篇,总结了MySQL的事务隔离级别. 上一篇:MySQL核心知 ...