基于 Paimon 的袋鼠云实时湖仓入湖实战剖析
在当今数据驱动的时代,企业对数据的实施性能力提出了前所未有的高要求。为了应对这一挑战,构建高效、灵活且可扩展的实时湖仓成为数字化转型的关键。本文将深入探讨袋鼠云数栈如何通过三大核心实践——ChunJun 融合 Flink CDC、MySQL 一键入湖至 Paimon 的实践,以及湖仓一体治理 Paimon 的实践,重塑实时湖仓的架构与管理,为企业打造实时数据分析的新引擎。
ChunJun 融合 Flink CDC
Flink CDC(Change Data Capture)是由 Apache Flink 提供的一个流数据集成工具,它允许用户通过 YAML 文件优雅地定义 ETL(Extract, Transform, Load)流程,并自动生成定制化的 Flink 算子和提交 Flink 作业。
Flink CDC 的核心特性包括:端到端数据集成框架、易于构建作业的 API、多表支持、整库同步精确一次语义、增量快照算法等诸多特性。ChunJun 融合 Flink CDC 能够更好支持数据的入湖入仓,带来了多方面的变化:
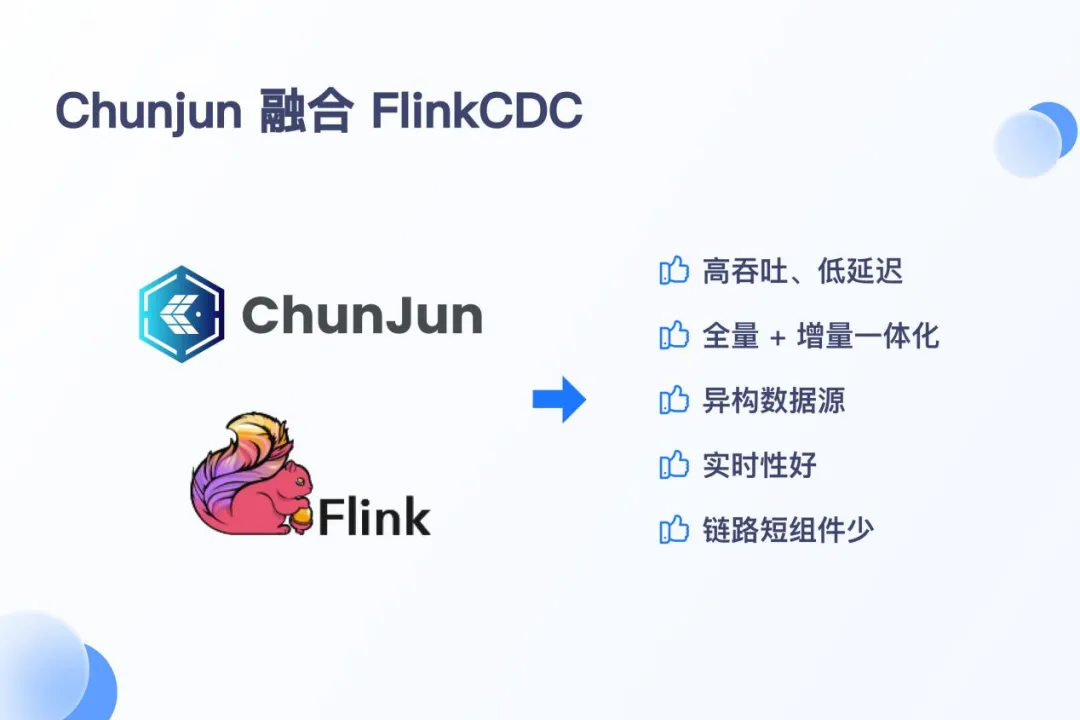
· 高吞吐、低延迟:Flink CDC 能够以高吞吐量和低延迟的方式捕获和传输数据库的变更
· 全增量一体化:Flink CDC 支持全量数据和增量数据的同步,无需手动操作即可实现全量快照与增量日志的自动衔接
· 支持异构数据源:Flink CDC 支持多种数据源,可以轻松实现异构数据源的集成,通过 Flink SQL 定义不同类型的 CDC 表,实现数据融合
· 实时性:支持近实时的数据同步,满足对数据时效性要求高的场景
· 链路短组件少:Flink CDC 的架构设计让整个数据捕获和处理的链路变得更为简洁,所涉及的组件数量相对有限,这不但降低了系统的繁杂程度,还削减了学习与运维的成本
MySQL 一键入湖 Paimon 实践
ChunJun 融合 Flink CDC 增加了实时湖仓数据接入的方式,结合 FLink CDC 提供的 MySQL 数据到 Paimon 的数据同步能力,能够高效地将 MySQL 表数据实时写入 Paimon 中。在融合的同时,还支持历史 Json 格式构建任务、脏数据、Mertic、表血缘、可视化配置等功能。
接下来通过内部实践案例进行深入分析。
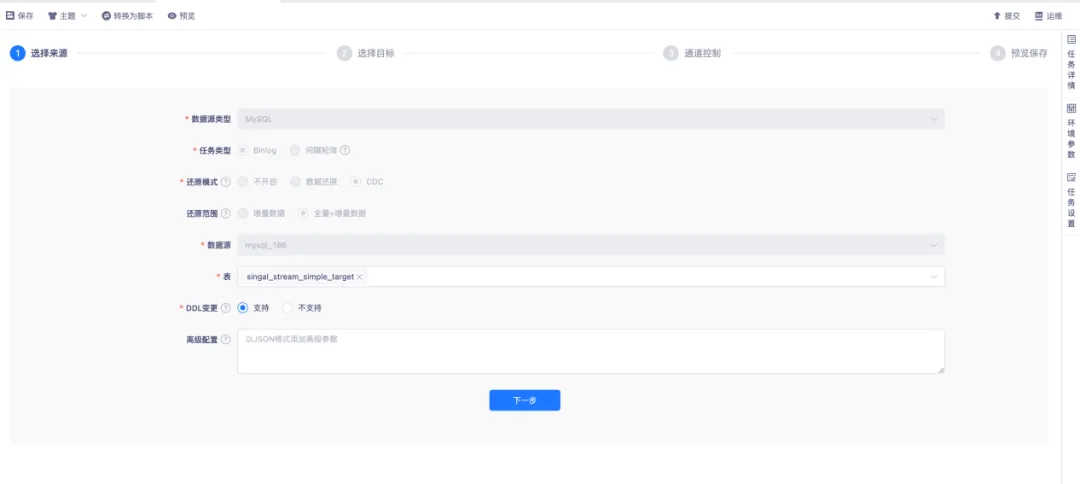
● 采集配置 Flink CDC 来源
实时采集配置 Flink CDC 来源为 MySQL 时,向导模式配置还原范围采用全量+增量模式。
首先,对数据库表进行全表快照读取,生成数据的一致性快照,以同步来源表的历史全量数据。在全量快照读取完成后,会自动切换至增量模式,对数据库的增量变化进行采集。表选择的方式多样,支持整库同步、分库分表同步、单表选择同步,同时也支持通过正则的方式选择表。
对于 DDL 变更,当上游产生 DDL 操作时,若选择支持,下游会自动执行;若选择不支持,则对上游产生的 DDL 做异常捕获,此时任务会失败。搭配告警功能,可及时告知出现异常的情况。出现异常后,需要手动执行 DDL 操作,任务才能恢复正常运行。
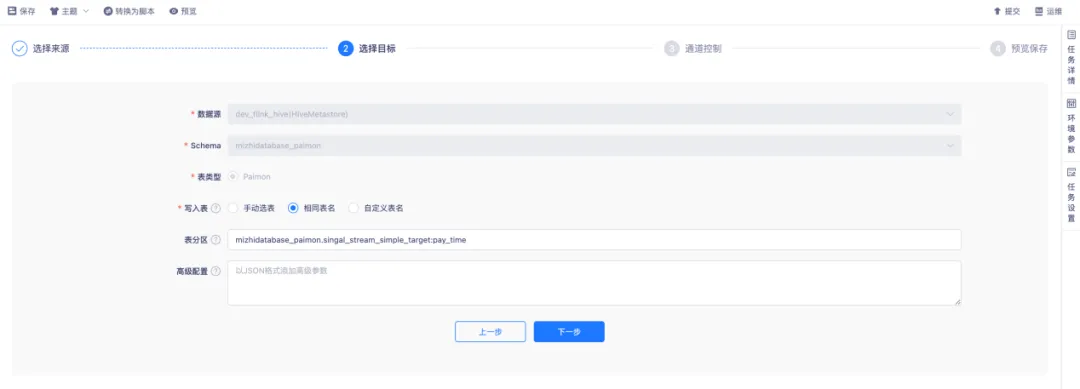
● 采集配置目标端
目标源通过 HiveMetastore 方式配置目标 Paimon 表。写入表的方式具有一定灵活性,支持手动选择表。对于上游存在多表写入同一下游表的场景,有一定要求,必须保证上下游表结构保持一致。
同时,支持使用相同表名、自定义表名的方式。在同步前,会先创建写入的目标表,如果已存在,则直接使用现成表。表分区方面,通过输入固定的语法,将对应上游的主键表字段作为目标 Piamon 表的分区字段。
● 调度运行采集任务
实时采集任务在通过语法检查后,提交至调度运维中运行。采集任务的指标包括 Mertic 输入输出指标展示、脏数据指标以及数据血缘解析等。
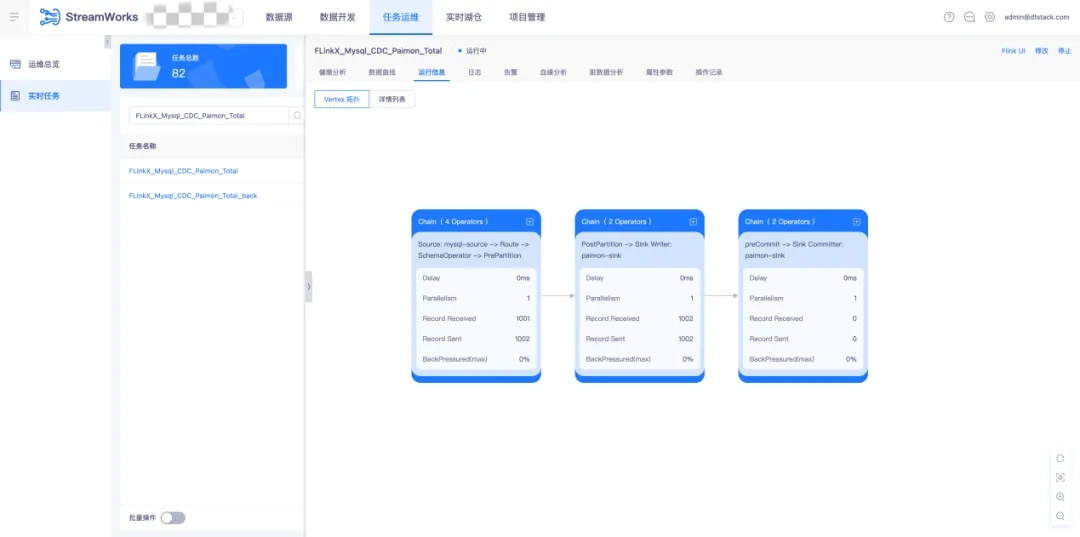
● 查询入湖数据
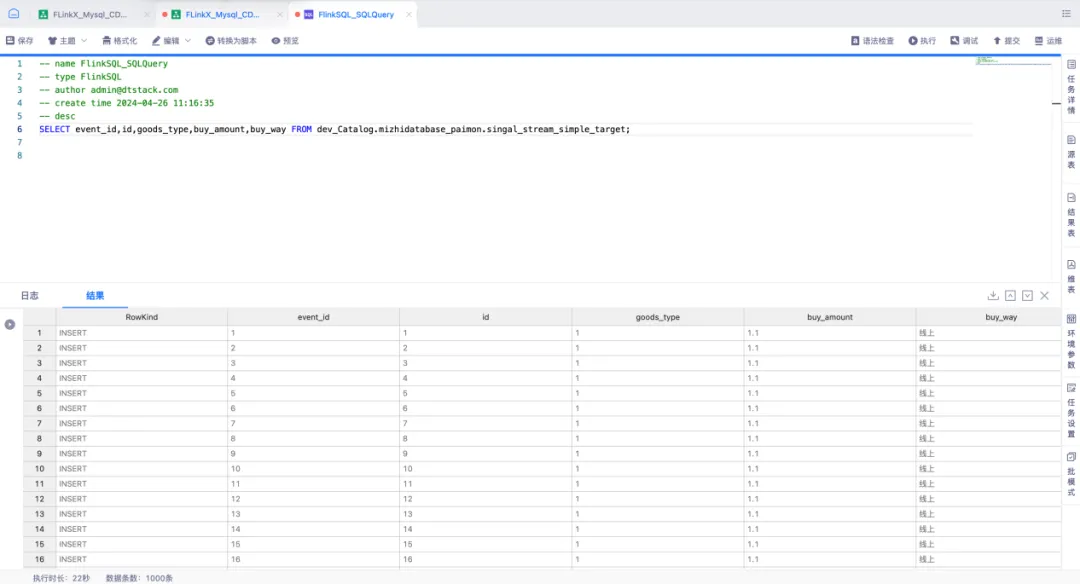
通过实时平台中 FlinkSQL 任务所提供的功能,对 Paimon 表进行查询并插入数据。利用 FlinkSQL 的 SqlQuery 功能构建 Select 查询语句,并采用流模式实时查询 Paimon 表,以采集插入数据的情况。
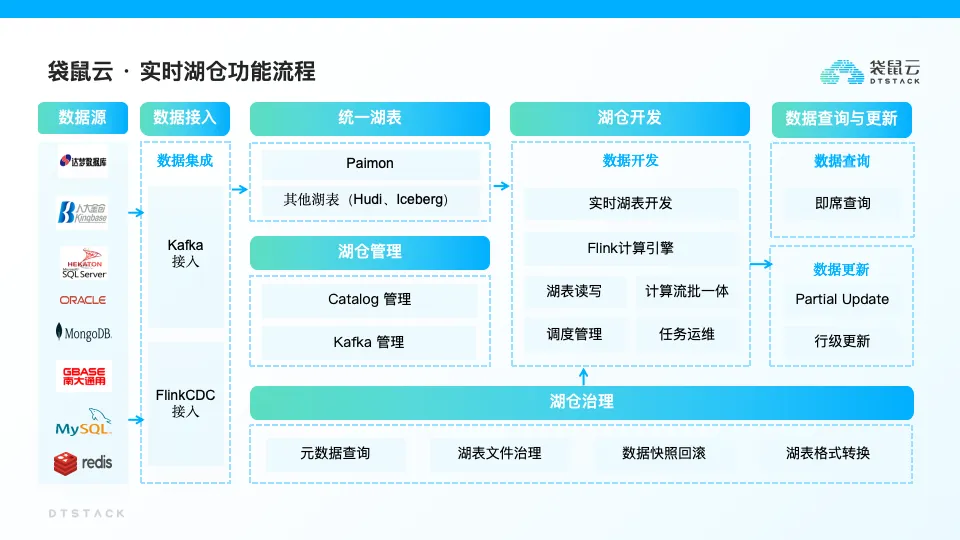
湖仓一体治理 Paimon 实践
在构建和维护数据湖与数据仓库(湖仓)的一体化架构进程中,袋鼠云凭借湖仓治理机制,不断推进实时数据湖的优化与完备。
然而,Paimon 在数据处理期间可能会引发数据碎片化的问题,像小文件的急剧增多、过时快照的持续累积以及孤儿文件的出现,这些状况均有可能给数据湖表的读写效率带来极为显著的不良影响。
为有效应对这一挑战,袋鼠云于数栈湖仓一体中引入了文件治理机制,支持定期开展数据整理操作,例如合并小文件、清理过期的数据快照以及清除孤儿文件等。此类治理活动旨在增强数据湖的整体读写性能,保障数据流的高效运行和分析工作的顺利开展。借由这些数据治理手段,袋鼠云能够为湖仓架构的稳定性和性能提供稳固支撑,进而助力企业在大数据时代实现敏捷决策和深度洞察。
元数据管理
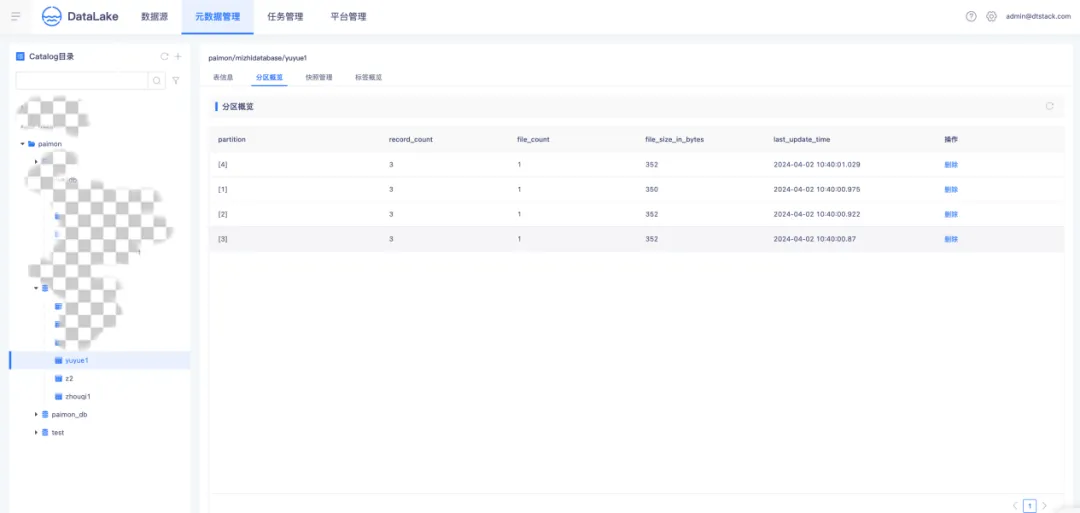
● Paimon 分区概览
Paimon 运用了与 Apache Hive 相同的分区理念来对数据进行分离。分区属于一种可选的形式,能够依据日期、城市和部门等特定列的值,将表划分成相关的部分。每个表能够拥有一个或多个分区键,以识别某一特定的分区。分区概览会展示分区的数据记录、文件数量以及文件的大小,并且支持对分区的删除操作。
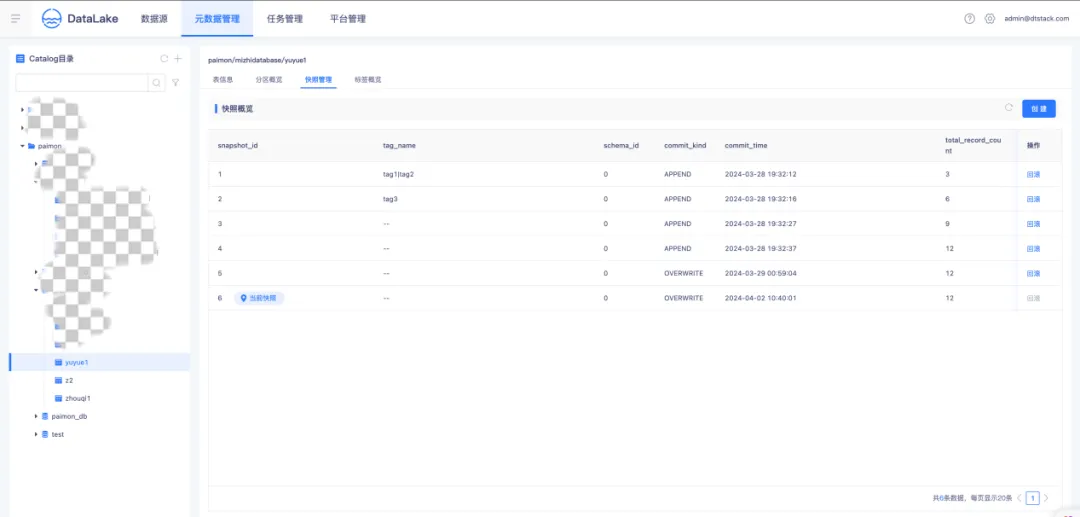
● Paimon 快照概览
快照记录了一个表在某一特定时间点的状态。用户能够借助最新的快照获取一个表的最新数据。利用时间旅行,用户还可以通过较早的快照访问表的先前状态。快照概览展示了当前表的所有快照、最新 snapshot,支持手动创建标签并在列表中展示引用关系,同时支持快照的删除和回滚操作。
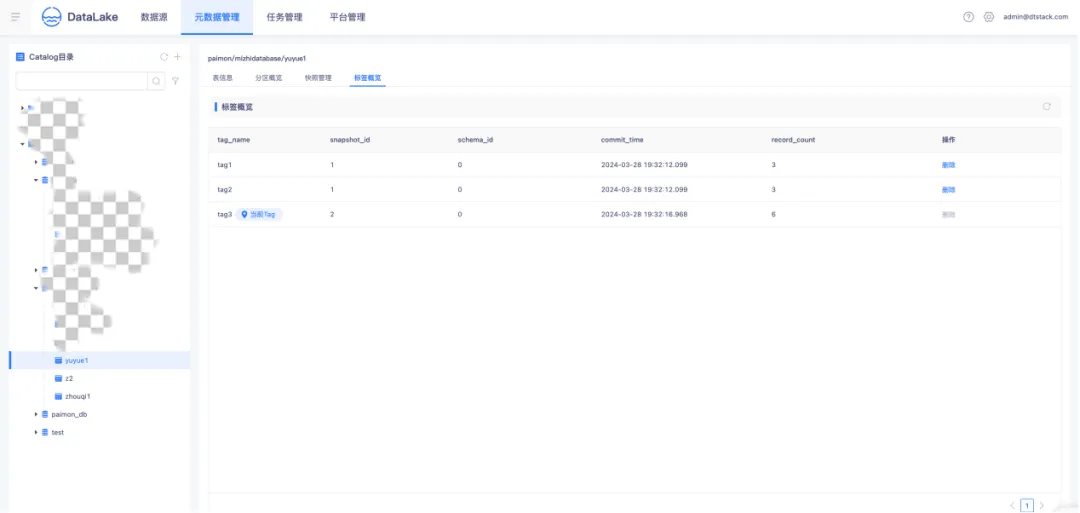
● Paimon 标签概览
标签是对快照的引用,能够基于某个特定快照创建。用户能够在特定的快照上添加标签,如此一来,即便快照过期且被删除,只要标签仍然存在,就能够通过标签访问到相应的数据。标签概览展示了表的所有历史标签版本、标签与快照的引用关系,并且支持标签的删除操作。
湖表治理
● Paimon 小文件合并
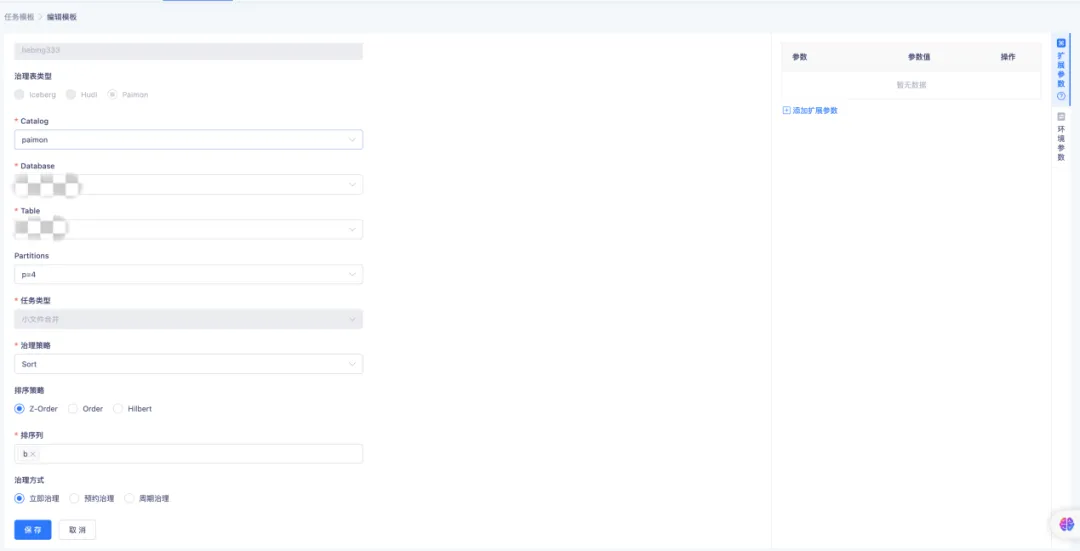
随着时间的不断推移,持续的写入操作或许会产生大量的小文件,这将致使查询性能降低,原因在于系统需要打开并读取更多的文件。Compaction 能够通过合并这些小文件,从而减少文件的总数。在数据文件治理中,支持对 Paimon Table、Database 的小文件进行治理。
Compaction Table 支持三种排序策略,通过配置不同的治理方式,支持周期性地对表进行治理。Compaction Database 支持对单个或者多个库执行文件的合并操作。
● Paimon 孤儿文件清理
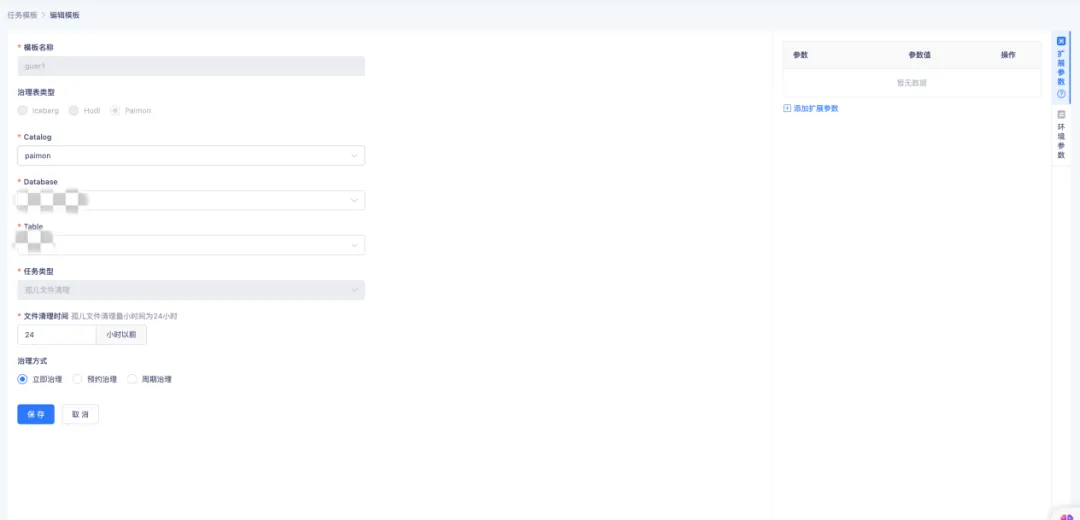
孤儿文件指的是那些不再被任何快照所引用的文件,其可能因异常的写入操作、未完成的事务或者错误的删除操作而出现。清理此类孤儿文件是维系数据湖健康状态的关键环节,毕竟它们会占据存储空间。
袋鼠云实时湖仓能够通过配置表的孤儿文件清理策略,支持清理 24 小时以前的孤儿文件,同时还能够通过配置周期治理,实现周期性地对孤儿文件进行治理。
● Paimon 过期快照清理
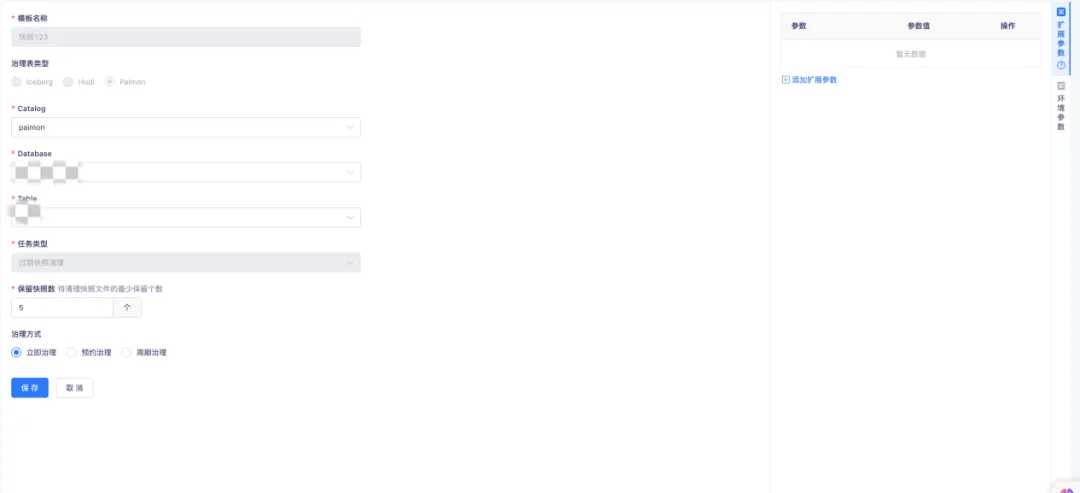
Paimon Writer 在每次提交数据时,会生成一个或两个快照。这些快照可能包含新增的数据文件,也可能将一些旧的数据文件标记为删除。需要注意的是,即使数据文件被标记为删除,它们也不会立即从物理存储中真正删除。通过配置过期快照清理和过期快照保留数量,可以对快照进行物理存储的删除操作。
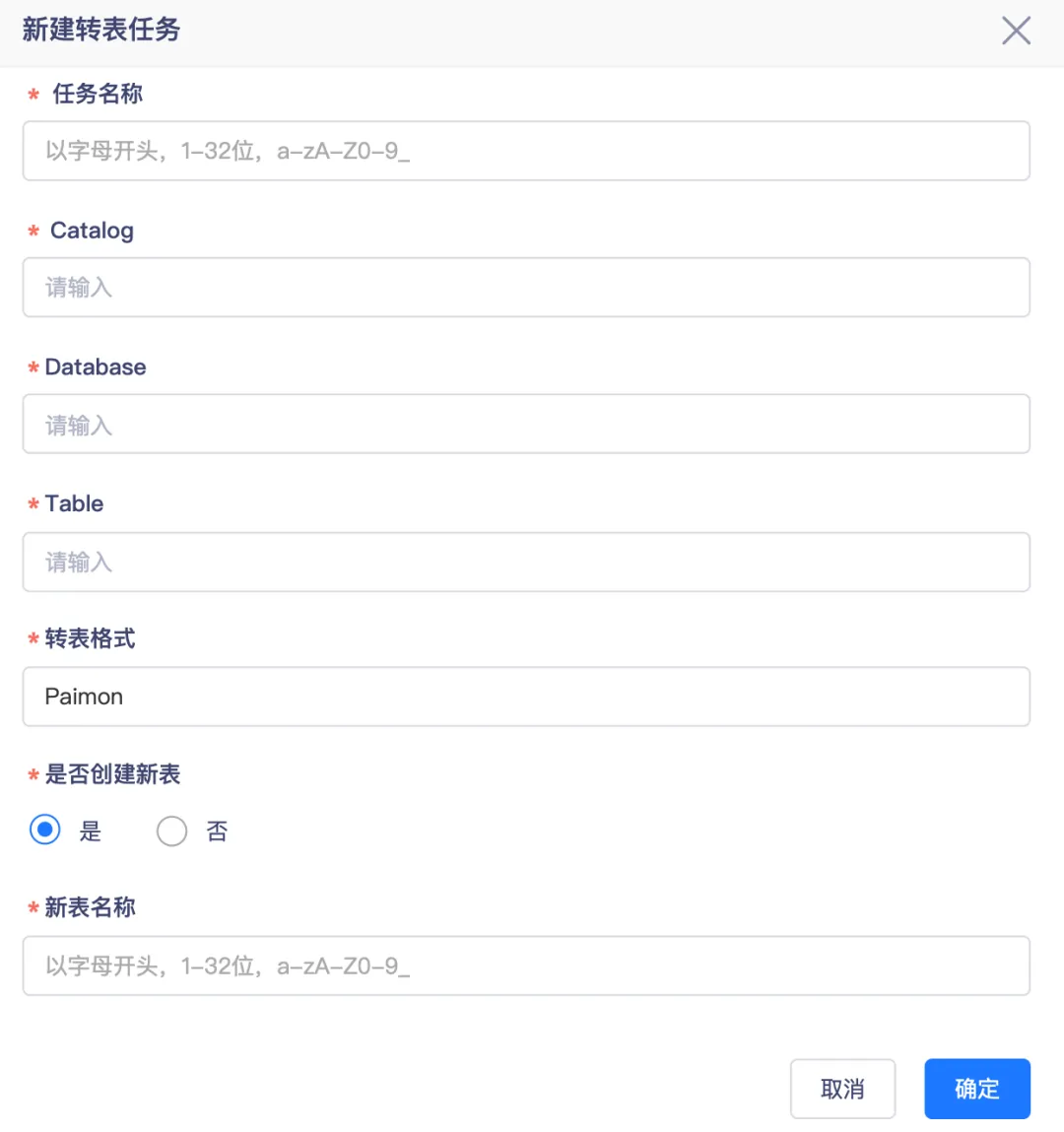
一键 Hive 表转 Paimon 表
● 原地转表
使用 Spark 内置的 migrate_table 进行表迁移时,会先创建一个临时的 Paimon 表,然后将源表的文件直接移动到该临时表中,接着对临时 Paimon 表进行 rename 操作,使其表名与源表一致,这样原来的 Hive 表就不再存在。
● New 新表
袋鼠云实时湖仓自定义了一个全新的存储过程 migrate_to_target_table ,该存储过程会读取源表的数据,创建目标 Target 表,并把源表的数据写入到新创建的 Target 表中,在此过程中原有的 Hive 表依然得以保留。
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
基于 Paimon 的袋鼠云实时湖仓入湖实战剖析的更多相关文章
- 基于Apache Hudi + Flink的亿级数据入湖实践
本次分享分为5个部分介绍Apache Hudi的应用与实践 实时数据落地需求演进 基于Spark+Hudi的实时数据落地应用实践 基于Flink自定义实时数据落地实践 基于Flink+Hudi的应用实 ...
- COS 数据湖最佳实践:基于 Serverless 架构的入湖方案
01 前言 数据湖(Data Lake)概念自2011年被推出后,其概念定位.架构设计和相关技术都得到了飞速发展和众多实践,数据湖也从单一数据存储池概念演进为包括 ETL 分析.数据转换及数据处理的下 ...
- 华为云FusionInsight湖仓一体解决方案的前世今生
摘要:华为云发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念,那我们就来看看湖仓一体的来世今生. 伴随5G.大数据.AI.IoT的飞速发展,数据呈现大规模.多样性的极速增长 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- Apache Hudi在华米科技的应用-湖仓一体化改造
徐昱 Apache Hudi Contributor:华米高级大数据开发工程师 巨东东 华米大数据开发工程师 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技 ...
- 李呈祥:bilibili在湖仓一体查询加速上的实践与探索
导读: 本文主要介绍哔哩哔哩在数据湖与数据仓库一体架构下,探索查询加速以及索引增强的一些实践.主要内容包括: 什么是湖仓一体架构 哔哩哔哩目前的湖仓一体架构 湖仓一体架构下,数据的排序组织优化 湖仓一 ...
- 华为云MRS支持lakeformation能力,打造一站式湖仓,释放数据价值
摘要:对云端用户而言,业务价值发现是最重要的,华为MRS支持LakeFormation后,成功降低了数据应用的成本,帮助客户落地"存"与"算"的管理,加快推进了 ...
- MRS+LakeFormation:打造一站式湖仓,释放数据价值
摘要:华为LakeFormation是企业级的一站式湖仓构建服务. 本文分享自华为云社区<华为云MRS支持LakeFormation能力,打造一站式湖仓,释放数据价值]>,作者:break ...
- 【转】在Spring中基于JDBC进行数据访问时怎么控制超时
http://www.myexception.cn/database/1651797.html 在Spring中基于JDBC进行数据访问时如何控制超时 超时分类 超时根据作用域可做如下层级划分: Tr ...
- 基于ElementUI,设置流体高度时,固定列与底部有间隙
基于ElementUI,设置流体高度时,固定列与底部有间隙问题,如下图: 解决办法: 1.fixed流体的高度设置为100% 2.将fixed的滚动内容的最大高度设置为none,bottom为 ...
随机推荐
- 公安部网防G01-网站安全卫士软件/linux防御
公安部网防G01-该软件免费使用,安装在网站服务器上,利用操作系统内核加固和主机web流量过滤技术,有效检测并抵御网页篡改.SQL注入.漏洞攻击.暴力破解.木马控制.XSS跨站.CC拒绝服务.系统提权 ...
- [源码系列:手写spring] IOC第八节:BeanFactoryPostProcessor和BeanPostProcessor
内容介绍 BeanFactoryPostProcessor和BeanPostProcessor是spring中具有重量级地位的两个接口,理解了这两个接口的主要作用,基本就理解Spring的核心原理了. ...
- [SDR] 蓝牙专项教程 —— 从 0 到 1 教小白基于 SDR 编写蓝牙协议栈
目录 前言 一.开题之作 二.动态发送 BLE 广播包 三.基于 PlutoSDR 实现 BLE 广播包的收发一体能力 四.基于 PlutoSDR 的 BLE 广播包的收发实现接入涂鸦智能 APP 教 ...
- vivo Trace 监控追求极致的建设历程
作者:vivo 互联网服务器团队- Zhang Yi 当前vivo的应用监控产品Vtrace经常遇到用户反馈某个Trace链路信息没法给他们提供到实质的帮肋,对此团队一直在持续完善JavaAgent的 ...
- zookeeper选主机制
Zookeeper选主机制 一.Server工作状态 每个Server在工作过程中有四种状态: LOOKING:竞选状态,当前Server不知道leader是谁,正在搜寻. LEADING:领导者状态 ...
- uniapp阻止Modal模态框关闭
要阻止uniapp的Modal模态框关闭,没有找到相关api,但可以通过保存配置立即打开的方式变相实现阻止关闭: const option = { title: "输入礼品券名称" ...
- coreybutler/nvm-windows 简单使用
目录 nvm是什么 安装 简单命令 nvm是什么 Windows电脑node.js管理器.可以方便node.js的安装与切换. 最新版本1.1.11 coreybutler/nvm-windows 有 ...
- 【工具】FreePic2PDF+PdgCntEditor|PDF批量添加书签(Windows)
这俩软件都不大,比较便携. FreePic2PDF: 我下载的来源:https://www.52pojie.cn/thread-1317140-1-1.html(包含下载链接https://www.l ...
- 【经验】VMware|虚拟机只能使用鼠标无法使用键盘、装不了或装了VMware-Tools无法复制粘贴的可能解决办法
2024/04/24说明:这篇暂时修改为粉丝可见,因为正在冲粉丝量,等到我弄完了粉丝量的要求,我就改回来!不方便看到全文的小伙伴不好意思!! VMware Workstation Pro版本:16.2 ...
- Linux系列:如何用perf跟踪.NET程序的mmap泄露
一:背景 1. 讲故事 如何跟踪.NET程序的mmap泄露,这个问题困扰了我差不多一年的时间,即使在官方的github库中也找不到切实可行的方案,更多海外大佬只是推荐valgrind这款工具,但这款工 ...