gem5基础脚本搭建
gem5基础介绍
gem5的官网:
https://www.gem5.org/
gem5的官方入门教程:
https://www.gem5.org/getting_started/
https://www.gem5.org/documentation/learning_gem5/introduction/
gem5的官方文档:
https://www.gem5.org/documentation/
gem5是一个体系结构研究领域常用的仿真器,可以进行体系架构和微架构的建模和评估。官方对gem5的介绍是:
gem5 是一个模块化的、基于离散事件驱动的计算机系统模拟平台。这意味着:
- gem5 的组件可以根据你的需求灵活地重新排列、参数化、扩展或替换。
- 它通过一系列离散事件来模拟时间的流逝。
- 它的主要用途是以各种方式模拟一个或多个计算机系统。
- gem5 不仅仅是一个模拟器,它是一个模拟平台,允许你根据需求使用其预先构建的组件来搭建自己的模拟系统。
gem5 主要使用 C++ 和 Python 编写,大多数组件采用 BSD 风格的许可证发布。它可以以“全系统模式”(FS 模式)模拟完整的系统,包括设备和操作系统;也可以仅模拟用户程序,系统服务由模拟器在系统调用仿真模式(SE 模式)下直接提供。gem5 提供不同程度的支持,可以在多种 CPU 模型上运行 Alpha、ARM、MIPS、Power、SPARC、RISC-V 以及 64 位 x86 的二进制程序,这些 CPU 模型包括两个简单的单周期模型、一个乱序执行模型以及一个有序流水线模型。内存系统可以由缓存和交叉开关灵活构建,也可以使用 Ruby 模拟器来实现更加灵活的内存系统建模。
这里并没有列出 gem5 所有的组件和特性,但从以上这些就可以看出 gem5 是一个复杂且功能强大的模拟平台。尽管 gem5 如今已经具备了强大的功能,但社区仍在积极开发和维护中,个人开发者和一些公司都在持续推动其发展,新功能不断加入,已有功能也不断得到改进。
gem5的编译安装
见gem5安装记录,最终应编译得到可执行的gem5二进制文件。
gem5的简单脚本创建
该部分的主要目的是学习基础的脚本创建以及gem5的运行,首先要理解什么是配置脚本。gem5二进制文件通过将python脚本作为参数吃入,来设置和执行仿真,在脚本中,用户可以创建仿真的系统,创建系统中的所有组件,并指定它们的参数,随后通过脚本来启动仿真。
gem5的模块设计围绕着SimObject类型。大部分系统中的仿真组件都是SimObjects,例如CPUs,caches,内存控制器,总线等。gem5将这些类从C++实现导出到了python中。因此可以在python配置脚本中创建任意的SimObject,配置它们的参数,并指定SimObjects之间的交互。
示例的一个配置脚本如下:
import m5
from m5.objects import *
system = System()
system.clk_domain = SrcClockDomain()
system.clk_domain.clock = "1GHz"
system.clk_domain.voltage_domain = VoltageDomain()
system.mem_mode = "timing"
system.mem_ranges = [AddrRange("512MiB")]
system.cpu = RiscvTimingSimpleCPU()
system.membus = SystemXBar()
system.cpu.icache_port = system.membus.cpu_side_ports
system.cpu.dcache_port = system.membus.cpu_side_ports
system.cpu.createInterruptController()
system.mem_ctrl = MemCtrl()
system.mem_ctrl.dram = DDR3_1600_8x8()
system.mem_ctrl.dram.range = system.mem_ranges[0]
system.mem_ctrl.port = system.membus.mem_side_ports
system.system_port = system.membus.cpu_side_ports
thispath = os.path.dirname(os.path.realpath(__file__))
binary = os.path.join(
thispath,
"../../../",
"tests/test-progs/hello/bin/riscv/linux/hello",
)
system.workload = SEWorkload.init_compatible(binary)
process = Process()
process.cmd = [binary]
system.cpu.workload = process
system.cpu.createThreads()
root = Root(full_system=False, system=system)
m5.instantiate()
print(f"Beginning simulation!")
exit_event = m5.simulate()
print(f"Exiting @ tick {m5.curTick()} because {exit_event.getCause()}")
在该脚本中,首先引入m5库以及所有编译后的SimObjects:
import m5
from m5.objects import *
然后,创建第一个SimObject,即我们需要仿真的系统。System对象是仿真系统中所有其他对象的父类。System对象包含了大量功能(非时序级)信息,例如物理内存范围,根时钟域,内核(全系统仿真)等。为了创建系统的SimObject,只需要简单的将其作为一个python类进行例化:
system = System()
现在有了一个即将要仿真的系统,接下来设定系统的时钟。首先创建一个时钟域,然后设置其频率,设置一个SimObject的参数的方式非常类似于python中设置一个对象的成员,所以我们可以简单地将时钟设置为1GHz,并指定一个电源域作为时钟域。由于我们当前不关心系统功耗,所以我们可以直接使用电压域的默认选项:
system.clk_domain = SrcClockDomain()
system.clk_domain.clock = '1GHz'
system.clk_domain.voltage_domain = VoltageDomain()
一旦我们有了一个系统,我们来设置存储器如何仿真。我们将使用timing模式来进行存储仿真。在多数情况下都是用timing模式,除非是特殊情况。我们设置存储尺寸范围为512MB,注意在python配置脚本中,可以直接使用常用的单位,例如'512MB'的方式来描述。类似的,时间上也可以使用单位,例如'5ns':
system.mem_mode = 'timing'
system.mem_ranges = [AddrRange('512MB')]
下面我们可以创建一个CPU,我们采用一个最简单的时序CPU,使用RISCV ISA,该CPU模型除了内存访问外,每个时钟周期都执行一条指令,RISCV ISA的CPU采用RiscvTimingSimpleCPU()创建,类似的,X86架构的CPU可以使用X86TimingSimpleCPU(),ARM架构的可以使用ArmTimingSimpleCPU。:
system.cpu = RiscvTimingSimpleCPU()
接下来可以创建全系统的内存总线:
system.membus = SystemXBar()
鉴于我们有了内存总线,我们进一步将CPU的缓存端口连接上去,在该例子中,由于我们想要仿真的系统没有任何缓存,我们会把I-Cache和D-Cache直接连接到内存总线上:
system.cpu.icache_port = system.membus.cpu_side_ports
system.cpu.dcache_port = system.membus.cpu_side_ports
这里可以一些展开讨论。为了将内存系统单元连接到一起,gem5使用端口抽象。每个内存对象可以有两种端口:请求端口和响应端口。请求通过一个请求端口发送到一个响应端口,然后响应从一个响应端口发送到一个请求端口。当连接端口时,必须从请求端口连接到响应端口上。
在python配置脚本中可以很简单的把两个端口连接在一起,直接使用请求端口=响应端口就可以直接把它们互联,例如:
system.cpu.icache_port = system.l1_cache.cpu_side
在这个例子中,CPU的icache_port为请求端口,cache的cpu side为响应端口。请求端口和响应端口各自可以在=的任意一次,实现的连接都是一样的。在完成这个连接之后,请求方可以响应方发送请求。此外,gem5的python脚本还允许一侧为一个端口,而另一侧为一组端口,例如:
system.cpu.icache_port = system.membus.cpu_side_ports
在这个例子中,CPU的icache_port为请求端口,内存总线的cpu_side_ports是一组响应端口。在这个例子中,cpu_side_ports上会生成一个新的响应端口,并且这个新创建的端口会连接到请求端口上。
接下来我们需要将一些其他的端口连接起来以确保系统功能正确。我们需要在CPU上创建一个I/O控制器并将其连接到系统总线。此外,我们需要将一个特殊端口从系统连接到内存总线。这个端口是一个仅功能的端口使得系统可以读写内存。
system.cpu.createInterruptController()
system.system_port = system.membus.cpu_side_ports
接着,我们需要创建一个内存控制器并将其连接到内存总线。对于该系统,我们使用一个简单的DDR3控制器,其负责访问系统的整个内存范围:
system.mem_ctrl = MemCtrl()
system.mem_ctrl.dram = DDR3_1600_8x8()
system.mem_ctrl.dram.range = system.mem_ranges[0]
system.mem_ctrl.port = system.membus.mem_side_ports
完成上述配置之后,系统架构图如下:
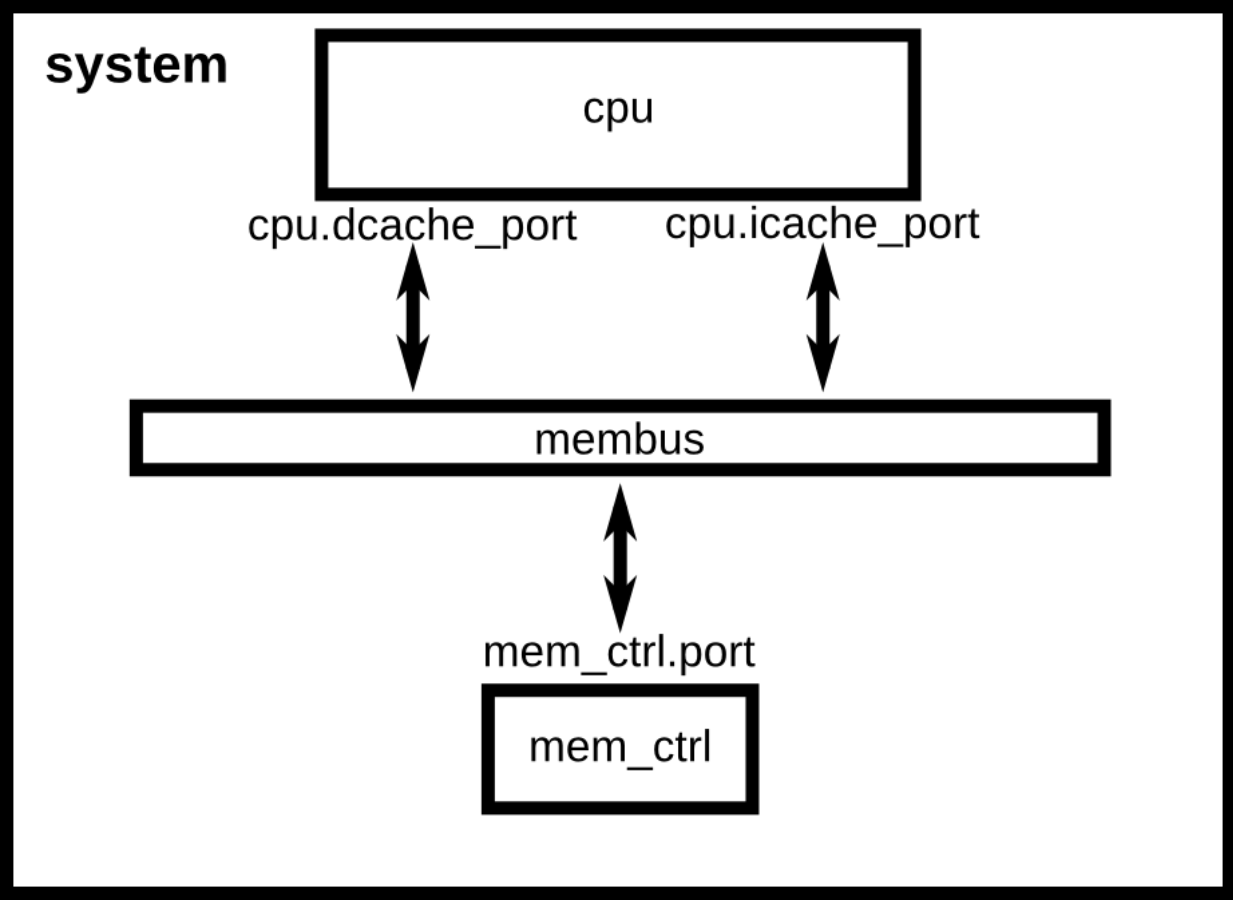
接下来我们需要设置CPU需要执行的进程,由于我们执行的是SE模式,我们只需要指定CPU的编译后的可执行程序即可。这里我们执行一个简单的“Hello World”程序。
这里需要额外注意的是,gem5可以分为全系统模式(full system,FS模式)和syscall 仿真模式(syscall emulation,SE模式)。在FS模式下,gem5仿真整个硬件系统并运行无修改的内核,FS模式类似于运行一个虚拟机。
而SE模式并不仿真系统中的所有设备,而是专注于仿真CPU和内存系统。SE相对来说更容易配置,因为不需要例化所有真实系统中需要的硬件设备。但是,SE在仿真功能上相对于FS也存在局限性。
如果针对研究问题没有建模整个系统的需求,并且希望有更好的性能的话,就应该使用SE模式。反之,如果需要高保真的系统建模,或者OS交互非常重要的情况下,应该使用FS模式。
首先我们需要创建进程(这也是一个SimObject),并且需要设定我们想要运行的进程程序,然后我们令CPU使用进程作为其工作负载,最后在CPU中创建功能执行上下文。
thispath = os.path.dirname(os.path.realpath(__file__))
binary = os.path.join(
thispath,
"../../../",
"tests/test-progs/hello/bin/riscv/linux/hello",
)
system.workload = SEWorkload.init_compatible(binary)
process = Process()
process.cmd = [binary]
system.cpu.workload = process
system.cpu.createThreads()
最后一步是例化系统并开始仿真。首先需要创建Root对象,然后例化仿真。例化的过程贯穿了我们用python创建的所有SimObjects并创建对应的C++等效。
需要注意的是,并不需要先例化python然后再去指定成员变量的具体参数,可以直接使用命名参数的方式来进行参数传递。例如:
root = Root(full_system=False, system=system)
m5.instantiate()
最终,我们可以开始实际的仿真了。
print(f"Beginning simulation!")
exit_event = m5.simulate()
print(f"Exiting @ tick {m5.curTick()} because {exit_event.getCause()}")
运行结果为:
python_envJ6JK212CLJ:gem5 bytedance$ build/RISCV/gem5.opt configs/deprecated/example/se.py -c tests/test-progs/hello/bin/riscv/linux/hello
gem5 Simulator System. https://www.gem5.org
gem5 is copyrighted software; use the --copyright option for details.
gem5 version 24.1.0.3
gem5 compiled May 22 2025 22:50:28
gem5 started Jun 24 2025 11:00:03
gem5 executing on J6JK212CLJ, pid 90723
command line: build/RISCV/gem5.opt configs/deprecated/example/se.py -c tests/test-progs/hello/bin/riscv/linux/hello
warn: The se.py script is deprecated. It will be removed in future releases of gem5.
Global frequency set at 1000000000000 ticks per second
warn: No dot file generated. Please install pydot to generate the dot file and pdf.
src/mem/dram_interface.cc:692: warn: DRAM device capacity (8192 Mbytes) does not match the address range assigned (512 Mbytes)
src/arch/riscv/isa.cc:280: info: RVV enabled, VLEN = 256 bits, ELEN = 64 bits
src/base/statistics.hh:279: warn: One of the stats is a legacy stat. Legacy stat is a stat that does not belong to any statistics::Group. Legacy stat is deprecated.
system.remote_gdb: Listening for connections on port 7000
**** REAL SIMULATION ****
src/sim/simulate.cc:199: info: Entering event queue @ 0. Starting simulation...
src/sim/mem_state.cc:448: info: Increasing stack size by one page.
Hello world!
Exiting @ tick 3306500 because exiting with last active thread context
结语
本文对gem5的基础概念进行了介绍,并对官方tutorial第一部分进行了翻译和整理,以展示gem5的基本使用方法。gem5实际上还有很多复杂的功能,待后面项目开发过程中再进行详细的整理和介绍。
gem5基础脚本搭建的更多相关文章
- IOS开发基础环境搭建
一.目的 本文的目的是windows下IOS开发基础环境搭建做了对应的介绍,大家可根据文档步骤进行mac环境部署: 二.安装虚拟机 下载虚拟机安装文件绿色版,点击如下文件安装 获取安装包: ...
- 【1】windows下IOS开发基础环境搭建
一.目的 本文的目的是windows下IOS开发基础环境搭建做了对应的介绍,大家可根据文档步骤进行mac环境部署: 二.安装虚拟机 下载虚拟机安装文件绿色版,点击如下文件安装 获取安装包: ...
- 01-Hadoop概述及基础环境搭建
1 hadoop概述 1.1 为什么会有大数据处理 传统模式已经满足不了大数据的增长 1)存储问题 传统数据库:存储亿级别的数据,需要高性能的服务器:并且解决不了本质问题:只能存结构化数据 大数据存储 ...
- 服务器脚本搭建国基北盛openstack平台
@ 目录 基础环境搭建 控制节点网卡配置 计算节点网卡配置 主机映射 3,关闭防火墙和selinux以及NetworkManager 设置yum源 计算节点分区 配置openrc.sh环境变量 平台组 ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- 用c#开发微信 (11) 微统计 - 阅读分享统计系统 1 基础架构搭建
微信平台自带的统计功能太简单,有时我们需要统计有哪些微信个人用户阅读.分享了微信公众号的手机网页,以及微信个人用户访问手机网页的来源:朋友圈分享访问.好友分享消息访问等.本系统实现了手机网页阅读.分享 ...
- EXT 基础环境搭建
EXT 基础环境搭建使用 Sencha CMD 下载地址 https://www.sencha.com/products/extjs/cmd-download/ Sencha CMD 常用命令 API ...
- Spark环境搭建(上)——基础环境搭建
Spark摘说 Spark的环境搭建涉及三个部分,一是linux系统基础环境搭建,二是Hadoop集群安装,三是Spark集群安装.在这里,主要介绍Spark在Centos系统上的准备工作--linu ...
- odoo10.0在odoo12.0环境的基础上搭建环境
在前边的文章中,讲述了如何搭建12.0的环境,现由业务的需要需要在此基础上搭建基于python2.7的10.0版本. 第一步,安装python2.7 sudo apt- 第二步,安装python-de ...
- Maven 学习笔记(一) 基础环境搭建
在Java的世界里,项目的管理与构建,有两大常用工具,一个是Maven,另一个是Gradle,当然,还有一个正在淡出的Ant.Maven 和 Gradle 都是非常出色的工具,排除个人喜好,用哪个工具 ...
随机推荐
- CF1956C Nene's Magical Matrix 题解
CF1956C Nene's Magical Matrix 被这题送走了,纪念一下. 巧妙的构造题,考虑比较方便处理的方案,假设我们从左上角的顶点开始涂,每次涂一个 \(1,2,3\dots n\) ...
- Windows Server 2016 - 关闭 按Ctrl+Alt+Del才能登录
在搜索中,搜索RUN.然后在RUN里搜索gpedit.msc,将其打开. 找到路径:计算机配置>Windows 配置>安全设置>本地策略>安全选项 启用"交互式登录: ...
- 认识Android Studio中各个模块
首先看看刚创建完的项目界面,除了菜单栏.工具栏等,没有什么可以编辑的界面 通过项目的文件浏览器可以打开所有项目文件,所以文件管理器在整个开发过程中相当重要. 其中用到最多的便是app项,其余大部分 ...
- Gym 102215 & 队内训练#5
A - Rooms and Passages 题意:找到每个数后面第一个负正对. 从前往后比较麻烦.从后向前,先记录正数位置,一旦出现这个数的相反数即产生一对负正对,通过和前面的负正对比较更新答案. ...
- 使用RestCloud ETL强大的自定义规则实现自定义数据处理算法
实时数据处理规则有什么作用? 在大数据中的实时数据采集.ETL批量数据传输过程中很多数据处理过程以及数据质量都希望实时进行处理和检测并把不符合要求的脏数据过滤掉或者进行实时的数据质量告警等. 在数据仓 ...
- JAVA基础-11-封装 继承 多态--九五小庞
1.封装 在面向对象程式设计方法中,封装(英语:Encapsulation)是指一种将抽象性函式接口的实现细节部分包装.隐藏起来的方法. 封装可以被认为是一个保护屏障,防止该类的代码和数据被外部类定义 ...
- SpringBoot0x00
Git版本控制 点击查看代码 git status//查看all文件 git add .//加入all文件 git commit -m "xxxxx"//命名本次迭代 git pu ...
- DeepSeek-R1详解
咱把这张 DeepSeek-R1 的架构图拆成几块唠,保证小白也能听懂!就当是带着大家"逛" 模型从训练到能用的 "流水线工厂",每个模块是干啥的.数据咋流动, ...
- 1003 Express Mail Taking
http://acm.hdu.edu.cn/contests/contest_showproblem.php?pid=1003&cid=909 Express Mail Taking Time ...
- claude code使用
白嫖了cursor半年多了,虽然免费的模型能满足日常开发,但是完成一个任务还是需要不停的修修改改,浪费的时间基本上太多了.听说claude code很强大,先试试它了. claude code刚出来的 ...