AI一周资讯 250926-251005

原文: https://mp.weixin.qq.com/s/fjXai70ijKlfqWYAVgLaYw
Meta LeCun团队开源首款代码世界模型CWM:用世界模型预测代码效果,32B参数跻身开源代码生成第一梯队
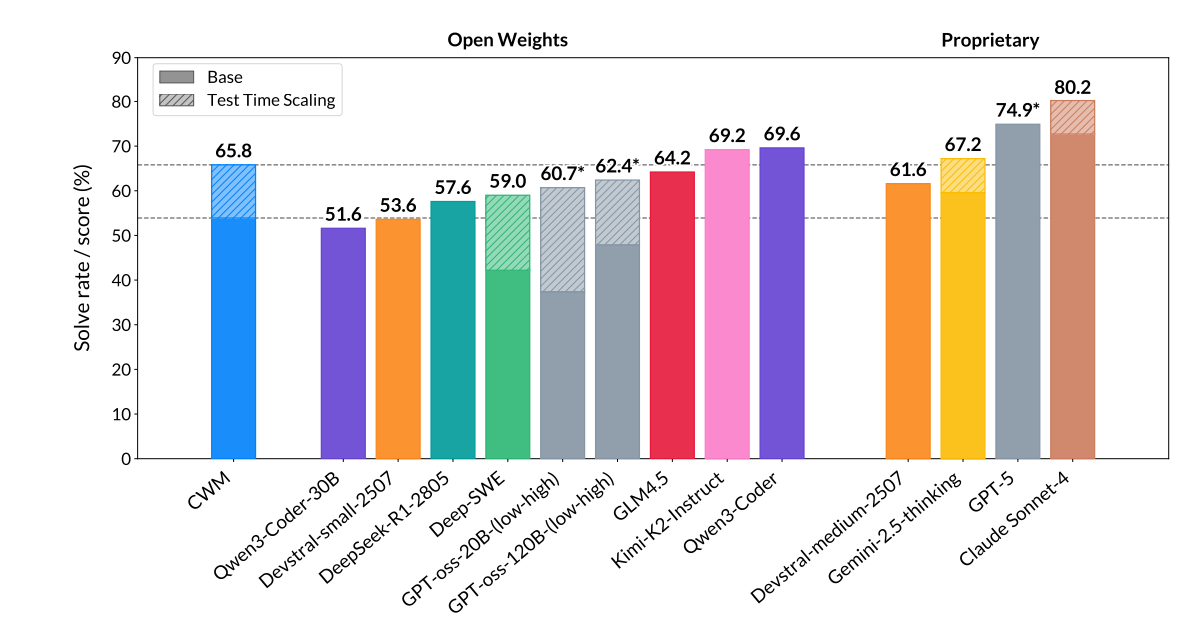
Meta由LeCun团队开源首款代码世界模型CWM(Code World Model),核心创新是将世界模型引入代码生成任务,通过提前预测代码指令效果规划满足需求的代码;模型基于大量编程数据及定制Python、Bash世界建模数据训练,可模拟Python程序在Bash环境中的执行及与Agent交互,提供3个32B参数的Checkpoint。性能上,SWE-bench Verified(真实开源项目缺陷修复评测)得65.8%(开源第一梯队,接近闭源Gemini-2.5-Thinking),LiveCodeBench得68.6%,Math-500得96.6%,AIME 2024得76.0%,为概念验证项目,以小参数模型检验世界模型对代码生成质量的提升效果。
- 论文:https://ai.meta.com/research/publications/cwm-an-open-weights-llm-for-research-on-code-generation-with-world-models/
- github: github.com/facebookresearch/cwm
- Model weights: : ai.meta.com/resources/models-and-libraries/cwm-downloads, huggingface.co/facebook/cwm, ../cwm-sft, ../cwm-pretrain
谷歌曝光Gemini 2.5 Flash-Lite驱动的“神经操作系统”原型:大模型即时生成动态UI,重新定义人机交互?
谷歌近日展示由Gemini 2.5 Flash-Lite驱动的“神经操作系统”原型,其UI由大模型即时生成并可根据用户交互动态调整。该原型核心技术包括“UI章程+UI交互”的模型输入结构(平衡界面一致性与动态生成)、交互追踪(增强上下文相关性)、流式生成结合React渐进式渲染(实现界面几乎瞬间响应)、生成式UI图谱(解决模型无状态问题);实际可应用于生成临时UI面板(如航班比价浮动窗)、应用内添加生成模式开关(如谷歌日历解决日程冲突)等场景,谷歌称其代表人机交互未来研究方向。
生数科技Vidu Q2全球上线:AI视频生成从“形似”跨入“神似”新阶段
2025年9月25日,生数科技新一代图生视频大模型Vidu Q2全球上线,标志AI视频生成技术从追求“形似”进入“神似”阶段,实现从“视频生成”到“演技生成”、“动态流畅”到“情感表达”的革命性跨越,解决了原有AI视频表情假、动作飘、运动幅度小、无法精准控制等问题。对比Vidu Q1,其核心亮点包括:AI演技更生动,攻克细微表情生成技术,可呈现复杂情绪转换(如复刻《甜蜜蜜》张曼玉片段的微笑-委屈-难过)、支持大幅运动及多人打戏(如双人拳击、悟空小林对战),角色一致性高;镜头语言更丰富,能实现宏观全景到微观特写快速切换及复杂运镜(如F1赛车多镜头调度);语义理解更准确,通过上下文推理、物理仿真等能力严格遵循复杂提示词(如猫弹古筝生成骷髅战士的分秒级要求),减少反复生成;时长选择更自由,支持2-8秒,突破行业普遍5秒限制。模型分为闪电模式(20秒生成5秒1080P视频)与电影大片模式,Web端、APP端及API同步上线,预计在影视短剧、数字人、广告营销等领域推动AI视频大规模商业化拐点。
京东AI系统性开源全栈核心项目:覆盖Agent/大模型/推理框架,提供生产级落地方案
京东AI近期系统性开源核心项目,覆盖Agent、大模型、推理框架、模型安全等全栈能力,瞄准产业落地痛点提供生产级、开箱即用解决方案。其中,JoyAgent 3.0是首个100%开源企业级智能体平台,升级DataAgent(集成数据治理DGP协议、智能问数等)和DCP数据治理模块,支持自然语言问数、复杂问题诊断分析,采用两阶段动态选表等TableRAG技术及SOPPlan模式,GAIA验证集准确率77%、BIRD-Bench Test集75.74%,经京东内部3万+智能体实践;OxyGent多智能体框架纯Python实现,以Oxy原子组件(工具、模型、智能体)为核心,切面设计统一生命周期,支持可视化推理洞察,GAIA评测59.14分;京医千询2.0是行业首个突破可信推理及全模态能力的医疗大模型,模拟医生临床思维、融合循证医学证据,支持文本/影像/检验报告等多模态解析及多步多源融合推理,已落地多家医院、健康管理中心;xLLM推理框架采用服务-引擎分离创新架构,推动国产AI Infra从跟随后定义新一代推理标准,京东零售用其实现5倍效率提升、90%成本优化;JoySafety大模型安全提供全链路防护方案,以可插拔安全原子能力+DAG策略编排为核心,内置敏感词识别等能力,独有“流式输出检测+撤回”机制(毫秒级风险判断、中断输出),京东内部验证将恶意攻击/提示词注入成功率降95%以上,支持Docker一键部署;此外还有向量数据库Vearch、跨端开发框架Taro等开源项目,形成全栈覆盖的开源体系。
夸克发布「造点AI」:Midjourney V7生图半价,通义万相Wan2.5生视频限时免费
夸克于2025年9月24日推出AI创作平台「造点AI」,集成AI生图(Midjourney V7、夸克图像1.0)与AI生视频(通义万相Wan2.5)功能。其中,Midjourney V7模型输出效果与原生一致,支持参考图、提示词润色、风格化(0-1000)等滑块及--sref(风格参考)、--profile(个人风格)参数,定价48元/月生成400张(约海外版8美元/月200张的半价);夸克图像1.0擅长亚洲人像、中文内容及传统国风元素,适用于电商、广告等场景。AI生视频同步接入9月24日上新的通义万相Wan2.5,支持音画同步生成、10秒1080P/24fps输出、复杂指令(镜头运动、场景变化)、人物一致性及音频驱动(上传音频生成匹配画面),9月24日至30日体验该模型生成视频可享7天限时免费。
阶跃AI推出桌面AI伙伴「小跃」:常驻桌面的多任务助手,支持自主复杂任务与妙计复用,Mac版邀测中
阶跃AI近日推出桌面伙伴「小跃」,该工具常驻桌面右上角,具备多任务并行能力,可自主执行复杂任务(如基于小红书OPPO动效设计师面经生成面试经验文档、监测亚马逊北美市场24小时销量飙升榜前二品类及对应前三商品并生成html看板),还支持定时任务与系统提醒(如设置事项提醒)、本地文件处理(整理桌面发票、计算1688商品美元价格并对比亚马逊同款差价);同时拥有「妙计」功能,可复用操作步骤(如「/设置提醒」「表单填写」)。未来「小跃」将支持语音输入、记住用户习惯、构建个性化操作界面及分享「妙计」,并提供喝水、久坐站立提醒等关怀功能。目前「小跃」开启邀请测试,仅开放Mac版本,Windows版本正在开发中;用户可通过在评论区留言最希望小跃完成的高频任务或进入官方体验群获取邀请码。

实现“边听边说”类人交互!首个“自然独白+双训练范式”原生全双工语音对话大模型发布
北京智源人工智能研究院联合Spin Matrix与新加坡南洋理工大学发布RoboBrain-Audio(FLM-Audio),这是首个支持“自然独白+双训练范式”的原生全双工语音对话大模型。该模型突破传统时分复用(TDM)架构高延迟、难处理频繁打断的局限,及现有原生全双工模型依赖词级对齐、破坏语言模型能力的问题,实现“边听边说”的类人交互(打断响应延迟最低80ms,可0.5秒内停止当前输出响应新输入)。
核心创新包括:一是自然独白对齐机制,弃用词级时间戳,采用句级标注,先生成完整句子再异步生成语音,保留语言模型连贯性,解决上下文依赖发音问题(如数字“2025”的语境化发音);二是双训练范式,后训练阶段使用100万小时音频-文本对及开源精标数据,交替“TTS风格(文本领先,模拟语音合成)”“ASR风格(语音领先,模拟语音识别)”训练,赋予“听”(ASR)“说”(TTS)基础能力;有监督微调阶段用20万条合成多轮对话数据(700+人声),分SFT-1(半双工过渡,融合“ASR-Response-TTS”)和SFT-2(全双工最终,直接从音频理解意图处理随机打断)两步。实验表现上,音频理解方面,中文ASR(Fleurs-zh)优于Qwen2-Audio,LibriSpeech-clean上优于同架构的Moshi(用更少数据);音频生成方面,TTS的WER与Seed-TTS等专业模型接近;全双工对话方面,文本内容质量接近Qwen2.5-Omni,流畅度、响应速度更优。生态意义上,作为RoboBrain系列关键能力载体,赋能具身智能体语音交互,与RoboBrain的感知、规划能力结合,加速构建“听懂人话、看懂世界、动手做事”的机器人智能体。

- Github:https://github.com/cofe-ai/flm-audio
- huggingface: https://huggingface.co/CofeAI/FLM-Audio
- 论文:https://arxiv.org/abs/2509.02521
ChatGPT变主动了!新功能Pulse每晚研究你,清晨推专属内容卡片
2025年9月26日,OpenAI宣布推出ChatGPT新功能「Pulse」预览版,首先向Pro订阅用户开放。Pulse是基于智能体的功能,ChatGPT每晚主动结合用户聊天记录、反馈及关联的日历等应用进行研究,次日清晨在手机App推送含AI生成配图的个性化内容卡片,内容涵盖之前聊过的具体话题、生活建议(如健康晚餐创意)、长期目标后续步骤等;用户可链接Gmail和Google日历(默认关闭,可在设置调整)以获取更相关建议(如起草会议议程、提醒买生日礼物、推荐旅行餐厅);还可请求ChatGPT每天搜索互联网内容(如周五本地活动综述、学新技能技巧、关注职业网球动态等),并通过点赞/踩反馈优化内容,查看/删除反馈历史。该功能经过安全检查避免有害内容,未来将推广至Plus用户。OpenAI CEO山姆·奥特曼称其为“迄今为止最喜欢的ChatGPT功能”,认为这是ChatGPT从被动转向主动、提供高度个性化服务的未来方向,也是走向实用化的第一步;用户反馈内容具体有用,已有工程师用其跟踪AI领域论文。
DeepMind发布Gemini Robotics 1.5系列:专为机器人与具身智能设计的“决策+执行”双模型组合
DeepMind发布专为机器人和具身智能打造的Gemini Robotics 1.5系列模型,包含两款核心模型——Gemini Robotics 1.5(视觉-语言-行动模型,可将视觉信息与指令转化为机器人运动指令,能反思行为、解释思考过程)与Gemini Robotics-ER 1.5(视觉-语言模型,擅长物理世界推理、多步骤计划、空间理解、自然语言交互,支持调用谷歌搜索等工具,为前者提供步骤指令)。
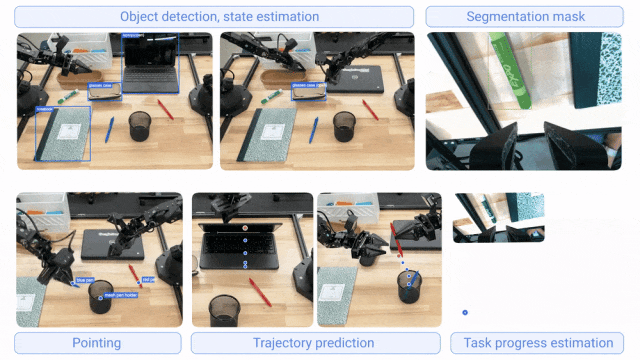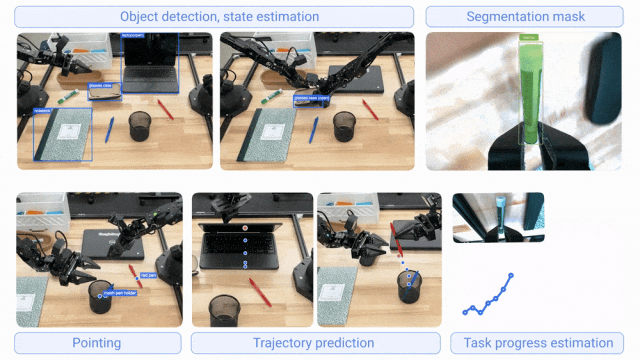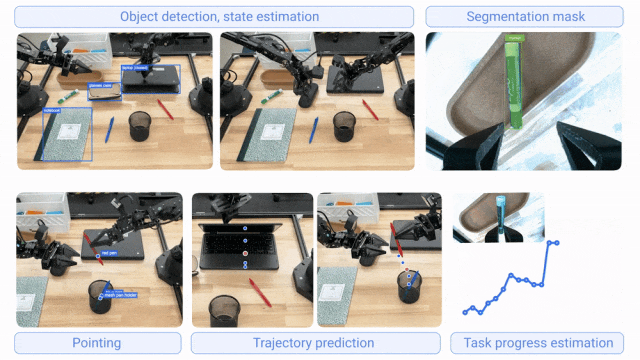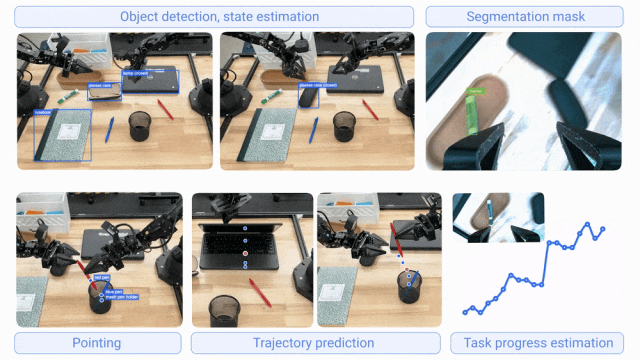
两者基于核心Gemini模型家族构建,通过不同数据集微调专精各自职能;协同工作时,Gemini Robotics-ER 1.5负责规划决策,Gemini Robotics 1.5负责执行动作,显著提升机器人对长周期任务与多样化环境的泛化能力。其中,Gemini Robotics-ER 1.5具备物体检测、状态估计、分割掩码、指向识别、轨迹预测、任务进度评估等能力;Gemini Robotics 1.5具备跨具身学习能力(可将一个机器人的动作迁移至另一个机器人,无需专门调整模型),支持复杂环境多步骤任务执行。
- 官网介绍:https://deepmind.google/discover/blog/gemini-robotics-15-brings-ai-agents-into-the-physical-world/
Kimi发布像素风Agent模型「OK Computer」:覆盖设计/生成/分析多任务,进度可视化超省心
Kimi基于Kimi K2推出全新Agent模型「OK Computer」,界面采用像素风设计。实测其功能覆盖三类任务:设计类可自主完成Pygame网页制作(含发展历程、试玩游戏等模块,自动搜索素材、编程部署)及中国十大原创音乐剧PPT制作(输出可编辑文件但第6-10部未完成);生成类能完成儿童故事绘本的编创、可视化、音频匹配及多模态结合;分析类可包办月之暗面2025年财务数据搜集分析及本地长Excel文件处理。模型特点包括任务过程用Todo List标记进度(“x”完成、“-”进行中),设计类无需找素材,分析类无需想评估角度,生成类可推荐风格,名字源于《银河系漫游指南》中人类与机器掌控权反转的设定。

腾讯混元3D推出业界首个高质量原生3D组件生成模型Hunyuan3D-Part
腾讯混元3D团队推出业界首个高质量原生3D组件生成模型Hunyuan3D-Part,针对现有组件式3D生成可控性、几何质量、语义连贯性不足的问题,通过P3-SAM原生3D分割模型(基于PointTransformerV3,利用大规模3D部件数据集训练,实现精确鲁棒的自动组件分割)和X-Part工业级组件生成模型(以包围盒为提示、结合语义特征扰动,生成高保真、结构一致的部件),解决组件式3D生成关键痛点,在PartObj-Tiny等数据集上效果超越现有工作。
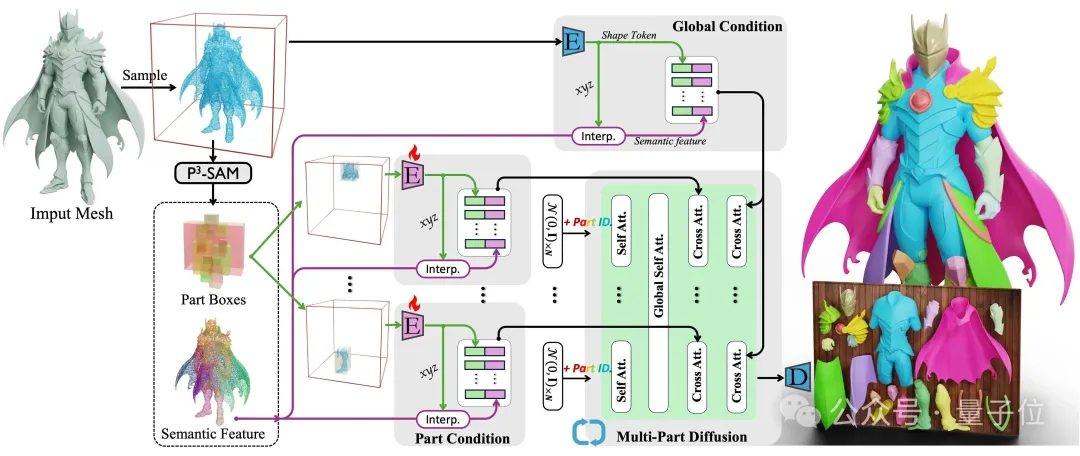
- Github:https://github.com/Tencent-Hunyuan/Hunyuan3D-Part
- huggingface:https://huggingface.co/tencent/Hunyuan3D-Part
- 论文(P3-SAM):https://arxiv.org/abs/2509.06784
- 论文(X-Part):https://arxiv.org/abs/2509.08643
- 体验地址(轻量版):https://huggingface.co/spaces/tencent/Hunyuan3D-Part
- 体验地址(满血版):https://3d.hunyuan.tencent.com/studio
AI影视本周大事件:釜山电影节展5部全AI作品,博纳升级AI制作,虚拟歌手破千万,奥斯卡允许AI参评
本周AI影视领域动态频出:2025年第30届釜山国际电影节“未来影像”AI电影国际峰将展映5部依托火山引擎Seedance视频生成、Seedream图像创作模型的即梦AI作品,包括香港首部全AI短片《九宵》(17分钟剧情片,通过AI生成镜头+动捕修正实现角色微表情与场景连贯)、《权利游戏》(长镜头时空转场女性主义主题)等,体现AI从“生成影像”到“读懂叙事”的跨越;
博纳影业2023年底成立国内首个AI制作中心,联合抖音、即梦AI推出《三星堆:未来启示录》,第一季采用“AI+”模式(AI生成大量内容+人工筛选),第二季升级为“+AI”模式(结合传统电影工业流程,用火山引擎模型提升院线级成片水准,目前进入最终制作阶段),还打造“博卡短剧平台”“博卡圆桌—剧本生成平台”实现“一句话成片”与年轻创作者发掘;
超级个体案例中,《九宵》20人团队用AI解决3D制作中角色造型/服装频繁更换的成本问题(传统流程难实现),耗时4个月训练模型保证人物稳定性与背景衔接;AI Talk(5-6人团队)用OmniHuman(1.5版提升“活人感”:手部配合动作、镜头切换、表情自适应音乐)及火山Seedream 4.0(4K画面)、Seedance 1.0 Pro(缩短创意到成品时间)打造虚拟歌手Yuri,其首支歌曲《Surreal》播放量破1100万。
技术方面,AI视频生成已能支撑高质量剧情长片,但“一键生成”仍遥远,现有模型在长镜头(超5秒稳定性下滑)、物理规律理解(人物与道具同框时比例/透视失真)等方面存在瓶颈,火山引擎总裁谭待强调模型需掌握物理规律才能生成逼真影像;
行业趋势上,美国电影艺术与科学学院2026年起允许AI参与创作的影片参评奥斯卡,影视行业从抵触到接受AI,核心是“工具变但故事渴望永恒”,创作者的艺术鉴赏力与思想表达是稀缺资源。
OpenAI「GPT门」引争议:未经同意切换敏感模型,用户质疑付费权益与选择权
近期,OpenAI被曝未经用户同意,将ChatGPT的GPT-4、GPT-5等模型强制路由至两款未公开的低算力敏感模型「gpt-5-chat-safety」(处理敏感/情感话题)与「gpt-5-a-t-mini」(高敏感度推理模型),导致回复被过滤或替换,引发用户对选择权、付费权益的质疑,被X网友称为「GPT门」事件。
该现象已被社交媒体广泛验证,例如用户使用非推理模型的GPT-4o时,输入「illegal」会触发切换至gpt-5-a-t-mini;还有用户反映选择GPT-4.5时被路由至GPT-5系列模型,而GPT-5在LMArena竞技场中表现落后于o3、4o等版本。
对此,OpenAI副总裁兼ChatGPT APP主管Nick Turley回应称,此为测试新的安全路由系统,当对话涉及敏感和情感话题时,会临时切换至专门处理的模型,目前询问后ChatGPT会告知当前模型。但用户批评此举涉嫌欺骗性商业行为(如澳大利亚用户指违反消费者权益法),类比「买可口可乐却装橙汁」,并强调开源模型的重要性以避免被专有模型供应商掌控服务。
- 参考资料1(Tibor Blaho的X推文): https://x.com/btibor91/status/1971959782379495785
- 参考资料2(CGoodman308的X推文): https://x.com/CGoodman308/status/1971968119808970782
- 参考资料3(Nick Turley的回应): https://x.com/nickaturley/status/1972031684913799355
- 参考资料4(Reddit讨论): https://www.reddit.com/r/singularity/comments/1ns5fhy/reports_openai_is_routing_all_users_even_plus_and/
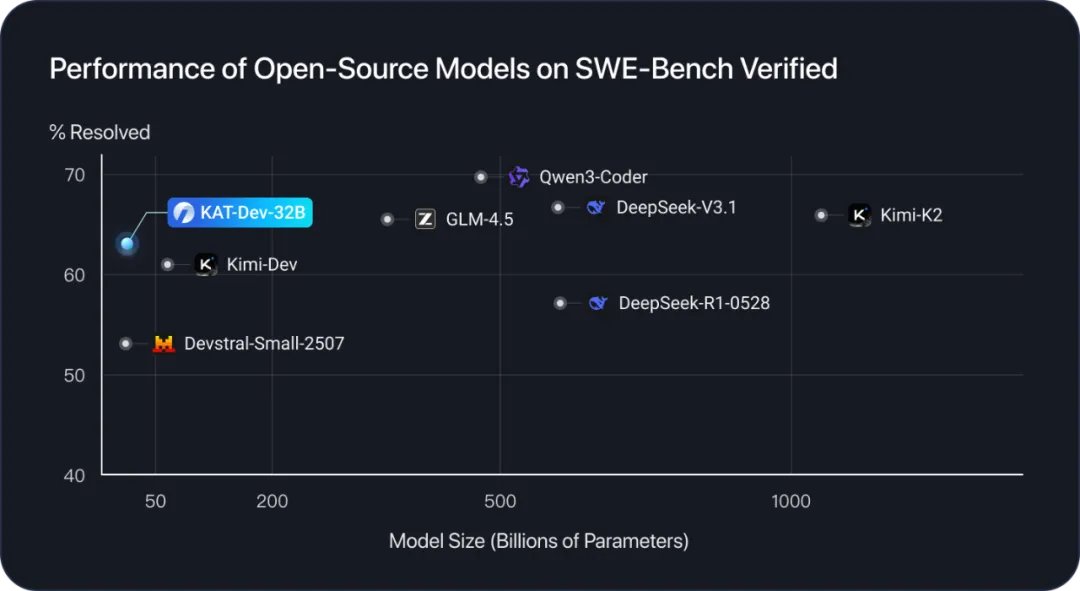
快手Kwaipilot推出KAT系列Agentic Coding大模型:开源32B+闭源旗舰,SWE-Bench解决率达73.4%
近日,快手Kwaipilot团队推出KAT系列Agentic Coding大模型,包含开源32B参数模型KAT-Dev-32B与闭源旗舰模型KAT-Coder。性能上,KAT-Dev-32B在SWE-Bench Verified上获62.4%解决率(开源模型第5),KAT-Coder以73.4%解决率比肩顶尖闭源模型。
开源与API方面,KAT-Dev-32B已在Hugging Face开源,KAT-Coder API密钥可通过“快手万擎”申请,支持Claude Code等工具访问。技术路线采用四阶段训练:Mid-Training增强Agent能力,SFT覆盖8大任务与场景,RFT用“教师轨迹”连接SFT与RL,大规模Agentic RL含熵轨迹剪枝、自研SeamlessFlow框架及企业级代码训练。
效果上,KAT-Coder可独立完成项目开发(如水果忍者游戏),涌现能力表现为对话轮次降32%、多工具并行调用。未来将深化IDE集成、扩展多语言、探索多智能体协作及多模态代码智能。
- 官方技术Blog:https://kwaipilot.github.io/KAT-Coder/
- huggingface:https://huggingface.co/Kwaipilot/KAT-Dev
- KAT-Coder开发工具接入指南:https://www.streamlake.com/document/WANQING/me6ymdjrqv8lp4iq0o9
- KAT-Coder API Key申请:https://console.streamlake.com/wanqing/
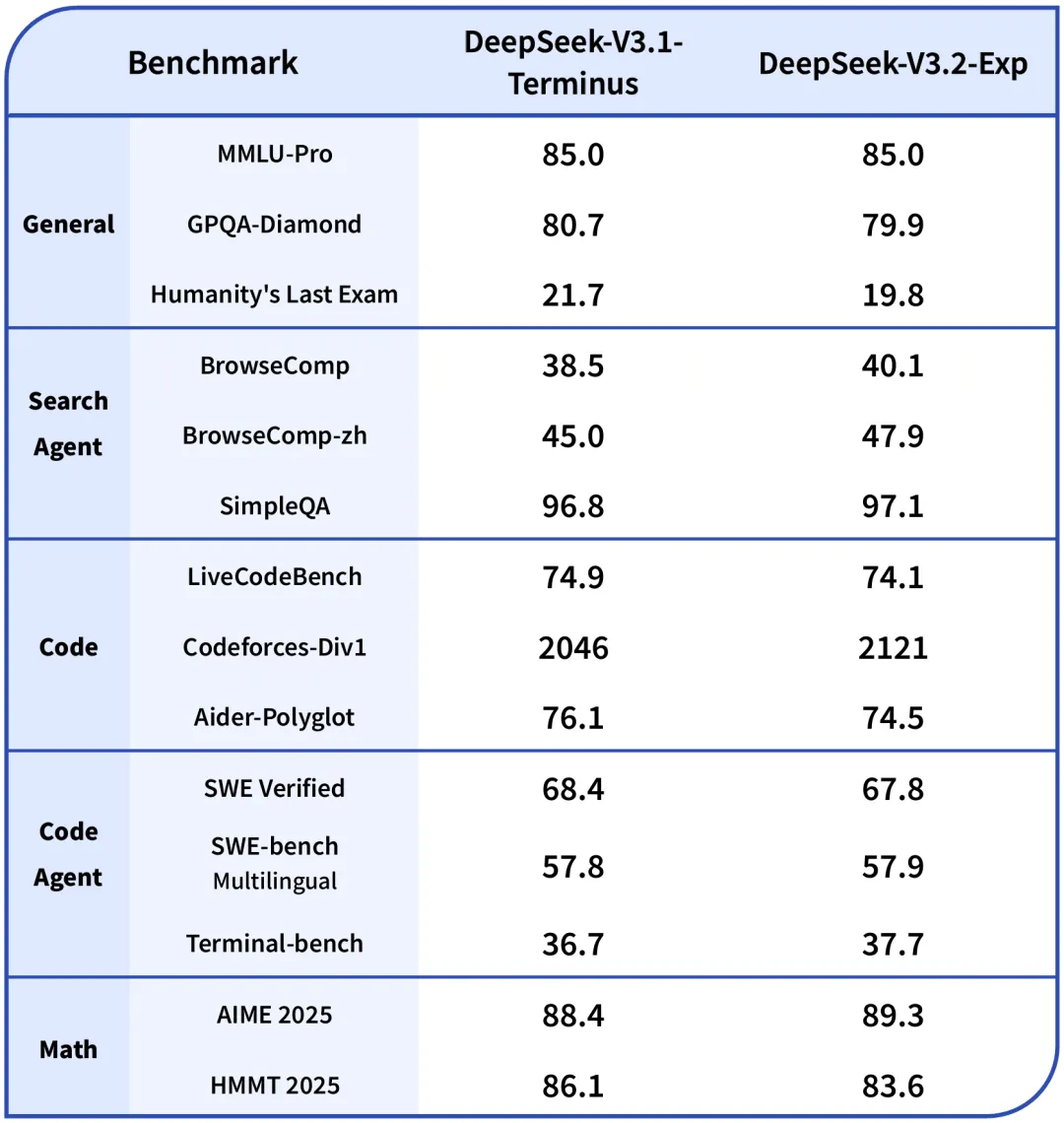
DeepSeek发布V3.2-Exp实验模型:DSA稀疏注意力提升长文本效率,API价格下调超50%
2025年9月29日,DeepSeek正式推出实验性版本DeepSeek-V3.2-Exp模型。该模型基于V3.1-Terminus引入DeepSeek Sparse Attention(DSA)细粒度稀疏注意力机制,在各领域公开评测集表现与V3.1-Terminus基本持平(几乎不影响输出效果)的前提下,实现长文本训练与推理效率大幅提升,目前官方App、网页端、小程序均已同步更新至该模型。同时,模型及相关资源同步开源:模型已在HuggingFace、ModelScope平台发布,同步公开技术论文,研究过程中设计的TileLang与CUDA算子也已开源(建议社区研究性实验使用TileLang版本调试迭代,高效部署使用CUDA版本)。
API服务同步优化:因新模型服务成本大幅降低,官方API价格下调50%以上,即刻生效,API模型版本为DeepSeek-V3.2-Exp,访问方式保持不变;为支持真实场景对比测试,V3.1-Terminus临时保留额外API接口(修改base_url="https://api.deepseek.com/v3.1_terminus_expires_on_20251015"即可访问),调用价格与V3.2-Exp一致,接口保留至2025年10月15日23:59,详细使用方法参考官方API文档;欢迎用户通过反馈链接提供测试意见。
- Github:https://github.com/deepseek-ai/DeepSeek-V3.2-Exp
- huggingface: https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
- 论文:https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
- 体验地址:https://chat.deepseek.com/
智源开源通用「小脑基座」RoboBrain-X0:破解机器人「一机一调」难题,实现跨本体零样本泛化
智源研究院在2025机器人学习大会(CoRL)上开源通用「小脑基座」RoboBrain-X0,旨在破解机器人产业「一机一调」开发困境。该基座源自RoboBrain多模态基座能力,融合真实机器人动作数据,通过统一建模视觉、语言与动作实现跨本体泛化与适配,具备感知到执行的一体化能力;其通过预训练即可实现多类真实机器人基础操作的零样本跨本体泛化,结合小样本微调可进一步释放复杂任务跨本体泛化潜力。
核心技术支柱包括:①学习任务「物理本质」而非具体动作,生成与机器人「身体」无关的通用语义动作序列,通过「本体映射机制」实时翻译为具体机器人可执行指令;②引入统一动作表征体系(Unified Action Vocabulary, UAV),通过动作tokenizer将末端执行器空间运动(位置、姿态、夹爪状态等)压缩为token序列,实现跨本体一致性与高效推理;③分层推理框架,将控制流分解为任务意图解析、通用动作转换、本体适配控制三层,保障迁移性与可解释性。配套开源跨本体真机数据集,包含视觉与语义理解数据、开源动作数据整合(如Agibot World)、本体厂商合作数据、自采「指令—动作」「指令—子任务推理—动作」样本,支持多本体迁移、长时序控制等研究。
评测表现方面,在LIBERO仿真平台综合成功率达96.3%,超越π0;真机跨本体评测总体成功率48.9%(为π0近2.5倍),基础抓放任务成功率100%。此外,智源此前还开源了面向真实物理环境的「通用具身大脑」RoboBrain 2.0 32B版本(时空认知突破,多项具身基准刷新纪录),以及全球首个具身智能SaaS开源框架RoboOS 2.0(集成MCP协议与无服务器架构,轻量化部署,打通大脑与异构本体协同通路)。
- Github:https://github.com/FlagOpen/RoboBrain-X0
- huggingface:https://huggingface.co/FlagRelease/RoboBrain-X0-FlagOS
- 核心训练数据集:https://huggingface.co/datasets/BAAI/RoboBrain-X0-Dataset
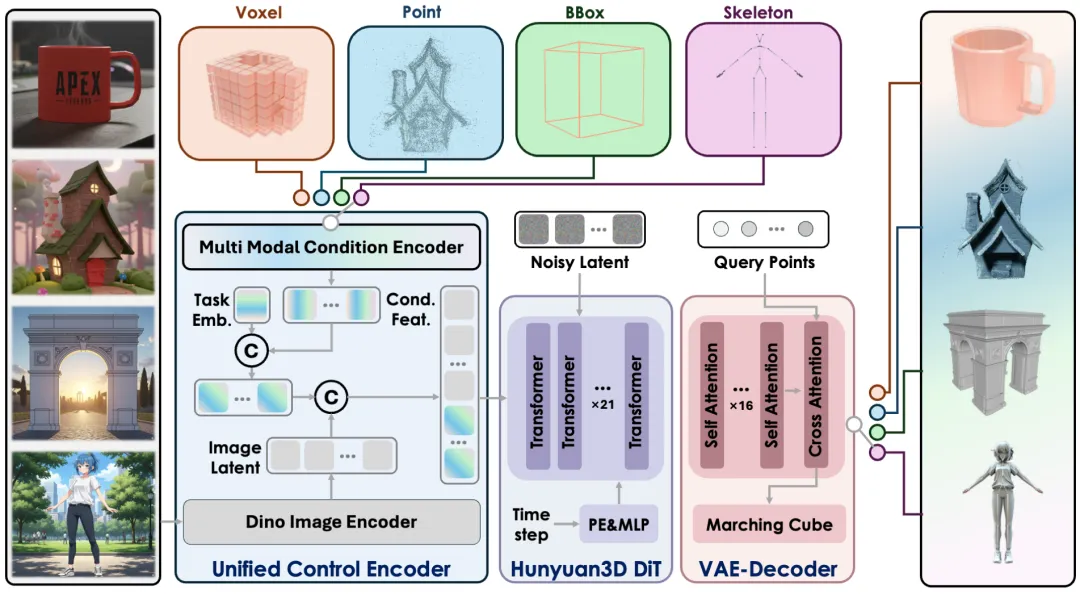
腾讯混元推出3D-Omni:统一多模态可控3D生成框架,破解图像依赖与细粒度控制难题
腾讯混元团队推出基于Hunyuan3D 2.1构建的统一多模态可控3D生成框架“混元3D-Omni”,针对现有3D生成模型依赖图像输入、缺乏细粒度多模态控制的痛点,核心创新包括轻量化统一控制编码器(将骨骼姿态、边界框、点云、体素四类控制信号统一表示为点云形式,提取特征后与图像DINO特征拼接作为DiT联合输入,区分不同模态避免混淆)和渐进式难度感知训练策略(训练时随机选择控制条件,偏向采样难度高的信号如骨骼姿态、降低简单信号如点云权重,提升多模态融合鲁棒性与输入缺失容错性);架构延续Hunyuan3D 2.1的VecSet表示3D VAE+潜在扩散模型(LDM)主干,3D VAE将输入点云编码为潜在表示,解码器重建SDF场并提取网格,扩散阶段采用流匹配LDM。
实验结果显示,该框架可实现高精度可控生成:骨骼控制能精准生成对应姿态的角色几何,边界框可调节物体比例(如沙发增加长度时自动生成支撑腿)、解决单图生成“纸片”问题,点云(含完整、深度图生成、噪声点云)缓解单视图歧义、还原遮挡结构与尺度对齐,体素提供稀疏几何线索、提升比例与细节重建准确性。目前框架已开放推理代码及权重,推动可控3D生成的学术研究与工业落地。
- Github:https://github.com/Tencent-Hunyuan/Hunyuan3D-Omni
- huggingface:https://huggingface.co/tencent/Hunyuan3D-Omni
- 官网介绍:https://3d.hunyuan.tencent.com
- 论文:https://arxiv.org/pdf/2509.21245
浪潮信息刷新AI推理天花板
在 2025 人工智能计算大会上,浪潮信息凭借两款 AI 服务器连破国内纪录,为智能体产业化提供关键支撑:基于元脑 SD200 超节点 AI 服务器,DeepSeek R1 大模型实现8.9 毫秒的国内最快 Token 生成速度,且单机可承载 4 万亿参数模型、通信延迟低至 0.69 微秒;基于元脑 HC1000 超扩展 AI 服务器,依托创新 DirectCom 极速架构,首次将推理成本击破1 元 / 每百万 Token,同时两款产品分别适配低延迟敏感场景与大规模降本需求,通过软硬件协同创新突破 GPU 主导架构的瓶颈,助力智能体跨越 “技术可用到商业可持续” 的关键门槛。

Google: Vercel 基于 Gemini 和 AI SDK 构建的市场研究代理
使用Gemini和Vercel AI SDK构建的自动化市场调研工具可以自动收集市场趋势数据,提取结构化数据并通过Chart.js进行可视化,最终生成整合分析和图表的HTML报告并转换为PDF。教程提供了详细步骤和代码示例,适合快速上手Gemini的用户,也可用于竞争对手分析和行业趋势预测。
Meta: 开源SOTA 级视觉基础模型DINOv3
DINOv3是一款采用自监督学习的通用视觉基础模型,70 亿参数,训练数据达17 亿张图像,首次实现自监督全面超越弱监督。其在密集预测任务(如目标检测、语义分割)表现突出,具备高分辨率、密集特征与高精度,无需微调即可实现 SOTA 性能,还提供系列可部署模型,在卫星影像、医学诊断等领域已有实际应用
- 论文:https://ai.meta.com/research/publications/dinov3/
- huggingface:https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- 官方介绍:https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
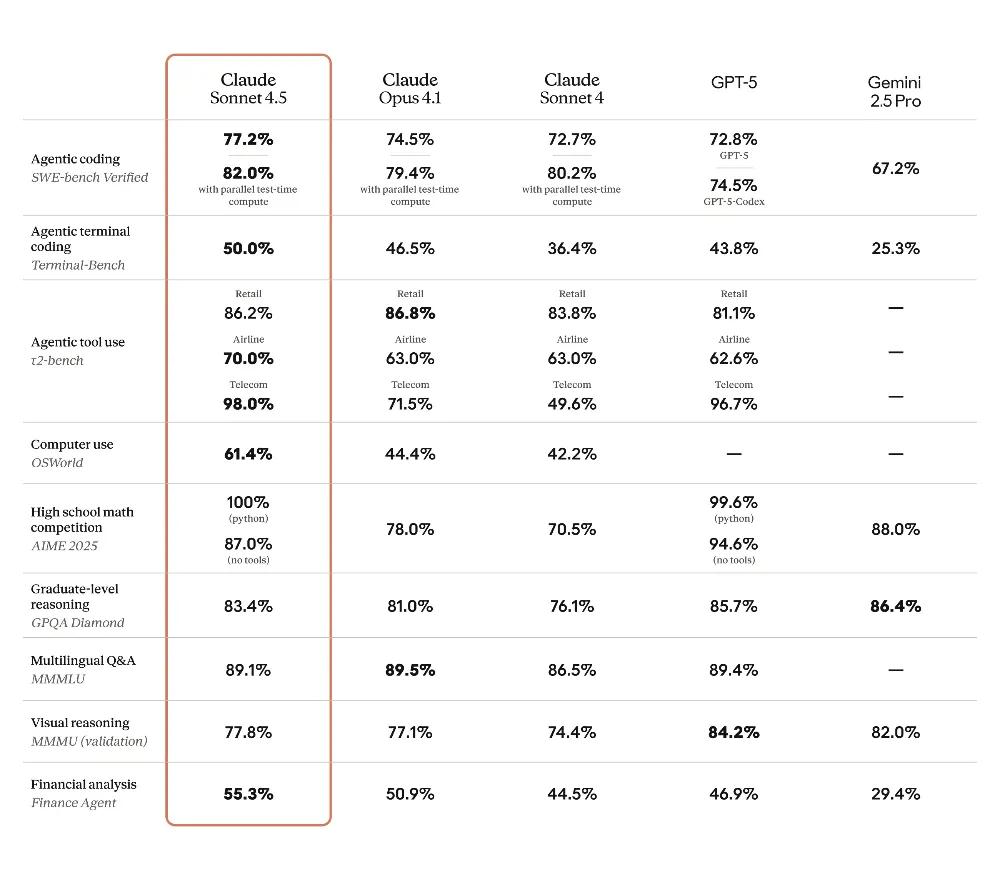
Claude Sonnet 4.5重磅发布!编程推理超越GPT-5,VS Code插件+情境管理功能开放公测
2025年9月30日,Anthropic正式发布Claude Sonnet 4.5,其编程、推理等能力全面超越GPT-5,计价与Claude Sonnet 4一致(输入每百万tokens 3美元,输出每百万tokens 15美元)。核心性能上,该模型在SWE-bench Verified(真实编程能力)评测中稳居榜首,在OSWorld(AI计算机操作能力)基准中以61.4%得分率获第一(较Sonnet 4的42.2%提升显著),可持续处理复杂任务超30小时,在推理、数学等多维度超越GPT-5,法律、金融等专业领域知识与推理能力较旧版(含Opus 4.1)进步明显,且是Anthropic迄今价值观对齐性最高的系统(自动化行为审计失当评分更低)。
同时,Claude Code升级:推出原生VS Code扩展插件(支持侧边栏、行内差异对比)、终端2.0(状态可视化+可搜索历史)、检查点功能(回退代码/对话),并开放Claude Agent SDK(新增子智能体与钩子函数);Claude开发者平台新增情境编辑(自动清理陈旧工具调用,降低84%token消耗)、记忆工具(跨会话存储信息),两者结合使智能体性能提升39%。目前,以上功能已在Claude开发者平台、Amazon Bedrock及Google Cloud Vertex AI开放公测。
蚂蚁百灵开源万亿参数推理大模型Ring-1T-preview:数学推理逼近GPT-5,多任务性能超越Gemini-2.5-pro
2025年9月30日,蚂蚁百灵大模型开源万亿参数(1000B)推理大模型Ring-1T-preview(完整版仍在训练中)。该模型延续Ling 2.0的MoE架构,在20T高质量语料上预训练,结合棒冰(icepop)方法及自研开源高效强化学习系统ASystem进行推理能力RLVR训练;目前存在语种混杂、推理重复、身份认知错误等问题。
测试表现方面,其在AIME 2025纯自然语言推理得92.6分,逼近GPT-5 with thinking(no tools)的94.6水平;在HMMT 2025、竞赛级代码生成任务LiveCodeBench v6、CodeForces及抽象推理基准ARC-AGI-1等任务中超越Gemini-2.5-pro和DeepSeek-V3.1-Terminus-Thinking;接入多智能体框架AWorld后,在IMO 2025中仅用一次推理解出第3题,第1、2、4、5题能一次性给出部分正确答案。此外,蚂蚁百灵自2025年3月起持续迭代,9月先后开源Ling-mini-2.0、推出Ring-mini-2.0等模型,上周五开源Ring-flash-linear-2.0、Ring-mini-linear-2.0,同步发布FP8融合算子、线性Attention推理融合算子。

- huggingface: https://huggingface.co/inclusionAI/Ring-1T-preview
- 魔搭社区: https://modelscope.cn/models?page=1&tabKey=task
通义千问推出多语言实时音视频同传模型Qwen3-LiveTranslate-Flash:18种语言+方言,3秒延迟,准确度超GPT-4o/Audio-Preview
通义千问发布多语言实时音视频同传模型Qwen3-LiveTranslate-Flash,核心亮点包括支持18种主要官方语言(中文、英文、法语等)及普通话、粤语、四川话等方言;首次引入视觉上下文增强技术,利用口型、动作、文字、实体等多模态信息应对嘈杂环境及一词多译问题;通过轻量混合专家架构与动态采样策略实现最低3秒延迟;采用语义单元预测技术缓解跨语言调序问题,实时同传保持离线翻译94%以上准确度;基于海量语音数据训练,可根据原始语音自适应调节语气和表现力的拟人音色。
性能上,该模型在公开测试集的中英及多语言语音翻译榜单中,准确度优于Gemini-2.5-Flash、GPT-4o-Audio-Preview、Voxtral Small-24B等主流大模型,除AVG.XX-EN外均获第一名;在不同领域和复杂声学环境下测试成绩亦优于Gemini-2.5-Flash等模型。应用中可区分“mask(口罩)”与“Musk(马斯克)”、识别低频专有名词(如人名),支持芊悦(Cherry)、上海-阿珍(Jada)等多种音色。后续将持续提升语音翻译准确性、自然度、情感一致性,拓展更多语种,增强复杂语音环境下的鲁棒性,其意义在于或将降低全球开发者在实时跨语言交流应用上的创新门槛,加速国际会议、跨境直播、无障碍沟通等场景的下一代产品落地。

字节火山引擎发布豆包大模型1.6-vision:首款具备工具调用能力的视觉深度思考模型,测评超Gemini等前沿模型
2025年9月30日,字节跳动火山引擎正式发布豆包大模型1.6-vision,系豆包大模型家族首款具备工具调用能力的视觉深度思考模型。该模型在多项专业视觉理解公开测评中表现优异,开启工具调用模式的版本在高分辨率和复杂视觉感知测评中超越Gemini 2.5 Pro、OpenAI o3、Qwen3-VL等前沿模型;支持Point(几何数学题解答、出行路线规划等)、Grounding(目标捕捉)、Zoom(图片细节捕捉)、Rotate(画面倾斜/倒置调整)4种工具调用,提供高细节(精细特征提取、复杂图像识别)与低细节(简单分类检索、整体场景识别)两种理解模式;与豆包大模型1.5-vision相比综合成本降低约50%,已上线火山方舟,推理价格为0.0008元起/千输入tokens、0.002元起/千输出tokens;有望应用于OCR信息提取、图像审核、巡检安防、视频与图片标注、教育解题、AI搜索问答等场景。体验上,未开启工具调用时可识别画面特色视觉元素(如限定地点到武康路、复兴西路、永嘉路等区域);开启高细节理解后,能准确解读复杂卫星地图(识别图中文字、区分干旱严重程度的颜色深浅并关联地名分析)。
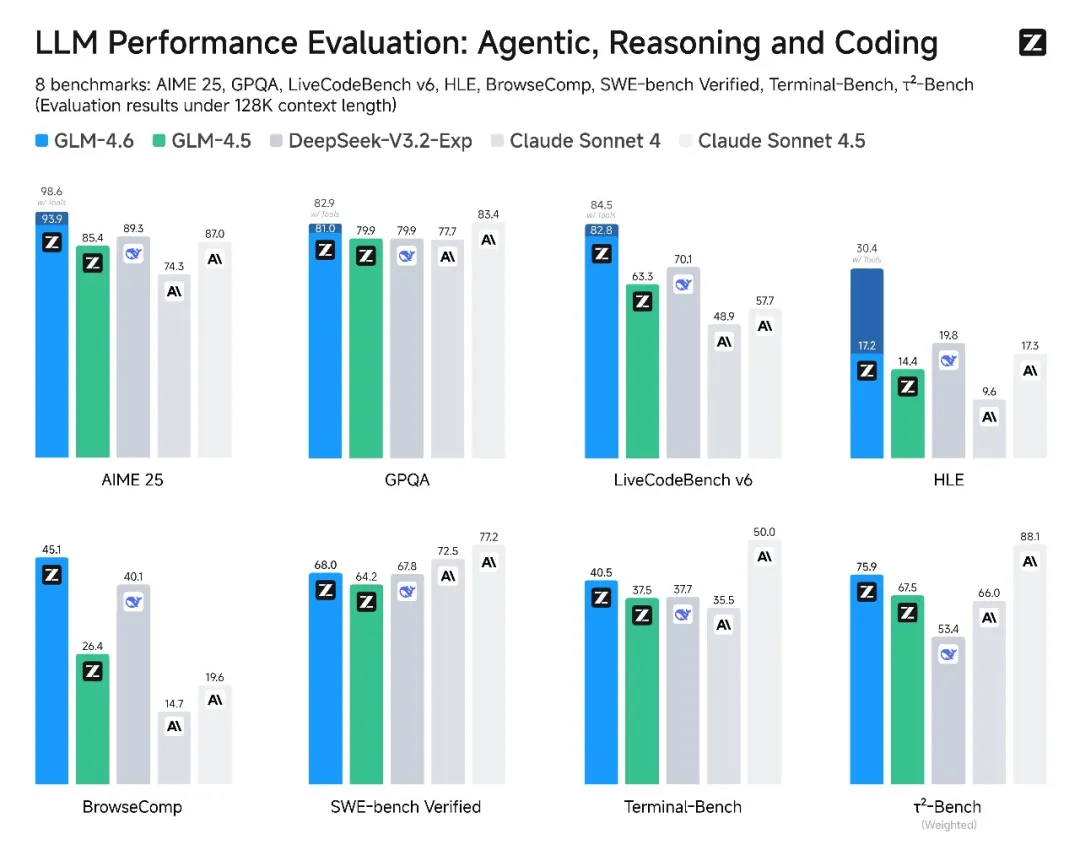
国庆前夕国产大模型卷疯了!智谱GLM-4.6编程超Claude Sonnet 4,20元包月性价比碾压
国庆前夕国产大模型密集迭代,智谱AI发布新一代大模型GLM-4.6,在真实编程、长上下文处理、推理能力、信息搜索、写作能力与智能体应用等方面全面提升,整体性能超越DeepSeek-V3.2-Exp;在AIME 25、GPQA、LCB v6等8大权威基准测试中稳居国产模型首位,部分榜单赶超Claude Sonnet 4等顶尖模型;真实编程任务实测超过Claude Sonnet 4,平均token消耗较GLM-4.5节省30%以上。
实测显示其编程能力显著提升:“旋转六边形弹跳球模拟”无边界溢出且有控制选项,优于GLM-4.5;“交互式太阳系模拟”支持3D拖动、速度/大小调整,可与Claude Sonnet 4.5媲美;“水豚骑自行车SVG动画”生成准确(水豚形态真实、骑行姿态正确),优于GPT-5;“3D射击游戏”(736行代码、击中奖励/计分)、“速度型与力量型种群相互作用模拟”(模块化控制板、可视化美观)完成度高;AI PPT制作能通过多轮对话调整大纲、替换内容、添加配图,文本理解与智能体调用准确。芯片适配方面,寒武纪完成GLM-4.6 FP8+Int4混合量化部署(首次国产芯片投产该方案,精度不变降推理成本);摩尔线程基于vLLM框架适配,新一代GPU原生FP8精度稳定运行,验证MUSA架构兼容性与适配能力。
价格与服务上,GLM Coding Plan同步升级,推出最低20元包月畅玩套餐(1/7 Claude价格享9/10能力);企业版提供安全、高性价比编码方案;老用户自动升级至GLM-4.6,新增图像识别与搜索能力,支持Claude Code、Roo Code等10+主流编程工具;GLM Coding Max面向高频重度开发者(Claude Max 3倍用量)。
- huggingface: https://huggingface.co/datasets/zai-org/CC-Bench-trajectories
- 技术报告地址: https://z.ai/blog/glm-4.6
- 体验地址: https://chat.z.ai
AI一周资讯 250926-251005的更多相关文章
- 偶尔转帖:AI会议的总结(by南大周志华)
偶尔转帖:AI会议的总结(by南大周志华) 说明: 纯属个人看法, 仅供参考. tier-1的列得较全, tier-2的不太全, tier-3的很不全. 同分的按字母序排列. 不很严谨地说, tier ...
- 【转载】 AI会议的总结(by南大周志华)
原文地址: https://blog.csdn.net/LiFeitengup/article/details/8441054 最近在查找期刊会议级别的时候发现这篇博客,应该是2012年之前的内容,现 ...
- AI产业将更凸显个人英雄主义 周志华老师的观点是如此的有深度
今天无意间在网上看的了一则推送,<周志华:AI产业将更凸显个人英雄主义> http://tech.163.com/18/0601/13/DJ7J39US00098IEO.html 摘录一些 ...
- 程序员体验AI换脸就不要用ZAO了,详解Github周冠军项目Faceswap的变脸攻略
本文链接:https://blog.csdn.net/BEYONDMA/article/details/100594136 上个月笔者曾在<银行家杂志>发文传统银行如何引领开放 ...
- 最强云硬盘来了,让AI模型迭代从1周缩短到1天
摘要:华为云擎天架构+ Flash-Native存储引擎+低时延CurreNET,数据存储和处理还有啥担心的? 虽然我们已经进入大数据时代,但多数企业数据利用率只有10%,数据的价值没有得到充分释放. ...
- 思必驰周强:AI 和传统信号技术在实时音频通话中的应用
如何用 AI 解决声音传输&处理中的三大问题?三大问题又是哪三大问题? 在「RTE2022 实时互联网大会」中,思必驰研发总监 @周强以<AI 和传统信号技术在实时音频通话中的应用> ...
- Python 霸榜的一周,又有什么新 AI 力作呢?「GitHub 热点速览」
GPT 带火了一波语言模型,LLaMA 和 Alpaca 也在持续发力.依旧是各类 GPT 后缀霸榜 GitHub trending 的一周,为此特推部分专门收录了两个比较不错的 GPT 应用.而作为 ...
- AI(一):概念与资讯
AI: Artificial Intelligence(人工智能),它是研究.开发用于模拟和扩展人的智能的理论.方法.技术及应用系统的一门新的技术科学,上个世纪50年代一次学术讨论会议上,下图中几位著 ...
- AI 的会议总结(by南大周志华)
原文链接:http://blog.csdn.net/akipeng/article/details/6533897 这个列的更详细:http://www.cvchina.info/2010/08/31 ...
- AI 学习路线
[导读] 本文由知名开源平台,AI技术平台以及领域专家:Datawhale,ApacheCN,AI有道和黄海广博士联合整理贡献,内容涵盖AI入门基础知识.数据分析挖掘.机器学习.深度学习.强化学习.前 ...
随机推荐
- raspberry 修改static ip地址,ssh 可以访问到
raspberry 修改static ip地址,ssh 可以访问到 转载连接 http://www.jianshu.com/p/2c2a8291728d 如果我们希望直接不通过电脑直接连接登录到树莓派 ...
- 线性代数 A 的 LU 分解
我们本章的目的是对 \(A=LU\) 进行分析,我们以这种思路来看待高斯消元. 好现在还是从简单的开始. 首先,讲一下上一章中没讲完的内容--乘积的逆. 假设 \(A\) 和 \(B\) 均是可逆矩阵 ...
- 第三方供应商不提供API接口?教你四步破解集成难题
API开放需求 在企业数字化转型过程中,异构系统之间的连接是信息化阶段不可或缺的一环.通过应用API,企业能够实现不同系统.平台和应用之间的数据交换与功能调用,从而形成端到端的业务流程协同.然而,很多 ...
- SciTech-Mathmatics-ComplexSpace-Encode/Decode- (Discrete)Multi-Dimensional FourierTransform: arbitrary $R^n$ functions + SpectralAnalysis + ImageSynthesis__FourierSeries: PeriodicalFunctions
多维复空间上的离散傅立叶变换\(MD-DFT\)(Multi-Dimensional Discrete Fourier Transform) : 多维\(C^k\)(k维复数空间)上的\(MD-DFT ...
- SBOM(软件物料清单)—— 软件供应链安全的“成分说明书”
1. 概述 现代软件都是组装的而非纯自研.随着开源组件在数字化应用中的使用比例越来越高,混源开发已成为当前业内主流开发方式.开源组件的引入虽然加快了软件开发效率,但同时将开源安全问题引入了整个软件供应 ...
- luoguP1216 [USACO1.5] [IOI1994]数字三角形 Number Triangles
[USACO1.5] [IOI1994]数字三角形 Number Triangles 题目描述 观察下面的数字金字塔. 写一个程序来查找从最高点到底部任意处结束的路径,使路径经过数字的和最大.每一步可 ...
- luoguP1163-二分
银行贷款 题目链接:https://www.luogu.com.cn/problem/P1163 本题思路: orz公式 数学公式给出n,m,k,求贷款者向银行支付的利率 p,使得: $ \sum_{ ...
- 树上高斯消元(P5643 sol)
经典小技巧.以 P5643 为例,首先显然 min-max 容斥,之后枚举子集,算 \(x\) 到子集的期望移动步数.考虑高斯消元,\(x \not \in S\) 时转移方程为 \(f_x = \d ...
- MyEMS 开源能源管理系统:革新能源管控模式的技术实践与生态构建
在全球能源结构转型与 "双碳" 目标驱动下,能源管理系统已从传统的计量统计工具升级为集数据感知.智能分析.优化决策于一体的综合平台.MyEMS 作为基于 Python 开发的开源解 ...
- vivo Pulsar 万亿级消息处理实践(4)-Ansible运维部署
作者:Liu Sikang.互联网大数据团队-Luo Mingbo Pulsar作为下一代云原生架构的分布式消息中间件,存算分离的架构设计能有效解决大数据场景下分布式消息中间件老牌一哥"Ka ...