MQ(部署模式)
MQ部署模式
1、master-slave部署模式
1)shared filesystem Master-Slave部署方式
主要是通过共享存储目录来实现master和slave的热备,所有的ActiveMQ应用都在不断地获取共享目录的控制权,哪个应用抢到了控制权,它就成为master。
多个共享存储目录的应用,谁先启动,谁就可以最早取得共享目录的控制权成为master,其他的应用就只能作为slave
2)shared database Master-Slave方式
与shared filesystem方式类似,只是共享的存储介质由文件系统改成了数据库而已
3)Replicated LevelDB Store方式
这种主备方式是ActiveMQ5.9以后才新增的特性,使用ZooKeeper协调选择一个node作为master。被选择的master broker node开启并接受客户端连接。其他node转入slave模式,连接master并同步他们的存储状态。slave不接受客户端连接。所有的存储操作都将被复制到连接至Master的slaves。
如果master死了,得到了最新更新的slave被允许成为master。fialed node能够重新加入到网络中并连接master进入slave mode。所有需要同步的disk的消息操作都将等待存储状态被复制到其他法定节点的操作完成才能完成。所以,如果你配置了replicas=3,那么法定大小是(3/2)+1=2. Master将会存储并更新然后等待 (2-1)=1个slave存储和更新完成,才汇报success。至于为什么是2-1,熟悉Zookeeper的应该知道,有一个node要作为观擦者存在
单一个新的master被选中,你需要至少保障一个法定node在线以能够找到拥有最新状态的node。这个node将会成为新的master。因此,推荐运行至少3个replica nodes,以防止一个node失败了,服务中断。
2、Broker-Cluster部署方式
前面的Master-Slave的方式虽然能解决多服务热备的高可用问题,但无法解决负载均衡和分布式的问题。Broker-Cluster的部署方式就可以解决负载均衡的问题。
Broker-Cluster部署方式中,各个broker通过网络互相连接,并共享queue。当broker-A上面指定的queue-A中接收到一个message处于pending状态,而此时没有consumer连接broker-A时。如果cluster中的broker-B上面由一个consumer在消费queue-A的消息,那么broker-B会先通过内部网络获取到broker-A上面的message,并通知自己的consumer来消费。
1)static Broker-Cluster部署
在activemq.xml文件中静态指定Broker需要建立桥连接的其他Broker:
1、 首先在Broker-A节点中添加networkConnector节点:
<networkConnectors>
<networkConnector uri="static:(tcp:// 0.0.0.0:61617)"duplex="false"/>
</networkConnectors>
2、 修改Broker-A节点中的服务提供端口为61616:
<transportConnectors>
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
</transportConnectors>
3、 在Broker-B节点中添加networkConnector节点:
<networkConnectors>
<networkConnector uri="static:(tcp:// 0.0.0.0:61616)"duplex="false"/>
</networkConnectors>
4、 修改Broker-A节点中的服务提供端口为61617:
<transportConnectors>
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61617?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
</transportConnectors>
5、分别启动Broker-A和Broker-B。
2)Dynamic Broker-Cluster部署
在activemq.xml文件中不直接指定Broker需要建立桥连接的其他Broker,由activemq在启动后动态查找:
1、 首先在Broker-A节点中添加networkConnector节点:
<networkConnectors>
<networkConnectoruri="multicast://default"
dynamicOnly="true"
networkTTL="3"
prefetchSize="1"
decreaseNetworkConsumerPriority="true" />
</networkConnectors>
2、修改Broker-A节点中的服务提供端口为61616:
<transportConnectors>
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61616? " discoveryUri="multicast://default"/>
</transportConnectors>
3、在Broker-B节点中添加networkConnector节点:
<networkConnectors>
<networkConnectoruri="multicast://default"
dynamicOnly="true"
networkTTL="3"
prefetchSize="1"
decreaseNetworkConsumerPriority="true" />
</networkConnectors>
4、修改Broker-B节点中的服务提供端口为61617:
<transportConnectors>
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61617" discoveryUri="multicast://default"/>
</transportConnectors>
5、启动Broker-A和Broker-B
3、Master-Slave与Broker-Cluster相结合的部署方式
可以看到Master-Slave的部署方式虽然解决了高可用的问题,但不支持负载均衡,Broker-Cluster解决了负载均衡,但当其中一个Broker突然宕掉的话,那么存在于该Broker上处于Pending状态的message将会丢失,无法达到高可用的目的。
由于目前ActiveMQ官网上并没有一个明确的将两种部署方式相结合的部署方案,所以我尝试者把两者结合起来部署:
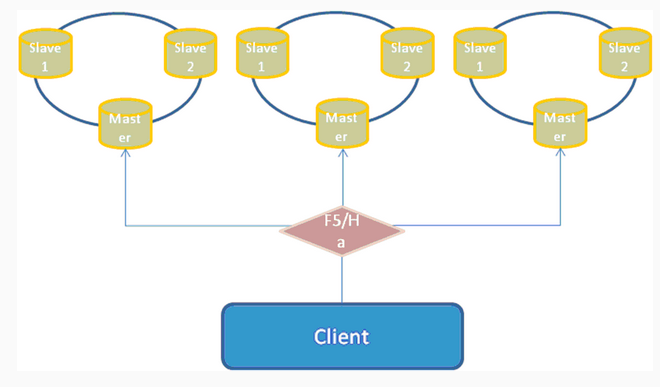
部署配置步骤:
这里以Broker-A + Broker-B建立cluster,Broker-C作为Broker-B的slave为例:
1)首先在Broker-A节点中添加networkConnector节点:
<networkConnectors>
<networkConnector uri="masterslave:(tcp://0.0.0.0:61617,tcp:// 0.0.0.0:61618)" duplex="false"/>
</networkConnectors>
2)修改Broker-A节点中的服务提供端口为61616:
<transportConnectors>
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
</transportConnectors>
3)在Broker-B节点中添加networkConnector节点:
<networkConnectors>
<networkConnector uri="static:(tcp:// 0.0.0.0:61616)"duplex="false"/>
</networkConnectors>
4)修改Broker-B节点中的服务提供端口为61617:
<transportConnectors>
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61617?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
</transportConnectors>
5)修改Broker-B节点中的持久化方式:
<persistenceAdapter>
<kahaDB directory="/localhost/kahadb"/>
</persistenceAdapter>
6)在Broker-C节点中添加networkConnector节点:
<networkConnectors>
<networkConnector uri="static:(tcp:// 0.0.0.0:61616)"duplex="false"/>
</networkConnectors>
7)修改Broker-C节点中的服务提供端口为61618:
<transportConnectors>
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61618?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
</transportConnectors>
8)修改Broker-B节点中的持久化方式:
<persistenceAdapter>
<kahaDB directory="/localhost/kahadb"/>
</persistenceAdapter>
9)分别启动broker-A、broker-B、broker-C,因为是broker-B先启动,所以“/localhost/kahadb”目录被lock住,broker-C将一直处于挂起状态,当人为停掉broker-B之后,broker-C将获取目录“/localhost/kahadb”的控制权,重新与broker-A组成cluster提供服务。
本文来自:http://www.open-open.com/lib/view/open1400126457817.html
MQ(部署模式)的更多相关文章
- Apache Spark技术实战之8:Standalone部署模式下的临时文件清理
未经本人同意严禁转载,徽沪一郎. 概要 在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件,这些临时目录和文件又是在什么时候被清理,本文将就这些问题做深入细致的解答. 从 ...
- 【技巧】Java工程中的Debug信息分级输出接口及部署模式
也许本文的标题你们没咋看懂.但是,本文将带大家领略输出调试的威力. 灵感来源 说到灵感,其实是源于笔者在修复服务器的ssh故障时的一个发现. 这个学期初,同袍(容我来一波广告产品页面,同袍官网)原服务 ...
- Nacos系列:Nacos的三种部署模式
三种部署模式 Nacos支持三种部署模式 1.单机模式:可用于测试和单机使用,生产环境切忌使用单机模式(满足不了高可用) 2.集群模式:可用于生产环境,确保高可用 3.多集群模式:可用于多数据中心场景 ...
- Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理
问题导读 1.在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件? 2.在Standalone部署模式下分为几种模式? 3.在client模式和cluster模式下有什么 ...
- 【待补充】Spark 集群模式 && Spark Job 部署模式
0. 说明 Spark 集群模式 && Spark Job 部署模式 1. Spark 集群模式 [ Local ] 使用一个 JVM 模拟 Spark 集群 [ Standalone ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- ASP.NET MVC深入浅出系列(持续更新) ORM系列之Entity FrameWork详解(持续更新) 第十六节:语法总结(3)(C#6.0和C#7.0新语法) 第三节:深度剖析各类数据结构(Array、List、Queue、Stack)及线程安全问题和yeild关键字 各种通讯连接方式 设计模式篇 第十二节: 总结Quartz.Net几种部署模式(IIS、Exe、服务部署【借
ASP.NET MVC深入浅出系列(持续更新) 一. ASP.NET体系 从事.Net开发以来,最先接触的Web开发框架是Asp.Net WebForm,该框架高度封装,为了隐藏Http的无状态模 ...
- Nginx+Docker部署模式下 asp.net core 获取真实的客户端ip
目录 Nginx+Docker部署模式下 asp.net core 获取真实的客户端ip 场景 过程还原 结论 参考资料 Nginx+Docker部署模式下 asp.net core 获取真实的客户端 ...
- 入门大数据---Spark部署模式与作业提交
一.作业提交 1.1 spark-submit Spark 所有模式均使用 spark-submit 命令提交作业,其格式如下: ./bin/spark-submit \ --class <ma ...
- Spark内核-部署模式
Master URL Meaning local 在本地运行,只有一个工作进程,无并行计算能力. local[K] 在本地运行,有K个工作进程,通常设置K为机器的CPU核心数量. local[*] 在 ...
随机推荐
- es6数组去重、数组中的对象去重 && 删除数组(按条件或指定具体元素 如:id)&& 筛选去掉没有子组件的父组件
// 数组去重 { const arr = [1,2,3,4,1,23,5,2,3,5,6,7,8,undefined,null,null,undefined,true,false,true,'中文' ...
- Taro3 扫描不同二维码参数不同,但是热启动之后参数不变 根据环境不同更换域名
热启动:先执行缓存的静态数据,然后再执行页面代码.比如右上角退出或者按home键错误用法:用的Taro3 react function函数,之前用的 Taro.getLaunchOptionsSyn ...
- WinExec("D:\\MY_tool\\APPLICATION\\calc.exe", SW_SHOW);
1 #pragma comment(lib,"shell32.lib")2 3 4 ShellExecute(NULL, NULL,"calc.exe", NU ...
- Flink akka AskTimeoutException问题排查
最近遇到一个很奇怪的问题,Flink任务正常启动正常运行一段时间后就会报错,,错误详情如下 2019-12-11 17:20:57.757 flink [flink-scheduler-1] ERRO ...
- Java集合-LinkedHashSet
LinkedHashSet 重点: LinkedHashSet 不允许重复元素,与 HashSet的区别是:它是有序的 LinkedHashSet 底层结构是 数组table + 双向链表 [介绍] ...
- Ajax同步和异步的区别,如何解决跨域的问题
同步的概念应该是来自于OS中关于同步的概念:不同进程为协同完成某项工作而在先后次序上调整(通过阻塞,唤醒等方式),同步强调的是顺序性,谁先谁后,异步则不存在这种顺序性. 同步:浏览器访问服务器请求,用 ...
- 打包python文件为exe程序 vscode
一.项目下虚拟环境下载pyinstaller.exe 打包 1.检查是否下载 pyinstaller: 如果没有在vscode终端输入:pip3 install pyinstaller 安装成功后下 ...
- Absolute Path Traversal 错误解决
Absolute Path Traversal (APT) 是一种常见的安全漏洞,攻击者可以通过该漏洞访问应用程序的文件系统中的文件, 包括敏感信息,从而可能导致应用程序遭受攻击. 一.使用专门的文件 ...
- win电脑查看wifi密码的方法
1.使用电脑连接需要查看的WiFi,鼠标右击电脑桌面右下角[WiFi图标],在弹出的菜单中点击[打开"网络和internet"设置]. 2.在弹出的设置窗口中点击[网络和共享中心] ...
- windows jetbrains toolbox 无法修改应用安装目录(应用正在运行)的解决方案
打开 jetbrains toolbook安装目录/.settings.json 添加一行 "install_location": 指定的路径地址 解决方案来自 JetBrains ...