使用 Elastic Agents 把定制的日志摄入到 Elasticsearch 中
转载自:https://mp.weixin.qq.com/s/QQxwYh1uLCkKn1LK72ojJA
在以前的系统中,我们可以使用如下的几种方式来采集日志:
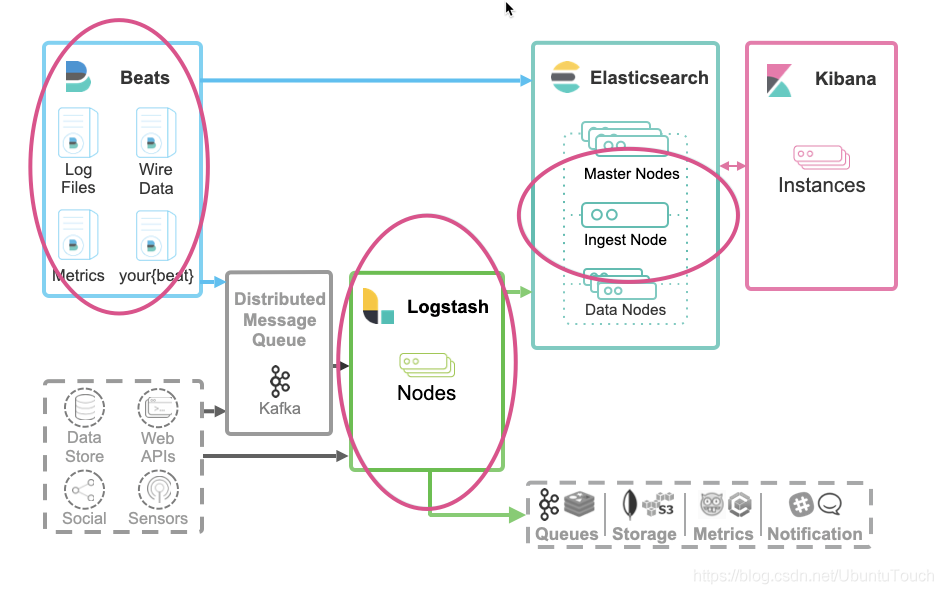
1.我们可以直接使用 Beats 把数据传入到 Elasticsearch 中。对数据的处理,我们可以使用 Beats 的 processors 来处理数据,或者通过 Elasticsearch 集群的 ingest nodes 来处理数据。
2.我们可以通过 Beats => Logstash => Elasticsearch。针对这种情况,我们可以分别在 Beats,Logstash 或者 Elasticsearch 集群的 ingest nodes 来处理数据。
3.我们可以直接使用各种编程语言来直接向 Elasticsearch 集群进行写入。我们可以使用 Elasticsearch 集群的 ingest nodes 来处理数据。
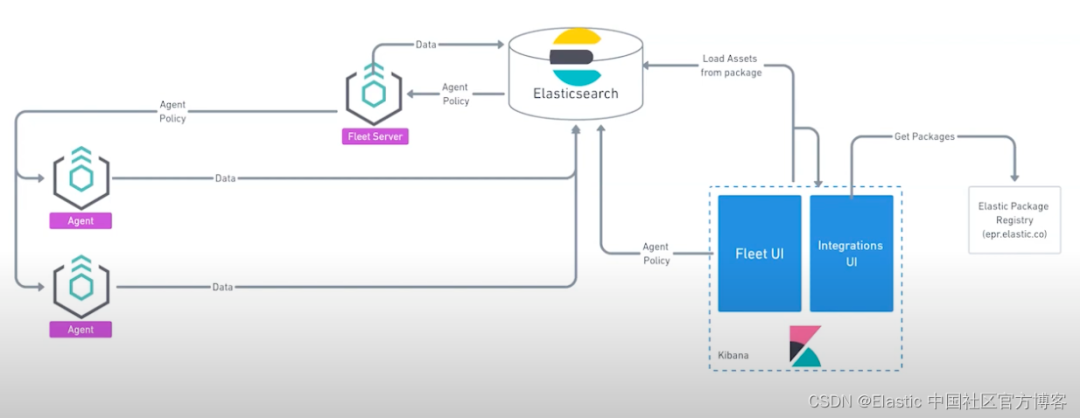
在今天的文章里,我们来详细地描述如何使用 Elastic Agents 把应用中的定制日志摄入到 Elasticsearch 中并进行分析。在今天的演示中,我将使用如下测试环境:
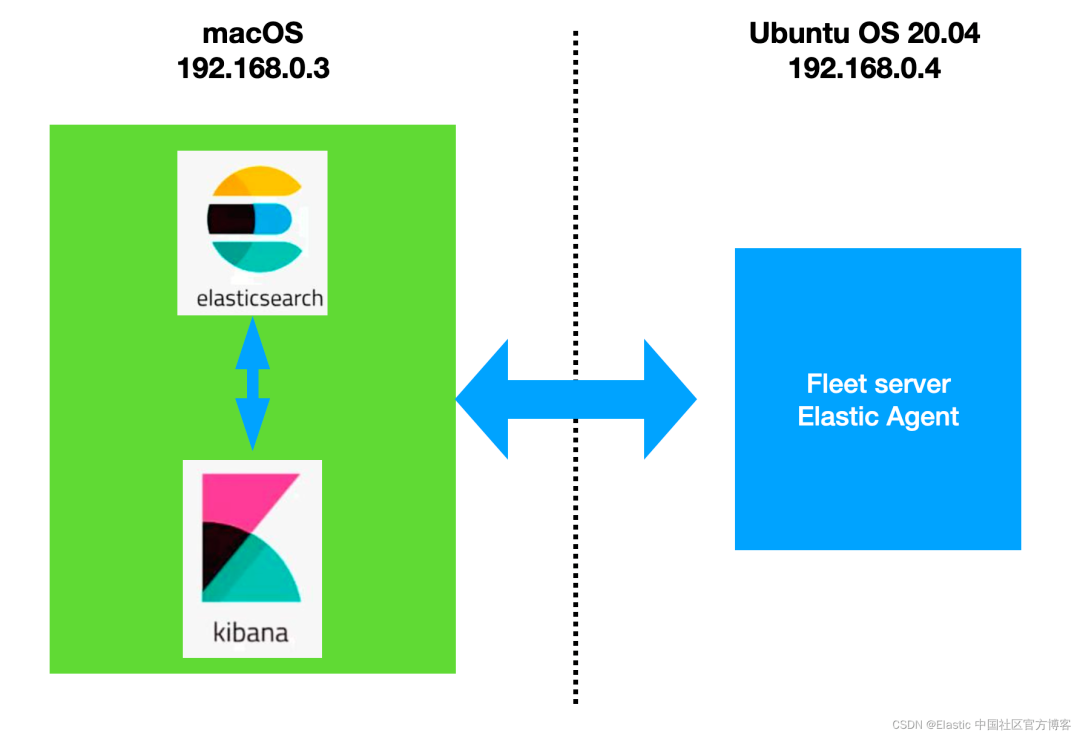
我将使用 Elastic Stack 8.3 来进行安装并展示。
准备日志
为了方便,我们使用我之前的一个教程写的文章里的例子来生成日志。我使用 Python 应用来生成日志。请参考文章 “Beats: 使用 Filebeat 进行日志结构化 - Python”。我们按照如下的步骤在 Ubuntu OS 的机器上来运行应用:
liuxg@liuxgu:~/python/logs$ pwd
/home/liuxg/python/logs
liuxg@liuxgu:~/python/logs$ ls
createlogs.py createlogs_1.py createlogs_2.py filebeat_json.yml json_logs test.log
liuxg@liuxgu:~/python/logs$ python createlogs_2.py
liuxg@liuxgu:~/python/logs$ cat json_logs
{"user_name": "arthur", "id": 42, "verified": false, "event": "logged_in"}
{"user_name": "arthur", "id": 42, "verified": true, "event": "changed_state"}
可以看出来在我的应用目录里会生成一个叫做 json_logs 的文件。它的内容如上所示。上面的文档路径及文件名将在下面的配置中要用到。我们的日志路径是:
/home/liuxg/python/logs/json_logs
安装
在进行下面的练习之前,我们必须安装好 Elasticsearch 及 Kibana。我们可以参考之前的文章:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Elastic:使用 Docker 安装 Elastic Stack 8.0 并开始使用
我们按照上面的要求进行安装 Elasticsearch 及 Kibana。为了能够让 fleet 正常工作,内置的 API service 必须启动。我们必须为 Elasticsearch 的配置文件 config/elasticsearch.yml 文件配置:
xpack.security.authc.api_key.enabled: true
配置完后,我们再重新启动 Elasticsearch。针对 Kibana,我们也需要做一个额外的配置。我们需要修改 config/kibana.yml 文件。在这个文件的最后面,添加如下的一行:
xpack.encryptedSavedObjects.encryptionKey: 'fhjskloppd678ehkdfdlliverpoolfcr'
如果你不想使用上面的这个设置,你可以使用如下的方式来获得:
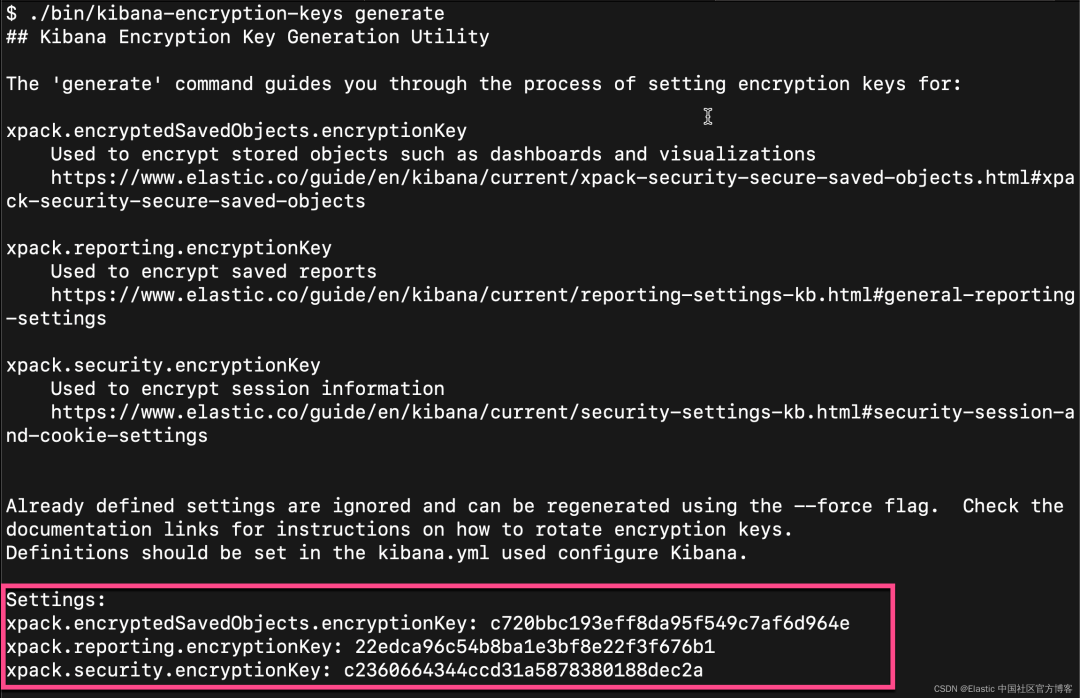
从上面的输出中,我们可以看出来,有三个输出的 key。我们可以把这三个同时拷贝,并添加到 config/kibana.yml 文件的后面。当然,我们也可以只拷贝其中的一个也可。我们再重新启动 Kibana。
这样我们对 Elasticsearch 及 Kibana 的配置就完成。针对 Elastic Stack 8.0 以前的版本安装,请阅读我之前的文章 “Observability:如何在最新的 Elastic Stack 中使用 Fleet 摄入 system 日志及指标”。
除此之外,Kibana 需要 Internet 连接才能从 Elastic Package Registry 下载集成包。确保 Kibana 服务器可以连接到https://epr.elastic.co 的端口 443 上 。如果你的环境有网络流量限制,有一些方法可以解决此要求。有关详细信息,请参阅气隙环境。
目前,Fleet 只能被具有 superuser role 的用户所使用。
配置 Fleet
使用 Kibana 中的 Fleet 将日志、指标和安全数据导入 Elastic Stack。第一次使用 Fleet 时,你可能需要对其进行设置并添加 Fleet Server。在做配置之前,我们首先来查看一下有没有任何的 integration 被安装:
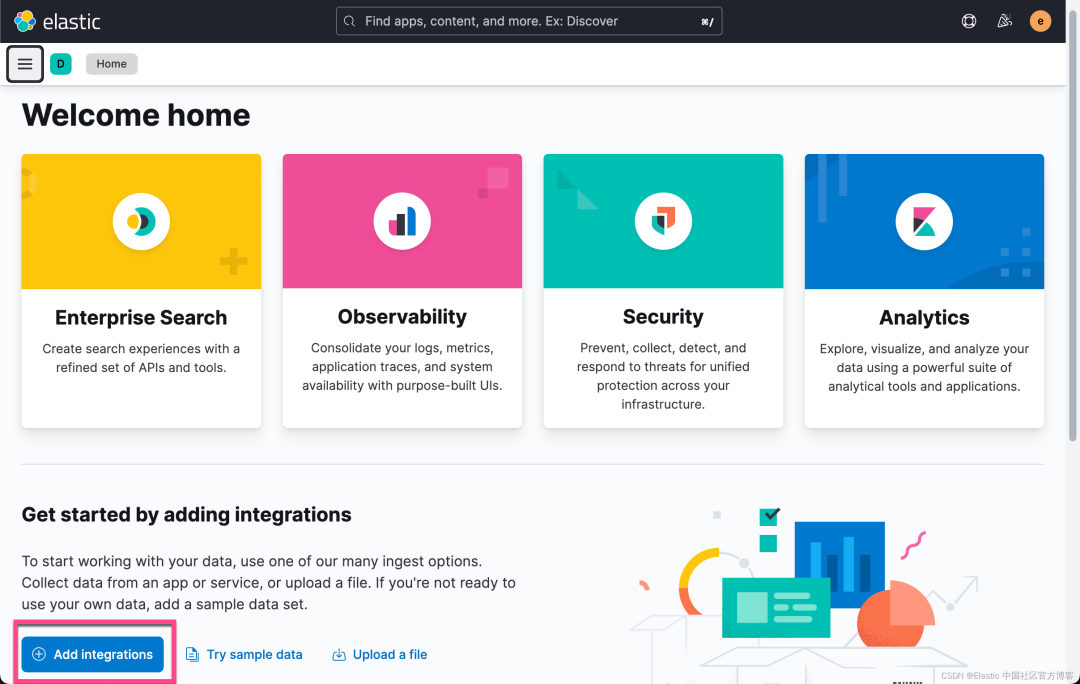
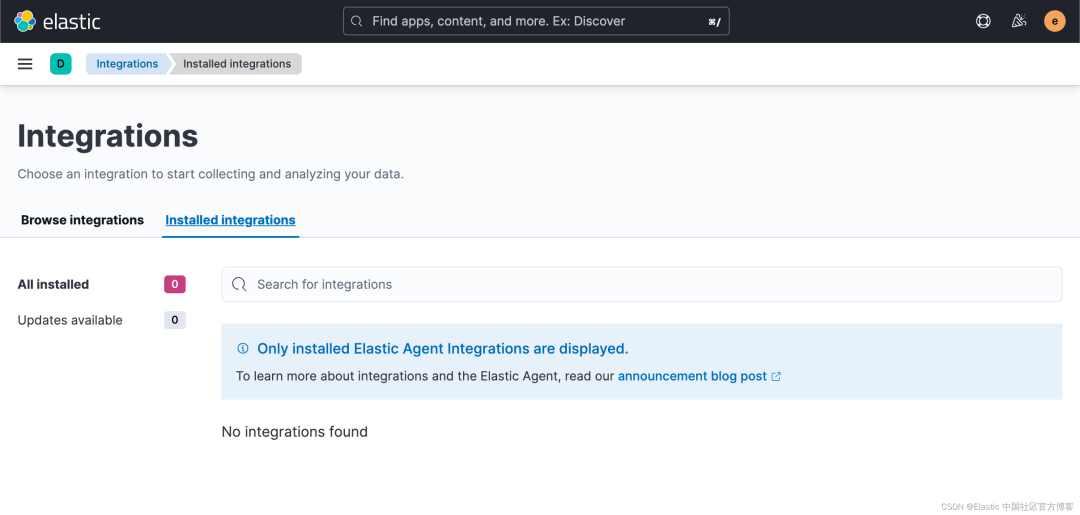
从上面我们可以看出来没有任何安装的 integrations。
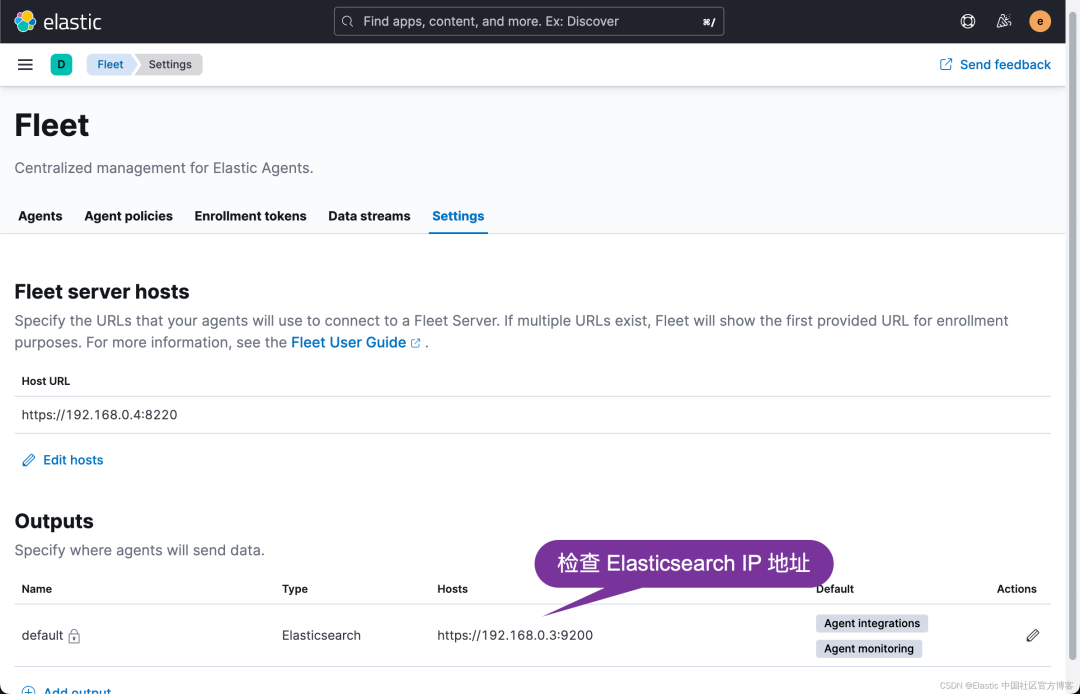
我们打开 Fleet 页面:
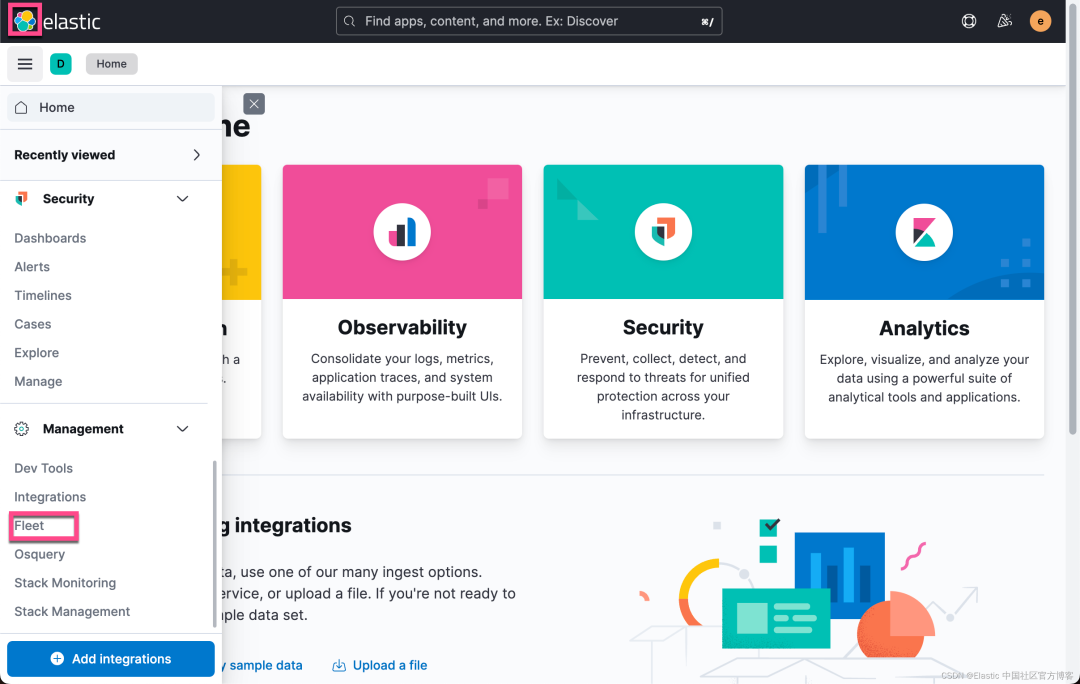
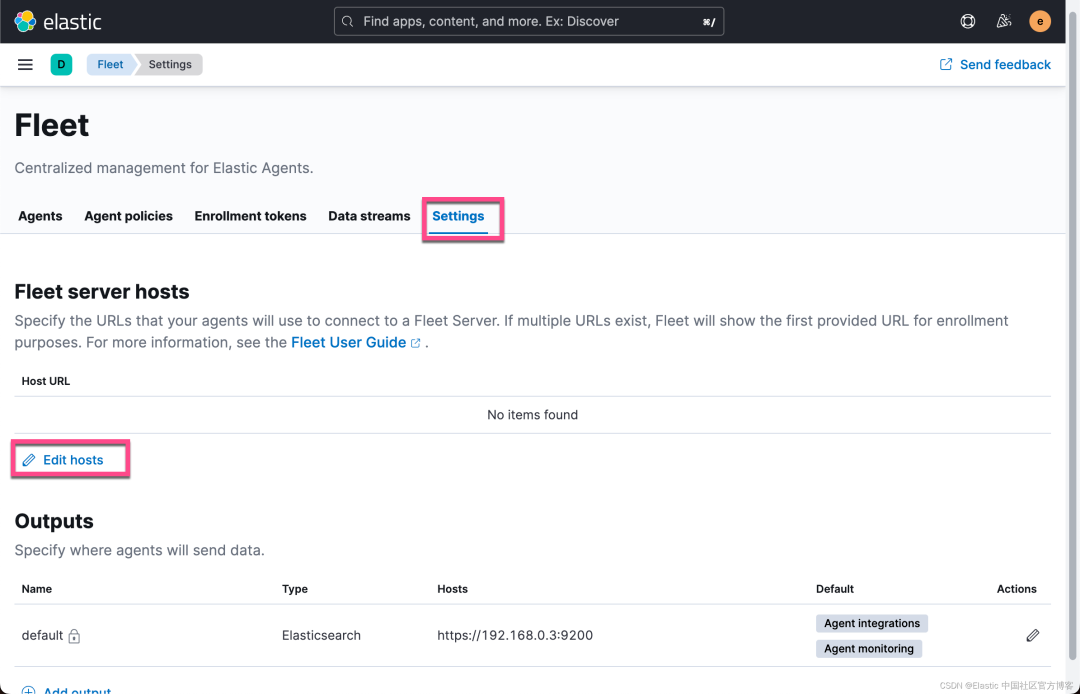
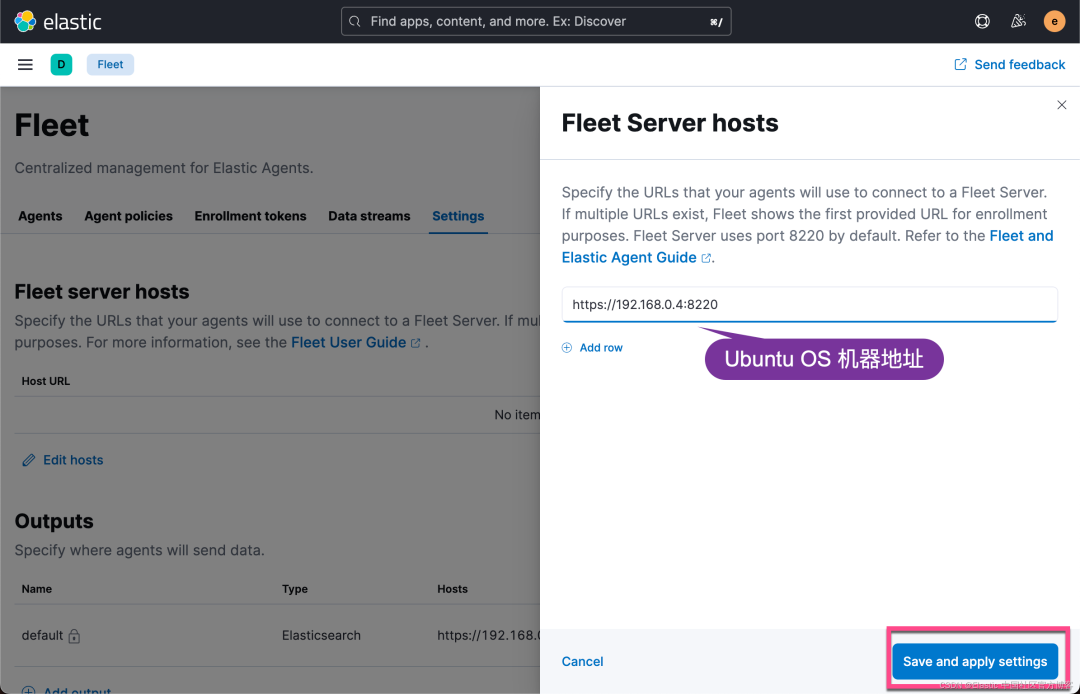
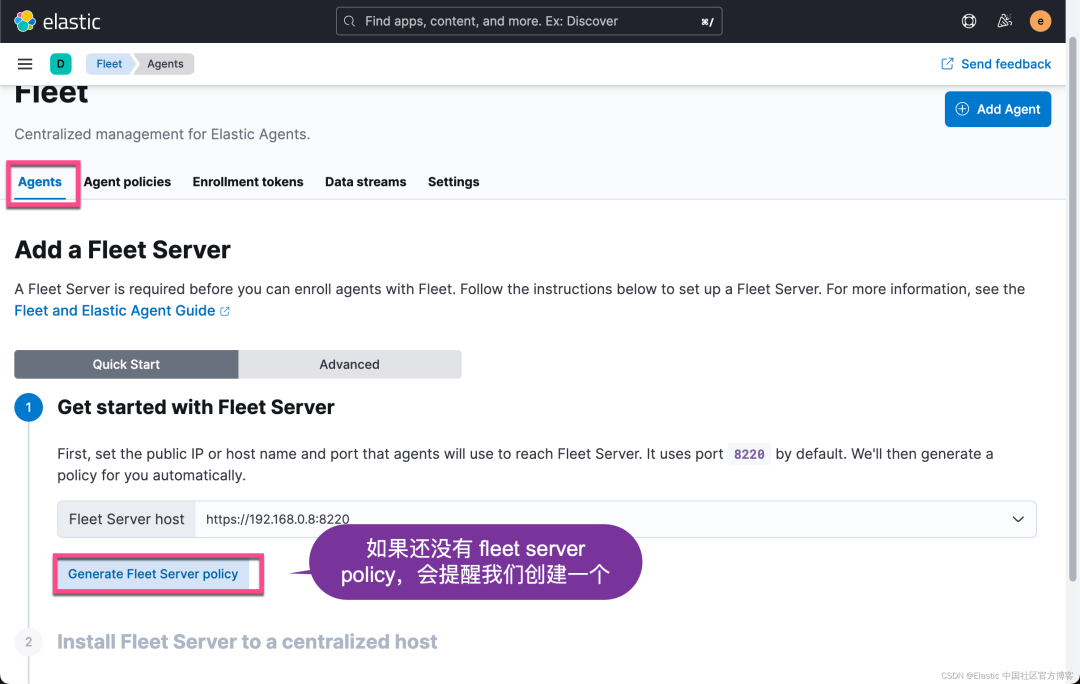
我们接下来添加 Agent:
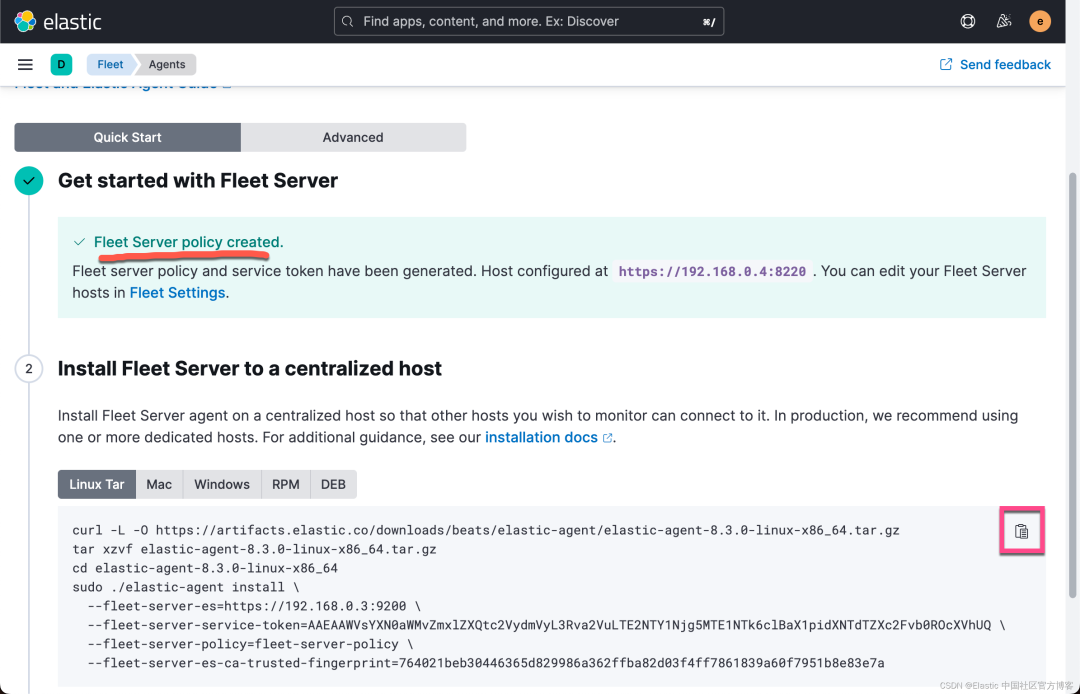
上面显示我们的 Fleet Sever policy 被成功地创建了。我们需要把我们的 Fleet Server 安装到 Ubuntu OS 机器上。
我们的目标机器是 Linux OS。我们点击上面的拷贝按钮,并在 Linux OS 上进行安装:
curl -L -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.3.0-linux-x86_64.tar.gz
tar xzvf elastic-agent-8.3.0-linux-x86_64.tar.gz
cd elastic-agent-8.3.0-linux-x86_64
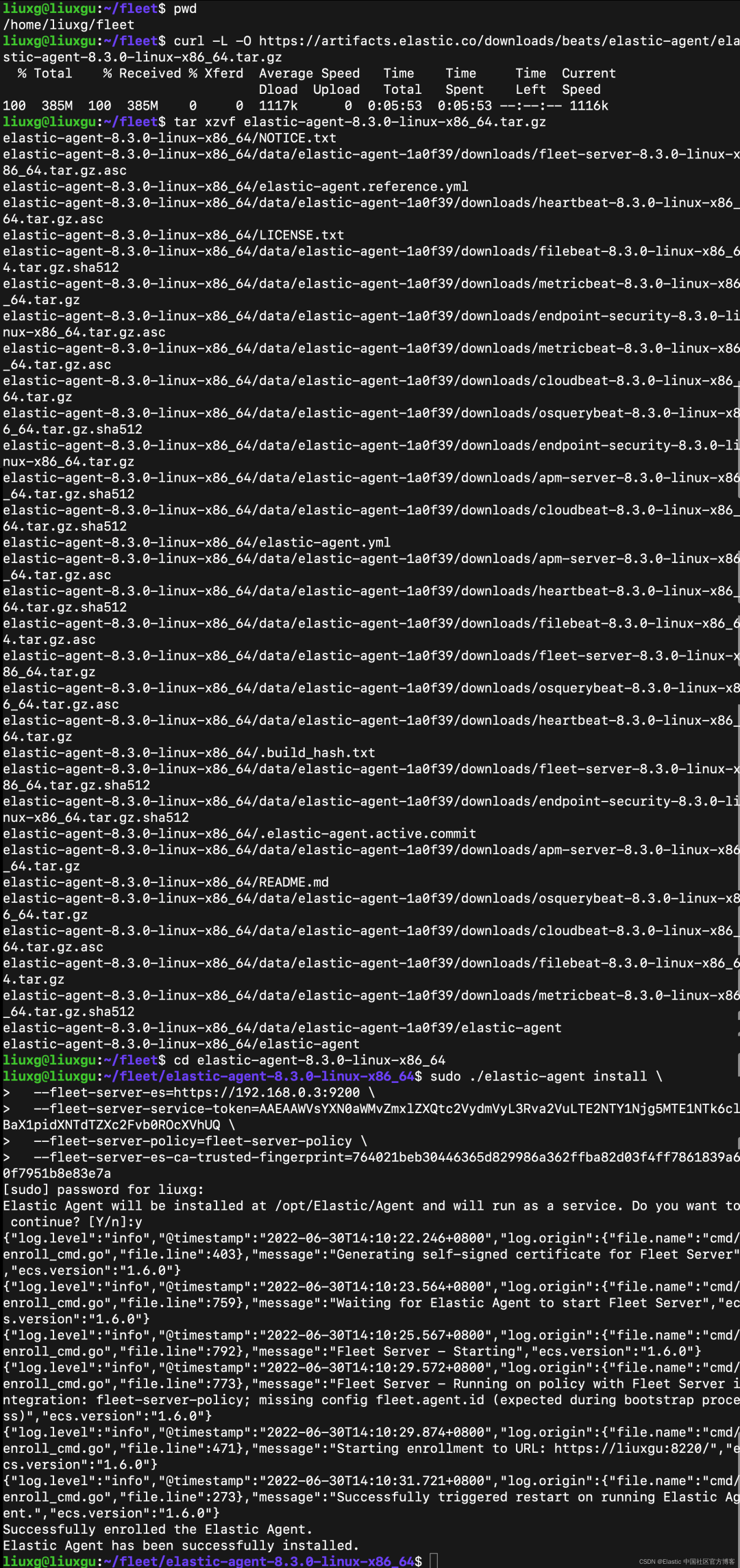
sudo ./elastic-agent install \
--fleet-server-es=https://192.168.0.3:9200 \
--fleet-server-service-token=AAEAAWVsYXN0aWMvZmxlZXQtc2VydmVyL3Rva2VuLTE2NTY1Njg5MTE1NTk6clBaX1pidXNTdTZXc2Fvb0ROcXVhUQ \
--fleet-server-policy=fleet-server-policy \
--fleet-server-es-ca-trusted-fingerprint=764021beb30446365d829986a362ffba82d03f4ff7861839a60f7951b8e83e7a
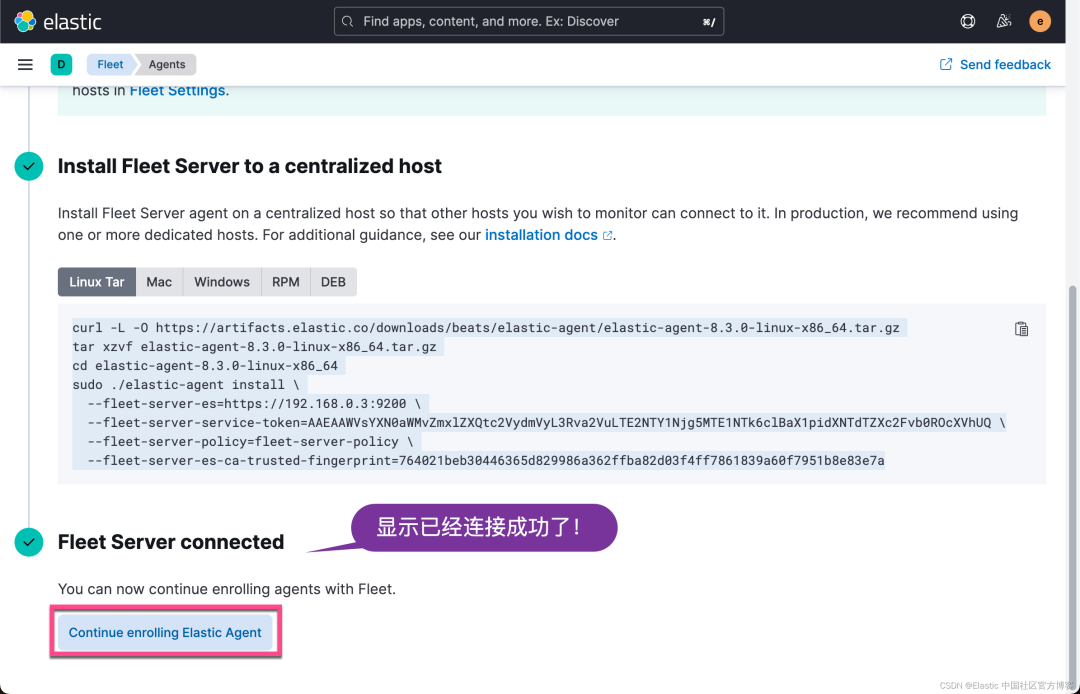
我们按照 Kibana 中的提示来安装:
等过一段时间,我们可以看到这个运用于 192.168.0.4 机器上的 Agents 的状态也变为 healthy:
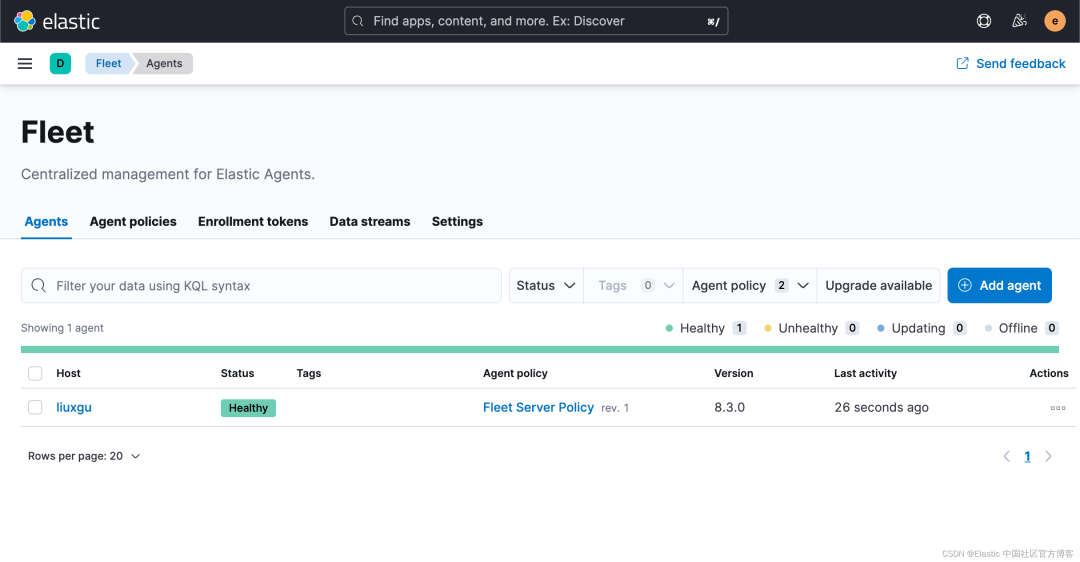
由于我们的 Elastic Agent 和 Fleet Server 是在一个服务器上运行的,所以,我们直接在 Fleet Server Policy 里添加我们想要的 integration。如果你的 Elastic Agent 可以运行于另外的一个机器上,而不和 Fleet Server 在同一个机器上,你可以创建一个新的 policy,比如 logs。然后让 agent 赋予给这个 新创建的 policy。
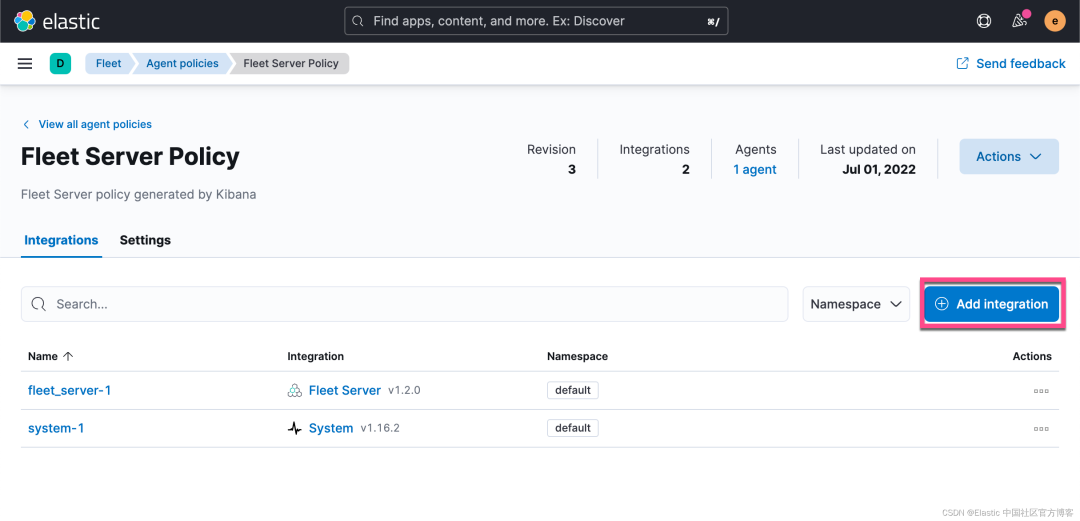
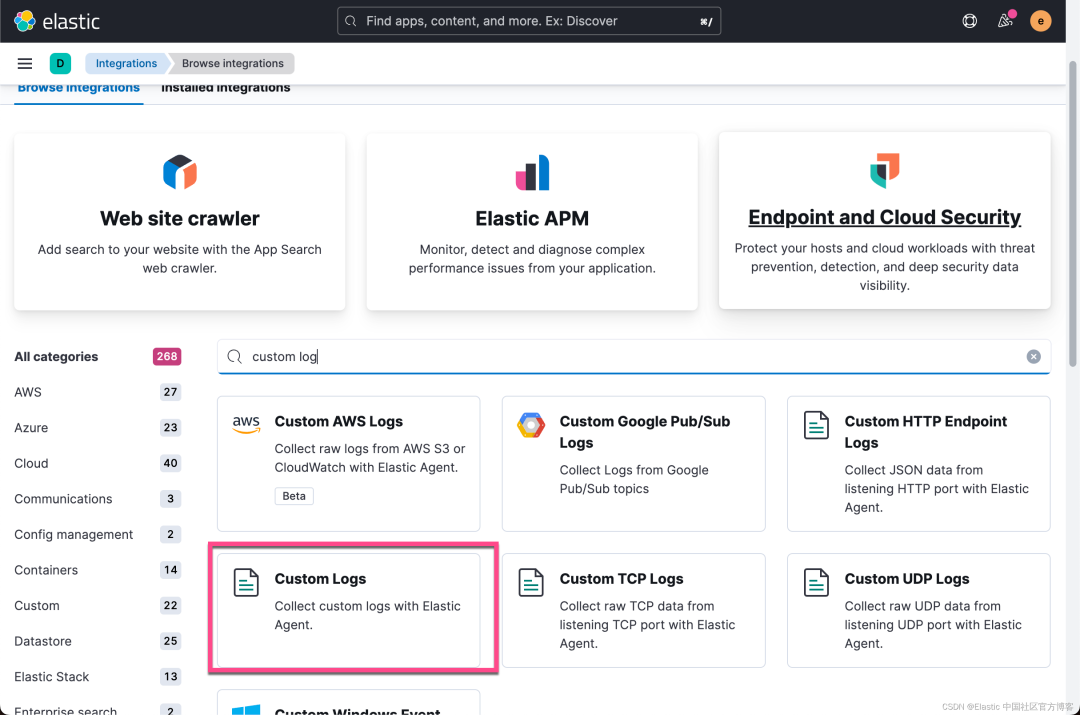
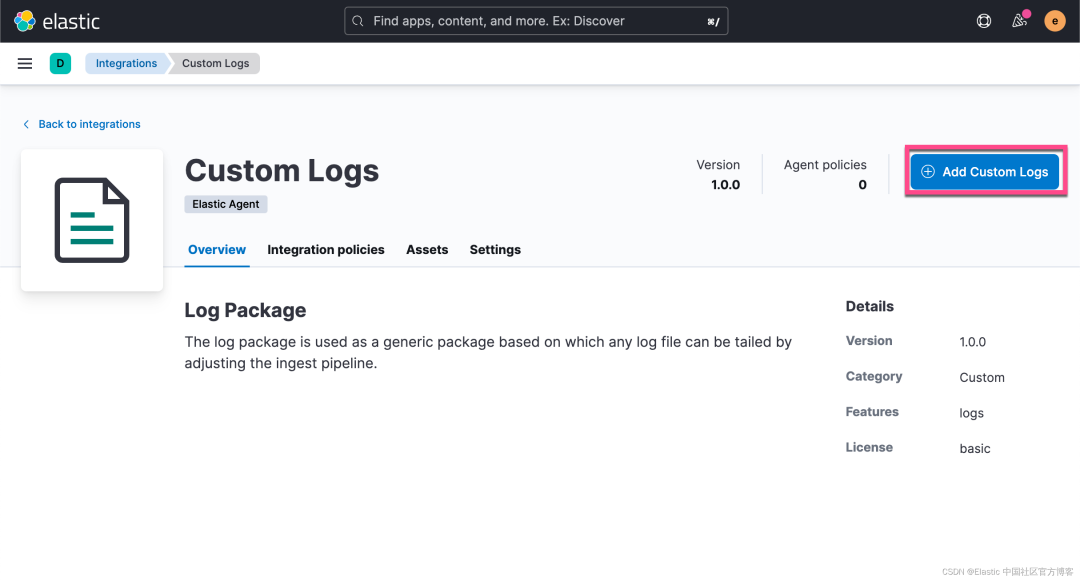
我们直接在这个 Fleet Server Policy 里添加一个叫做 custom log 的集成:
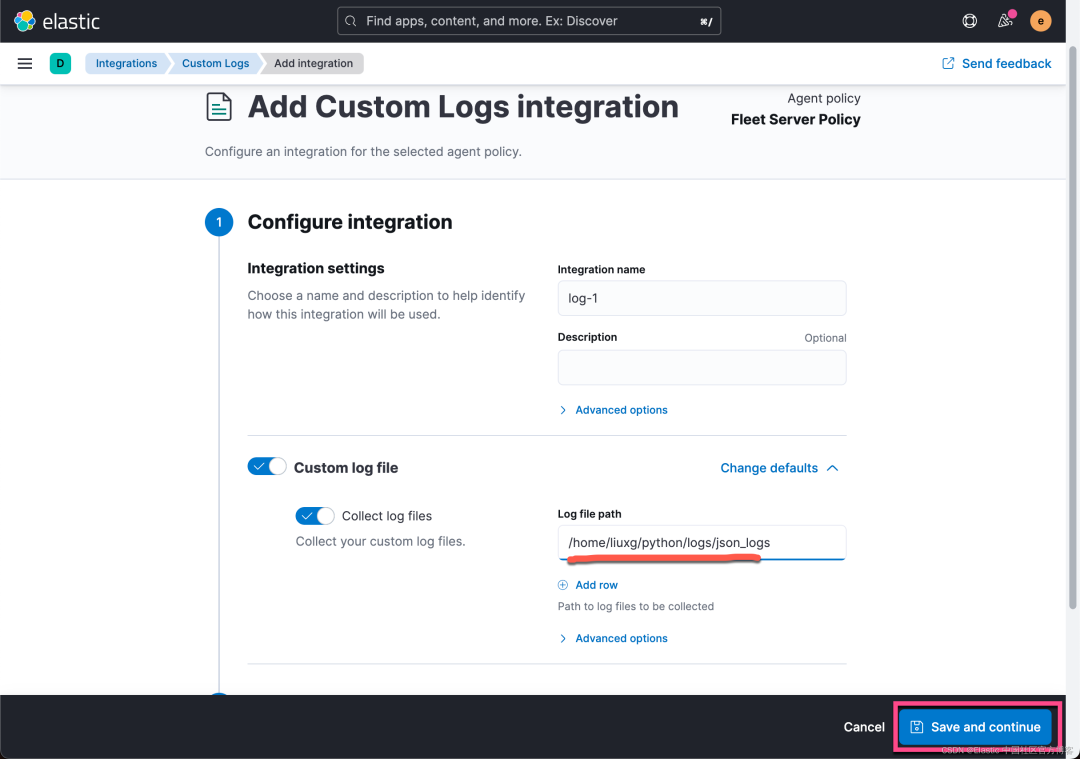
在上面,我们把 Ubuntu OS 上的日志的路径添加进去:
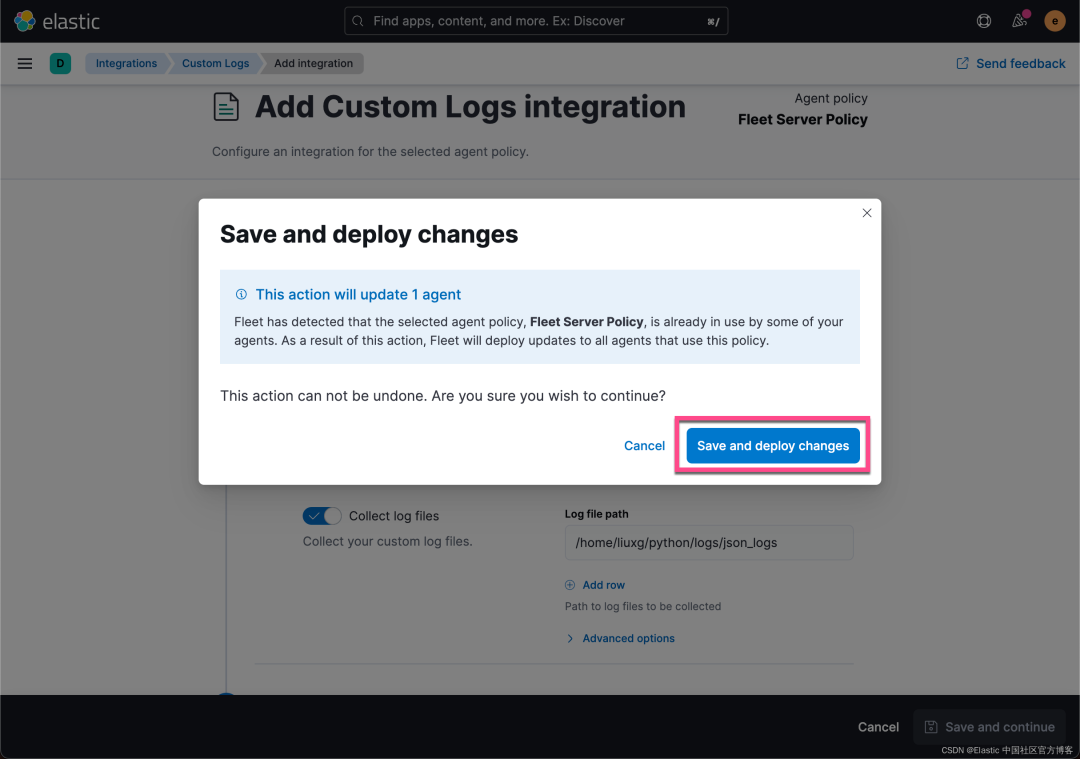
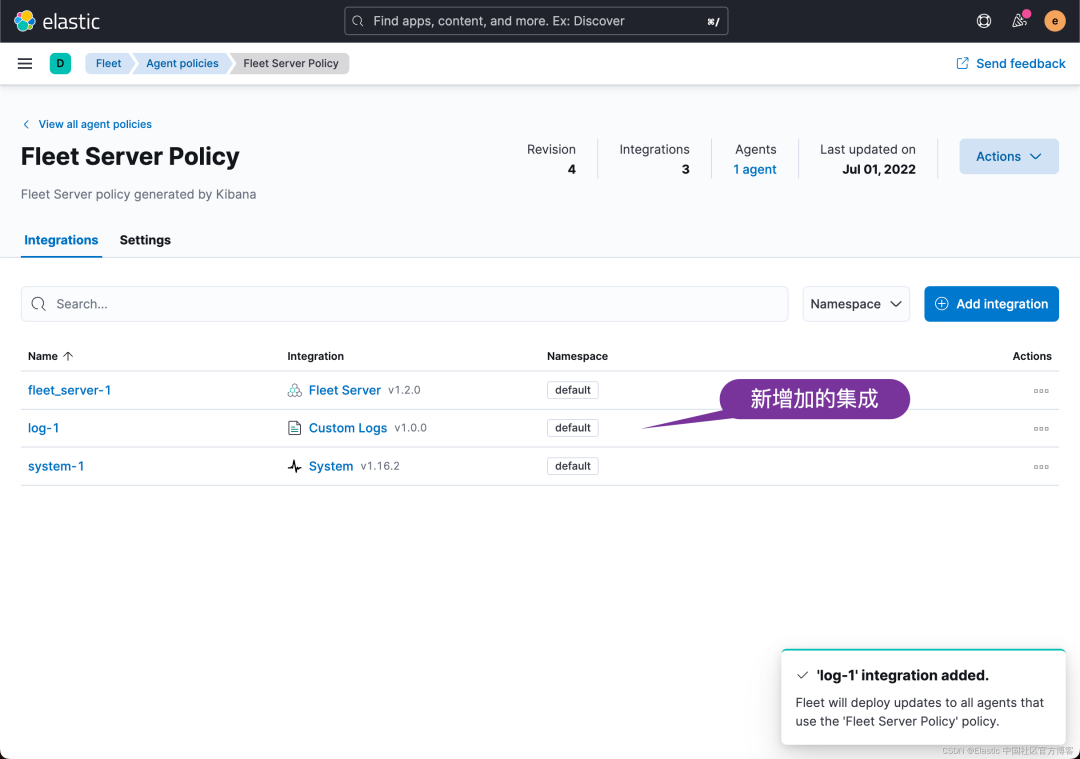
在上面,我们可以看到新增加的 log-1 集成。
如果你之前已经生成过 json_logs 日志文件,我们可以删除当前目录的文件,并再次生成该文件:
liuxg@liuxgu:~/python/logs$ pwd
/home/liuxg/python/logs
liuxg@liuxgu:~/python/logs$ ls
createlogs.py createlogs_1.py createlogs_2.py filebeat_json.yml json_logs test.log
liuxg@liuxgu:~/python/logs$ rm json_logs
liuxg@liuxgu:~/python/logs$ python createlogs_2.py
我们接下来回到 Discover 去查看:
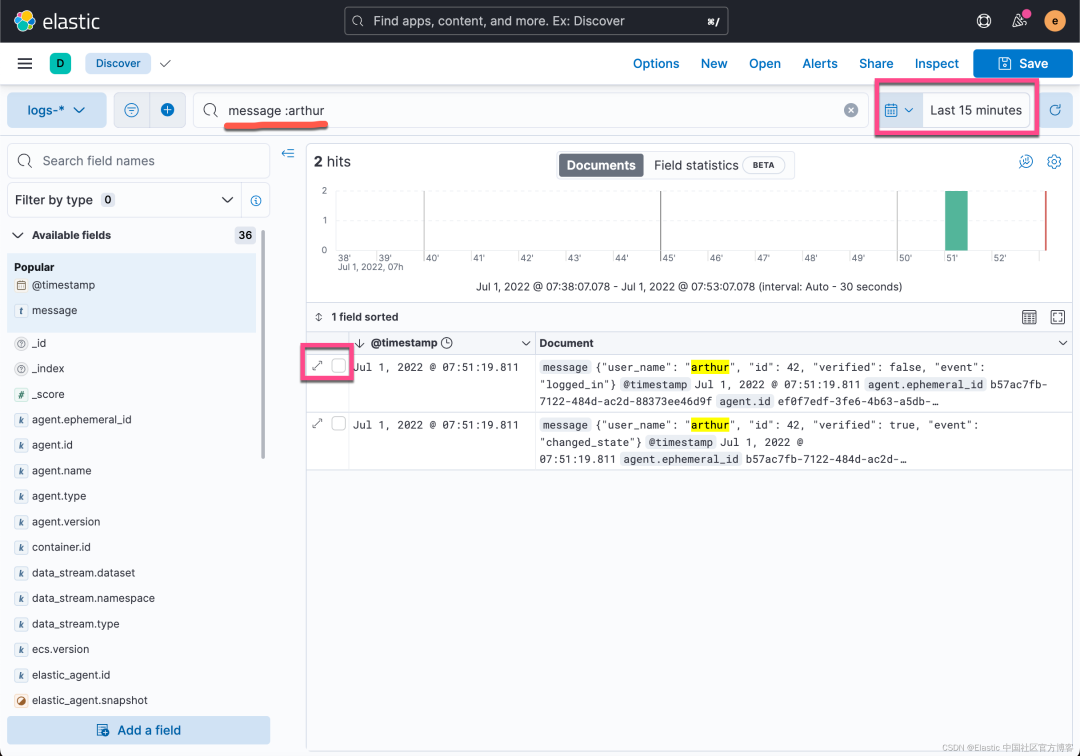
在搜索框中输入 json_logs,我们发现在过去 15分钟之内有两个新摄入的文档。我们再次查看 message 的内容:
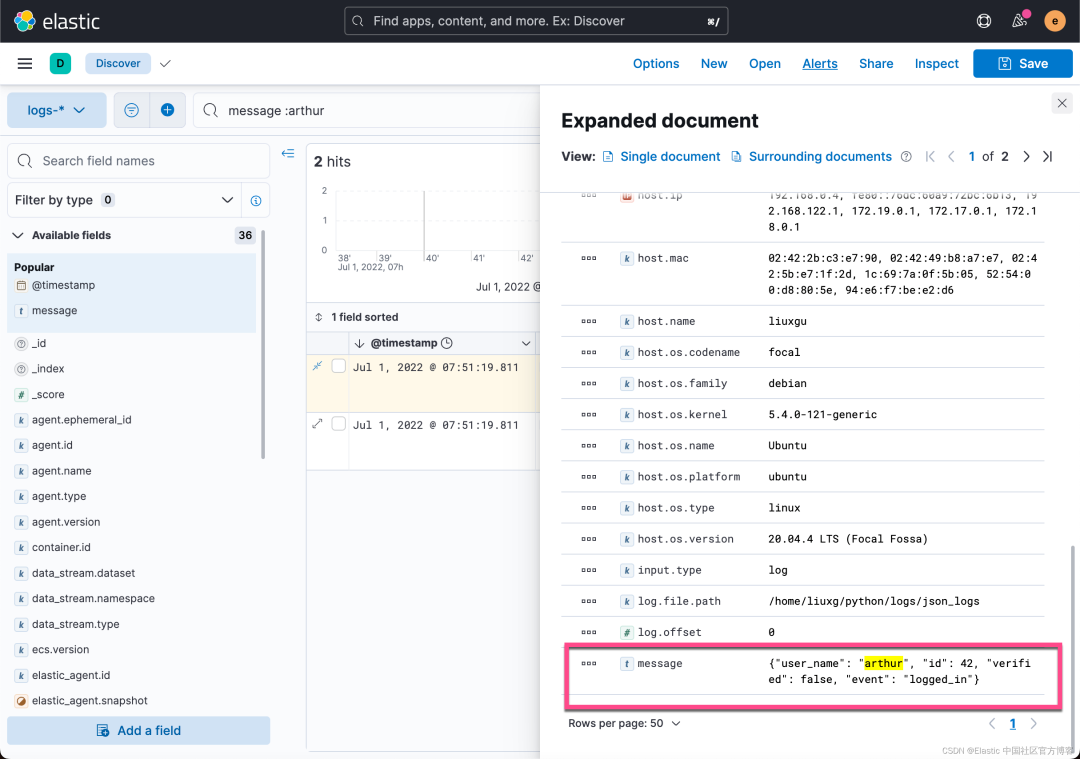
显然,我们可以看到 message 字段显示的就是我们之前在日志中的信息。它是一个 JSON 格式的信息。这个虽然好,但是它不是结构化的日志信息。我们想要的是 user_name 为文档的一个字段,id 为另外一个字段这样的结构化信息。在之前的 Filebeat 中,我们可以轻松地使用 Filebeat 所提供的 processors 或者就像如同在文章 “Beats: 使用 Filebeat 进行日志结构化 - Python” 使用的那样。我们可以使用 Filebeat input type 所提供的固有功能来完成。再者,我们还可以使用 Elasticsearch 集群的 ingest node 来完成。
那么针对我们目前的 Elastic Agent 摄入方式,我们该如何结构化这个 message 信息呢?答案是使用 ingest pipeline。
我们在 Kibana 的 Dev Tools 中创建如下的 ingest pipeline:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "structure a JSON format message",
"processors": [
{
"json": {
"field": "message",
"target_field": "json_fields"
}
}
]
},
"docs": [
{
"_source": {
"message": "{\"user_name\": \"arthur\", \"id\": 42, \"verified\": false, \"event\": \"logged_in\"}"
}
}
]
}
在上面,我们通过 _simulate 来测试我们的 pipeline:
{
"docs": [
{
"doc": {
"_index": "_index",
"_id": "_id",
"_source": {
"json_fields": {
"verified": false,
"id": 42,
"event": "logged_in",
"user_name": "arthur"
},
"message": """{"user_name": "arthur", "id": 42, "verified": false, "event": "logged_in"}"""
},
"_ingest": {
"timestamp": "2022-07-01T00:03:30.040008Z"
}
}
}
]
}
如上所示,我们的 josn processor 能够非常出色地完成 message 的结构化,并把结构化的信息保存于一个叫做 json_fields 的字段中。在完成上面的模拟后,我们使用如下的命令来创建一个 pipeline:
PUT _ingest/pipeline/message_structure
{
"description": "structure a JSON format message",
"processors": [
{
"json": {
"field": "message",
"target_field": "json_fields"
}
}
]
}
在上面,我们创建了一个叫做 message_structure 的 ingest pipeline。
我们接下来展示如何在 custom logs 里来使用这个 ingest pipeline。我们重新打开 log-1 集成:
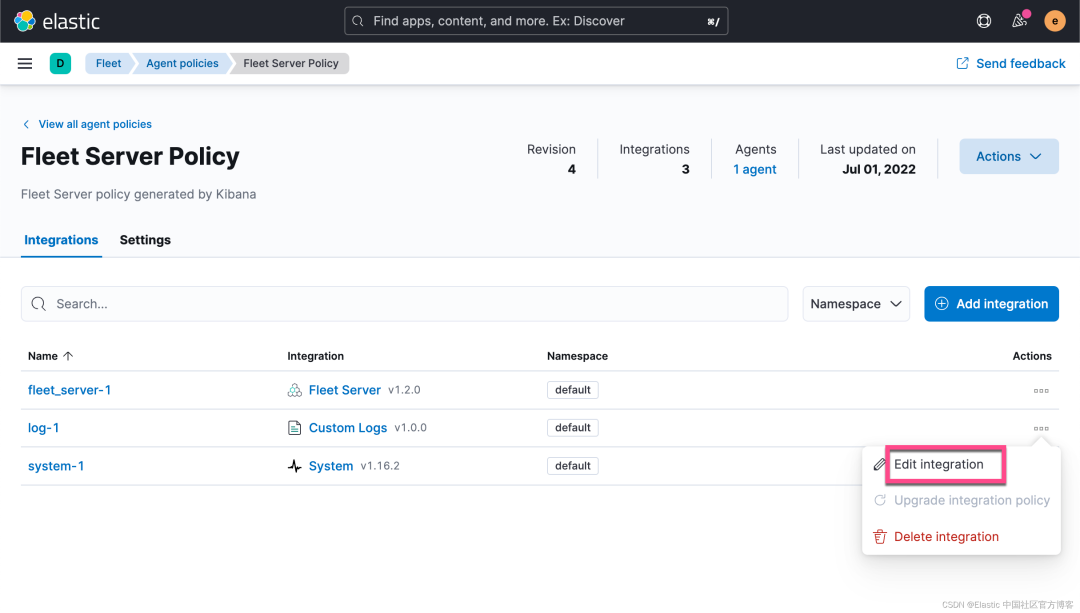
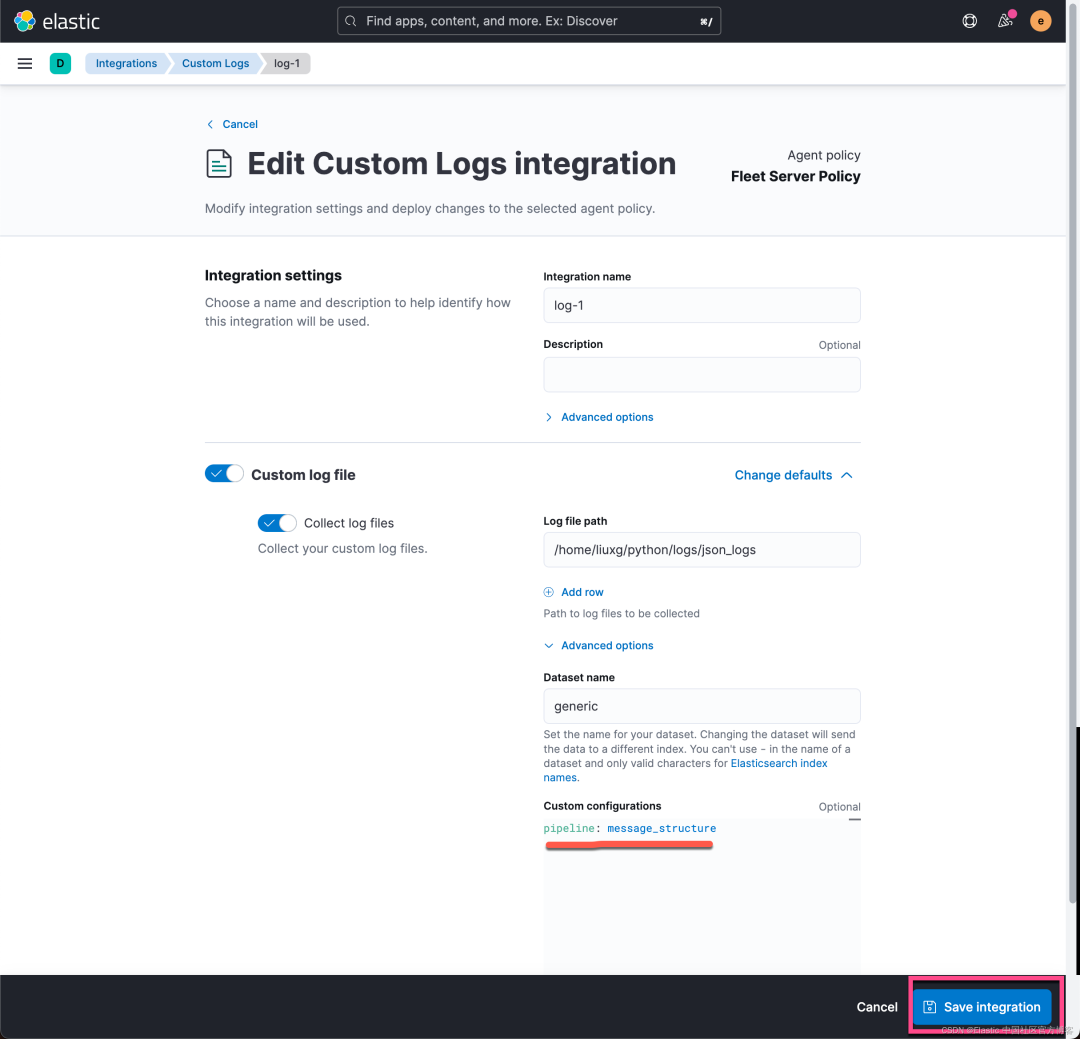
如上所示,我们在 Custom congfiguration 里填写 pipeline 的定义。点击上面的 Save integration:
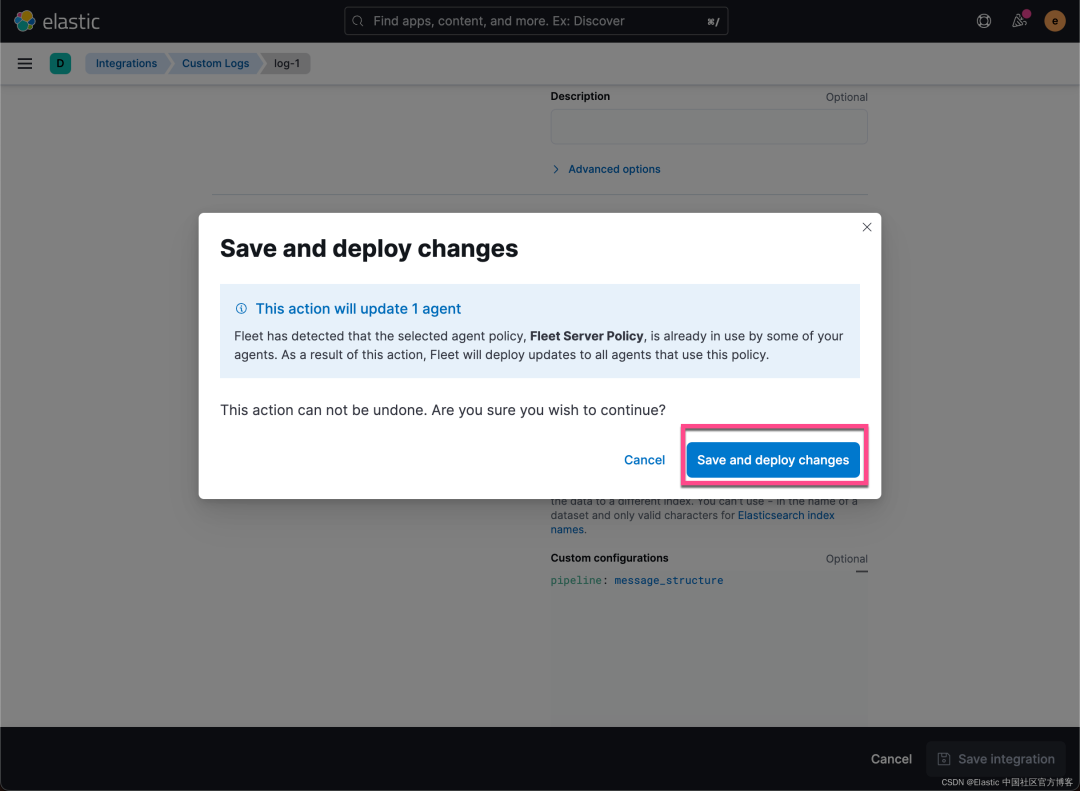
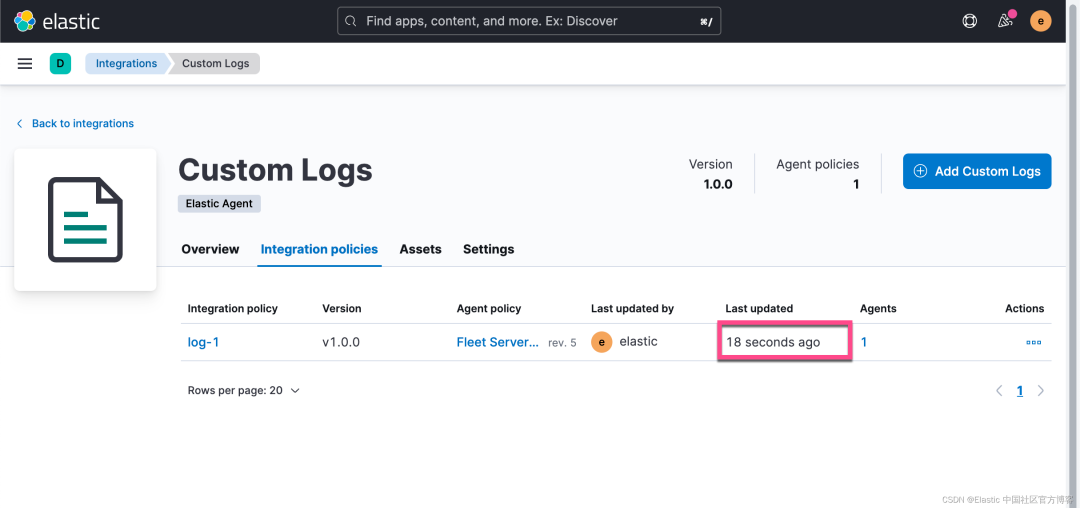
上面显示,我们的更新完毕。
我们接下来再次删除在日志目录下的 json_logs 文件,并再次运行 python 应用:
liuxg@liuxgu:~/python/logs$ pwd
/home/liuxg/python/logs
liuxg@liuxgu:~/python/logs$ ls
createlogs.py createlogs_1.py createlogs_2.py filebeat_json.yml json_logs test.log
liuxg@liuxgu:~/python/logs$ rm json_logs
liuxg@liuxgu:~/python/logs$ python createlogs_2.py
我们再次回到 Discover 界面来进行查看:
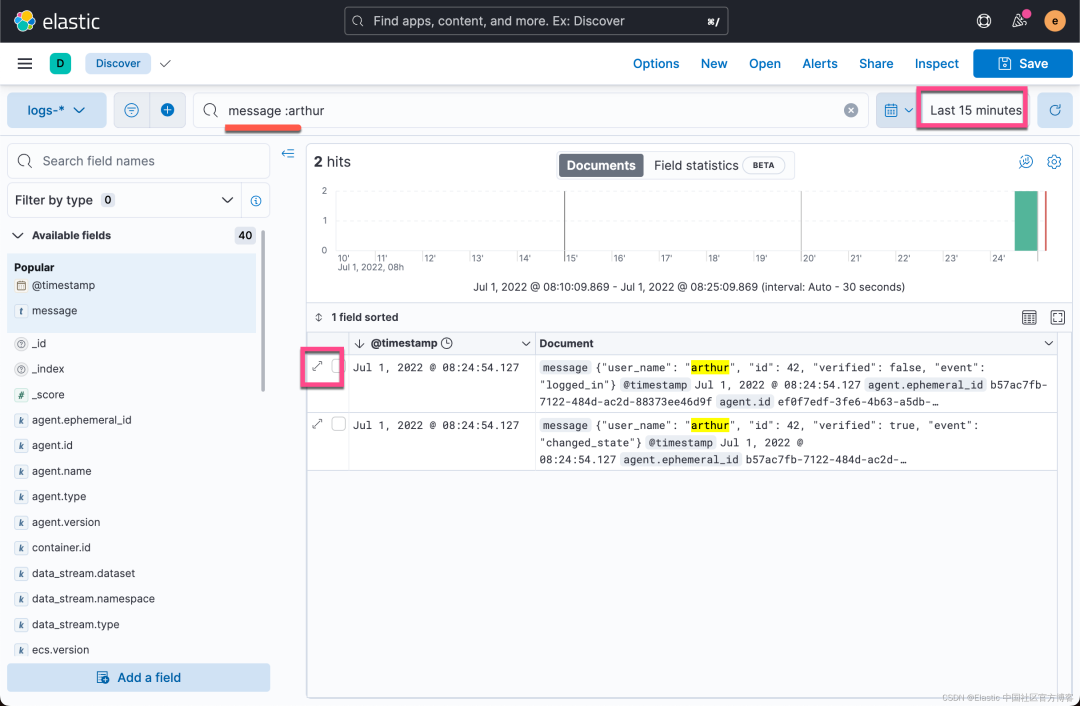
我们可以看到最新的日志信息被收集起来了。我们展开该文档进行查看:
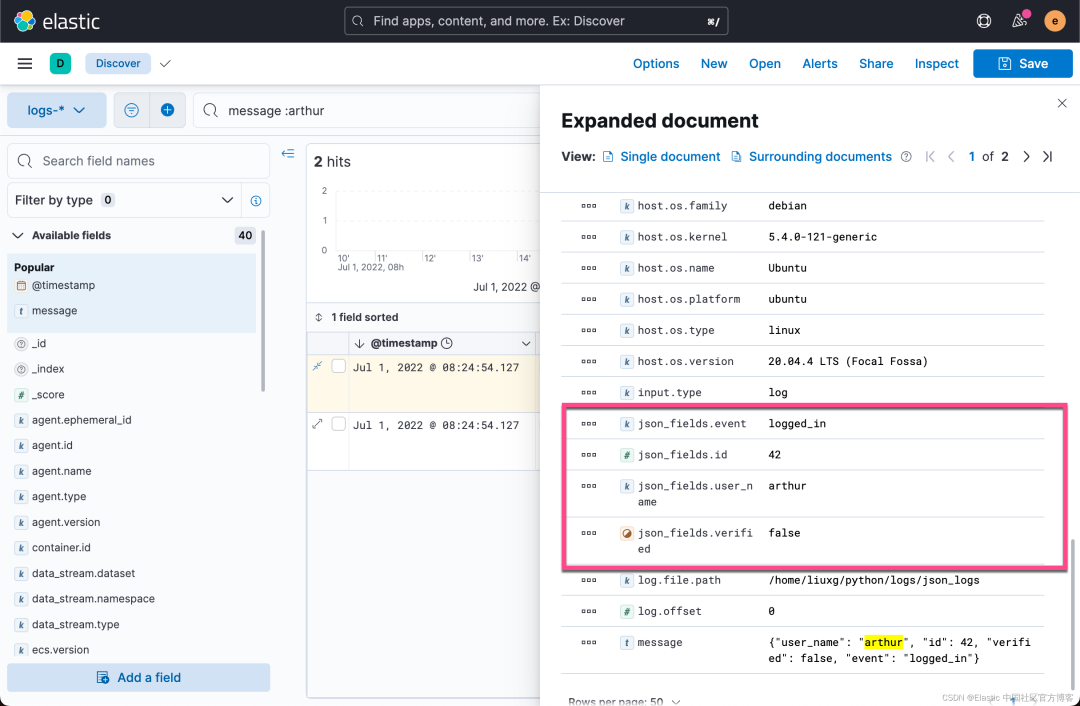
我们可以看到 message 的信息被结构化了,并且保存于一个叫做 json_fields 的字段中。
好了,今天我的分享就写到这里。希望对大家从 Beats 转换到 Elastic Agents 的使用提供一个平滑的过度。在未来,Elastic 更推崇 Elastic Agents 的使用虽然之前的 Beats 方式还可以继续使用。使用 Elastic Agents 可以使我们的 Agents 更容易集中管理。
使用 Elastic Agents 把定制的日志摄入到 Elasticsearch 中的更多相关文章
- logstash收集的日志输出到elasticsearch中
logstash收集的日志输出到elasticsearch中 一.需求 二.实现步骤 1.编写pipeline文件 1.`elasticsearch`配置参数解析: 2.可能会报的一个异常 2.准备测 ...
- logstash 6.6.0 读取nginx日志 插入到elasticsearch中
logstash.conf input { # For detail config for log4j as input, # See: https://www.elastic.co/guide/en ...
- 转载---Beats:如何使用Filebeat将MySQL日志发送到Elasticsearch
在今天的文章中,我们来详细地描述如果使用Filebeat把MySQL的日志信息传输到Elasticsearch中.为了说明问题的方便,我们的测试系统的配置是这样的: 我有一台MacOS机器.在上面我安 ...
- Beats:使用 Elastic Stack 记录 Python 应用日志
文章转载自:https://elasticstack.blog.csdn.net/article/details/112259500 日志记录实际上是每个应用程序都必须具备的功能.无论你选择基于哪种技 ...
- ELK日志系统:Elasticsearch + Logstash + Kibana 搭建教程
环境:OS X 10.10.5 + JDK 1.8 步骤: 一.下载ELK的三大组件 Elasticsearch下载地址: https://www.elastic.co/downloads/elast ...
- Windows 系统下json 格式的日志文件发送到elasticsearch
Windows 系统下json 格式的日志文件发送到elasticsearch配置 Nxlog-->logstash-->ElasticSearch Logstash https://ww ...
- ELK日志系统:Elasticsearch + Logstash + Kibana 搭建教程(转)
环境:OS X 10.10.5 + JDK 1.8 步骤: 一.下载ELK的三大组件 Elasticsearch下载地址: https://www.elastic.co/downloads/elast ...
- ELK日志系统:Elasticsearch+Logstash+Kibana+Filebeat搭建教程
ELK日志系统:Elasticsearch + Logstash + Kibana 搭建教程 系统架构 安装配置JDK环境 JDK安装(不能安装JRE) JDK下载地址:http://www.orac ...
- kafka日志同步至elasticsearch和kibana展示
kafka日志同步至elasticsearch和kibana展示 一 kafka consumer准备 前面的章节进行了分布式job的自动计算的概念讲解以及实践.上次分布式日志说过日志写进kafka, ...
随机推荐
- OneOS下调试支持的几种方式
方法论 当我们遇到问题,应该怎么办?这不仅应用于程序开发,也是我们在生活中遇到问题的时候,应该想的事儿,怎么办!趁着此次机会,我好好想了七秒钟. 先问是不是问题,如果不是就不用解决了 如果确实是问题, ...
- JS中的数据类型及转换
js的六大类型 js中有六种数据类型,Boolean: 布尔类型 Number:数字(整数int,浮点数float ) String:字符串 Object:对象 (包含Array数组 ) 特殊数据类型 ...
- 60行从零开始自己动手写FutureTask是什么体验?
前言 在并发编程当中我们最常见的需求就是启动一个线程执行一个函数去完成我们的需求,而在这种需求当中,我们常常需要函数有返回值.比如我们需要同一个非常大的数组当中数据的和,让每一个线程求某一个区间内部的 ...
- 技术分享 | 自制GreatSQL Docker镜像
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 近期打算制作一个GreatSQL的docker镜像,方便社区用户使用GreatSQL. 制作docker镜像的环境基于Ce ...
- 超全selenium元素定位XPath、CSS
说明:在HTML页面中,<p> 是一个标签,<p>hello</p> 是一个元素,元素由一个开始的标签和结束的标签组成.<font color="r ...
- 宜宾市黑烟车电子抓拍系统App
2020.11 - 2021.06负责手机App开发 项目说明: 主要用于管理人员的移动办公,通过与管理平台共享数据库,实现:人工审核.推送交警.账户管理.信息查询.数据统计.点位电子地图.设备 ...
- 完整代码:AgileFontSet迅捷字体设置程序
AgileFontSet用于快捷设置Windows系统字体和桌面图标间距,介绍参见:https://www.cnblogs.com/ybmj/p/11340105.html .这里提供AgileFon ...
- JAVA语言基础组成(2)
函数 函数的定义 1.什么是函数? 函数就是定义在类中的具有特定功能的一段独立小程序.函数也称为方法. 2.函数的格式: 修饰符 返回值类型 函数名(参数类型 形式参数1,参数类型 形式参数2,.. ...
- 创新能力加速产业发展,SphereEx 荣获“中关村银行杯”『大数据与云计算』领域 TOP1
8 月 9 日下午,2022 中关村国际前沿科技创新大赛"中关村银行杯"大数据与云计算领域决赛在北京市门头沟区中关村(京西)人工智能科技园·智能文创园落下了帷幕.SphereEx ...
- 在微信小程序中,如何获取 for 循环的 index
微信小程序中,for 循环的 index(索引值)可以用wx:for-index="index"来获取. <view class="item" wx:fo ...