Nvidia Tensor Core初探
1 背景
2 硬件单元
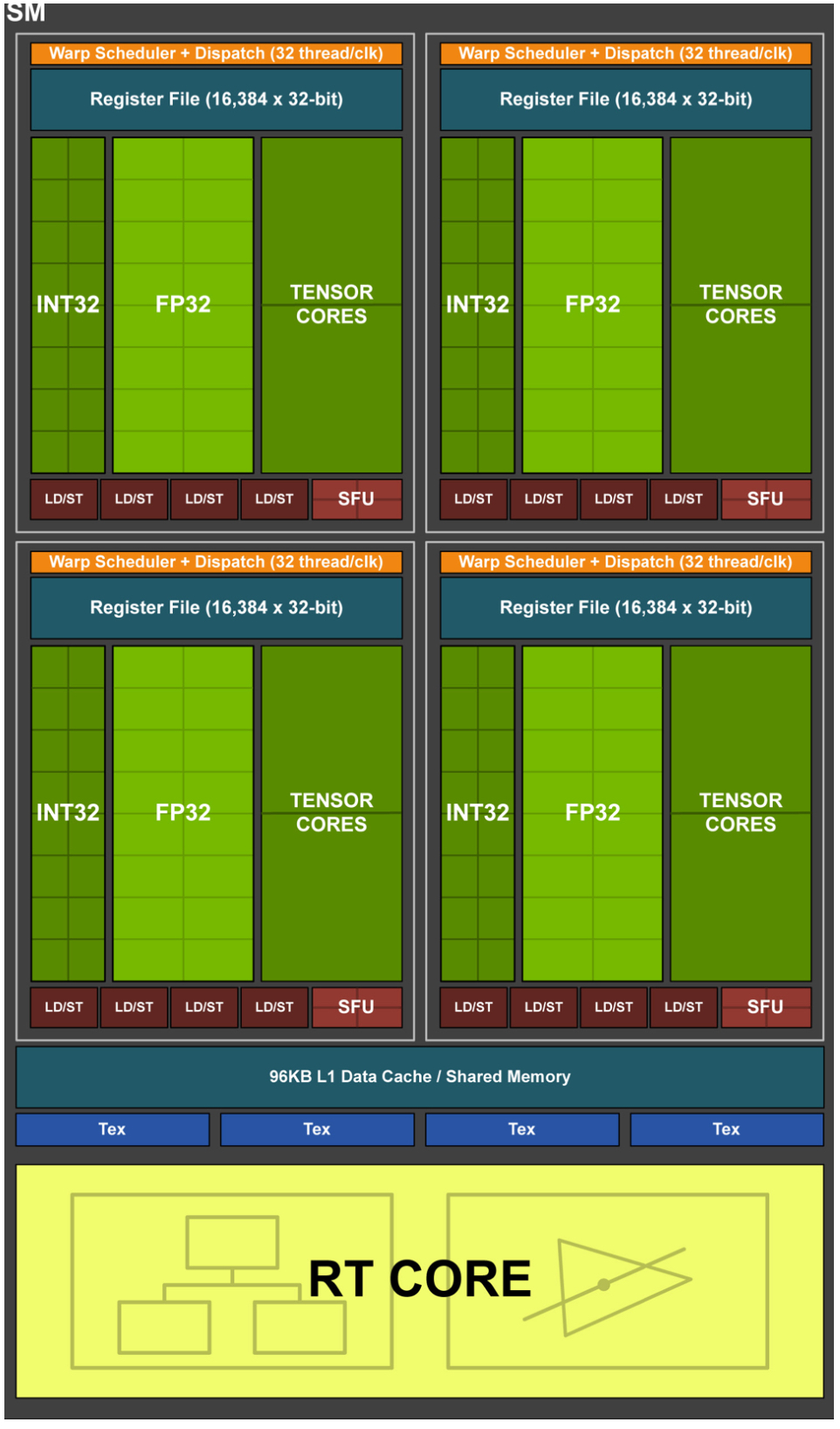
3 架构
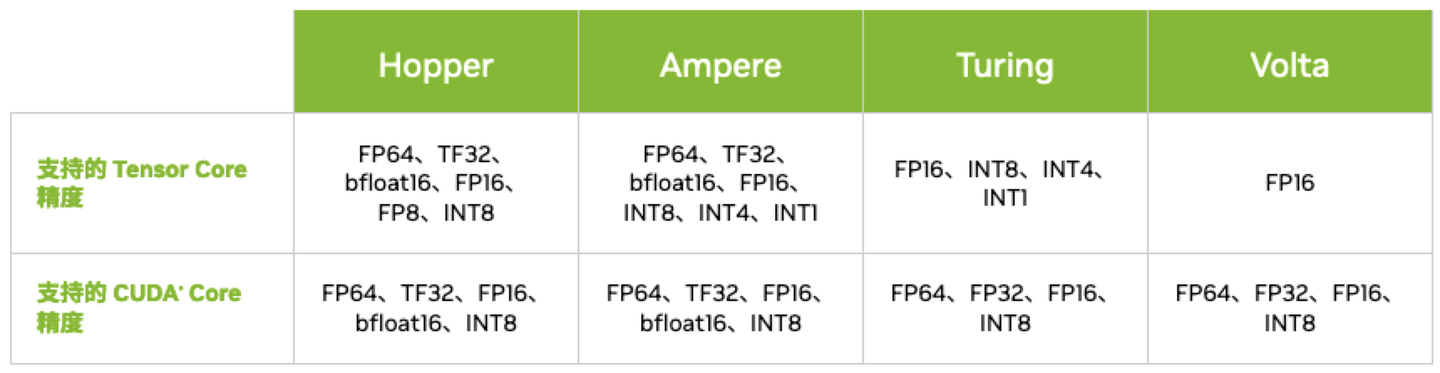
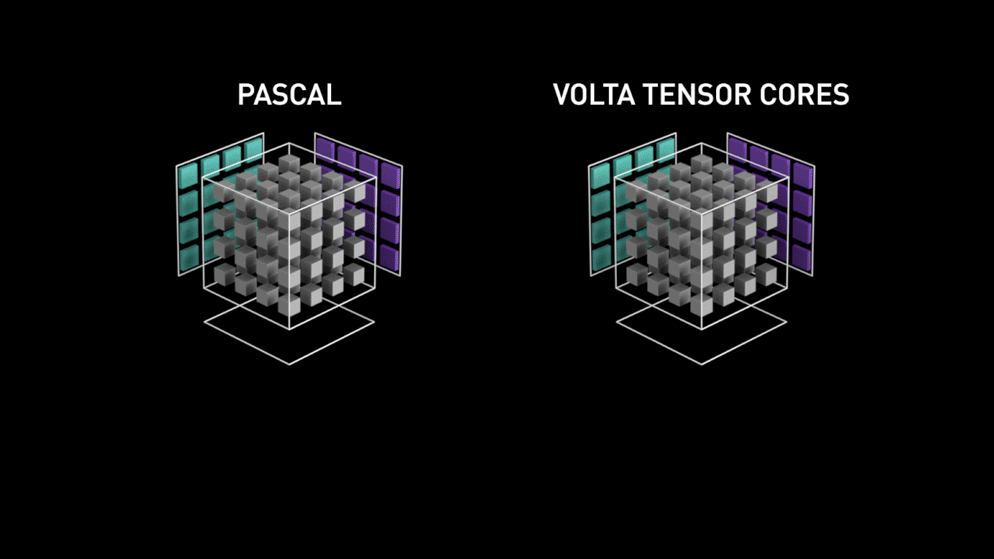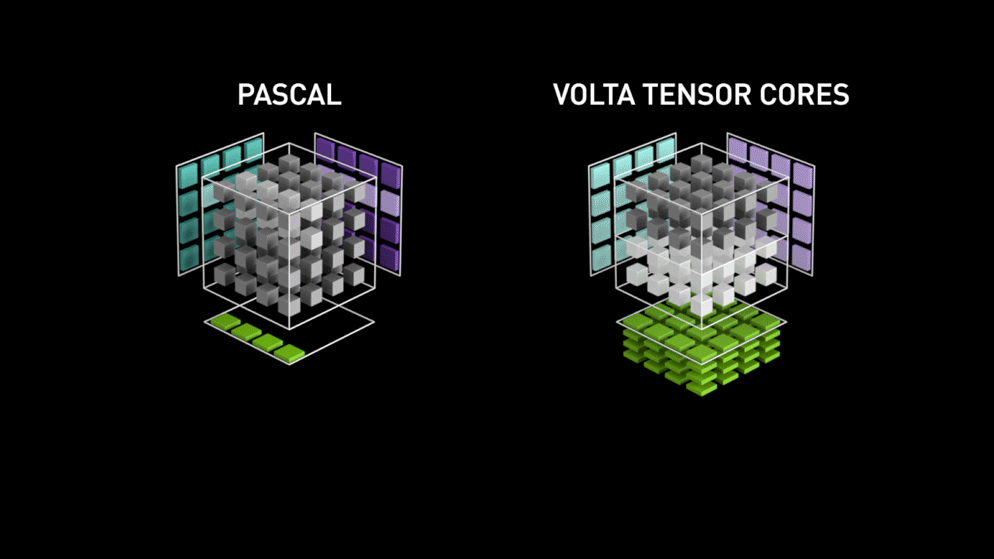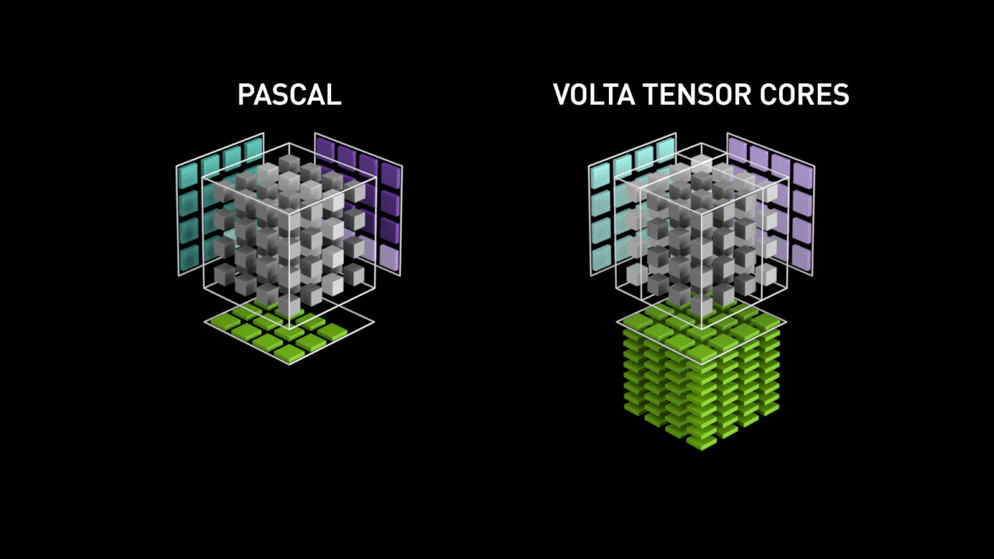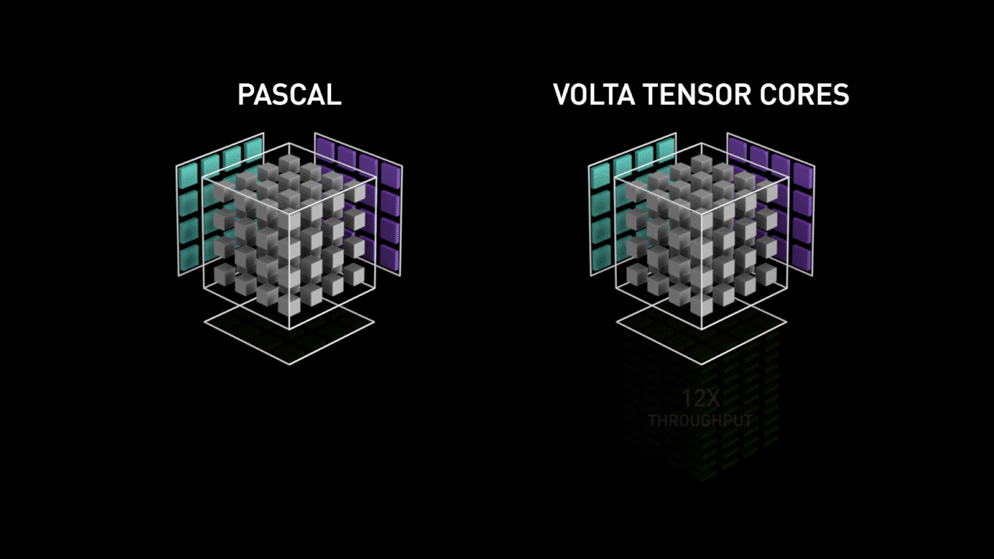
3.1 Volta Tensor Core
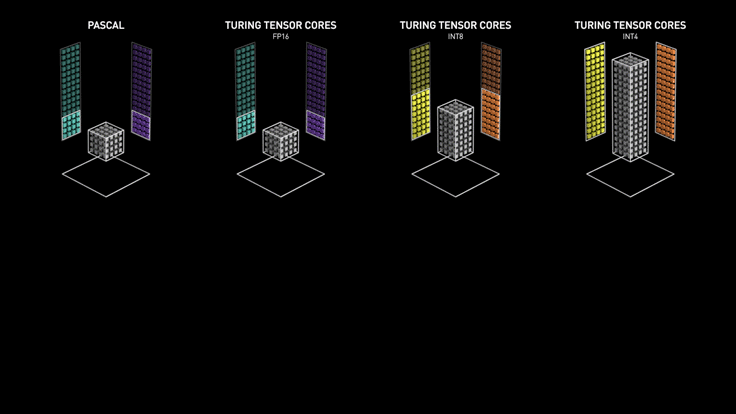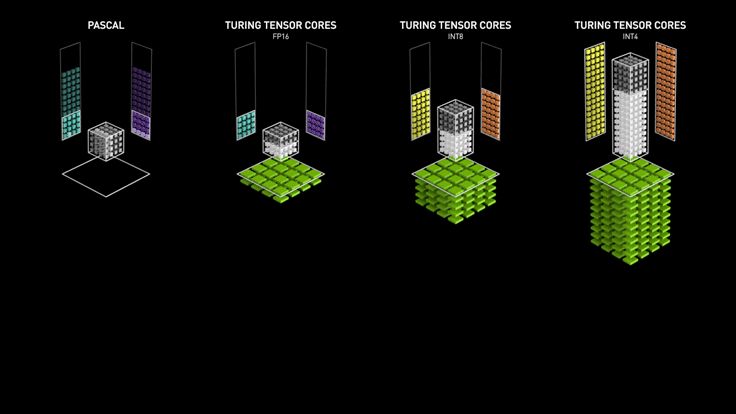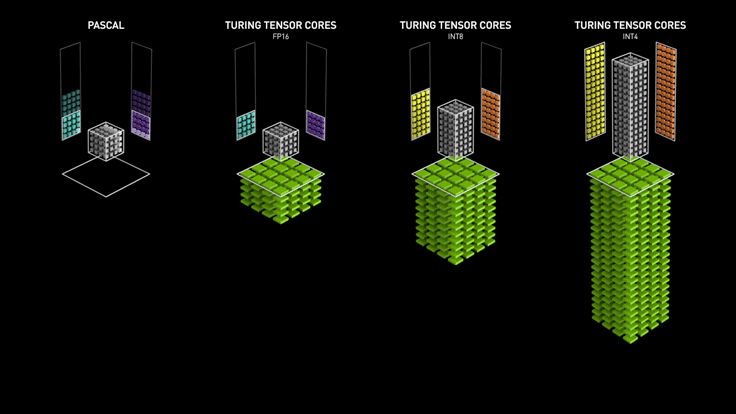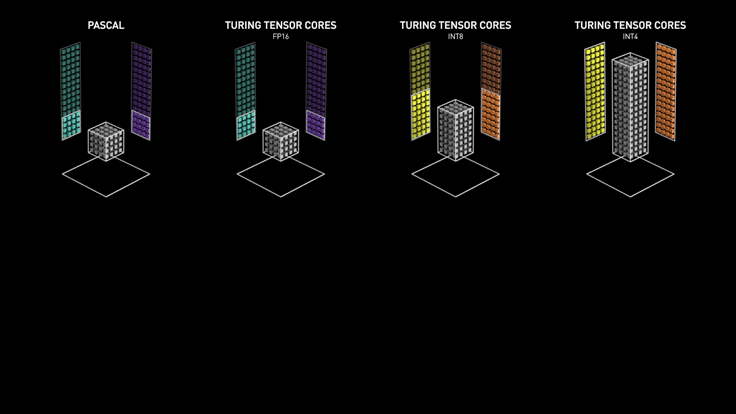
3.2 Turing Tensor Core
3.3 Ampere Tensor Core
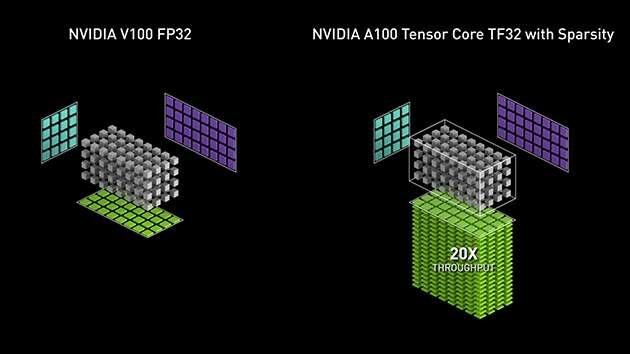
3.4 Hopper Tensor Core

4 调用
4.1 WMMA (Warp-level Matrix Multiply Accumulate) API
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment; void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
void fill_fragment(fragment<...> &a, const T& v);
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);
- fragment:Tensor Core数据存储类,支持matrix_a、matrix_b和accumulator
- load_matrix_sync:Tensor Core数据加载API,支持将矩阵数据从global memory或shared memory加载到fragment
- store_matrix_sync:Tensor Core结果存储API,支持将计算结果从fragment存储到global memory或shared memory
- fill_fragment:fragment填充API,支持常数值填充
- mma_sync:Tensor Core矩阵乘计算API,支持D = AB + C或者C = AB + C
4.2 WMMA PTX (Parallel Thread Execution)
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride};
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride};
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride};
wmma.mma.sync.aligned.alayout.blayout.shape.dtype.ctype d, a, b, c;
- wmma.load:Tensor Core数据加载指令,支持将矩阵数据从global memory或shared memory加载到Tensor Core寄存器
- wmma.store:Tensor Core结果存储指令,支持将计算结果从Tensor Core寄存器存储到global memory或shared memory
- wmma.mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C
4.3 MMA (Matrix Multiply Accumulate) PTX
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;
- ldmatrix:Tensor Core数据加载指令,支持将矩阵数据从shared memory加载到Tensor Core寄存器
- mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C
4.4 SASS
Nvidia Tensor Core初探的更多相关文章
- NVIDIA Tensor Cores解析
NVIDIA Tensor Cores解析 高性能计算机和人工智能前所未有的加速 Tensor Cores支持混合精度计算,动态调整计算以加快吞吐量,同时保持精度.最新一代将这些加速功能扩展到各种工作 ...
- NVIDIA深度学习Tensor Core性能解析(下)
NVIDIA深度学习Tensor Core性能解析(下) DeepBench推理测试之RNN和Sparse GEMM DeepBench的最后一项推理测试是RNN和Sparse GEMM,虽然测试中可 ...
- NVIDIA深度学习Tensor Core性能解析(上)
NVIDIA深度学习Tensor Core性能解析(上) 本篇将通过多项测试来考验Volta架构,利用各种深度学习框架来了解Tensor Core的性能. 很多时候,深度学习这样的新领域会让人难以理解 ...
- Tensor Core技术解析(下)
Tensor Core技术解析(下) 让FP16适用于深度学习 Volta的深度学习能力是建立在利用半精度浮点(IEEE-754 FP16)而非单精度浮点(FP32)进行深度学习训练的基础之上. 该能 ...
- Tensor Core技术解析(上)
Tensor Core技术解析(上) NVIDIA在SIGGRAPH 2018上正式发布了新一代GPU架构--Turing(图灵),黄仁勋称Turing架构是自2006年CUDA GPU发明以来最大的 ...
- 用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割
用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割 Accelerating Medical Image Segmentation with NVIDIA Tensor ...
- Asp.net Core 初探(发布和部署Linux)
前言 俗话说三天不学习,赶不上刘少奇.Asp.net Core更新这么长时间一直观望,周末帝都小雨,宅在家看了下Core Web App,顺便搭建了个HelloWorld环境来尝尝鲜,第一次看到.Ne ...
- jenkins部署net core初探
一步一步,小心翼翼吖.看了好几个博客,摸索了两天了,才搭建成功,不容易,先写篇文章记下来,hhhhhhhhhhhh 相关环境配置 服务器:centos7 源代码管理器:git 技术选型:net cor ...
- ASPNET CORE初探
ASP.NET Core 开发-中间件(Middleware) ASP.NET Core开发,开发并使用中间件(Middleware). 中间件是被组装成一个应用程序管道来处理请求和响应的软件组件 ...
- linux环境上运行.net core 初探
1.安装 .net core 环境 rpm --import https://packages.microsoft.com/keys/microsoft.ascsh -c 'echo -e " ...
随机推荐
- vue中模块化后mapState的使用
代码如下: 相当于声明了一个变量name,然后以state入参取得其modules文件夹中user文件里的name属性.因为在模块(如user)中,在抛出时的export default中添加了一句: ...
- Hive 操作与应用 词频统计
一.hive用本地文件进行词频统计 1.准备本地txt文件 2.启动hadoop,启动hive 3.创建数据库,创建文本表 4.映射本地文件的数据到文本表中 5.hql语句进行词频统计交将结果保存到结 ...
- 北京金橙子ezcad2和lmc1控制卡二次开发的动态连接库手册
我要吐槽一下金橙子打电话过去一问三不答.要个手册2.0的不给,只给3.0的.而且态度角度***钻,想尽一切办法让你自己用不了.我又不是要做打标卡,只是做个二次开发.有必要这样吗?反正我是不会推荐用户再 ...
- 转发 关于Windows安装解压版MySQL出现服务正在启动-服务无法启动的问题
部分转自 :https://blog.csdn.net/u013901768/article/details/80707307 我是从服务器上复制了mysql的整个目录,到本地,然后怎么也不好用,看了 ...
- F. K-th Power 容斥,莫比乌斯
F. K-th Power 传送门: 牛客:https://ac.nowcoder.com/acm/contest/34866/F cf:https://codeforces.com/group/5z ...
- Linux centos7.6 安装 docker
1.安装官网教程 https://docs.docker.com/engine/install/centos/ 2.卸载之前的 docker sudo yum remove docker \ dock ...
- loadrunner获取时间戳
web_save_timestamp_param("tStamp", LAST); //取时间戳
- MySql数据库的两大引擎InnoDB和MyIsam的区别
事务方面 InnoDB支持事务,MyISAM不支持事务.MySql的默认存储引擎为InnoDB 外键方面 InnoDB支持外键,MyISAM不支持,对一个包含外键的InnoDB表转为MYISAM会失败 ...
- switch case return return 返回不了值的原因
我在页面写了一个ajax ,但是控制器 是 用switch case break 控制的控制器 , 我想 在case login 方法里 直接 return , 但是不好使 始终是 null , ...
- vsftpd配置FTP服务器(Centos7.x安装)
安装配置 1. 安装vsftpd 检查是否安装了vsftpd # rpm -qa | grep vsftpdvsftpd-2.2.2-24.el6.x86_64 如果有展示则已经安装,不需要重新安装 ...