Nvidia Tensor Core初探
1 背景
2 硬件单元
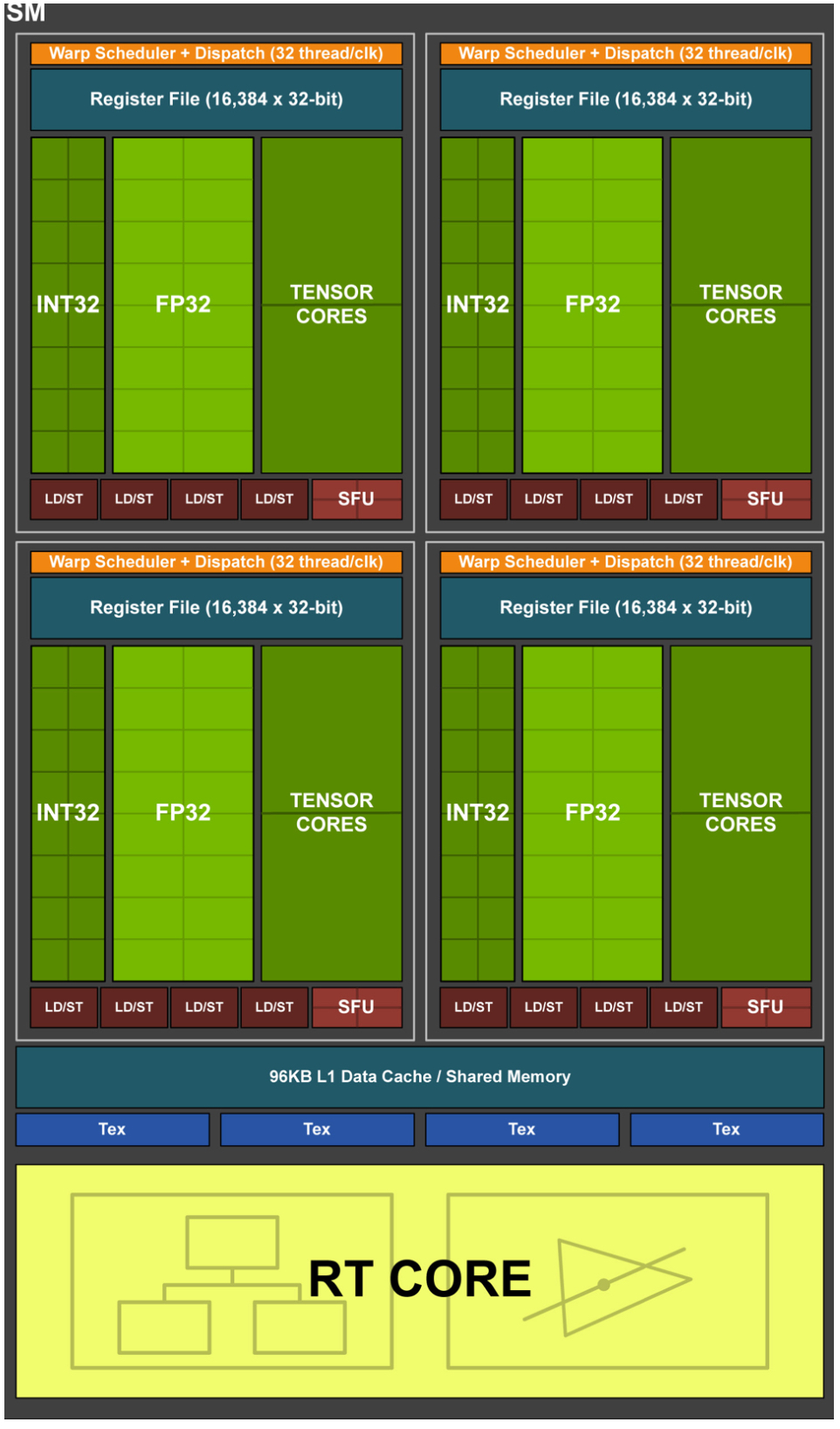
3 架构
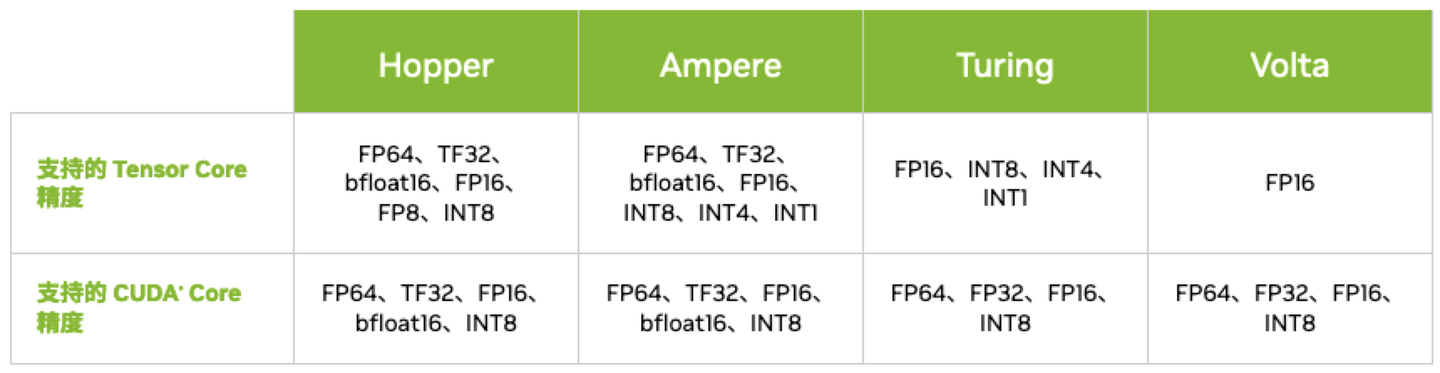
3.1 Volta Tensor Core
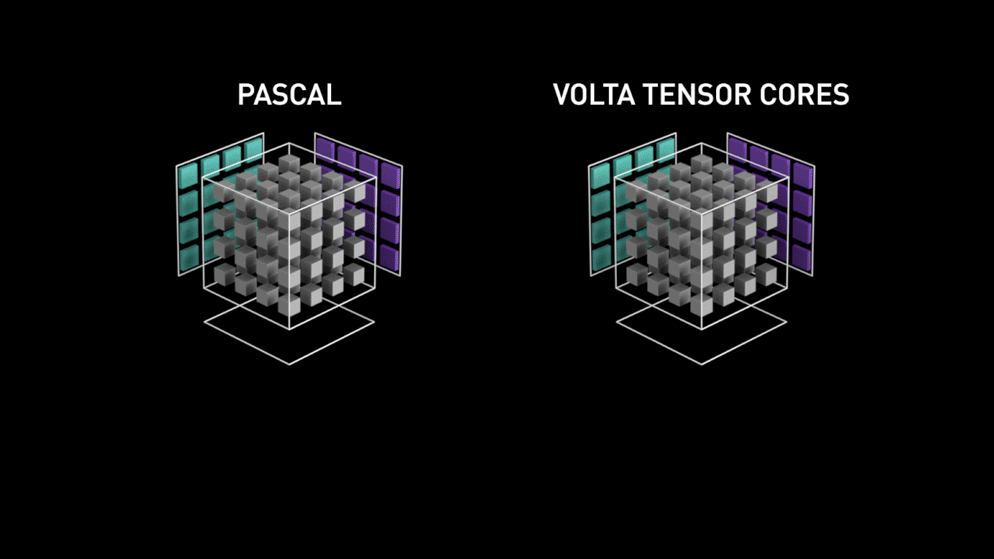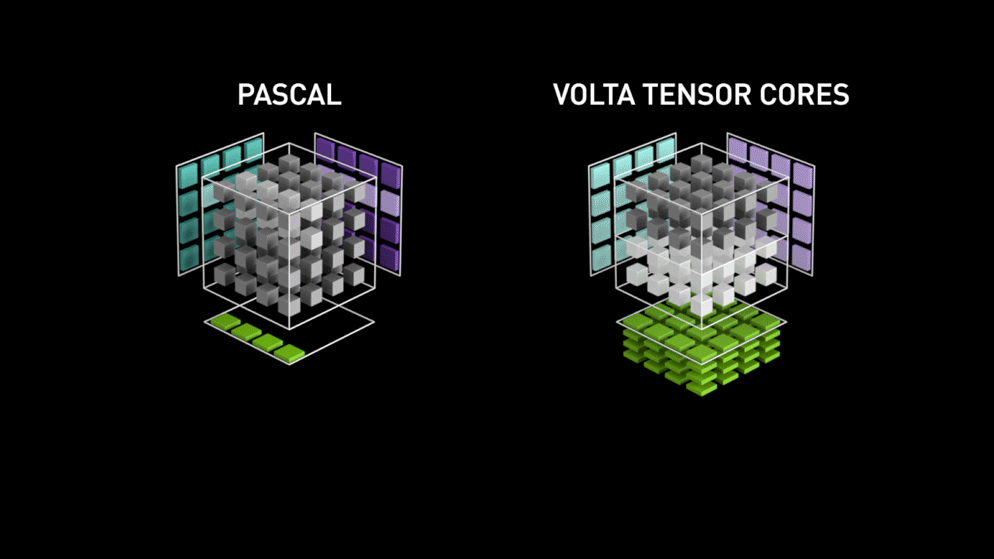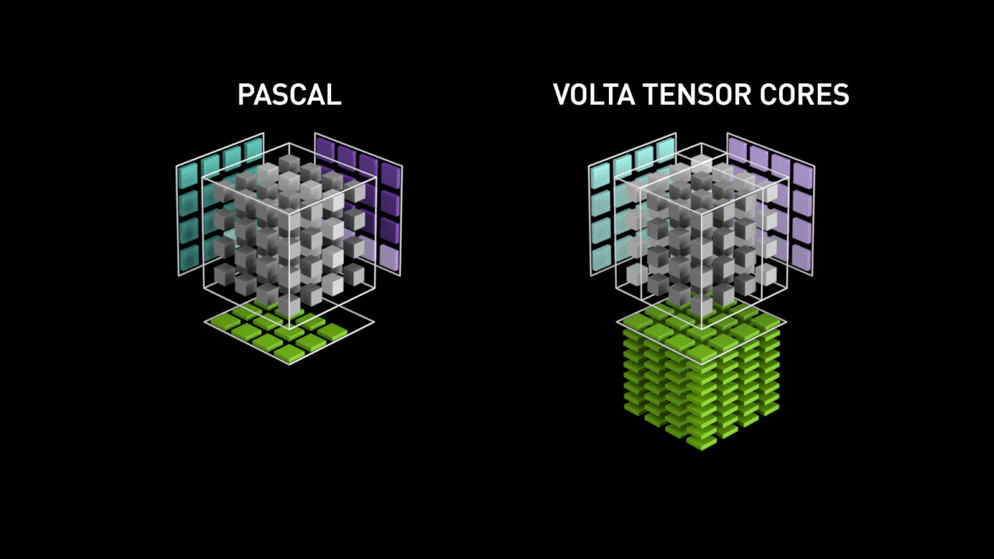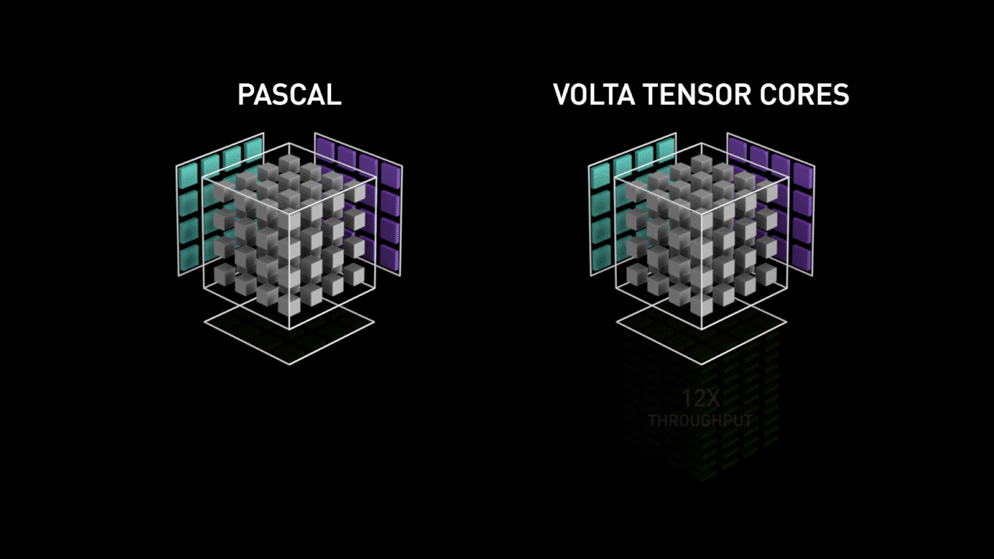
3.2 Turing Tensor Core
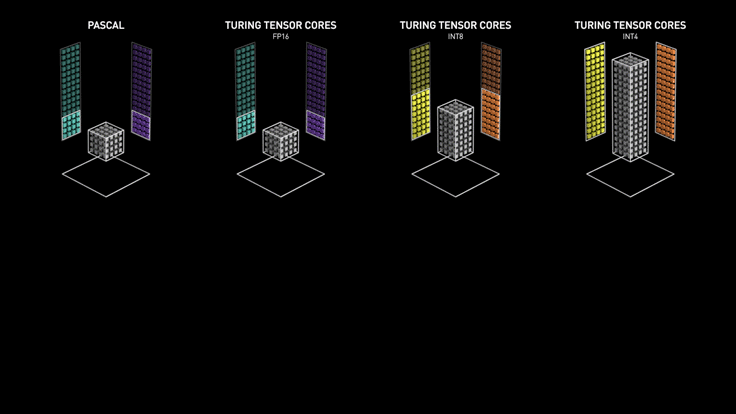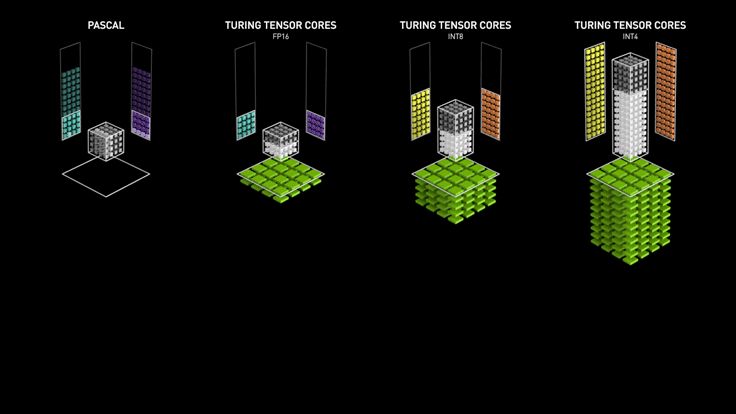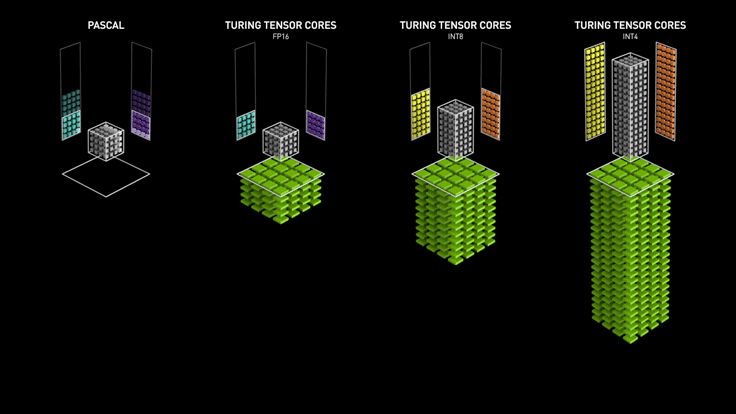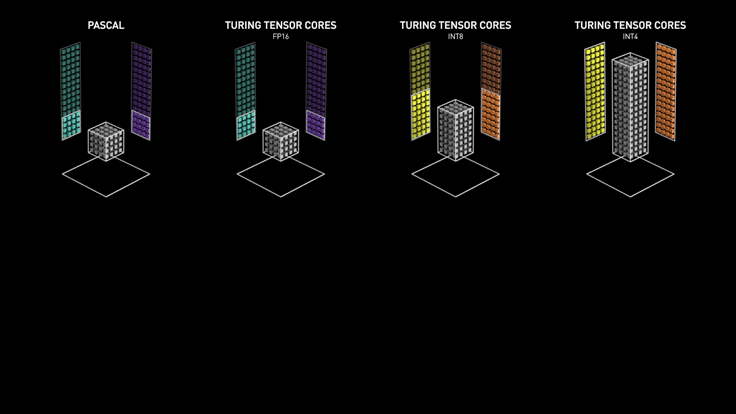
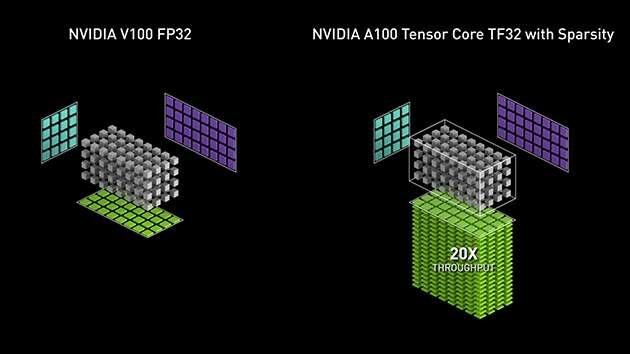
3.3 Ampere Tensor Core
3.4 Hopper Tensor Core

4 调用
4.1 WMMA (Warp-level Matrix Multiply Accumulate) API
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment; void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
void fill_fragment(fragment<...> &a, const T& v);
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);
- fragment:Tensor Core数据存储类,支持matrix_a、matrix_b和accumulator
- load_matrix_sync:Tensor Core数据加载API,支持将矩阵数据从global memory或shared memory加载到fragment
- store_matrix_sync:Tensor Core结果存储API,支持将计算结果从fragment存储到global memory或shared memory
- fill_fragment:fragment填充API,支持常数值填充
- mma_sync:Tensor Core矩阵乘计算API,支持D = AB + C或者C = AB + C
4.2 WMMA PTX (Parallel Thread Execution)
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride};
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride};
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride};
wmma.mma.sync.aligned.alayout.blayout.shape.dtype.ctype d, a, b, c;
- wmma.load:Tensor Core数据加载指令,支持将矩阵数据从global memory或shared memory加载到Tensor Core寄存器
- wmma.store:Tensor Core结果存储指令,支持将计算结果从Tensor Core寄存器存储到global memory或shared memory
- wmma.mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C
4.3 MMA (Matrix Multiply Accumulate) PTX
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;
- ldmatrix:Tensor Core数据加载指令,支持将矩阵数据从shared memory加载到Tensor Core寄存器
- mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C
4.4 SASS
Nvidia Tensor Core初探的更多相关文章
- NVIDIA Tensor Cores解析
NVIDIA Tensor Cores解析 高性能计算机和人工智能前所未有的加速 Tensor Cores支持混合精度计算,动态调整计算以加快吞吐量,同时保持精度.最新一代将这些加速功能扩展到各种工作 ...
- NVIDIA深度学习Tensor Core性能解析(下)
NVIDIA深度学习Tensor Core性能解析(下) DeepBench推理测试之RNN和Sparse GEMM DeepBench的最后一项推理测试是RNN和Sparse GEMM,虽然测试中可 ...
- NVIDIA深度学习Tensor Core性能解析(上)
NVIDIA深度学习Tensor Core性能解析(上) 本篇将通过多项测试来考验Volta架构,利用各种深度学习框架来了解Tensor Core的性能. 很多时候,深度学习这样的新领域会让人难以理解 ...
- Tensor Core技术解析(下)
Tensor Core技术解析(下) 让FP16适用于深度学习 Volta的深度学习能力是建立在利用半精度浮点(IEEE-754 FP16)而非单精度浮点(FP32)进行深度学习训练的基础之上. 该能 ...
- Tensor Core技术解析(上)
Tensor Core技术解析(上) NVIDIA在SIGGRAPH 2018上正式发布了新一代GPU架构--Turing(图灵),黄仁勋称Turing架构是自2006年CUDA GPU发明以来最大的 ...
- 用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割
用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割 Accelerating Medical Image Segmentation with NVIDIA Tensor ...
- Asp.net Core 初探(发布和部署Linux)
前言 俗话说三天不学习,赶不上刘少奇.Asp.net Core更新这么长时间一直观望,周末帝都小雨,宅在家看了下Core Web App,顺便搭建了个HelloWorld环境来尝尝鲜,第一次看到.Ne ...
- jenkins部署net core初探
一步一步,小心翼翼吖.看了好几个博客,摸索了两天了,才搭建成功,不容易,先写篇文章记下来,hhhhhhhhhhhh 相关环境配置 服务器:centos7 源代码管理器:git 技术选型:net cor ...
- ASPNET CORE初探
ASP.NET Core 开发-中间件(Middleware) ASP.NET Core开发,开发并使用中间件(Middleware). 中间件是被组装成一个应用程序管道来处理请求和响应的软件组件 ...
- linux环境上运行.net core 初探
1.安装 .net core 环境 rpm --import https://packages.microsoft.com/keys/microsoft.ascsh -c 'echo -e " ...
随机推荐
- C#基于数据库链接增删改查
一.创建一个winfrom窗体 1.创建项目 2.创建一个链接数据的类 3.封装数据库的实体类(查询和增加) 在对数据操作时必须引用连个数据库using using System.Data; usin ...
- 第四天 while 嵌套循环语句
python全栈开发笔记第四天 while 嵌套循环语句 while 条件 while 条件 print() print() 例题:num1 =int(input("num1:") ...
- vs 2015 默认管理员启动
方法一: 找到 VS快捷方式 所在位置,并对其高级属性中的"用管理员身份运行"进行勾选,然后进行确定. 此方法 如果是通过sln文件的快捷方式打开的,不是管理员 方法二: 1.打开 ...
- Vue二级联动上传图片
二级联动的后台和之前一样都需要一个字典字段查询来实现二级联动 但是由于VUE语法和AJAX的不同在前台绑定的时候也有所不同 2.1 首先下拉框的写法就有了本质的改变通过v-model="&q ...
- requests模块获取cookie -----class 'requests.cookies.RequestsCookieJar'
#coding=utf-8 import requests url="http://www.baidu.com" response=requests.get(url) cookie ...
- 004Java的一些基本概念
004Java的一些基本概念 1.Java特性和优势 Java至少具有以下特性: 简单性(没有头文件.没有指针运算.也没有分配内存等操作) 面向对象(万物皆对象) 可移植性(一次编写,到处运行 Wri ...
- 【JIRA】jira issue reindex
参考文档: https://community.atlassian.com/t5/Marketplace-Apps-Integrations/Scriptrunner-Listener-Reindex ...
- python求列表中n个最大或最小的值
import heapq #y为结果列表,n为所求的n个值,x为来源列表 y=heapq.nsmallest(n,x) y=heapq.nlargest(n,x)
- Word 找不到 Endnote选项
Word 2010 找不到 Endnote选项汇总(不是Office有效加载项)因为基本百度上的问题我全都遇到了-说明:在我们使用Word的过程中,常常发现没有Endnote选项.然后去找百度方法:1 ...
- python pandas dataframe excel xlwings docx 常用简单函数方法汇总
# -*- coding: UTF-8 -*-import pandas as pdimport numpy as npimport datetimeimport osimport sysimport ...