技术分享 | innodb_buffer_pool_size为什么无法调低至1GB以内
前言
innodb_buffer_pool_size可以调大,却不能调小至1GB以内,这是为什么?
MySQL 版本:5.7.30
测试环境有台 MySQL 服务器反应很慢,检查系统后发现内存使用量已超过90%,并且有大量的SWAP占用:

运行top按内存占用排序,查看系统资源使用情况
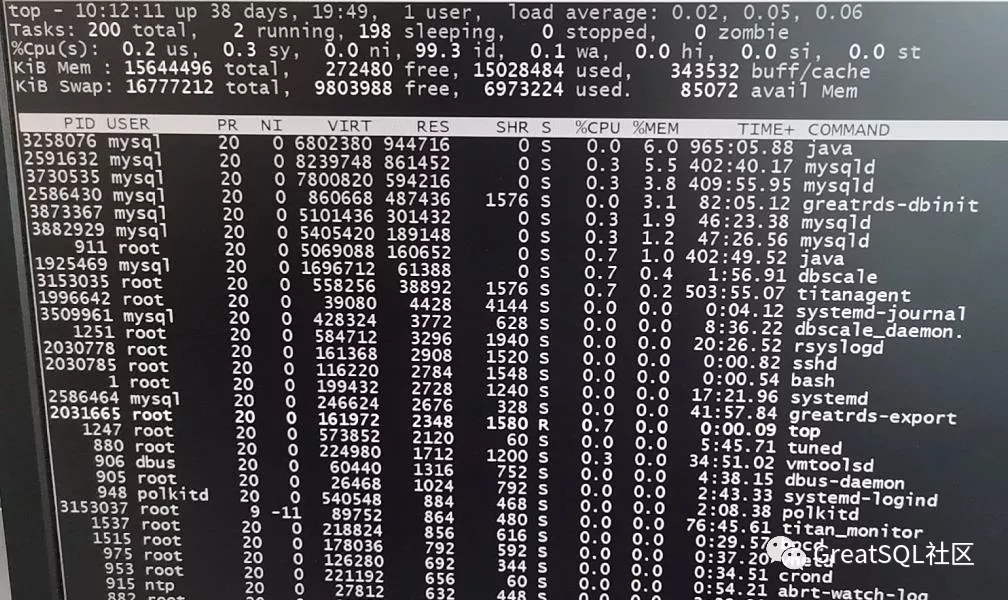
可以看到内存占用最多的是java进程和4个mysqld进程。
由于短期内无法加内存,java内存大小应用不让调整,那就只能想办法压缩mysqld使用的内存大小了。
这台服务器部署了4个 MySQL 实例,其中两个是轻量级应用,数据量非常少,但当时创建的时候配置文件使用的是相同的配置,所以先拿这两个开刀。
执行下面的命令查看当前innodb buffer pool值
mysql>show global variables like 'innodb_buffer_pool%';
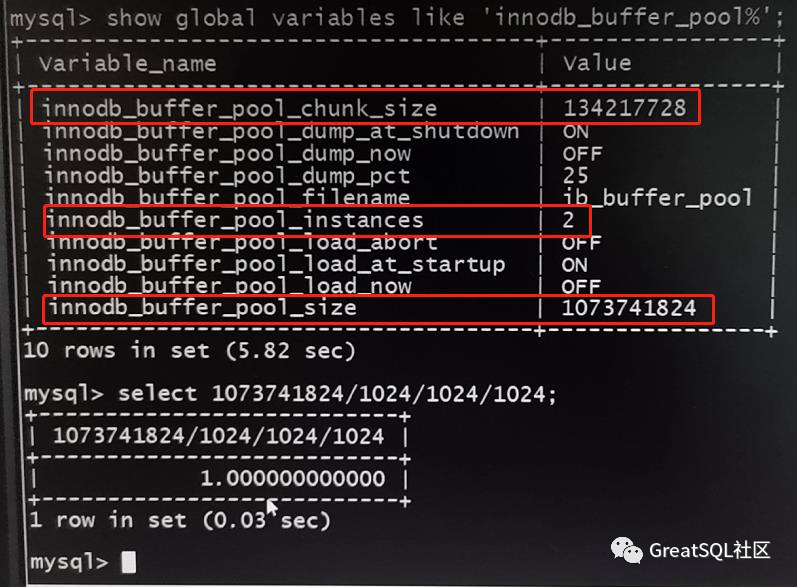
给分配1GB,并不算大(服务器内存16G),但这个实例里交易量和数据量都很小,先试试砍半吧。
从MySQL 5.7开始,innodb_buffer_pool_size必须等于innodb_buffer_pool_chunk_size *innodb_buffer_pool_instances的整数倍才行,详见官网说明(https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool-resize.html)。
mysql>set global innodb_buffer_pool_size=13421772822;
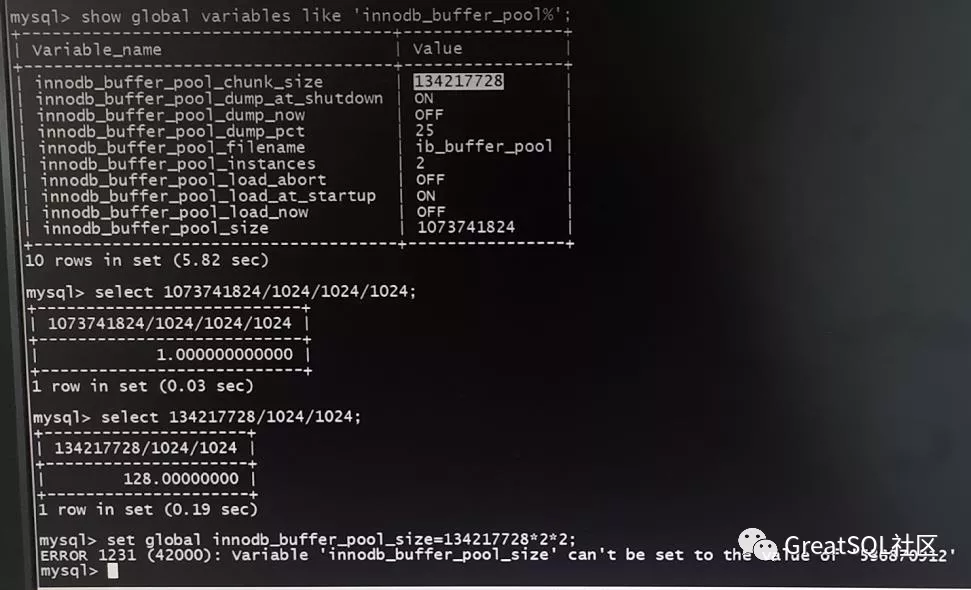
没想到,居然报错了!难道是BUG?试试调大innodb_buffer_pool_size
mysql>set global innodb_buffer_pool_size=13421772825;
调大不报错,正百思不得其解,经同事点播,可能是 innodb_buffer_pool_instances 的设置值导致的(官网描述 innodb_buffer_pool_instances 必须在 innodb_buffer_pool_size 大于等于 1G 时才生效),也就是说:
因为innodb_buffer_pool_instances 值为 2,因此 innodb_buffer_pool_size必须大于1GB。
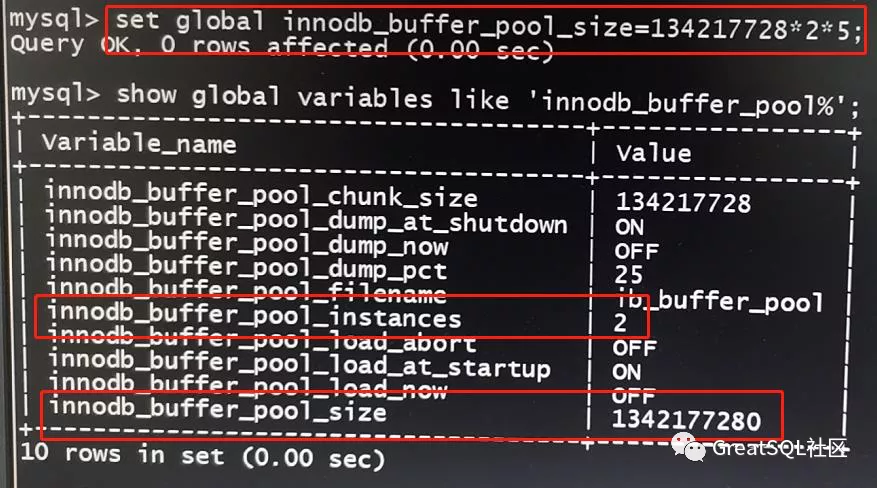
为印证猜测,将innodb_buffer_pool_instances改成1,修改配置文件后重启实例,查看innodb_buffer_pool相关变量值
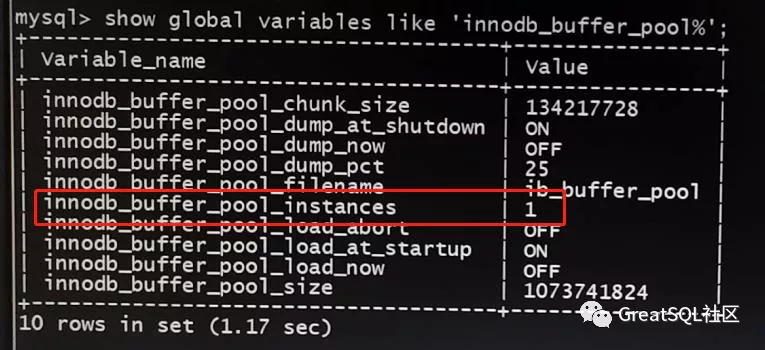
可以看到innodb_buffer_pool_instances已变成1,再次调低 innodb_buffer_pool_size
mysql>set global innodb_buffer_pool_size=13421772814;
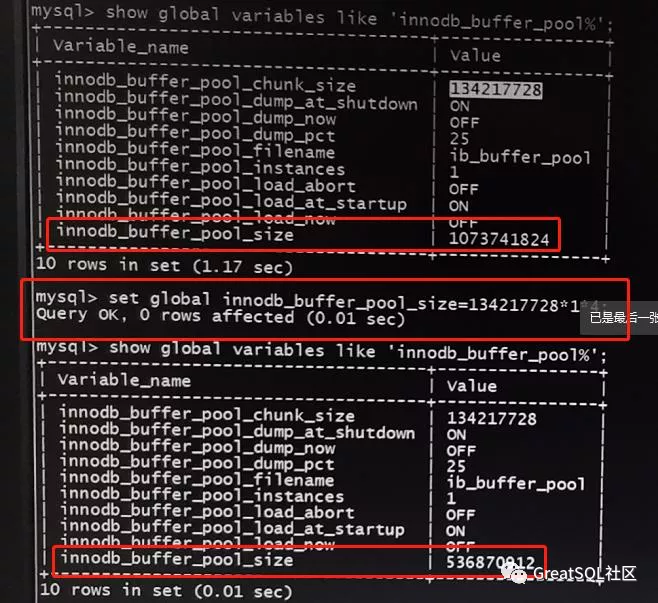
这次设置成功了,说明我们的猜测是正确的。
总结及建议
当 innodb_buffer_pool_size 值低于 1GB时,没必要也不能设置 innodb_buffer_pool_instances 值大于等于 2。
一般而言,当 innodb_buffer_pool_size 值不高于 8GB时,没必要设置 innodb_buffer_pool_instances 值大于 1。
通常,当 innodb_buffer_pool_size 较大时(大于64GB),innodb_buffer_pool_instances 设置为 8 是个比较合理的值。
Enjoy MySQL
文章推荐:
技术分享 | MGR最佳实践(MGR Best Practice)
https://mp.weixin.qq.com/s/66u5K7a9u8GcE2KPn4kCaA
技术分享 | 万里数据库MGR Bug修复之路
https://mp.weixin.qq.com/s/IavpeP93haOKVBt7eO8luQ
Macos系统编译percona及部分函数在Macos系统上运算差异
https://mp.weixin.qq.com/s/jAbwicbRc1nQ0f2cIa_2nQ
技术分享 | 利用systemd管理MySQL单机多实例
https://mp.weixin.qq.com/s/iJjXwd0z1a6isUJtuAAHtQ
产品 | GreatSQL,打造更好的MGR生态
https://mp.weixin.qq.com/s/ByAjPOwHIwEPFtwC5jA28Q
产品 | GreatSQL MGR优化参考
https://mp.weixin.qq.com/s/5mL_ERRIjpdOuONian8_Ow
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
Gitee:
https://gitee.com/GreatSQL/GreatSQL
GitHub:
https://github.com/GreatSQL/GreatSQL
微信&QQ群:
可扫码添加GreatSQL社区助手微信好友,发送验证信息“加群”加入GreatSQL/MGR交流微信群,亦可直接扫码加入GreatSQL/MGR交流QQ群。

本文由博客一文多发平台 OpenWrite 发布!
技术分享 | innodb_buffer_pool_size为什么无法调低至1GB以内的更多相关文章
- 恒天云技术分享系列3 – KVM性能调优
恒天云技术分享:http://www.hengtianyun.com/download-show-id-11.html KVM是什么 KVM 是 kernel-based Virtual Machin ...
- 阿里技术分享:阿里自研金融级数据库OceanBase的艰辛成长之路
本文原始内容由作者“阳振坤”整理发布于OceanBase技术公众号. 1.引言 OceanBase 是蚂蚁金服自研的分布式数据库,在其 9 年的发展历程里,从艰难上线到找不到业务场景濒临解散,最后在双 ...
- 腾讯技术分享:GIF动图技术详解及手机QQ动态表情压缩技术实践
本文来自腾讯前端开发工程师“ wendygogogo”的技术分享,作者自评:“在Web前端摸爬滚打的码农一枚,对技术充满热情的菜鸟,致力为手Q的建设添砖加瓦.” 1.GIF格式的历史 GIF ( Gr ...
- UWA 技术分享连载 转载
技术分享连载1 Q1:Texture占用内存总是双倍,这个是我们自己的问题,还是Unity引擎的机制? Q2:我现在发现两个因素直接影响Overhead,一个是Shader的复杂度,一个是空Updat ...
- 美团技术分享:深度解密美团的分布式ID生成算法
本文来自美团技术团队“照东”的分享,原题<Leaf——美团点评分布式ID生成系统>,收录时有勘误.修订并重新排版,感谢原作者的分享. 1.引言 鉴于IM系统中聊天消息ID生成算法和生成策略 ...
- 融云技术分享:解密融云IM产品的聊天消息ID生成策略
本文来自融云技术团队原创分享,原文发布于“融云全球互联网通信云”公众号,原题<如何实现分布式场景下唯一 ID 生成?>,即时通讯网收录时有部分改动. 1.引言 对于IM应用来说,消息ID( ...
- 老J的技术分享之总结
老J做IT这块有二十多个年头了,算是中国IT的见证者与参与者.那个时候刚开始接触和了解时,对于他的一些建议,我不是很乐于去接受,因为我觉得他的那一套技术体系不是很适合如今的情况,当时间久了后发现,他对 ...
- 技术分享 | Update更新慢、死锁等问题的排查思路分享
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 一.简介 在开始排错之前我们需要知道 Update 在 MySQL 中的生命周期 ...
- 网易视频云技术分享:linux软raid的bitmap分析
网易视频云是网易倾力打造的一款基于云计算的分布式多媒体处理集群和专业音视频技术,提供稳定流畅.低时延.高并发的视频直播.录制.存储.转码及点播等音视频的PAAS服务,在线教育.远程医疗.娱乐秀场.在线 ...
随机推荐
- VMWare中CentOS安装VM-Tools
查看CD-ROM驱动器的设备信息 可以通过下面几个命令来查看 dmesg命令 dmesg | egrep -i --color 'cdrom|dvd|cd/rw|writer' /proc/sys/d ...
- unity---脚本创建按钮
脚本创建按钮 新建文件夹 Resources 方便引用图片 在文件Resources中新建Images,并且下载一个图片 没有图片,按钮内容无法显示 图片需要处理一下 Textrue Type 改为 ...
- 设计并实现加法器类 Adder
学习内容:设计并实现加法器类 Adder 代码示例: package 实验三; import java.util.Scanner; public class Adder { private int n ...
- node-sass,sass-loader和node之间的关系
vue-cli运行在node平台上scss语言是运行在 node-sass平台上node-sass的运行环境是node平台vue-cli工程中不识别scss语法,.scss模块,sass-loader ...
- 1.3温度转换(中国大学Mooc-Python 语言程序设计)
温度转换 温度刻画的两种不同体系 1.摄氏度:(中国等世界大多数国家使用) 以1标准大气压下水的结冰点为0度,沸点为100度,将温度进行等分刻画 2.华氏度:(美国.英国等国家使用) 以1标准大气压 ...
- (数据科学学习手札137)orjson:Python中最好用的json库
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,我们在日常使用Pytho ...
- synchronized下的 i+=2 和 i++ i++执行结果居然不一样
起因 逛[博客园-博问]时发现了一段有意思的问题: 问题链接:https://q.cnblogs.com/q/140032/ 这段代码是这样的: import java.util.concurrent ...
- JS:Array
js有五种基本数据类型:string,number,boolean,null,undefined 一种引用类型,包括:1.Object类型:2.Function类型:3.Array类型:4.RegEx ...
- 左右手切换工具xmouse v1.2版本发布
Xmouse 方便的切换鼠标左右键,因为功能非常简单,所以支持.net framework 2.0及以上 windows环境就可以了,目前已测试win7.win10可用. 关于为什么做这么个东西,那是 ...
- 基于web3D展示技术的煤矿巷道3D可视化系统
地下开采离不开巷道工程.煤矿的生产.运输.排水.通风等各个环节都少不了巷道的支持.在煤矿智能化建设被提上日程的今天,巷道工程的智能化.可视化建设也成了行业趋势.尤其是复杂的井下作业环境,人员信息安全问 ...