我和Apache DolphinScheduler的缘分
关于 DolphinScheduler社区
Apache DolphinScheduler(incubator) 于17年在易观数科立项,19年3月开源, 19 年8月进入Apache 孵化器,社区发展非常迅速,目前已有IBM、美团、腾讯、360等 400+ 公司在生产上使用,代码+文档贡献者近200位,社区用户4000 +人。DolphinScheduler (简称DS) 致力于使大数据任务调度开箱即用,它以拖拉拽的可视化方式将各种任务间的关系组装成 DAG(有向无环图),并实时监控整个数据pipeline的运行状态,同时支持失败重试、重跑、恢复失败、补数等大数据常用操作
主人翁介绍
温合民,前创业公司技术合伙人,Apache DolphinScheduler Committer,8年互联网研发经验,现专注于大数据平台研发,深入参与开源社区建设

DolphinScheduler对于我来说,不仅是我们内部引入的一个项目,还是我职业生涯的引路人。
我和DolphinScheduler的缘分
就在2019年之前,我还是一名后端研发工程师,鲜有机会能接触到大数据,但是我一直对大数据有浓厚兴趣,由于我没有实践经验,所以一直也没有尝试从事大数据相关工作。19年我由于参与创业项目进展不顺利,退出后入职了一家新公司,可能面试时沟通不深入,误打误撞就进了一个搞数据分析的部门,工作职责主要是数据工具的研发,就这样,开启了我的大数据之旅。
从参与数据研发到现在,对我帮助最大、影响最大的就是我接触并在我们的数据平台中引入了DS,进而参与到开源。
最开始参与大数据平台建设时,我发现大数据平台中的大部分组件都已经发展成熟。只有大数据平台中的核心系统,大数据调度系统还没有深入人心的产品出现,这样的产品就像Spring之于后端、Vuejs之于前端、Hadoop之于大数据存储。我认为可能的原因是每个团队对调度系统的诉求不一样,比如:任务类型的多样化、系统的可扩展、系统的高可用、对非研发人员友好等,这就对大数据调度系统提出很高的要求,不仅要功能完备,还要便于二次开发,进行技术选型时也要非常谨慎。
我们在引入DS前,团队已经在使用kettle做ETL系统,随着任务越来越多,kettle的脚本管理越发混乱,对ETL系统功能的诉求也越来越多,团队决定替换ETL系统,我承担了技术选型的工作,开始在google、github寻找潜在的项目。
我们对ETL系统的核心需求:
- 任务管理:B/S架构,支持DAG
- 任务类型:支持sql(mysql、postgresql、hive)、shell、python、spark
- 任务编排:多任务按照串行、并行触发;条件触发任务
- 任务配置:变量注入、失败重跑、暂停、中断、手工触发
- 任务依赖:自动化处理ETL任务依赖关系
- 流控:并发、限流
- 监控:任务状态、结束通知、失败报警
- 权限:用户管理、权限管理
我通过调研选择了几个备选项目:DolphinScheduler、Azkaban、Airflow、Oozie
参考了当时EasyScheduler官网的横向对比
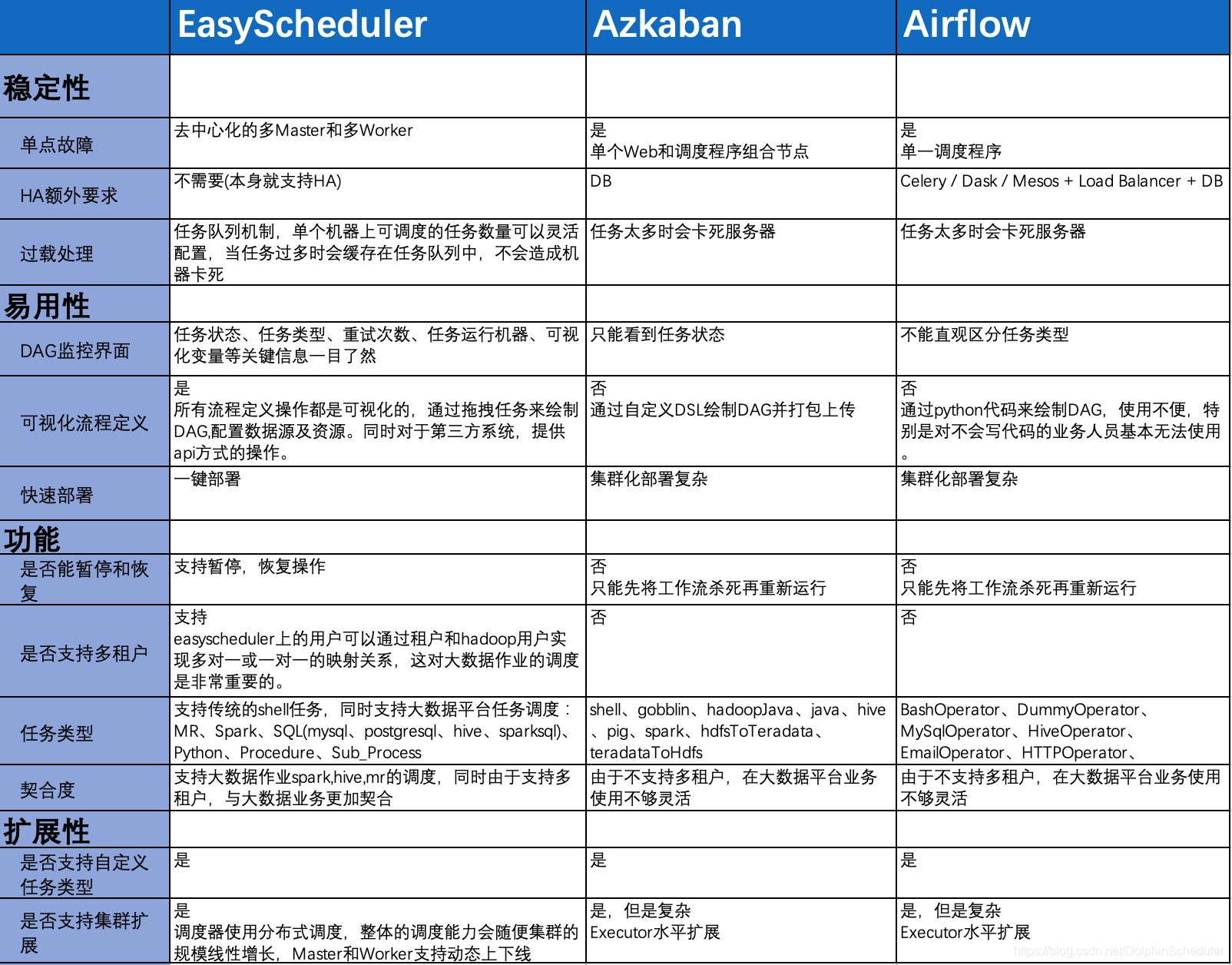
我在调研时做的对比图
| 需求点 | EasyScheduler | azkaban | oozie | elastic-job | XXL-Job |
|---|---|---|---|---|---|
| WEB UI | 支持 | 支持 | 支持 | 不支持 | 支持 |
| DAG | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 用户权限 | 支持 | 编码配置 | 支持 | 不支持 | 支持 |
| shell任务 | 支持 | 编码配置 | 编码配置 | 编码配置 | 支持 |
| python任务 | 支持 | 不支持 | 不支持 | 编码配置 | 支持 |
| sql任务 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 串行任务编排 | 支持 | 支持 | 未调研 | 未调研 | 支持 |
| 并行任务编排 | 支持 | 支持 | 未调研 | 未调研 | 不支持 |
| 条件任务编排 | 不支持 | 支持 | 未调研 | 未调研 | 不支持 |
| 变量注入 | 支持 | - | 未调研 | 未调研 | 支持 |
| 手工触发任务 | 支持 | 支持 | 未调研 | 未调研 | 支持 |
| 中断任务 | 支持 | 支持 | 未调研 | 未调研 | 支持 |
| 失败重跑 | 支持 | 支持 | 未调研 | 未调研 | 支持 |
| 状态监控 | 支持 | 支持 | 未调研 | 未调研 | 支持 |
| 资源监控 | 支持 | 不支持 | 未调研 | 未调研 | 不支持 |
| 通知可配置 | 支持 | 支持 | 未调研 | 未调研 | 支持 |
| 完成通知 | 支持 | 支持 | 未调研 | 未调研 | 不支持 |
| 失败通知 | 支持 | 支持 | 未调研 | 未调研 | 支持 |
| HA | 支持 | 支持 | 支持 | 支持 | 支持 |
| 插件机制 | 支持 | 支持 | 支持 | 支持 | 支持 |
| github star | 2.7K(调研时) | 2.9K | 525K | 5.4K | 10.7K |
表格中“未调研”是因为核心需求不满足,就没有花时间继续调研
调研DolphinScheduler的过程非常顺利,DS不仅提供了完善的用户文档,还有demo可以立即上手试一试,这点对用户非常友好,并且DS社区非常活跃,社区里藏龙卧虎。我是因为DS的功能吸引了我,也因为DS社区激发了我对开源的热情。
之前没有参与过开源项目,对开源知之甚少,在社区帮助下逐渐熟悉了开源贡献流程。我先从issue入手,通过回答issue中的问题去熟悉项目功能和源码,然后阅读源码的过程中可能会发现一些问题或bug,提交pr修复发现的问题,人生中第一个被合并的pr对我来说非常有成就感。因为我们内部基于DS做了二次开发,增强了DS的ETL能力,本着受益开源贡献开源的精神,将大家需要的功能提交给社区,通过努力也得到了社区认可,成为Apache Committer是我技术道路的一个里程碑。
参与开源让我有机会能和社区中的高手一起探讨问题,开源不仅打开了自己的视野,同时也提供了一条技术成长的路径。在感受开源魅力和强大的同时,我也非常感谢DS让我有幸能够参与其中。
最后希望DS茁壮成长,我也会伴随DS的成长,看着它每天进步,成为中国开源事业的重要一员。
Who’s using DolphinScheduler?
参与贡献
随着国内开源的崛起,DolphinScheduler迎来了蓬勃发展,为了做更好用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,青春在开源上留下一点印记
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度
社区汇总了以下适合新手的问题列表:https://github.com/apache/incubator-dolphinscheduler/issues/4124
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的
如果您想参与贡献,却发现上述方法都搞不明白,也没关系,我们有个开发者种子孵化群,可以添加微信(easyworkflow) 手把手教会您,添加时请说明想参与贡献哈
Apache DolphinScheduler开源社区非常期待您的参与
我和Apache DolphinScheduler的缘分的更多相关文章
- Apache DolphinScheduler(海豚调度) - 1.3 系列核心表结构剖析
Apache DolphinScheduler 是一个分布式去中心化,易扩展的可视化 DAG 工作流任务调度系统.致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用. 近日 ...
- 本周六 Apache DolphinScheduler & Doris 将联合线上 Meetup
活动背景 2020年,大数据成为国家基建的一个重要组成,大数据在越来越多的领域展现威力.随着大数据的应用场景越来越多,大家对数据的响应速度和数据加工工作流的方便程度也提出了更高的要求.在这种背景下,相 ...
- Apache DolphinScheduler新一代分布式工作流任务调度平台实战-上
概述 定义 dolphinscheduler 官网地址 https://dolphinscheduler.apache.org/ dolphinscheduler GitHub地址 https://g ...
- Apache DolphinScheduler 3.0.0 正式版发布!
点亮 ️ Star · 照亮开源之路 GitHub:https://github.com/apache/dolphinscheduler 版本发布 2022/8/10 2022 年 8 ...
- 日均 6000+ 实例,TB 级数据流量,Apache DolphinScheduler 如何做联通医疗大数据平台的“顶梁柱”?
作者 | 胡泽康 鄞乐炜 作者简介 胡泽康 联通(广东)产业互联网公司 大数据工程师,专注于开源大数据领域,从事大数据平台研发工作 鄞乐炜 联通(广东)产业互联网公司 大数据工程师,主要从事大数据平 ...
- 数据平台调度升级改造 | 从Azkaban 平滑过度到 Apache DolphinScheduler 的操作实践
Fordeal的数据平台调度系统之前是基于Azkaban进行二次开发的,但是在用户层面.技术层面都存在一些痛点问题难以被解决.比如在用户层面缺少任务可视化编辑界面.补数等必要功能,导致用户上手难体验差 ...
- 倒计时2日!基于 Apache DolphinScheduler&TiDB 的交叉开发实践,从编写到调度让你大幅提升效率
当大数据挖掘成为企业赖以生存.发展乃至转型的生命,如何找到一款好软件帮助企业满足需求,成为了许多大数据工程师困扰的问题.但在当下高速发展的大数据领域,光是一款好软件似乎都不足以满足所有场景业务需求,许 ...
- 感谢有你!Apache DolphinScheduler 项目 GitHub star 突破 8k
本周伊始,Apache DolphinScheduler 项目在 GitHub 上的 Github Star 总数首次突破 8K.目前,Apache DolphinScheduler 社区已经拥有 C ...
- 大数据平台迁移实践 | Apache DolphinScheduler 在当贝大数据环境中的应用
大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用. 本次演讲主要 ...
随机推荐
- Android 子线程 UI 操作真的不可以?
作者:vivo 互联网大前端团队- Zhang Xichen 一.背景及问题 某 SDK 有 PopupWindow 弹窗及动效,由于业务场景要求,对于 App 而言,SDK 的弹窗弹出时机具有随机性 ...
- [CSP-S 2019 Day2]Emiya家今天的饭
思路: 这种题目就考我们首先想到一个性质.这题其实容易想到:超限的菜最多只有一个,再加上这题有容斥那味,就枚举超限的菜然后dp就做完了. 推式子能力还是不行,要看题解. 式子还需要一个优化,就是废除冗 ...
- 论文阅读 Dynamic Network Embedding by Modeling Triadic Closure Process
3 Dynamic Network Embedding by Modeling Triadic Closure Process link:https://scholar.google.com.sg/s ...
- 官方出品,比 mydumper 更快的逻辑备份工具
mysqldump 和 mydumper 是我们常用的两个逻辑备份工具. 无论是 mysqldump 还是 mydumper 都是将备份数据通过 INSERT 的方式写入到备份文件中. 恢复时,myl ...
- 使用 Nocalhost 开发 Rainbond 上的微服务应用
本文将介绍如何使用 Nocalhost 快速开发 Rainbond 上的微服务应用的开发流程以及实践操作步骤. Nocalhost 可以直接在 Kubernetes 中开发应用,Rainbond 可以 ...
- Maven笔记---超详细
显眼位置标注来源:此文章为B站课程黑马程序员Maven全套教程笔记,由本人整理. Maven简介 Maven的本质是一个项目管理工具,将项目开发和管理过程抽象成一个项目对象模型(POM) POM (P ...
- 腾讯QQ快捷登陆
腾讯QQ快捷 相关各语言对接qq快捷登录教程 [C#]QQ开放平台(QQ站外登录)_流程和源码示例 j2ee中实现QQ第三方登陆 web实现QQ第三方登录 asp.net网站接入QQ登录 php实现q ...
- springboot available: expected at least 1 bean which qualifies as autowire candidate奇葩问题
Exception encountered during context initialization - cancelling refresh attempt: org.springframewor ...
- 基于.NetCore开发博客项目 StarBlog - (12) Razor页面动态编译
系列文章 基于.NetCore开发博客项目 StarBlog - (1) 为什么需要自己写一个博客? 基于.NetCore开发博客项目 StarBlog - (2) 环境准备和创建项目 基于.NetC ...
- 关于各种Vue UI框架中加载进度条的正确使用
这里拿MUSE UI 中的进度条举例 <mu-circular-progress :size="40" class="icon" v-if="i ...