2.10:数据加工与展示-pandas清洗、Matplotlib绘制
〇、目标
1、 使用pandas完成基本的数据清洗加工处理;
2、 使用Matplotlib进行简单的数据图形化展示。
一、用pandas清洗处理数据
1、判断是否存在空值


数据缺失在很多数据中存在,是首先要解决的常见问题。NaN(Not a Number)在NumPy中是浮点值,易检测。而Python的None关键字在数组中也被作为NaN处理。需要注意的是,Python本身并没有定义NaN,而numpy中定义了NaN。因此使用的使用,要明确使用np.NaN。None是在Python中定义的,可以直接使用。Pandas提供isnull和notnull两个方法来判断Series对象或DataFrame对象中是否存在空值。其输出结果是一个有True和False组成的bool类型的Series对象或DataFrame对象。
2、过滤空值
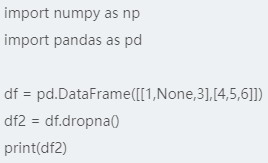

Series过滤空值时,直接过滤掉空值所在的数据和对应的索引。DataFrame过滤空值时,dropna()默认会删除包含缺失值的行,传入how=‘all’参数时,删除所有值均为NaN的行;传入axis=1,可以按照同样的方式删除列。注意在生成DataFrame时,None默认被标记为float,所以对应的列中,整数5也被转化成5.0。另外,dropna方法返回一个新的DataFrame对象,原来的DataFrame对象不变。
3、补全空值
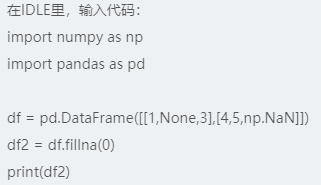

Dropna()简单粗暴,抛弃了其他非空数据,因此可以采取补全数据的方式,如fillna()。补全时,可以使用常数补全,如fillna(0);或者用字典补全,即为不同的列设置不同的填充值,字典的键就是列的索引名,如fillna({1:0.5, 2:0})。需要注意的是,默认fillna()返回一个新的对象。如果需要在原对象上修改数据,可设定inplace=True修改原对象,如df.fillna(0, inplace=True)。空值补全时可能会污染数据,比如错误的补全值。一般可以使用插值方法来填充,如前向填充:fillna(method=“ffile”, limit=2),或者将Series的平均值或中位数填充NaN,如data.fillna(data.mean())。
4、删除重复值

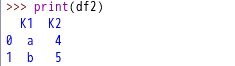
由于各种原因,DataFrame中会出现重复的行。可以使用DataFrame的duplicated()用于判断某行是否重复,返回一个Series对象,由True和False构成。可以使用drop_duplicates()直接返回不重复的值,还可以指定特定列,如:drop_duplicates([‘K1’])。
5、检测和过滤异常值

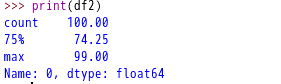
异常值(outlier)指的是在正常情况下,不可能产生的数值,比如在正常的水温测试过程中,水温在100摄氏度一下,人的年龄一般在120岁以内,大于零岁。异常值的过滤或变换运算在很大程度上其实就是数组运算。DataFrame的describe方法可以返回该DataFrame对象的数据进行统计信息展示。比如最大最小值,均值等。我们假定超过50的数据为异常值,可以通过使用any方法选出全部满足条件的行,比如any(1)表示一行中有1个数据满足即可进行过滤。
6、数据排序


Sort_index()在指定轴上对索引排序,默认升序,默认0轴(行)。Sort_values()在指定轴上根据数值进行排序,默认升序。如果排序的DataFrame中存在NaN数据,则排序末尾(最大或最小)。此外,Pandas还提供了一个更简单的取前n行最大值的函数:Nlargest(),使用方法为:df.nlargest(3,'A'),即取A列中最大的前3行数据。
7、空值替换

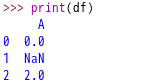
使用fillna填充空值是通用值替换的特殊例子。对于不同的数据源,对空值的标识可能不同,如有的使用-999标识空值。如果需要对这些非标准空值进行NaN替换,可以使用replace方法。可以替换单值:Df.replace( -999,np.NaN, inplace = True)或列表:Df.replace( [-999, -1000], np.NaN)或列表对:Df.replace( [-999, -1000], [np.NaN,0])或字典:Df.replace( {-999: np.NaN, -1000:0})。df的iloc方法,可以接收行号和列号进行选取。如果df.iloc[3][4]表示第三行,第四列。如果使用loc方法,则需要使用行号和列名,如df.loc[3][“A”]。
二、Matplotlib展示数据
1、使用plot函数绘制曲线

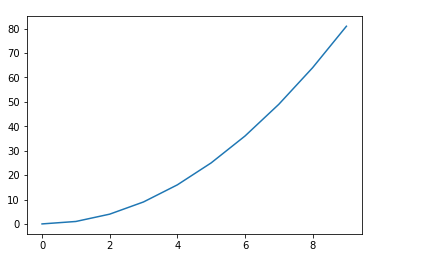
Matplotlib用于在python环境下进行Matlab风格的绘图,使用时主要使用其接口库pyplot,使用前先导入:import matplotlib.pyplot as plt。普通的曲线使用plot函数即可完成,plot函数的参数角度。但大多有默认参数。只需要输入x和y轴的数据即可绘制出一条默认风格曲线图。
2、使用控制字符串

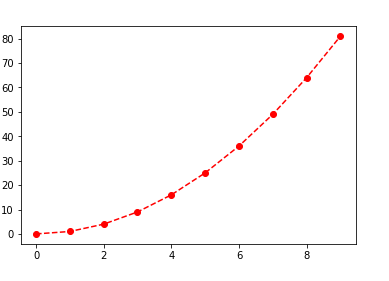
控制字符依次包括:颜色字符、风格字符和标记字符。其中,颜色字符:r、g、b等,或 数字格式'#008080';风格字符:- 、-- 、-.、 |(实线、虚线、点画线等);标记字符:.、,、v、<、>等;也可以使用显式表达,如color=“g”,linestyle=“dashed”,marker =“o”等。
3、图形中的文本

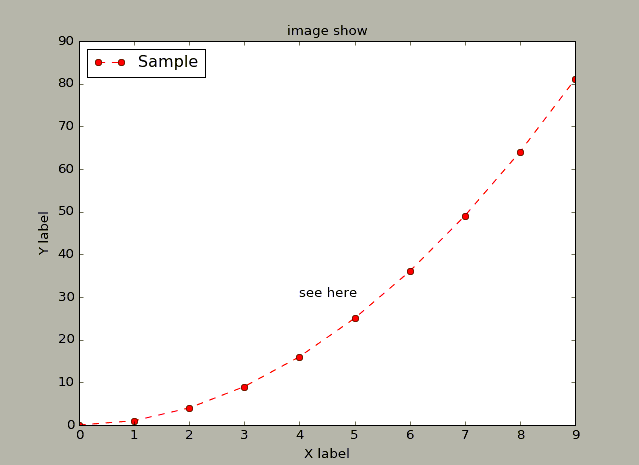
在Matplotlib中有丰富的图形文本设置,如:设置标题title(),图例标注label,X轴标注xlabel(),Y轴标:ylabel(),文本信息text()等。默认情况下,不能显示汉字,如果需要显示汉字,可设置fontproperties参数,指定使用的字体即可。
4、多线绘制

通过查看plot的函数原型,可以发现:plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs),其中x轴数据可省略,而y轴数据不可省略。如果不设定多线的格式控制,系统自动区分。除了设置多个y轴数据,plot函数还可以直接接受多维数组。
5、多子图绘制1

使用subplot函数,可以把多个子图绘制在一起。其原型为:plt.subplot(rows, cols, number),需要指定行列和当前正在绘制的编号,编号从左到右,从上到下,行优先。如plt.subplot(2,2,1)表示绘制2行2列的多子图,当前绘制位置是第1,subplot(2,2,4)则表示第四个位置(从上到下,都左到右)。
6、多子图绘制2
subplots函数可以生成一个画布和多个子图。其原型为:fig,ax = subplots(nrows, ncols, sharex, sharey, squeeze, subplot_kw, gridspec_kw, **fig_kw) 。 nrows和ncols表示将画布分割成几行几列 例:nrows = 2,ncols = 2表示将画布分割为2行2列,并起始值都为0,当调用画布中的坐标轴时,ax[0,0]表示调用坐上角的,ax[1,1]表示调用右下角的;sharex和sharey表示坐标轴的属性是否相同,可选的参数:True,False,row,col,默认值均为False,表示画布中的四个ax是相互独立的;当sharex = True, sharey = True时,生成的四个ax的所有坐标轴用有相同的属性;简单起见,直接使用二维索引的方式来获得指定的子图,并直接使用子图的plot方法进行绘制,如ax[0][0].plot(…),在一个2行2列的画布上的第一个子图中绘制。
7、不同的绘图风格

pie函数用于绘制饼图。饼图常用的设置属性包括:x,(每一块)的比例,如果sum(x) > 1会使用sum(x)归一化;labels :(每一块)饼图外侧显示的说明文字;explode :(每一块)离开中心距离;startangle :起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起;shadow :在饼图下面画一个阴影。默认值:False,即不画阴影;labeldistance :label标记的绘制位置,相对于半径的比例,默认值为1.1, 如<1则绘制在饼图内侧;autopct :控制饼图内百分比设置,可以使用format字符串或者format function'%1.1f'指小数点前后位数(没有用空格补齐)。其他设置参数,请参阅使用手册。
2.10:数据加工与展示-pandas清洗、Matplotlib绘制的更多相关文章
- 用Python的Pandas和Matplotlib绘制股票KDJ指标线
我最近出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中给出了MACD,KDJ ...
- 用Python的Pandas和Matplotlib绘制股票唐奇安通道,布林带通道和鳄鱼组线
我最近出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中给出了MACD,KDJ ...
- Pandas与Matplotlib结合进行可视化
前面所介绍的都是以表格的形式中展现数据, 下面将介绍Pandas与Matplotlib配合绘制出折线图, 散点图, 饼图, 柱形图, 直方图等五大基本图形. Matplotlib是python中的一个 ...
- [数据清洗]- Pandas 清洗“脏”数据(三)
预览数据 这次我们使用 Artworks.csv ,我们选取 100 行数据来完成本次内容.具体步骤: 导入 Pandas 读取 csv 数据到 DataFrame(要确保数据已经下载到指定路径) D ...
- [数据清洗]- Pandas 清洗“脏”数据(二)
概要 了解数据 分析数据问题 清洗数据 整合代码 了解数据 在处理任何数据之前,我们的第一任务是理解数据以及数据是干什么用的.我们尝试去理解数据的列/行.记录.数据格式.语义错误.缺失的条目以及错误的 ...
- [数据清洗]-使用 Pandas 清洗“脏”数据
概要 准备工作 检查数据 处理缺失数据 添加默认值 删除不完整的行 删除不完整的列 规范化数据类型 必要的转换 重命名列名 保存结果 更多资源 Pandas 是 Python 中很流行的类库,使用它可 ...
- [数据清洗]-Pandas 清洗“脏”数据(一)
概要 准备工作 检查数据 处理缺失数据 添加默认值 删除不完整的行 删除不完整的列 规范化数据类型 必要的转换 重命名列名 保存结果 更多资源 Pandas 是 Python 中很流行的类库,使用它可 ...
- 微信小程序结合后台数据管理实现商品数据的动态展示、维护
微信小程序给我们提供了一个很好的开发平台,可以用于展现各种数据和实现丰富的功能,本篇随笔介绍微信小程序结合后台数据管理实现商品数据的动态展示.维护,介绍如何实现商品数据在后台管理系统中的维护管理,并通 ...
- python处理数据的风骚操作[pandas 之 groupby&agg]
https://segmentfault.com/a/1190000012394176 介绍 每隔一段时间我都会去学习.回顾一下python中的新函数.新操作.这对于你后面的工作是有一定好处的.本文重 ...
- 【SpringBoot】转载 springboot使用thymeleaf完成数据的页面展示
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/weixin_36380516/artic ...
随机推荐
- 使用Watchtower实现Docker容器自动更新
前言:通常情况下我们手动更新容器的步骤比较繁琐,需要四个步骤: 1.停止容器 2.删除容器 3.检查镜像更新情况,更新镜像 4.重新启动容器 容器少还无所谓,但要是需要更新大量的容器就会工作量巨大. ...
- kibana配置文件kibana.yml参数详解
server.port: 默认值: 5601 Kibana 由后端服务器提供服务,该配置指定使用的端口号. server.host: 默认值: "localhost" 指定后端服务 ...
- ProxySQL SQL 注入引擎
ProxySQL 2.0.9 引入了 libsqlinjection 作为识别可能的 SQL 注入攻击的机制. 启用 SQL 注入检测 要启用 SQL 注入检测,只需要启用变量 mysql-aut ...
- nginx配置文件内容详解
events { # 服务器最大链接数 worker_connections 1024; # 设置一个进程是否同时接受多个网络连接,默认为off multi_accept on; #事件驱动模型,se ...
- prometheus设置使用密码nginx反向代理访问
注意: 1.设置访问密码的方式 2.ngixn反向代理的配置 # 安装 Apache工具包 apt install apache2-utils htpasswd -bc /etc/nginx/.pro ...
- 初试 Prometheus + Grafana 监控系统搭建并监控 Mysql
转载自:https://cloud.tencent.com/developer/article/1433280 文章目录1.Prometheus & Grafana 介绍1.1.Prometh ...
- HashMap底层原理及jdk1.8源码解读
一.前言 写在前面:小编码字收集资料花了一天的时间整理出来,对你有帮助一键三连走一波哈,谢谢啦!! HashMap在我们日常开发中可谓经常遇到,HashMap 源码和底层原理在现在面试中是必问的.所以 ...
- Python-函数-字符串函数
函数 1.字符串函数 #(1)add() 对两个数组的元素进行字符串连接 import numpy as np print(np.char.add(["xiaodu"],[&quo ...
- OpenDataV低代码平台增加自定义属性编辑
上一篇我们讲到了怎么在OpenDataV中添加自己的组件,为了让大家更快的上手我们的平台,这一次针对自定义属性编辑,我们再来加一篇说明.我们先来看一下OpenDataV中的属性编辑功能. 当我们拖动一 ...
- Docker Private Registry
Docker Private Registry 目录 Docker Private Registry Docker Registry Docker Private Registry 使用docker- ...