Warmup小记
什么是warmup
热身,在刚刚开始训练时以很小的学习率进行训练,使得网络熟悉数据,随着训练的进行学习率慢慢变大,到了一定程度,以设置的初始学习率进行训练,接着过了一些inter后,学习率再慢慢变小;
学习率变化:上升——平稳——下降
为什么用warmup
- 有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
- 有助于保持模型深层的稳定性
可以认为,刚开始模型对数据的“分布”理解为零,或者是说“均匀分布”(当然这取决于你的初始化);在第一轮训练的时候,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。当训练了一段时间(比如两轮、三轮)后,模型已经对每个数据点看过几遍了,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型学偏,所以可以适当调大学习率。这个过程就可以看做是warmup。
当模型训到一定阶段后(比如十个epoch),模型的分布就已经比较固定了,或者说能学到的新东西就比较少了。如果还沿用较大的学习率,就会破坏这种稳定性,用我们通常的话说,就是已经接近loss的local optimal了,为了靠近这个point,我们就要慢慢来。
这里只摘录了一小段,参考文献 [1] 解释的很好。
learning rate schedule
warmup和learning schedule是类似的,只是学习率变化不同。如图
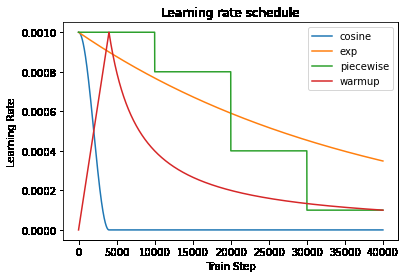
learning rate schedule
tensorflow 中有几种不同的learning rate schedule,以上图的3种为例,更多schedule可以直达官网
# CosineDecay
cosine_learning_rate_schedule = tf.keras.optimizers.schedules.CosineDecay(0.001,4000)
plt.plot(cosine_learning_rate_schedule(tf.range(40000, dtype=tf.float32)),label="cosine")
# ExponentialDecay
exp_learning_rate_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
0.001, 4000, 0.9, staircase=False, name=None
)
plt.plot(exp_learning_rate_schedule(tf.range(40000, dtype=tf.float32)),label="exp")
# PiecewiseConstantDecay
boundaries = [10000, 20000,30000]
values = [0.001, 0.0008, 0.0004,0.0001]
piecewise_learning_rate_schedule = tf.keras.optimizers.schedules.PiecewiseConstantDecay(
boundaries, values)
plt.plot([piecewise_learning_rate_schedule(step) for step in tf.range(40000, dtype=tf.float32)],label="piecewise")
# 自定义 Schedule
my_learning_rate_schedule = MySchedule(0.001)
plt.plot([my_learning_rate_schedule(step) for step in tf.range(40000, dtype=tf.float32)],label="warmup")
plt.title("Learning rate schedule")
plt.ylabel("Learning Rate")
plt.xlabel("Train Step")
plt.legend()
# 自定义 Schedule
class MySchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, initial_learning_rate, warmup_steps=4000):
super(MySchedule, self).__init__()
self.initial_learning_rate = initial_learning_rate
self.warmup_steps = warmup_steps
def __call__(self, step):
if step > self.warmup_steps:
return self.initial_learning_rate * self.warmup_steps * step ** -1
else:
return self.initial_learning_rate * step * (self.warmup_steps ** -1)
warmup in transformer
Noam Optimizer
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps ** -1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)
learning_rate = CustomSchedule(d_model)
optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98,
epsilon=1e-9)
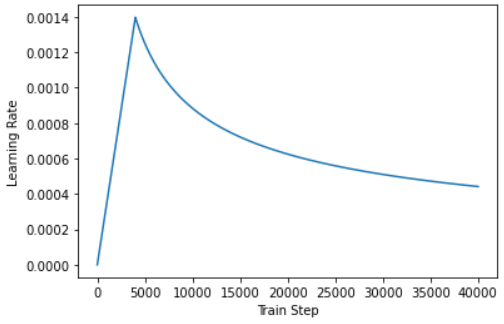
temp_learning_rate_schedule = CustomSchedule(128)
plt.plot(temp_learning_rate_schedule(tf.range(40000, dtype=tf.float32)))
plt.ylabel("Learning Rate")
plt.xlabel("Train Step")
关于warmup参数
一般可取训练steps的10%,参考BERT。这里可以根据具体任务进行调整,主要需要通过warmup来使得学习率可以适应不同的训练集合,另外我们也可以通过训练误差观察loss抖动的关键位置,找出合适的学习率。[4]
references
【1】神经网络中 warmup 策略为什么有效;有什么理论解释么? - 香侬科技的回答 - 知乎 https://www.zhihu.com/question/338066667/answer/771252708
【2】tf官方文档 tf.keras.optimizers.schedules. https://www.tensorflow.org/versions/r2.6/api_docs/python/tf/keras/optimizers/schedules
【3】理解语言的 Transformer 模型. https://www.tensorflow.org/tutorials/text/transformer#优化器(optimizer)
【4】聊一聊学习率预热linear warmup. https://cloud.tencent.com/developer/article/1929850
Warmup小记的更多相关文章
- [原]Paste.deploy 与 WSGI, keystone 小记
Paste.deploy 与 WSGI, keystone 小记 名词解释: Paste.deploy 是一个WSGI工具包,用于更方便的管理WSGI应用, 可以通过配置文件,将WSGI应用加载起来. ...
- MySql 小记
MySql 简单 小记 以备查看 1.sql概述 1.什么是sql? 2.sql发展过程? 3.sql标准与方言的关系? 4.常用数据库? 5.MySql数据库安装? 2.关键概念 表结构----- ...
- Git小记
Git简~介 Git是一个分布式版本控制系统,其他的版本控制系统我只用过SVN,但用的时间不长.大家都知道,分布式的好处多多,而且分布式已经包含了集中式的几乎所有功能.Linus创造Git的传奇经历就 ...
- 广州PostgreSQL用户会技术交流会小记 2015-9-19
广州PostgreSQL用户会技术交流会小记 2015-9-19 今天去了广州PostgreSQL用户会组织的技术交流会 分别有两个session 第一个讲师介绍了他公司使用PostgreSQL-X2 ...
- 东哥读书小记 之 《MacTalk人生元编程》
一直以来的自我感觉:自己是个记性偏弱的人.反正从小读书就喜欢做笔记(可自己的字写得巨丑无比,尼玛不科学呀),抄书这事儿真的就常发生俺的身上. 因为那时经常要背诵课文之类,反正为了怕自己忘记, ...
- Paypal支付小记
Paypal支付小记 *:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !impo ...
- IIS 7.5 Application Warm-Up Module
http://www.cnblogs.com/shanyou/archive/2010/12/21/1913199.html 有些web应用在可以处理用户访问之前,需要装载很多的数据,或做一些花费很大 ...
- linux 下cmake 编译 ,调用,调试 poco 1.6.0 小记
上篇文章 小记了: 关于 Poco::TCPServer框架 (windows 下使用的是 select模型) 学习笔记. http://www.cnblogs.com/bleachli/p/4352 ...
- mongodb入门学习小记
Mongodb 简单入门(个人学习小记) 1.安装并注册成服务:(示例) E:\DevTools\mongodb3.2.6\bin>mongod.exe --bind_ip 127.0.0.1 ...
随机推荐
- java反射获取类的成员函数,成员变量,构造函数
package com.imooc.reflect;import javax.sound.midi.Soundbank;import java.lang.reflect.Constructor;imp ...
- ubuntu21.10搭建jenkins和gitlab自动化部署环境
镜像下载.域名解析.时间同步请点击阿里云开源镜像站 前置环境: vmware pro 16 + ubuntu21.10 安装gitlab 搭建ssh远程 打开终端 sudo apt-get insta ...
- ssh编译安装后重启失败问题
编译好的ssh重启出现如下报错 这个原因是因为systemd与ssh不兼容造成的 删掉服务 rm /usr/lib/systemd/system/sshd.service 重启 /etc/init.d ...
- [SPDK/NVMe存储技术分析]008 - RDMA概述
毫无疑问地,用来取代iSCSI/iSER(iSCSI Extensions for RDMA)技术的NVMe over Fabrics着实让RDMA又火了一把.在介绍NVMe over Fabrics ...
- 利用MSSQL getshell
此次复现使用的sql server 2000 和sql server 2008两个环境进行的 是在已知数据库密码的基础上进行的 0x01 MSSQL连接 连接MSSQL 2000 新建连接: 填写目的 ...
- 知识点简单总结——FWT(快速沃尔什变换),FST(快速子集变换)
知识点简单总结--FWT(快速沃尔什变换),FST(快速子集变换) 闲话 博客园的markdown也太傻逼了吧. 快速沃尔什变换 位运算卷积 形如 $ f[ i ] = \sum\limits_{ j ...
- buu equation wp
知识点考察:jsfuck解码.js逆向.z3处理大量数据 源码分析 源码 根据提示猜测有jsfuck Jsfuck编码共六个字符分别为[.].+.!.(.) 观察上述不难发现l['jsfuck']=' ...
- XStream类的对象将javaBean转成XML
[省市联动] servlet端: //返回数据xml(XStream) XStream xStream = new XStream(); //把路径设置别名 xStream.alias("c ...
- Tomcat启动时shell窗口乱码解决方法
tomcat/conf/目录下,修改logging.properties java.util.logging.ConsoleHandler.encoding = utf-8 更改为 java.util ...
- mybatis学习一:基于xml与注解配置入门实例与问题
注:本case参考自:http://www.cnblogs.com/ysocean/p/7277545.html 一:Mybatis的介绍: MyBatis 本是apache的一个开源项目iBatis ...