GNN 101
GNN 101
Why
Graph无处不在

Graph Intelligence helps
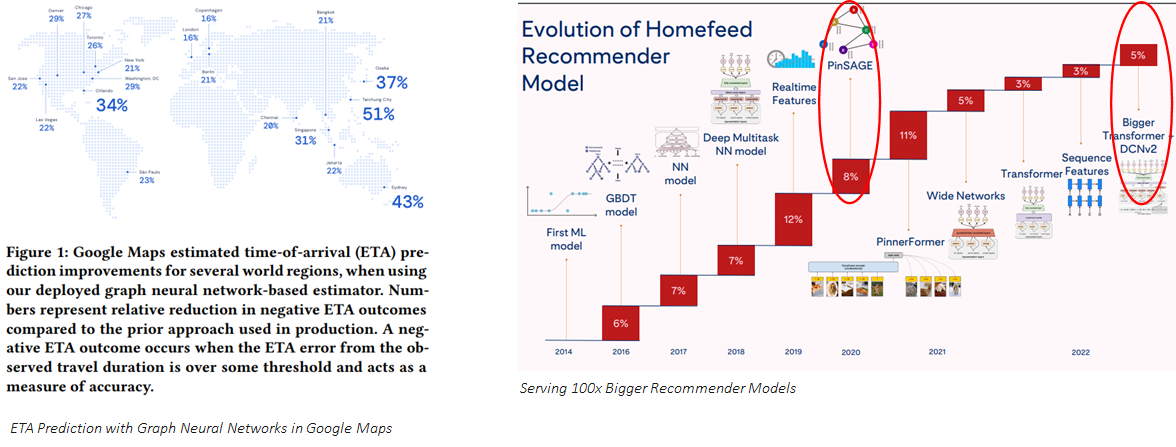
It’s the right time now!
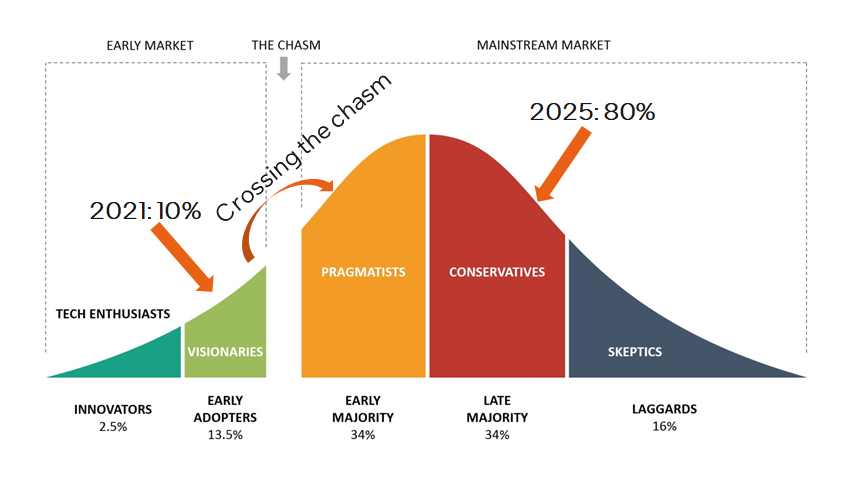
Gartner预测,graph技术在数据和分析创新中的使用率从2021年的10%,到2025年会增长到80%。我们目前正在经历从early adoption到early mainstream的穿越大峡谷期间,既不太早也不太晚,时间刚刚好。
What
如何建模图
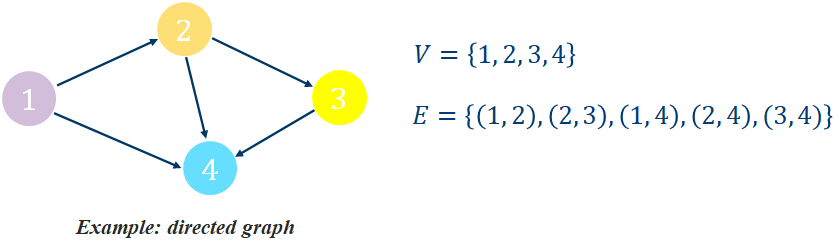
A graph is an ordered pair = (, ) comprising:
, a set of vertices (or nodes)
⊆{(,)|,∈}, a set of edges (or links), which are pairs of nodes
Example:
Different Types of Graph
Are edges directed?
Directed Graph vs. Undirected GraphAre there multiple types of nodes or multiple types of edges?
Homogeneous Graph vs Heterogeneous Graph
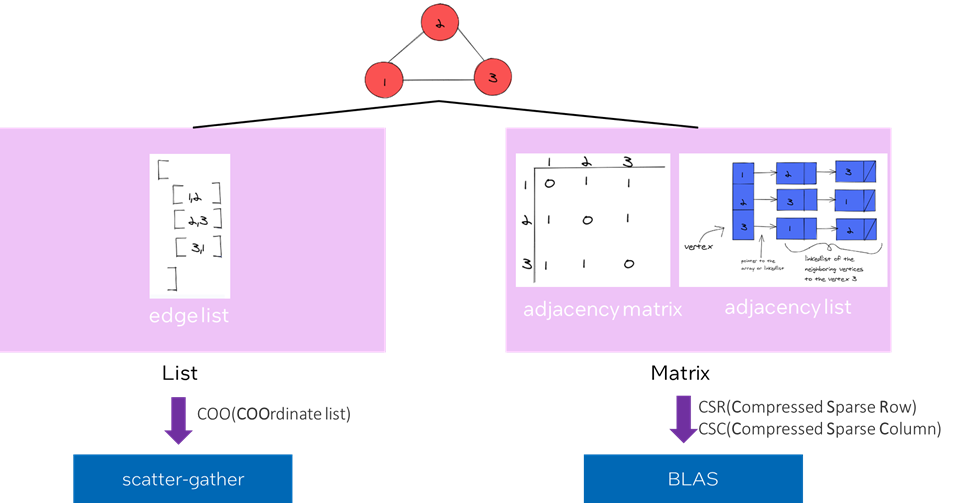
如何表示图
不同的表示方式会指向不同的计算模式。
如何计算图
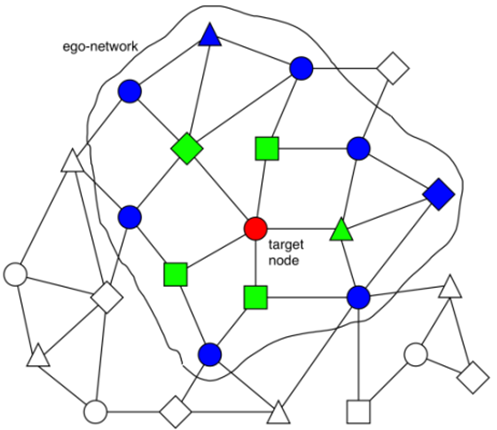
如下图所示,图的计算步骤如下:
遍历图中的所有结点,或者采样图中的一些结点。每次选择其中一个结点,称为目标结点(target node);
一个-层的GNN至少需要聚合目标结点的L-跳领域的信息。因此,我们需要以围绕目标结点构造一个L-跳的ego network。图中是一个2-跳ego network的例子,其中绿色结点是第1跳,蓝色结点是第2跳;
计算并更新ego-network里的每个结点的embedding。embeddings会使用到图的结构信息和结点与边的特征。
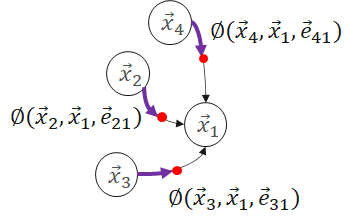
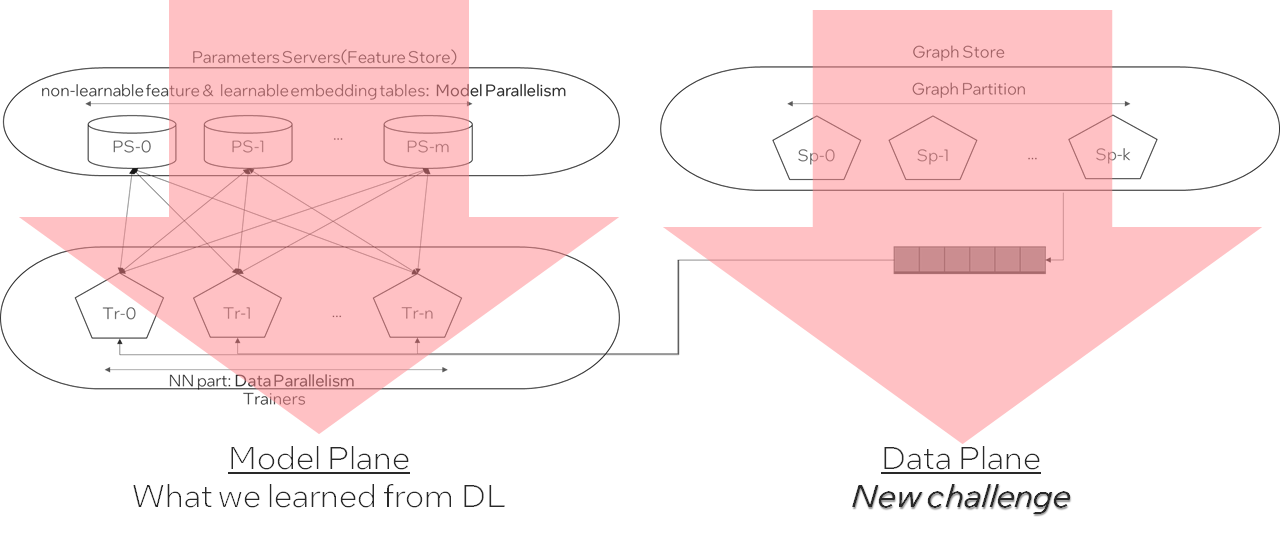
那么,这些embedding是如何计算和更新的呢?主要是使用Message Passing的计算方法。Message Passing有一些计算范式如GAS(Gather-ApplyEdge-Scatter), SAGA(Scatter-ApplyEdge-Gather-ApplyVertex)等。我们这里介绍归纳得比较全面的SAGA计算范式。假设需要计算和更新下图中的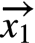 :
:
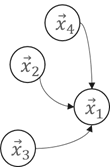
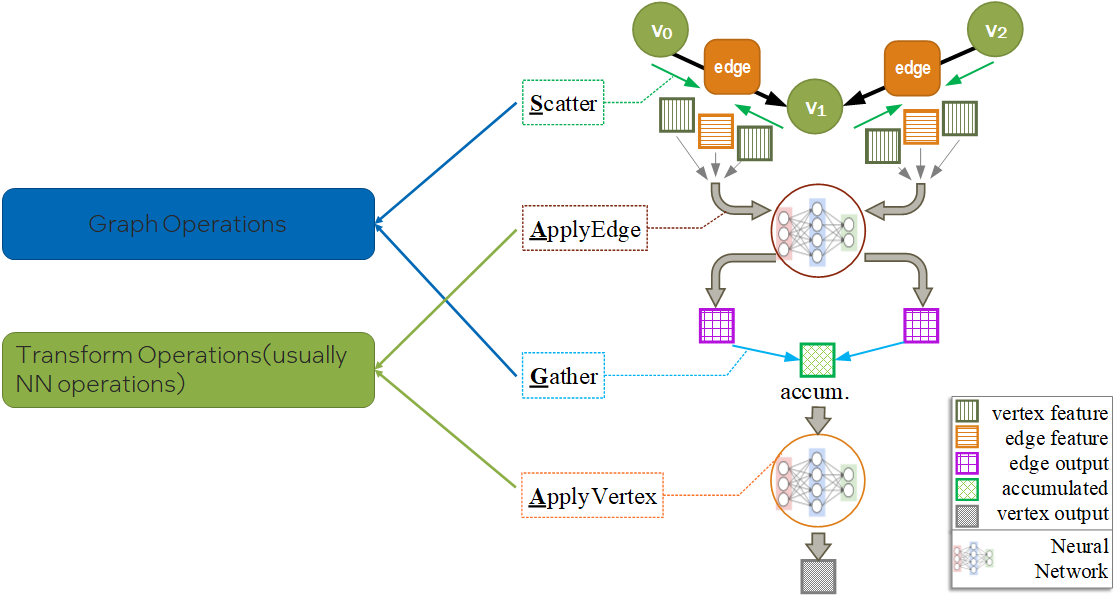
Scatter
Propagate message from source vertex to edge.
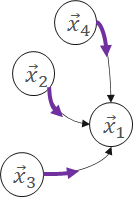
ApplyEdge
Transform message along each edge.
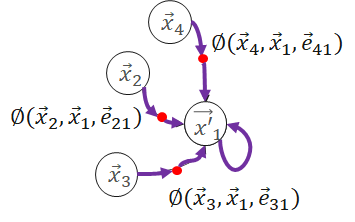
Gather
Gather transformed message to the destination vertex.
ApplyVertex
Transform the gathered output to get updated vertex.
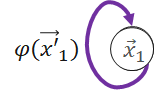
公式如下:

分析一下,会发现,SAGA模式中ApplyEdge和ApplyVertex是传统deep learning中的NN(Neural Network)操作,我们可以复用;而Scatter和Gather是GNN新引入的操作。即,Graph Computing = Graph Ops + NN Ops。
不同的图数据集规模
One big graph
可能高达数十亿的结点,数百亿的边。
Many small graphs
不同的图任务
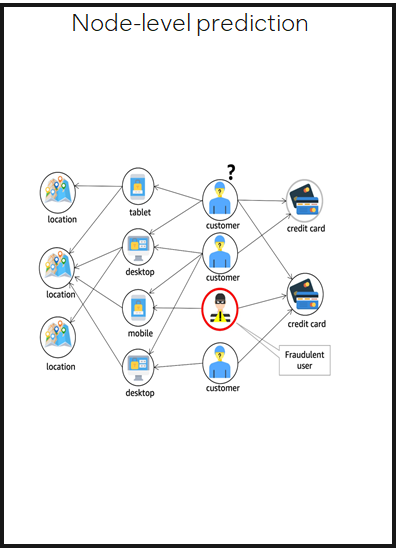
Node-level prediction
预测图中结点的类别或性质
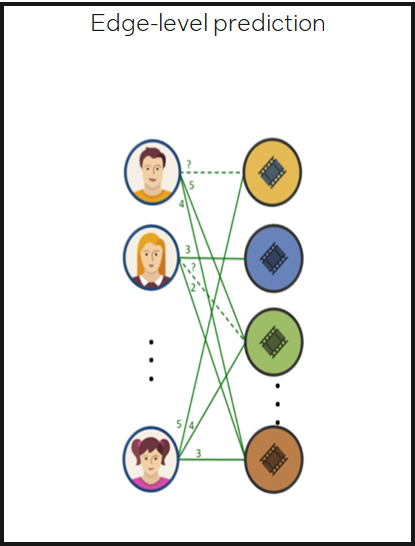
Edge-level prediction
预测图中两个结点是否存在边,以及边的类别或性质
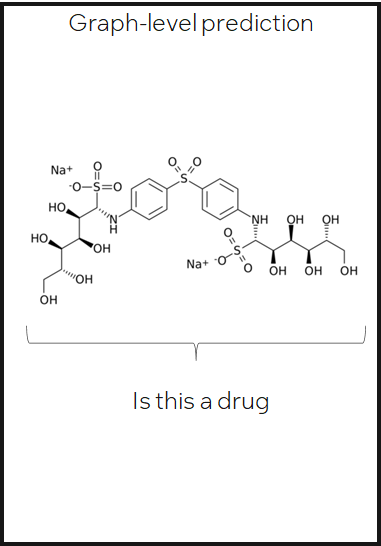
Graph-level prediction
预测整图或子图的类别或性质
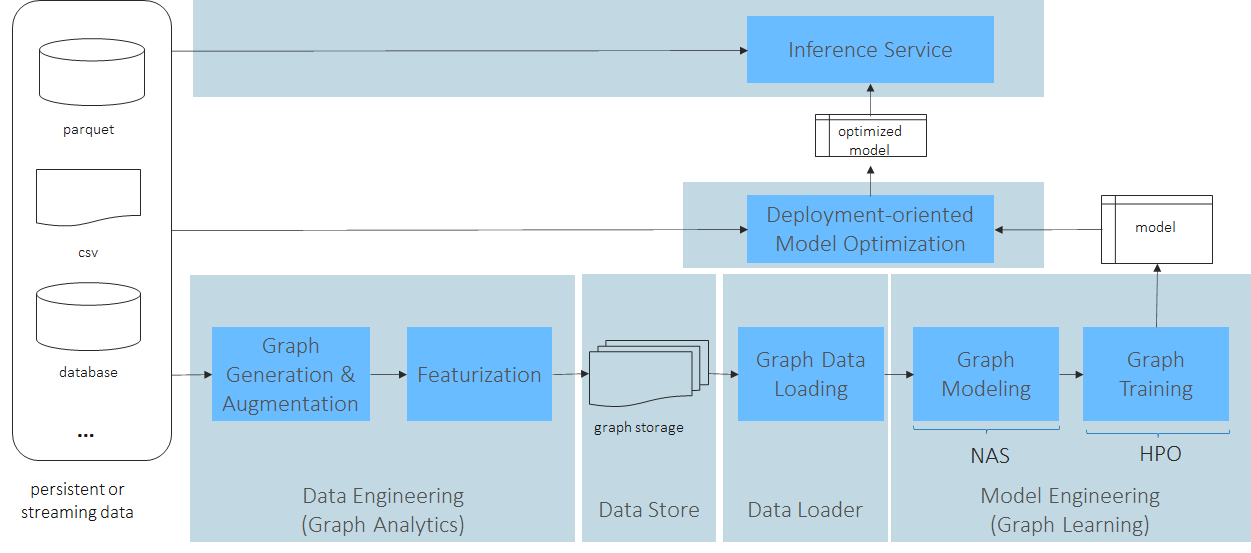
How
Workflow
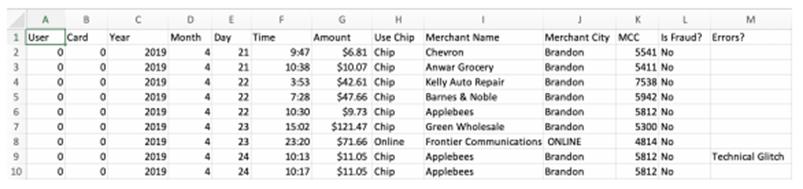
以fraud detection为例:
Tabformer数据集
workflow
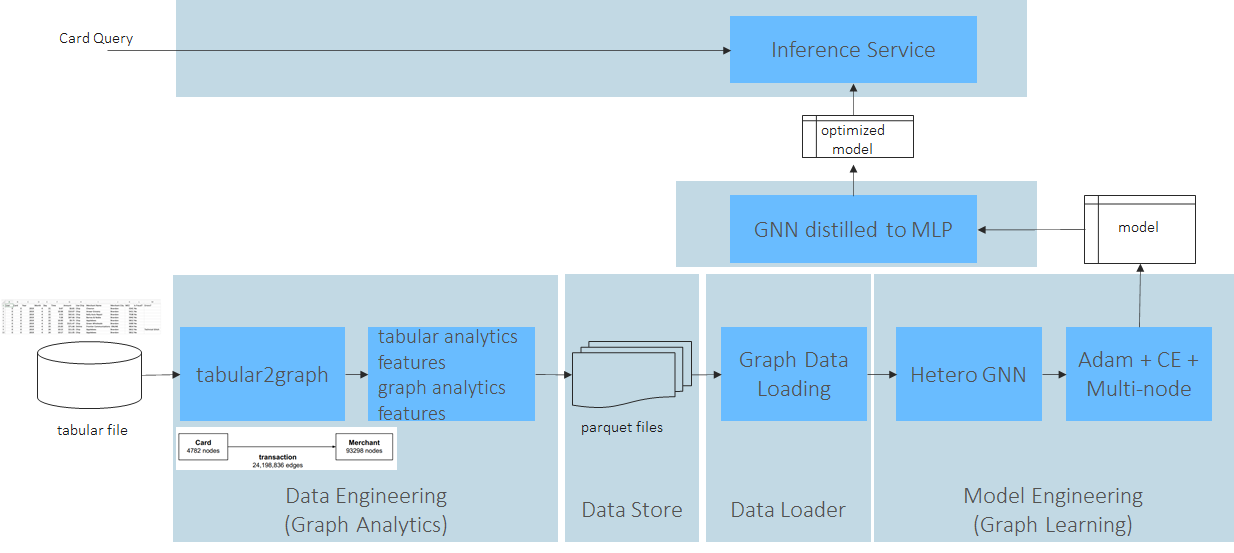
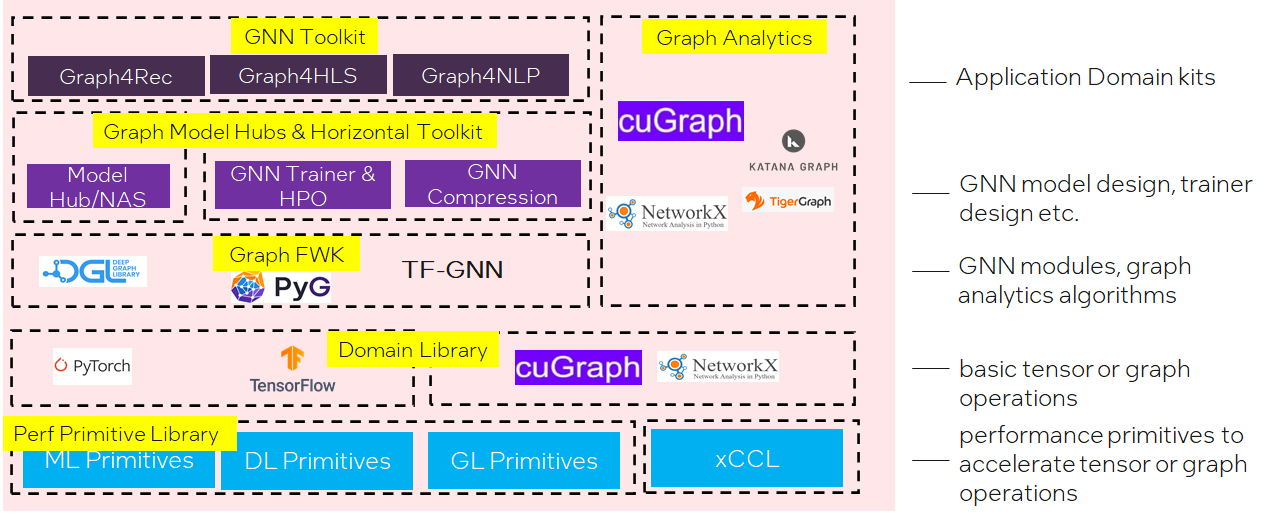
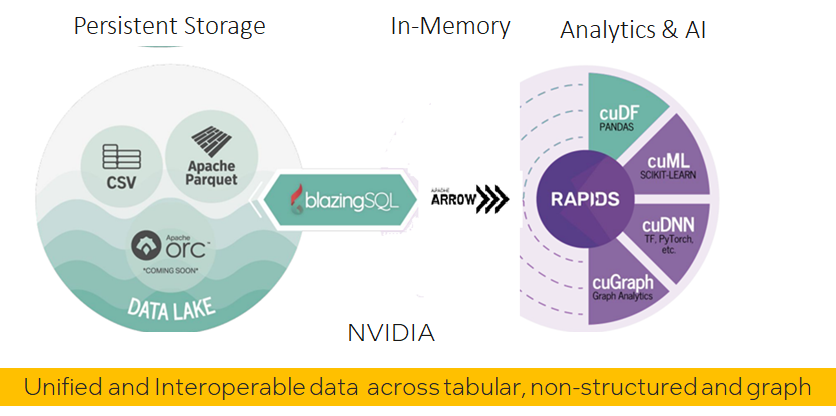
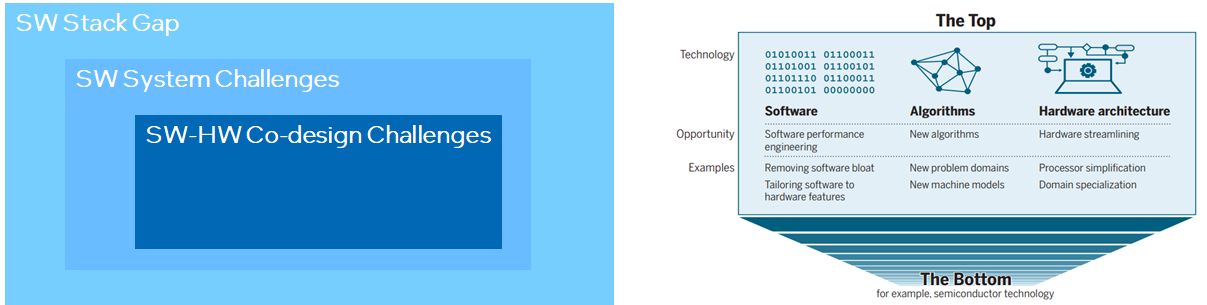
软件栈
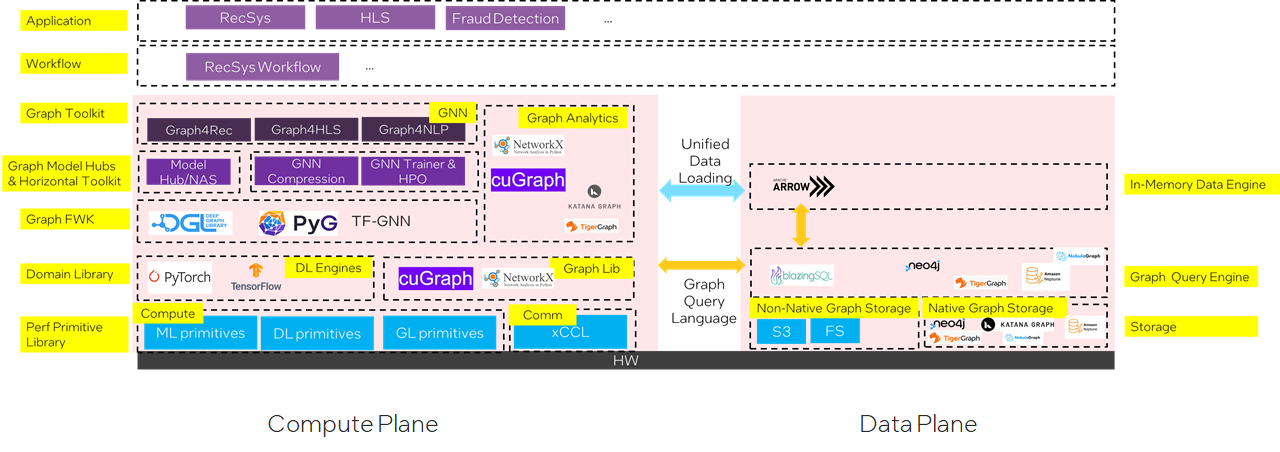
计算平面
数据平面
SW Challenges
Graph Sampler
For many small graphs datasets, full batch training works most time. Full batch training means we can do training on whole graph;
When it comes to one large graph datasets, in many real scenarios, we meet Neighbor Explosion problem;
Neighbor Explosion:
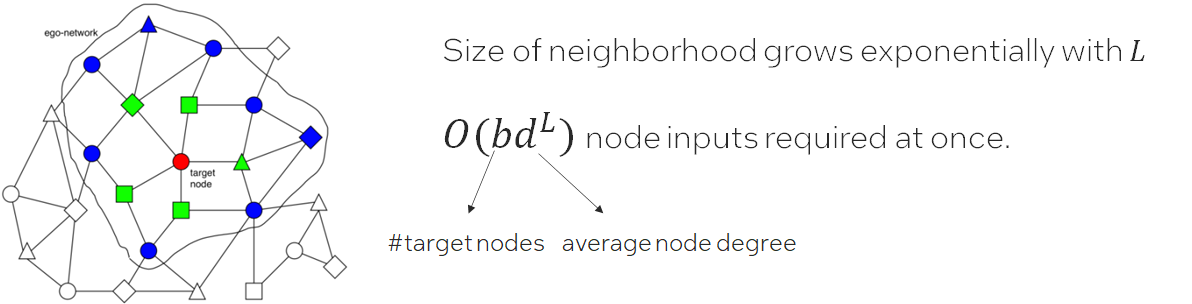
Graph sampler comes to rescue. Only sample a fraction of target nodes, and furthermore, for each target node, we sample a sub-graph of its ego-network for training. This is called mini-batch training.
Graph sampling is triggered for each data loading. And the hops of the sampled graph equals the GNN layer number . Which means graph sampler in data loader is important in GNN training.

Challenge: How to optimize sampler both as standalone and in training pipe?
When graph comes to huge(billions of nodes, tens of billions of edges), we meet new at-scale challenges:
How to store the huge graph across node? -> graph partition
How to build a training system w/ not only distributed model computing but also distributed graph store and sampling?
How to cut the graph while minimize cross partition connections?
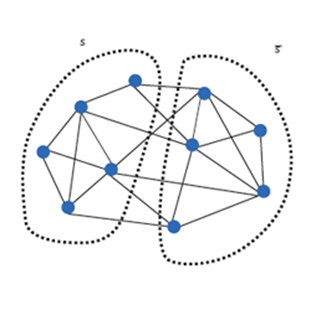
A possible GNN distributed training architecture:
Scatter-Gather
Fuse adjacent graphs ops
One common fuse pattern for GCN & GraphSAGE:
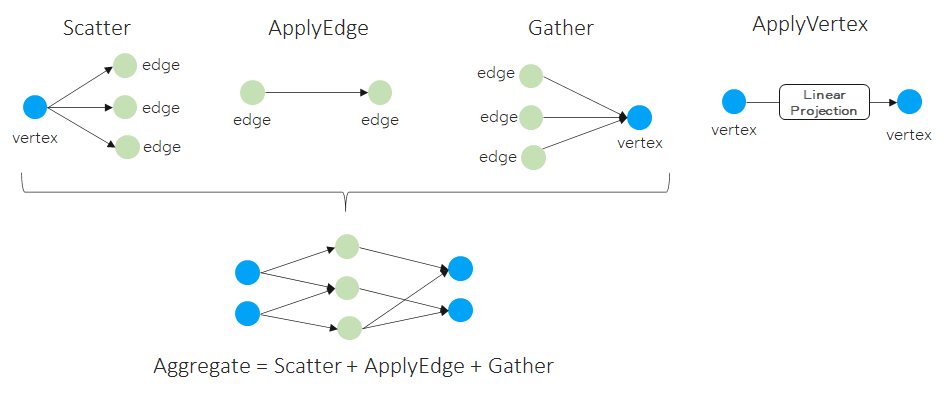
Challenge:
How to fuse more GNN patterns on different ApplyEdge and ApplyVertex,automatically?How to implement fused Aggregate
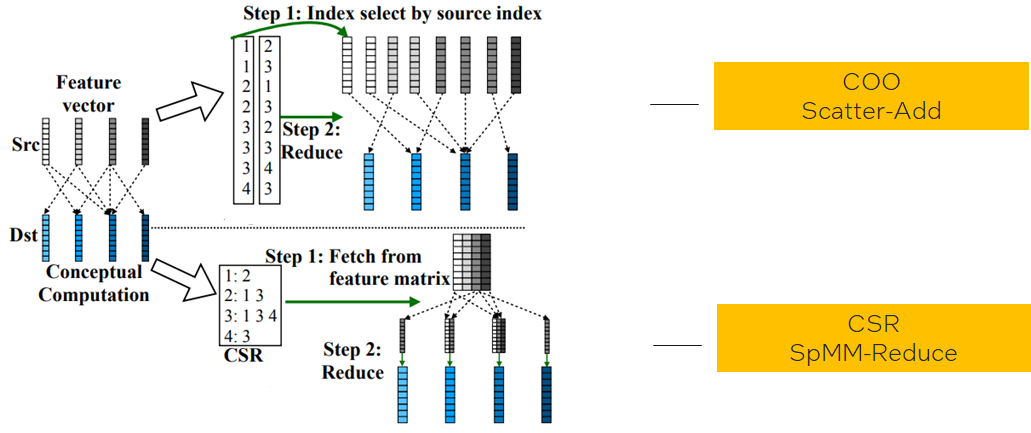
Challenge:Different graph data structures lead to different implementations in same logic operations;
Different graph characteristics favors different data structures;(like low-degree graphs favor COO, high-degree graphs favor CSR)
How to find the applicable zone for each and hide such complexity to data scientists?
More
Inference challenge
GNN inference needs full batch inference, how to make it efficient?
Distributed inference for big graph?
Vector quantization for node and edge features?
GNN distilled to MLP?
SW-HW co-design challenge
How to relief irregular memory access in scatter-gather?
Do we need some data flow engine for acceleration?
…
Finishing words
“There is plenty of room at the top” 对技术人员很重要。但为避免入宝山而空返,我们更需要建立起技术架构,这就像是地图一样,只有按图索骥才能更好地探索和利用好top里的plenty of room。
References
Graph + AI: What’s Next? Progress in Democratizing Graph for All
Recent Advances in Efficient and Scalable Graph Neural Networks
Understanding and Bridging the Gaps in Current GNN Performance Optimizations
Understanding GNN Computational Graph: A Coordinated Computation, IO, And Memory Perspective
fuseGNN: Accelerating Graph Convolutional Neural Network Training on GPGPU
VQ-GNN: A Universal Framework to Scale up Graph Neural Networks using Vector Quantization
NeuGraph: Parallel Deep Neural Network Computation on Large Graphs
Completing a member knowledge graph with Graph Neural Networks
PinnerFormer: Sequence Modeling for User Representation at Pinterest
GNN 101的更多相关文章
- 了解 ARDUINO 101* 平台
原文链接 简介 作为一名物联网 (IoT) 开发人员,您需要根据项目的不同需求,选择最适合的平台来构建应用. 了解不同平台的功能至关重要. 本文第一部分比较了 Arduino 101 平台和 Ardu ...
- Entity Framework 6 Recipes 2nd Edition(10-1)译->非Code Frist方式返回一个实体集合
存储过程 存储过程一直存在于任何一种关系型数据库中,如微软的SQL Server.存储过程是包含在数据库中的一些代码,通常为数据执行一些操作,它能为数据密集型计算提高性能,也能执行一些为业务逻辑. 当 ...
- 虚拟 router 原理分析- 每天5分钟玩转 OpenStack(101)
上一节我们创建了虚拟路由器"router_100_101",并通过 ping 验证了 vlan100 和 vlan101 已经连通. 本节将重点分析其中的原理. 首先我们查看控制节 ...
- VS:101 Visual Studio 2010 Tips
101 Visual Studio 2010 Tips Tip #1 How to not accidentally copy a blank line TO – Text Editor ...
- 【Mocha.js 101】钩子函数
前情提要 在上一篇文章<[Mocha.js 101]同步.异步与 Promise>中,我们学会了如何对同步方法.异步回调方法以及 Promise 进行测试. 在本篇文章中,我们将了解到 M ...
- 【Mocha.js 101】同步、异步与 Promise
前情提要 在上一篇文章<[Mocha.js 101]Mocha 入门指南>中,我们提到了如何用 Mocha.js 进行前端自动化测试,并做了几个简单的例子来体验 Mocha.js 给我们带 ...
- [nginx] connect() failed (111: Connection refused) while connecting to upstream, client: 101.18.123.107, server: localhost,
nginx一直报错, 2016/12/02 10:23:19 [error] 1472#0: *31 connect() failed (111: Connection refused)while c ...
- 学习 Linux,101: Linux 命令行
概述 本教程将简要介绍 bash shell 的一些主要特性,涵盖以下主题: 使用命令行与 shell 和命令交互 使用有效的命令和命令序列 定义.修改.引用和导出环境变量 访问命令历史和编辑工具 调 ...
- UVa 101 The Blocks Problem Vector基本操作
UVa 101 The Blocks Problem 一道纯模拟题 The Problem The problem is to parse a series of commands that inst ...
随机推荐
- C++ 运行单个实例,防止程序多次启动
利用内核对象 封装的类,使用运行单个实例,防止多次启动Demo 例子下载地址:http://pan.baidu.com/share/link?shareid=3202369154&uk=303 ...
- Windows API 学习
Windows API学习 以下都是我个人一些理解,笔者不太了解windows开发,如有错误请告知,非常感谢,一切以microsoft官方文档为准. https://docs.microsoft.co ...
- springboot拦截器总结
Springboot 拦截器总结 拦截器大体分为两类 : handlerInterceptor 和 methodInterceptor 而methodInterceptor 又有XML 配置方法 和A ...
- 【SQLServer】max worker threads参数配置
查看和设置max worker threads USE master; //选中你想设置max worker threads的数据库.master表示在实例级别进行设置 GO EXEC sp_conf ...
- Visual Studio 2022 Community 不完全攻略
0. 前言 建议结合视频阅读哦 Visual Studio 2022 Community 不完全攻略 有问题或者意见欢迎评论 ! 1. 下载&安装 Visual Studio Communit ...
- IEEE浮点数向偶数舍
CSAPP 向偶数舍入初看上去好像是个相当随意的目标--有什么理由偏向取偶数呢?为什么不始终把位于两个可表示的值中间的值都向上舍入呢?使用这种方法的一个问题就是很容易假想到这样的情景:这种方法舍入 ...
- kubeadm init 命令执行流程
- 在 WPF 中实现融合效果
1. 融合效果 融合效果是指对两个接近的元素进行高斯模糊后再提高对比度,使它们看上去"粘"在一起.在之前的一篇文章中,我使用 Win2D 实现了融合效果,效果如下: 不过 Win2 ...
- [题解] Codeforces 1349 D Slime and Biscuits 概率,推式子,DP,解方程
题目 神题.很多东西都不知道是怎么凑出来的,随意设置几个变量,之间就产生了密切的关系.下次碰到这种题应该还是不会做罢. 令\(E_x\)为最后结束时所有的饼干都在第x个人手中的概率*时间的和.\(an ...
- gin项目部署到服务器并后台启动
前言 我们写好的gin项目想要部署在服务器上,我们应该怎么做呢,接下来我会详细的讲解一下部署教程. 1.首先我们要有一台虚拟机,虚拟机上安装好go框架. 2.将写好的项目上传到虚拟机上. 3.下载好项 ...