Neural Network模型复杂度之Dropout - Python实现
背景介绍
Neural Network之模型复杂度主要取决于优化参数个数与参数变化范围. 优化参数个数可手动调节, 参数变化范围可通过正则化技术加以限制. 本文从优化参数个数出发, 以dropout技术为例, 简要演示dropout参数丢弃比例对Neural Network模型复杂度的影响.算法特征
①. 训练阶段以概率丢弃数据点; ②. 测试阶段保留所有数据点算法推导
以概率\(p\)对数据点\(x\)进行如下变换,\[\begin{equation*}
x' = \left\{\begin{split}
&0 &\quad\text{with probability $p$,} \\
&\frac{x}{1-p} &\quad\text{otherwise,}
\end{split}\right.
\end{equation*}
\]即数据点\(x\)以概率\(p\)置零, 以概率\(1-p\)放大\(1/(1-p)\)倍. 此时有,
\[\begin{equation*}
\mathbf{E}[x'] = p\mathbf{E}[0] + (1-p)\mathbf{E}[\frac{x}{1-p}] = \mathbf{E}[x],
\end{equation*}
\]此变换不改变数据点均值, 为无偏变换.
若数据点\(x\)作为某线性变换之输入, 将其置零, 则对此线性变换无贡献, 等效于无效化该数据点及相关权重参数, 减少了优化参数个数, 降低了模型复杂度.数据、模型与损失函数
数据生成策略如下,\[\begin{equation*}
\left\{\begin{aligned}
x &= r + 2g + 3b \\
y &= r^2 + 2g^2 + 3b^2 \\
lv &= -3r - 4g - 5b
\end{aligned}\right.
\end{equation*}
\]Neural Network网络模型如下,
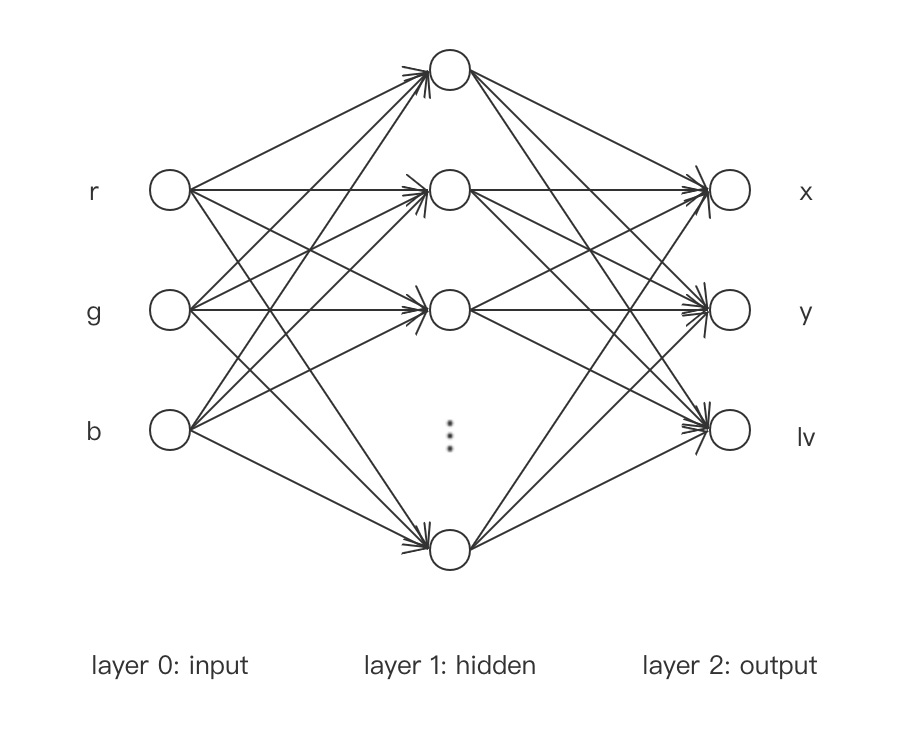
其中, 输入层为$(r, g, b)$, 隐藏层取激活函数$\tanh$, 输出层为$(x, y, lv)$且不取激活函数.
损失函数如下,
$$
\begin{equation*}
L = \sum_i\frac{1}{2}(\bar{x}^{(i)}-x^{(i)})^2+\frac{1}{2}(\bar{y}^{(i)}-y^{(i)})^2+\frac{1}{2}(\bar{lv}^{(i)}-lv^{(i)})^2
\end{equation*}
$$
其中, $i$为data序号, $(\bar{x}, \bar{y}, \bar{lv})$为相应观测值.代码实现
本文拟将中间隐藏层节点数设置为300, 使模型具备较高复杂度. 后逐步提升置零概率\(p\), 使模型复杂度降低, 以此观察泛化误差的变化. 具体实现如下,code
import numpy
import torch
from torch import nn
from torch import optim
from torch.utils import data
from matplotlib import pyplot as plt # 获取数据与封装数据
def xFunc(r, g, b):
x = r + 2 * g + 3 * b
return x def yFunc(r, g, b):
y = r ** 2 + 2 * g ** 2 + 3 * b ** 2
return y def lvFunc(r, g, b):
lv = -3 * r - 4 * g - 5 * b
return lv class GeneDataset(data.Dataset): def __init__(self, rRange=[-1, 1], gRange=[-1, 1], bRange=[-1, 1], num=100, transform=None,\
target_transform=None):
self.__rRange = rRange
self.__gRange = gRange
self.__bRange = bRange
self.__num = num
self.__transform = transform
self.__target_transform = transform self.__X = self.__build_X()
self.__Y_ = self.__build_Y_() def __build_X(self):
rArr = numpy.random.uniform(*self.__rRange, (self.__num, 1))
gArr = numpy.random.uniform(*self.__gRange, (self.__num, 1))
bArr = numpy.random.uniform(*self.__bRange, (self.__num, 1))
X = numpy.hstack((rArr, gArr, bArr))
return X def __build_Y_(self):
rArr = self.__X[:, 0:1]
gArr = self.__X[:, 1:2]
bArr = self.__X[:, 2:3]
xArr = xFunc(rArr, gArr, bArr)
yArr = yFunc(rArr, gArr, bArr)
lvArr = lvFunc(rArr, gArr, bArr)
Y_ = numpy.hstack((xArr, yArr, lvArr))
return Y_ def __len__(self):
return self.__num def __getitem__(self, idx):
x = self.__X[idx]
y_ = self.__Y_[idx]
if self.__transform:
x = self.__transform(x)
if self.__target_transform:
y_ = self.__target_transform(y_)
return x, y_ # 构建模型
class Linear(nn.Module): def __init__(self, dim_in, dim_out):
super(Linear, self).__init__() self.__dim_in = dim_in
self.__dim_out = dim_out
self.weight = nn.Parameter(torch.randn((dim_in, dim_out)))
self.bias = nn.Parameter(torch.randn((dim_out,))) def forward(self, X):
X = torch.matmul(X, self.weight) + self.bias
return X class Tanh(nn.Module): def __init__(self):
super(Tanh, self).__init__() def forward(self, X):
X = torch.tanh(X)
return X class Dropout(nn.Module): def __init__(self, p):
super(Dropout, self).__init__() assert 0 <= p <= 1
self.__p = p # 置零概率 def forward(self, X):
if self.__p == 0:
return X
if self.__p == 1:
return torch.zeros_like(X)
mark = (torch.rand(X.shape) > self.__p).type(torch.float)
X = X * mark / (1 - self.__p)
return X class MLP(nn.Module): def __init__(self, dim_hidden=50, p=0, is_training=True):
super(MLP, self).__init__() self.__dim_hidden = dim_hidden
self.__p = p
self.training = True
self.__dim_in = 3
self.__dim_out = 3 self.lin1 = Linear(self.__dim_in, self.__dim_hidden)
self.tanh = Tanh()
self.drop = Dropout(self.__p)
self.lin2 = Linear(self.__dim_hidden, self.__dim_out) def forward(self, X):
X = self.tanh(self.lin1(X))
if self.training:
X = self.drop(X)
X = self.lin2(X)
return X # 构建损失函数
class MSE(nn.Module): def __init__(self):
super(MSE, self).__init__() def forward(self, Y, Y_):
loss = torch.sum((Y - Y_) ** 2) / 2
return loss # 训练单元与测试单元
def train_epoch(trainLoader, model, loss_fn, optimizer):
model.train()
loss = 0 with torch.enable_grad():
for X, Y_ in trainLoader:
optimizer.zero_grad()
Y = model(X)
loss_tmp = loss_fn(Y, Y_)
loss_tmp.backward()
optimizer.step() loss += loss_tmp.item()
return loss def test_epoch(testLoader, model, loss_fn):
model.eval()
loss = 0 with torch.no_grad():
for X, Y_ in testLoader:
Y = model(X)
loss_tmp = loss_fn(Y, Y_)
loss += loss_tmp.item() return loss # 进行训练与测试
def train(trainLoader, testLoader, model, loss_fn, optimizer, epochs):
minLoss = numpy.inf
for epoch in range(epochs):
trainLoss = train_epoch(trainLoader, model, loss_fn, optimizer) / len(trainLoader.dataset)
testLoss = test_epoch(testLoader, model, loss_fn) / len(testLoader.dataset)
if testLoss < minLoss:
minLoss = testLoss
torch.save(model.state_dict(), "./mlp.params")
# if epoch % 100 == 0:
# print(f"epoch = {epoch:8}, trainLoss = {trainLoss:15.9f}, testLoss = {testLoss:15.9f}")
return minLoss numpy.random.seed(0)
torch.random.manual_seed(0) def search_dropout():
trainData = GeneDataset(num=50, transform=torch.Tensor, target_transform=torch.Tensor)
trainLoader = data.DataLoader(trainData, batch_size=50, shuffle=True)
testData = GeneDataset(num=1000, transform=torch.Tensor, target_transform=torch.Tensor)
testLoader = data.DataLoader(testData, batch_size=1000, shuffle=False) dim_hidden1 = 300
p = 0.005
model = MLP(dim_hidden1, p)
loss_fn = MSE()
optimizer = optim.Adam(model.parameters(), lr=0.003)
train(trainLoader, testLoader, model, loss_fn, optimizer, 100000) pRange = numpy.linspace(0, 1, 101)
lossList = list()
for idx, p in enumerate(pRange):
model = MLP(dim_hidden1, p)
loss_fn = MSE()
optimizer = optim.Adam(model.parameters(), lr=0.003)
model.load_state_dict(torch.load("./mlp.params"))
loss = train(trainLoader, testLoader, model, loss_fn, optimizer, 100000)
lossList.append(loss)
print(f"p = {p:10f}, loss = {loss:15.9f}") minIdx = numpy.argmin(lossList)
pBest = pRange[minIdx]
lossBest = lossList[minIdx] fig = plt.figure(figsize=(5, 4))
ax1 = fig.add_subplot(1, 1, 1)
ax1.plot(pRange, lossList, ".--", lw=1, markersize=5, label="testing error", zorder=1)
ax1.scatter(pBest, lossBest, marker="*", s=30, c="red", label="optimal", zorder=2)
ax1.set(xlabel="$p$", ylabel="error", title="optimal dropout probability = {:.5f}".format(pBest))
ax1.legend()
fig.tight_layout()
fig.savefig("search_p.png", dpi=100)
# plt.show() if __name__ == "__main__":
search_dropout()
结果展示
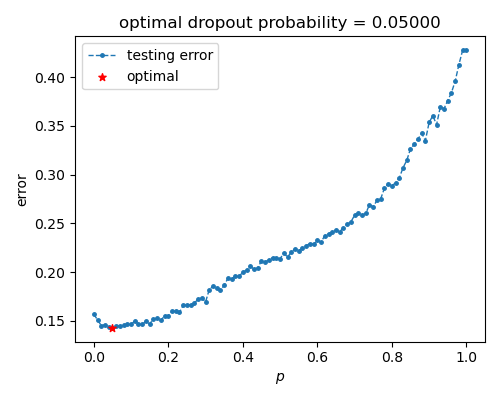
可以看到, 泛化误差在提升置零概率后先下降后上升, 大致对应降低模型复杂度使模型表现从过拟合至欠拟合.
使用建议
①. dropout为使整个节点失效, 通常作用在节点的最终输出上(即激活函数后);
②. dropout适用于神经网络全连接层.参考文档
①. 动手学深度学习 - 李牧
Neural Network模型复杂度之Dropout - Python实现的更多相关文章
- A Neural Network in 11 lines of Python
A Neural Network in 11 lines of Python A bare bones neural network implementation to describe the in ...
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Recurrent Neural Network系列4--利用Python,Theano实现GRU或LSTM
yi作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORK ...
- Python -- machine learning, neural network -- PyBrain 机器学习 神经网络
I am using pybrain on my Linuxmint 13 x86_64 PC. As what it is described: PyBrain is a modular Machi ...
- [Python Debug]Kernel Crash While Running Neural Network with Keras|Jupyter Notebook运行Keras服务器宕机原因及解决方法
最近做Machine Learning作业,要在Jupyter Notebook上用Keras搭建Neural Network.结果连最简单的一层神经网络都运行不了,更奇怪的是我先用iris数据集跑了 ...
- 从0开始用python实现神经网络 IMPLEMENTING A NEURAL NETWORK FROM SCRATCH IN PYTHON – AN INTRODUCTION
code地址:https://github.com/dennybritz/nn-from-scratch 文章地址:http://www.wildml.com/2015/09/implementing ...
- 机器学习: Python with Recurrent Neural Network
之前我们介绍了Recurrent neural network (RNN) 的原理: http://blog.csdn.net/matrix_space/article/details/5337404 ...
- 通过Visualizing Representations来理解Deep Learning、Neural network、以及输入样本自身的高维空间结构
catalogue . 引言 . Neural Networks Transform Space - 神经网络内部的空间结构 . Understand the data itself by visua ...
- Recurrent Neural Network[survey]
0.引言 我们发现传统的(如前向网络等)非循环的NN都是假设样本之间无依赖关系(至少时间和顺序上是无依赖关系),而许多学习任务却都涉及到处理序列数据,如image captioning,speech ...
- A Survey of Model Compression and Acceleration for Deep Neural Network时s
A Survey of Model Compression and Acceleration for Deep Neural Network时s 本文全面概述了深度神经网络的压缩方法,主要可分为参数修 ...
随机推荐
- 微信小程序-支付
微信小程序的支付只要用到官方的支付API : wx.requestPayment(Object object) 官方文档地址:https://developers.weixin.qq.com/mini ...
- TreeMap排序Comparator()重写
package map_;import java.util.Comparator;import java.util.TreeMap;/* * @author YAM */public class Tr ...
- 插头dp 模板
[JLOI2009]神秘的生物 只需要维护连通情况,采用最小表示法,表示此格是否存在,也即插头是否存在 分情况讨论当前格子的轮廓线上方格子和左方格子状态,转移考虑当前格子选不选,决策后状态最后要能合法 ...
- PHP的25种框架
本篇文章给大家分享的内容是25种PHP框架 -有着一定的参考价值,有需要的朋友可以参考一下. 世界流行框架汇总 在项目开发中,一些架构和代码都是重复的,为了避免重复劳动,于是各种各样的框架诞生了. 在 ...
- 网络配置:Netplan
Netplan 新出的Ubuntu服务器18.04版本修改了IP地址配置程序, Ubuntu和Debian的软件架构师删除了以前的ifup/ifdown命令和/etc/network/interfac ...
- 结合ChatGPT体验新必应new bing 的惊喜:这是我第一次使用的感受
前言 最近相信大家都被 ChatGPT 刷屏了,它的爆火大家是有目共睹的,微软的新必应(New Bing) 是结合了比 ChatGPT 更强大的新一代 OpenAI 语言模式,接下来我们一起来&quo ...
- 溢出标志位OF与进位标志位CF判断
1.OF与CF概述 OF(Overflow Flag,溢出标志位):有符号数之间加减运算的溢出标志 CF(Carry Flag,进位标志位):无符号数之间加减运算的溢出标志 快速判断(加法)(减法可转 ...
- Python ( 高级 第一部)
目录 time 时间模块 Python的内置方法 数字模块 随机模块 序列化模块 pickle 序列化模块 json os 系统模块 os shutil 模块 os,path 模块 文件压缩模块 z ...
- SQL注入、XSS
参考视频 一.Sql注入的原因 用户输入的信息,拼接到程序中进行了执行. 一.使用Burpsuite,进行万能钥匙探索 二.使用sqlmap进行测试 三.SQL注入基础知识 Mysql 5.x数据结构 ...
- windows的lib与dll
mingw编译出来的动态库的导入库可以直接在vc中直接使用 静态库 lib .a 动态库 dll动态库导入库 lib .dll.a 静态链接库a) 静态链接库的类和函数不需要导出,就能够被其他库调用. ...