Hive笔记之Fetch Task
在使用Hive的时候,有时候只是想取表中某个分区的前几条的记录看下数据格式,比如一个很常用的查询:
select * from foo where partition_column=bar limit 10;
这种对数据基本没什么要求,随便来点就行,既然如此为什么不直接读取本地存储的数据作为结果集呢。
Hive命令都要转换为MapReduce任务去执行,但是因为启动MapReduce需要消耗资源,然后速度还很慢(相比较于直接从本地文件中读取而言),所以Hive对于查询做了优化,对于某些查询可以不启动MapReduce任务的就尽量不去启动MapReduce任务,而是直接从本地文件读取。
个人理解: fetch task = 不启动MapReduce,直接读取本地文件输出结果。
在hive-site.xml中有三个fetch task相关的值:
hive.fetch.task.conversion
hive.fetch.task.conversion.threshold
hive.fetch.task.aggr
hive.fetch.task.conversion
这个属性有三个可选的值:
none:关闭fetch task优化
minimal:只在select *、使用分区列过滤、带有limit的语句上进行优化
more:在minimal的基础上更加强大了,select不仅仅可以是*,还可以单独选择几列,并且filter也不再局限于分区字段,同时支持虚拟列(别名)
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>
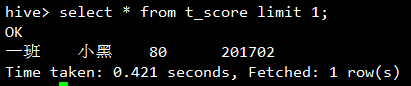
对于查询所有列的情况,会使用fetch task:
如果是查询部分列呢?
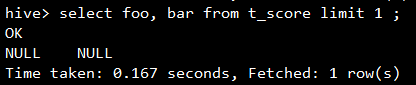
为什么查询部分列也使用了Fetch Task?查看一下当前的set hive.fetch.task.conversion的值:

尝试将hive.fetch.task.conversion设置为none,再查询:
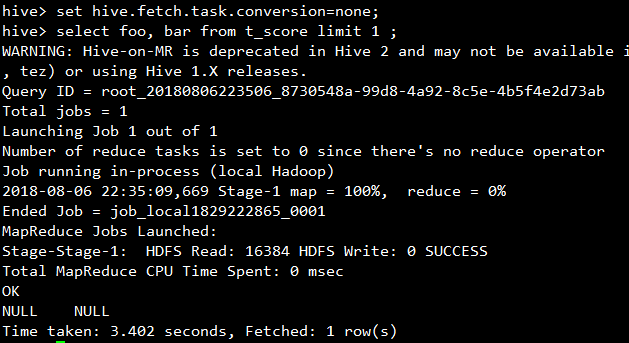
启动了MapReduce任务。
hive.fetch.task.conversion.threshold
在输入大小为多少以内的时候fetch task生效,默认1073741824 byte = 1G。
<property>
<name>hive.fetch.task.conversion.threshold</name>
<value>1073741824</value>
<description>
Input threshold for applying hive.fetch.task.conversion. If target table is native, input length
is calculated by summation of file lengths. If it's not native, storage handler for the table
can optionally implement org.apache.hadoop.hive.ql.metadata.InputEstimator interface.
</description>
</property>
hive.fetch.task.aggr
对于没有group by的聚合查询,比如select count(*) from src,这种最终都会在一个reduce中执行,像这种查询,可以把这个置为true将将其转换为fetch task,这可能会节约一些时间。
<property>
<name>hive.fetch.task.aggr</name>
<value>false</value>
<description>
Aggregation queries with no group-by clause (for example, select count(*) from src) execute
final aggregations in single reduce task. If this is set true, Hive delegates final aggregation
stage to fetch task, possibly decreasing the query time.
</description>
</property>
.
Hive笔记之Fetch Task的更多相关文章
- [转]Hive:简单查询不启用Mapreduce job而启用Fetch task
转自:http://www.iteblog.com/archives/831 如果你想查询某个表的某一列,Hive默认是会启用MapReduce Job来完成这个任务,如下: hive> SEL ...
- Hive基础(3)---Fetch Task(转)
我们在执行hive代码的时候,一条简单的命令大部分都会转换成为mr代码在后台执行,但是有时候我们仅仅只是想获取一部分数据而已,仅仅是获取数据,还需要转化成为mr去执行吗?那个也太浪费时间和内存啦,所以 ...
- Hive快捷查询:不启用Mapreduce job启用Fetch task三种方式介绍
如果查询表的某一列,Hive中默认会启用MapReduce job来完成这个任务,如下: hive>select id,name from m limit 10;--执行时hive会启用MapR ...
- Hive快捷查询:不启用Mapreduce job启用Fetch task
启用MapReduce Job是会消耗系统开销的.对于这个问题,从Hive0.10.0版本开始,对于简单的不需要聚合的类似SELECT <col> from <table> L ...
- 011-HQL中级1-Hive快捷查询:不启用Mapreduce job启用Fetch task三种方式介绍
如果你想查询某个表的某一列,Hive默认是会启用MapReduce Job来完成这个任务,如下: hive; Total MapReduce jobs Launching Job out since ...
- Hive笔记——技术点汇总
目录 · 概况 · 手工安装 · 引言 · 创建HDFS目录 · 创建元数据库 · 配置文件 · 测试 · 原理 · 架构 · 与关系型数据库对比 · API · WordCount · 命令 · 数 ...
- Hive笔记--sql语法详解及JavaAPI
Hive SQL 语法详解:http://blog.csdn.net/hguisu/article/details/7256833Hive SQL 学习笔记(常用):http://blog.sina. ...
- 【Hive】Hive笔记:Hive调优总结——数据倾斜,join表连接优化
数据倾斜即为数据在节点上分布不均,是常见的优化过程中常见的需要解决的问题.常见的Hive调优的方法:列剪裁.Map Join操作. Group By操作.合并小文件. 一.表现 1.任务进度长度为99 ...
- Hive 笔记
DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees ...
随机推荐
- PAT甲题题解-1032. Sharing (25)-链表水题
#include <iostream> #include <cstdio> #include <algorithm> #include <string.h&g ...
- 团队作业Week6:规格说明书编写
(1)请分析你们团队项目的典型用户和场景,并写一个团队博客发布你们团队项目的功能规格说明书. (2)再写一个博客团队博客发布你们项目的设计文档(技术规格说明书). 截止时间:2015-11-03
- BugPhobia开发篇章:Beta阶段第V次Scrum Meeting
0x01 :Scrum Meeting基本摘要 Beta阶段第五次Scrum Meeting 敏捷开发起始时间 2015/12/17 00:00 A.M. 敏捷开发终止时间 2015/12/17 23 ...
- Controller Plane
Toward Highly Available and Scalable Software Defined Networks for Service Providers IEEE Communicat ...
- 四种losses
1. Classification losses 每次输入一个样本,对样本进行类别预测,根据预测类别和真实标签得到对应的分类损失. 2. Pairwise losses 每次输入两个样本,数据集包含了 ...
- GitHub和Microsoft TFS对比有什么优势
GitHub变得越来越流行,最近Github发布了Github for Windows则大大降低了学习成本和使用难度,它甚至优于TFS. 微软也开始逐渐从TFS向GitHub转移了. 不是 TFS 输 ...
- 在 SQL Server 中从完整路径提取文件名(sql 玩转文件路径)
四个函数: --1.根据路径获取文件名 -- ============================================= -- Author: Paul Griffin -- Crea ...
- java学习一 path与classpath
path 任意目录下执行 javac JAVA classpath找到指定目录下的.class文件 前提是进入该文件目录里面 生成.class文件; 变量 的两个特性:1.约束了类型 2.约束了范围 ...
- Python day7之mysql
写在前面: 由于毕业论文撰写和答辩耽搁了几个月,但是在这几个月没有放弃学习Python,就是没有时间写博客.进行我们主要对数据库mysql的操作指令集的学习. 一.mysql术语 Mysql是最流行的 ...
- 【codevs1690】开关灯 (线段树 区间修改+区间求和 (标记))
[codevs1690]开关灯 2014年2月15日4930 题目描述 Description YYX家门前的街上有N(2<=N<=100000)盏路灯,在晚上六点之前,这些路灯全是关着的 ...