Hive笔记之Fetch Task
在使用Hive的时候,有时候只是想取表中某个分区的前几条的记录看下数据格式,比如一个很常用的查询:
select * from foo where partition_column=bar limit 10;
这种对数据基本没什么要求,随便来点就行,既然如此为什么不直接读取本地存储的数据作为结果集呢。
Hive命令都要转换为MapReduce任务去执行,但是因为启动MapReduce需要消耗资源,然后速度还很慢(相比较于直接从本地文件中读取而言),所以Hive对于查询做了优化,对于某些查询可以不启动MapReduce任务的就尽量不去启动MapReduce任务,而是直接从本地文件读取。
个人理解: fetch task = 不启动MapReduce,直接读取本地文件输出结果。
在hive-site.xml中有三个fetch task相关的值:
hive.fetch.task.conversion
hive.fetch.task.conversion.threshold
hive.fetch.task.aggr
hive.fetch.task.conversion
这个属性有三个可选的值:
none:关闭fetch task优化
minimal:只在select *、使用分区列过滤、带有limit的语句上进行优化
more:在minimal的基础上更加强大了,select不仅仅可以是*,还可以单独选择几列,并且filter也不再局限于分区字段,同时支持虚拟列(别名)
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>
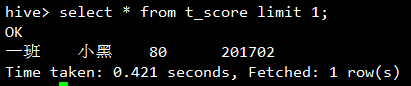
对于查询所有列的情况,会使用fetch task:
如果是查询部分列呢?
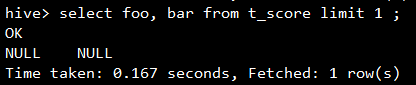
为什么查询部分列也使用了Fetch Task?查看一下当前的set hive.fetch.task.conversion的值:

尝试将hive.fetch.task.conversion设置为none,再查询:
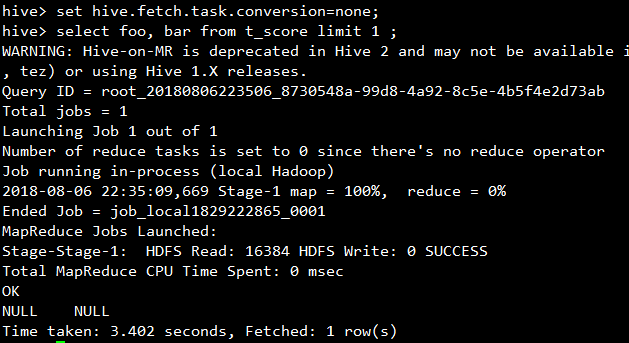
启动了MapReduce任务。
hive.fetch.task.conversion.threshold
在输入大小为多少以内的时候fetch task生效,默认1073741824 byte = 1G。
<property>
<name>hive.fetch.task.conversion.threshold</name>
<value>1073741824</value>
<description>
Input threshold for applying hive.fetch.task.conversion. If target table is native, input length
is calculated by summation of file lengths. If it's not native, storage handler for the table
can optionally implement org.apache.hadoop.hive.ql.metadata.InputEstimator interface.
</description>
</property>
hive.fetch.task.aggr
对于没有group by的聚合查询,比如select count(*) from src,这种最终都会在一个reduce中执行,像这种查询,可以把这个置为true将将其转换为fetch task,这可能会节约一些时间。
<property>
<name>hive.fetch.task.aggr</name>
<value>false</value>
<description>
Aggregation queries with no group-by clause (for example, select count(*) from src) execute
final aggregations in single reduce task. If this is set true, Hive delegates final aggregation
stage to fetch task, possibly decreasing the query time.
</description>
</property>
.
Hive笔记之Fetch Task的更多相关文章
- [转]Hive:简单查询不启用Mapreduce job而启用Fetch task
转自:http://www.iteblog.com/archives/831 如果你想查询某个表的某一列,Hive默认是会启用MapReduce Job来完成这个任务,如下: hive> SEL ...
- Hive基础(3)---Fetch Task(转)
我们在执行hive代码的时候,一条简单的命令大部分都会转换成为mr代码在后台执行,但是有时候我们仅仅只是想获取一部分数据而已,仅仅是获取数据,还需要转化成为mr去执行吗?那个也太浪费时间和内存啦,所以 ...
- Hive快捷查询:不启用Mapreduce job启用Fetch task三种方式介绍
如果查询表的某一列,Hive中默认会启用MapReduce job来完成这个任务,如下: hive>select id,name from m limit 10;--执行时hive会启用MapR ...
- Hive快捷查询:不启用Mapreduce job启用Fetch task
启用MapReduce Job是会消耗系统开销的.对于这个问题,从Hive0.10.0版本开始,对于简单的不需要聚合的类似SELECT <col> from <table> L ...
- 011-HQL中级1-Hive快捷查询:不启用Mapreduce job启用Fetch task三种方式介绍
如果你想查询某个表的某一列,Hive默认是会启用MapReduce Job来完成这个任务,如下: hive; Total MapReduce jobs Launching Job out since ...
- Hive笔记——技术点汇总
目录 · 概况 · 手工安装 · 引言 · 创建HDFS目录 · 创建元数据库 · 配置文件 · 测试 · 原理 · 架构 · 与关系型数据库对比 · API · WordCount · 命令 · 数 ...
- Hive笔记--sql语法详解及JavaAPI
Hive SQL 语法详解:http://blog.csdn.net/hguisu/article/details/7256833Hive SQL 学习笔记(常用):http://blog.sina. ...
- 【Hive】Hive笔记:Hive调优总结——数据倾斜,join表连接优化
数据倾斜即为数据在节点上分布不均,是常见的优化过程中常见的需要解决的问题.常见的Hive调优的方法:列剪裁.Map Join操作. Group By操作.合并小文件. 一.表现 1.任务进度长度为99 ...
- Hive 笔记
DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees ...
随机推荐
- 5分钟让你明白HTTP协议
一.HTTP简介 1.http协议介绍 HTTP协议(HyperText Transfer Protocol,超文本传输协议)是因特网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标 ...
- BackBone及其实例探究
摘要 我们小组对MVC框架进行了学习.我的队友们已经在博客中对MVC的设计模式及优缺点进行了详细的探讨与分析,因此我的博客中只对MVC进行简单的介绍,而我将把重心放在Backbone MVC框架一 ...
- Alpha版本发布时间安排
Alpha版本发布截止时间:2014年11月23日 第一轮迭代M1报告时间:2014年11月27日课上 - 每个团队5分钟时间汇报,5分钟时间提问 第一轮迭代M1事后分析报告时间:2014年11月29 ...
- BugPhobia开发篇章:Beta阶段第V次Scrum Meeting
0x01 :Scrum Meeting基本摘要 Beta阶段第五次Scrum Meeting 敏捷开发起始时间 2015/12/17 00:00 A.M. 敏捷开发终止时间 2015/12/17 23 ...
- 第二个Sprint冲刺第五天(燃尽图)
- Photo Cleaner -- proposed by Wei Zhang
Need想必大家都有用手机或相机记录生活的习惯吧!在旅途中,驴友们见到美丽的风景,往往激动地咔嚓一下拍张照记录下来.完事后发现角度不太好,于是又咔嚓一下……不知不觉中一下照了好多,然而真正需要的只是那 ...
- 从零开始学Kotlin-泛型(8)
从零开始学Kotlin基础篇系列文章 与 Java 一样,Kotlin 也提供泛型,为类型安全提供保证,消除类型强转的烦恼. 泛型类的基本使用 泛型,即 "参数化类型",将类型参数 ...
- MySQL与Spring事务隔离级别
https://zhuanlan.zhihu.com/p/27887568 能画第一张表,根据表描述.
- [转帖] k8s kubectl 命令行技巧
https://jimmysong.io/posts/kubectl-cheatsheet/ Kubectl Cheatsheet kubectl命令技巧大全Posted on November 3, ...
- js & parseFloat & toFixed
js & parseFloat & toFixed https://repl.it/languages/javascript https://repl.it/repls/MintyBa ...