zmq 三种模型的python实现
1.Request-Reply模式:
客户端在请求后,服务端必须回响应
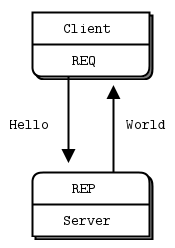
server:
#!/usr/bin/python
#-*-coding:utf-8-*-
import time
import zmq context = zmq.Context()
socket = context.socket(zmq.REP)
socket.bind("tcp://*:5555") while True:
message = socket.recv()
print(message)
#time.sleep(1)
socket.send("server response!")
client:
#!/usr/bin/python
#-*-coding:utf-8-*- import zmq
import sys context = zmq.Context()
socket = context.socket(zmq.REQ)
socket.connect("tcp://localhost:5555") while(True):
data = raw_input("input your data:")
if data == 'q':
sys.exit() socket.send(data) response = socket.recv();
print(response)
2.Publish-Subscribe模式:
广播所有client,没有队列缓存,断开连接数据将永远丢失。client可以进行数据过滤。
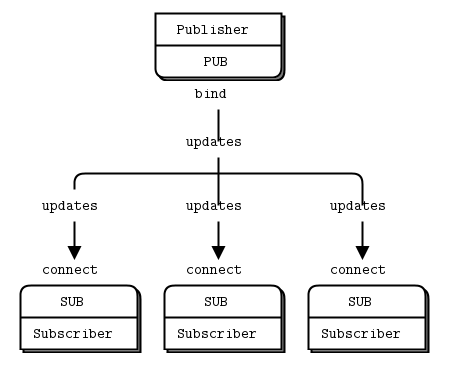
server:
#!/usr/bin/python
#-*-coding:utf-8-*- import zmq
context = zmq.Context()
socket = context.socket(zmq.PUB)
socket.bind("tcp://127.0.0.1:5000")
while True:
msg = raw_input('input your data:')
socket.send(msg)
client:
#!/usr/bin/python
#-*-coding:utf-8-*- import time
import zmq
context = zmq.Context()
socket = context.socket(zmq.SUB)
socket.connect("tcp://127.0.0.1:5000")
# 这里设置的是过滤条件,不然无法收到消息
socket.setsockopt(zmq.SUBSCRIBE,'')
while True:
print socket.recv()
3.Parallel Pipeline模式:
由三部分组成,push进行数据推送,work进行数据缓存,pull进行数据竞争获取处理。区别于Publish-Subscribe存在一个数据缓存和处理负载。
当连接被断开,数据不会丢失,重连后数据继续发送到对端。
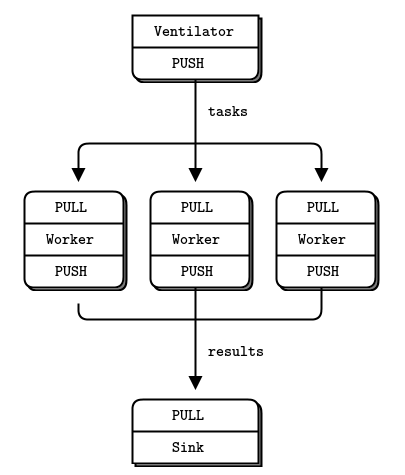
server:
#!/usr/bin/python
#-*-coding:utf-8-*- import zmq context = zmq.Context() socket = context.socket(zmq.PULL)
socket.bind('tcp://*:5558') while True:
data = socket.recv()
print data
work:
1 #!/usr/bin/python
2 #-*-coding:utf-8-*-
3
4 import zmq
5
6 context = zmq.Context()
7
8 recive = context.socket(zmq.PULL)
9 recive.connect('tcp://127.0.0.1:5557')
10
11 sender = context.socket(zmq.PUSH)
12 sender.connect('tcp://127.0.0.1:5558')
13
14 while True:
15 data = recive.recv()
16 sender.send(data)
client:
#!/usr/bin/python
#-*-coding:utf-8-*- import zmq
import time context = zmq.Context()
socket = context.socket(zmq.PUSH) socket.bind('tcp://*:5557') while True:
data = raw_input('input your data:')
socket.send(data)
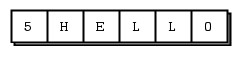
消息结构:
在每个消息buff前均会自带一个buff长度
zmq 三种模型的python实现的更多相关文章
- ZeroMQ - 三种模型的python实现
ZeroMQ是一个消息队列网络库,实现网络常用技术封装.在C/S中实现了三种模式,这段时间用python简单实现了一下,感觉python虽然灵活.但是数据处理不如C++自由灵活. 1.Request- ...
- SDN三种模型解析
数十年前,计算机科学家兼网络作家Andrew S. Tanenbaum讽刺标准过多难以选择,当然现在也是如此,比如软件定义网络模型的数量也很多.但是在考虑部署软件定义网络(SDN)或者试点之前,首先需 ...
- Javascript事件模型系列(一)事件及事件的三种模型
一.开篇 在学习javascript之初,就在网上看过不少介绍javascript事件的文章,毕竟是js基础中的基础,文章零零散散有不少,但遗憾的是没有看到比较全面的系列文章.犹记得去年这个时候,参加 ...
- PHP.23-ThinkPHP框架的三种模型实例化-(D()方法与M()方法的区别)
三种模型实例化 原则上:每个数据表应对应一个模型类(Home/Model/GoodsModel.class.php --> 表tp_goods) 1.直接实例化 和实例化其他类库一样实例化模型类 ...
- C语言提高 (3) 第三天 二级指针的三种模型 栈上指针数组、栈上二维数组、堆上开辟空间
1 作业讲解 指针间接操作的三个必要条件 两个变量 其中一个是指针 建立关联:用一个指针指向另一个地址 * 简述sizeof和strlen的区别 strlen求字符串长度,字符数组到’\0’就结束 s ...
- tensorflow 三种模型:ckpt、pb、pb-savemodel
1.CKPT 目录结构 checkpoint: model.ckpt-1000.index model.ckpt-1000.data-00000-of-00001 model.ckpt-1000.me ...
- 三种排序算法python源码——冒泡排序、插入排序、选择排序
最近在学习python,用python实现几个简单的排序算法,一方面巩固一下数据结构的知识,另一方面加深一下python的简单语法. 冒泡排序算法的思路是对任意两个相邻的数据进行比较,每次将最小和最大 ...
- 三种方法运行python
注:本文基于windows 1.交互式解释器 配置好环境变量后,命令行中打开,输入python即可,Ctrl+Z退出 命令行选项 当从命令行启动Python时,可以给解释器一些选项,如下: -d ...
- 矩阵的QR分解(三种方法)Python实现
1.Gram-Schmidt正交化 假设原来的矩阵为[a,b],a,b为线性无关的二维向量,下面我们通过Gram-Schmidt正交化使得矩阵A为标准正交矩阵: 假设正交化后的矩阵为Q=[A,B],我 ...
随机推荐
- CentOS 5.8下快速搭建FTP服务器
学习安装和配置vsftpd: 实验环境:CentOS 5.8 x86_64 测试环境关掉防火墙和selinux. service iptables stop setenforce 0 1.安装vsft ...
- 第32讲:List的基本操作实战与基于模式匹配的List排序算法实现
今天来学习一下list的基本操作及基于模式匹配的排序操作 让我们从代码出发 val bigData = List("hadoop","spark") val d ...
- 计算几何---凸包问题(Graham/Andrew Scan )
概念 凸包(Convex Hull)是一个计算几何(图形学)中的概念.用不严谨的话来讲,给定二维平面上的点集,凸包就是将最外层的点连接起来构成的凸多边型,它能包含点集中所有点的.严谨的定义和相关概念参 ...
- PHP搜索 搜索 搜索
//搜索界面 public function search(){ $param=input('param.'); $where=[]; //搜索框 if(!empty($param['content' ...
- 用JavaScript写的动态表格
实现的功能有Table表格添加,删除.输入,删除的全选,单行删除. HTML代码部分 <body> <form> <table border="1" ...
- 【CF600E】 Lomsat gelral
CF600E Lomsat gelral Solution 考虑一下子树的问题,我们可以把一棵树的dfn序搞出来,那么子树就是序列上的一段连续的区间. 然后就可以莫队飞速求解了. 但是这题还有\(\T ...
- HTML元素ID和JS方法名重复,JS调用失败
HTML元素ID和JS方法名重复时,JS中的重名方法无法被找到,不能执行. 修改ID或者方法名,两者不一致即可.
- javaScript中BOM
BOM是browser object model的缩写,简称浏览器对象模型 主要处理浏览器窗口(window)和框架(iframe),简述了与浏览器进行交互的方法和接口, 可以对浏览器窗口进行访问和操 ...
- Vue.js之下拉列表及选中触发事件
老早就听说了Vue.js是多么的简单.易学.好用等等,然而我只是粗略的看了下文档,简单的敲了几个例子,仅此而已. 最近由于项目的需要,系统的看了下文档,也学到了一些东西. 废话不多说,这里要说的是下拉 ...
- iOS开发笔记-图标和图片大小官方最新标准
这两天开发iOS app用到了Tab bar,然后随便切了点图标放上去发现效果极差.于是乎,开始查找苹果官方给的标准.搜索一番后,看到了一篇博文,但其内容与iOS人机交互指南最新版内容不符. 故此,在 ...