Seq2Seq模型与注意力机制
Seq2Seq模型
基本原理
- 核心思想:将一个作为输入的序列映射为一个作为输出的序列
- 编码输入
- 解码输出
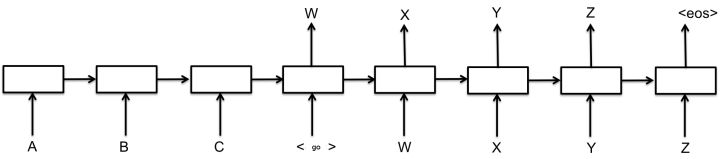
- 解码第一步,解码器进入编码器的最终状态,生成第一个输出
- 以后解码器读入上一步的输出,生成当前步输出
- 组成部件:
- Encoder
- Decoder
- 连接两者的固定大小的State Vector
解码方法
- 最核心部分,大部分的改进
- 贪心法
- 选取一种度量标准后,在当前状态下选择最佳的一个结果,直到结束
- 计算代价低
- 局部最优解
- 选取一种度量标准后,在当前状态下选择最佳的一个结果,直到结束
- 集束搜索(Beam Search)
- 启发式算法
- 保存beam size个当前较佳选择,决定了计算量,8~12最佳
- 解码时每一步根据保存的结果选择下一步扩展和排序,选择前beam size个保存
- 循环迭代,直到结束。选择最佳结果输出
- 改进
- 堆叠RNN
- Dropout机制
- 与编码器之间建立残差连接
- 注意力机制
- 记忆网络
注意力机制
Seq2Seq模型中的注意力机制
- 在实际发现,随着输入序列增长,模型性能发生显著下降
- 小技巧
- 将源语言句子逆序输入,或者重复输入两遍,得到一定的性能提升
- 解码时当前词及对应的源语言词的上下文信息和位置信息在编解码过程中丢失了
- 引入注意力机制解决上述问题:
- 解码时,每一个输出词都依赖于前一个隐状态以及输入序列每一个对应的隐状态
\[s_i = f(s_{i-1}, y_{i-1},c_i)\]
\[p(y_i|y_1,\cdots,y_{i-1})=g(y_{i-1},s_i,c_i)\]
其中,\(y\)是输出词,\(s\)是当前隐状态,\(f,g\)是非线性变换,通常为神经网络 - 语境向量\(c_i\)是输入序列全部隐状态\(h_1,\cdots,h_T\)的加权和
\[c_i=\sum \limits_{j=1}^T a_{ij}h_j \]
\[a_{ij} = \frac{\exp(e_{ij})}{\sum_k \exp(e_{ij})} \]
\[e_{ij}=a(s_{i-1},h_j) \] - 神经网络\(a\)将上一个输出序列隐状态\(s_{i-1}\)和输入序列隐状态\(h_j\)作为输入,计算出一个\(x_j,y_i\)对齐的值\(e_{ij}\)
- 考虑每个输入词与当前输出词的对齐关系,对齐越好的词,会有更大权重,对当前输出影响更大
- 双向循环神经网络
- 单方向:\(h_i\)只包含了\(x_0\)到\(x_i\)的信息,\(a_{ij}\)丢失了\(x_i\)后面的信息
双方向:第\(i\)个输入词对应的隐状态包括了\(\overrightarrow{h}_i\)和\(\overleftarrow{h}_i\),前者编码了\(x_0\)到\(x_i\)的信息,后者编码了\(x_i\)及之后的信息,防止信息丢失
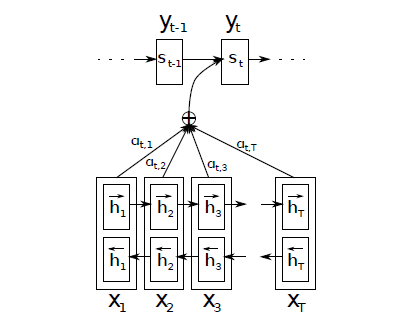
- 解码时,每一个输出词都依赖于前一个隐状态以及输入序列每一个对应的隐状态
常见Attention形式
本质:一个查询(query)到一系列(键key-值value)对的映射
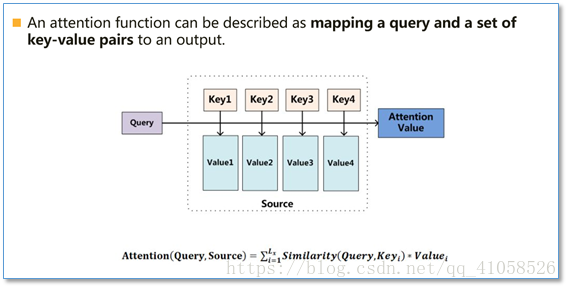
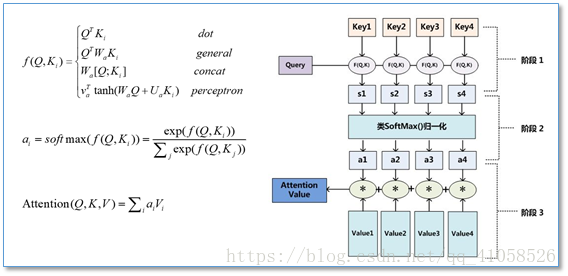
- 计算过程
- 将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等
- 使用一个softmax函数对这些权重进行归一化
- 权重和相应的键值value进行加权求和得到最后的attention
Seq2Seq模型与注意力机制的更多相关文章
- 深度学习教程 | Seq2Seq序列模型和注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/35 本文地址:http://www.showmeai.tech/article-det ...
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- 吴恩达《深度学习》-第五门课 序列模型(Sequence Models)-第三周 序列模型和注意力机制(Sequence models & Attention mechanism)-课程笔记
第三周 序列模型和注意力机制(Sequence models & Attention mechanism) 3.1 序列结构的各种序列(Various sequence to sequence ...
- Pytorch系列教程-使用Seq2Seq网络和注意力机制进行机器翻译
前言 本系列教程为pytorch官网文档翻译.本文对应官网地址:https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutor ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 序列模型和注意力机制
一.基础模型 假设要翻译下面这句话: "简将要在9月访问中国" 正确的翻译结果应该是: "Jane is visiting China in September" ...
- ng-深度学习-课程笔记-17: 序列模型和注意力机制(Week3)
1 基础模型(Basic models) 一个机器翻译的例子,比如把法语翻译成英语,如何构建一个神经网络来解决这个问题呢? 首先用RNN构建一个encoder,对法语进行编码,得到一系列特征 然后用R ...
- Coursera Deep Learning笔记 序列模型(三)Sequence models & Attention mechanism(序列模型和注意力机制)
参考 1. 基础模型(Basic Model) Sequence to sequence模型(Seq2Seq) 从机器翻译到语音识别方面都有着广泛的应用. 举例: 该机器翻译问题,可以使用" ...
- DLNg第三周:序列模型和注意力机制
1.基础模型 将法语翻译为英语,分为编码和解码阶段,将一个序列变为另一个序列.即序列对序列模型. 从图中识别出物体的状态,将图片转换为文字. 先使用CNN处理图片,再使用RNN将其转换为语言描述. 2 ...
- NLP教程(6) - 神经机器翻译、seq2seq与注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
随机推荐
- 配置Notepad++
Notepad++配置 1.自动换行 视图 - 自动换行 2.隐藏工具栏 设置 - 首选项... > 常用 > 工具栏 - 隐藏 3.隐藏菜单栏 设置 - 首选项... > 常用 & ...
- Hadoop hadoop(2.9.0)---uber模式(小作业“ubertask”优化)
前言: 在有些情况下,运行于Hadoop集群上的一些mapreduce作业本身的数据量并不是很大,如果此时的任务分片很多,那么为每个map任务或者reduce任务频繁创建Container,势必会增加 ...
- Go by Example-循环
Go By Example-循环语句 Go和其他大多数语言不太一样,没有While和Do-Whiile形式的循环,只有一个for,来实现循环. 基本结构 for循环的基本结构是这个样子 for 变量; ...
- OAuth 2.0 的四种方式
上一篇文章介绍了 OAuth 2.0 是一种授权机制,主要用来颁发令牌(token).本文接着介绍颁发令牌的实务操作. 下面我假定,你已经理解了 OAuth 2.0 的含义和设计思想,否则请先阅读这个 ...
- TynSerial序列(还原)TClientDataSet
TynSerial序列(还原)TClientDataSet 可以一次性序列(还原)多个TClientDataSet. 1)TClientDataSet查询数据 procedure TForm1.Qry ...
- android: requestLayout(), invalidate(), postInvalidate() 方法区别
一.invalidate和postInvalidate 这两个方法都是在重绘当前控件的时候调用的.invalidate在UI线程中调用,postInvalidate在非UI线程中调用.因为androi ...
- 123457123456---熊猫宝贝连数字游戏(儿童连数字)--com.threeObj03.shuziLink
熊猫宝贝连数字游戏(儿童连数字)--com.threeObj03.shuziLink
- 解决微信小程序textarea层级太高遮挡其他组件的问题
<view class='remark'> <view class='title'> 备注说明 </view> <textarea class='mark_t ...
- Python3多重继承排序原理(C3算法)
参考:https://www.jianshu.com/p/c9a0b055947b https://xubiubiu.com/2019/06/10/python-%E6%96%B9%E6%B3%95% ...
- iOS-AppDelegate详解
项目中AppDelegate详解 1.AppDelegate.h //模板默认引入程序需要使用“类”的框架,即UIKit.h头文件,使它包含在程序中 #import <UIKit/UIKit.h ...