IDM下载百度资源出现403的解决方法
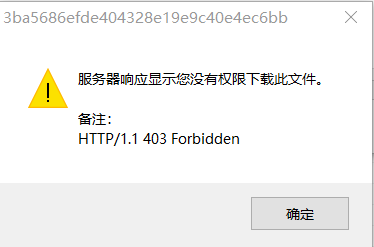
测试发现是受cookie的影响,百度为了防止用外部下载工具突破限速加入了cookie验证,因为一般的下载工具请求下载的时候不会附加cookie信息。
IDM就是这样,它请求下载文件时只知道文件的下载地址,并不会在请求协议里附加cookie。
可以通过代理服务器做手脚加入cookie。
这里的cookie只需要一个值,BDUSS的值。
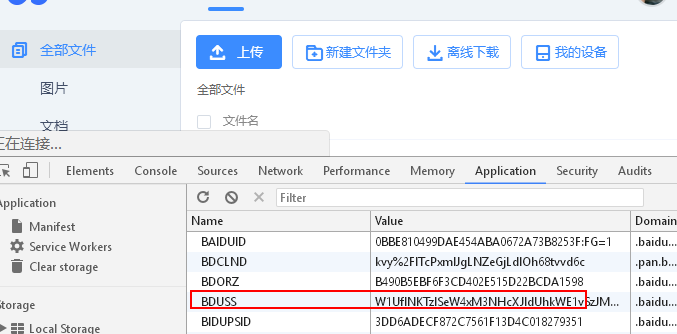
先从网盘页面拿到cookie值。
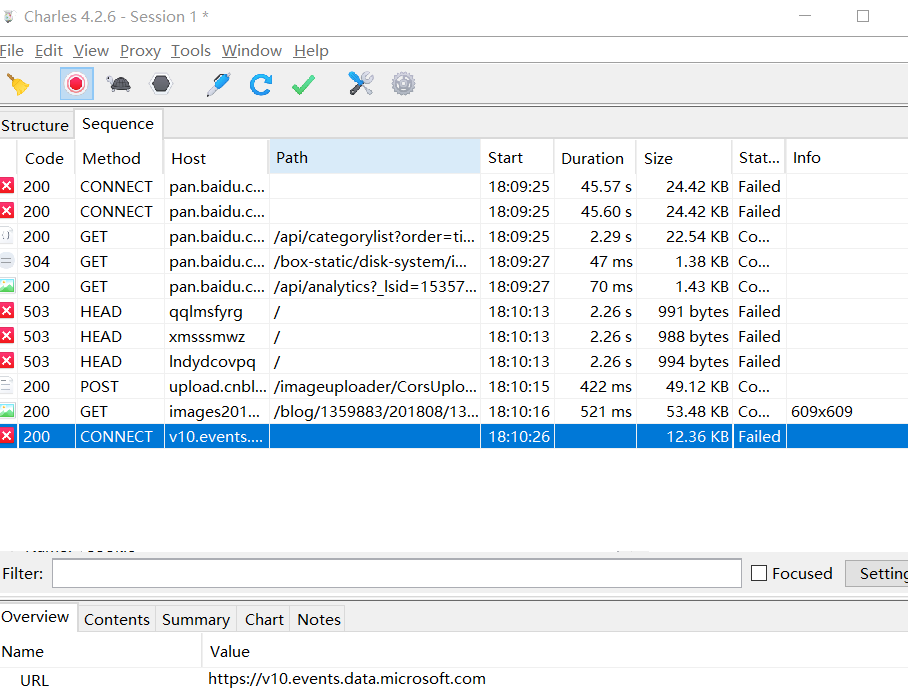
打开一个可以修改数据包的代理软件,如charls。
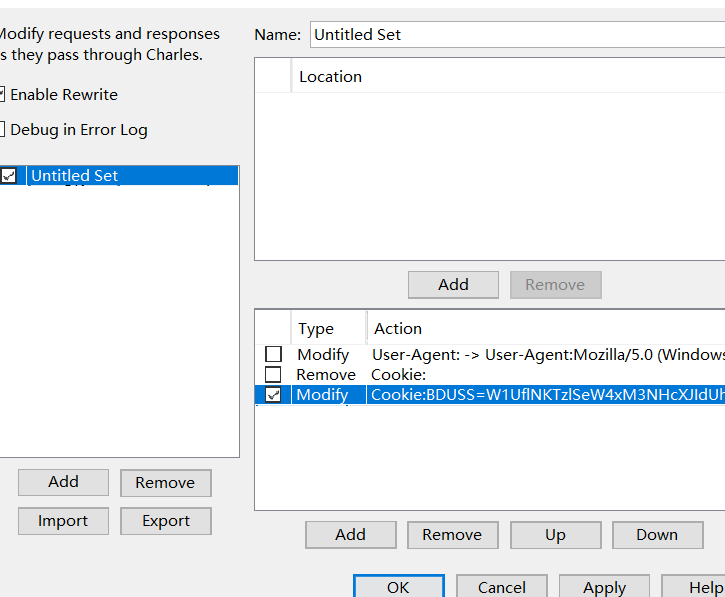

菜单tools-rewrite-enable rewrite,add一条修改规则。
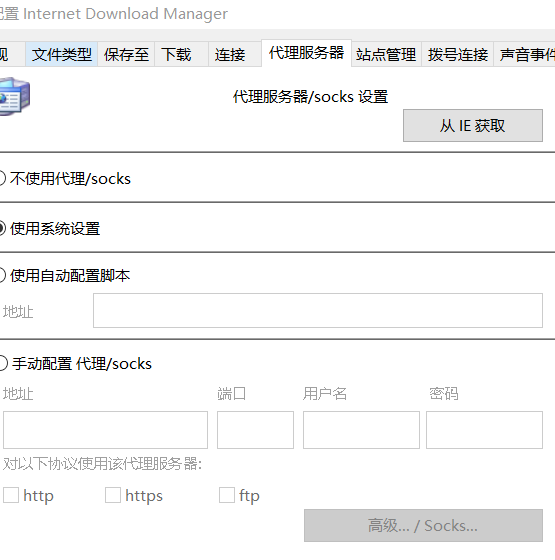
然后配置IDM,选项-代理服务器-使用系统代理,接受代理。

成功建立下载。
顺便说下迅雷下载403的解决方法:
同样是因为解决BDUSS的验证。
迅雷有内置浏览器,只要将BDUSS的cookie值写入其浏览器cookie数据表中,迅雷建立下载任务时会自动附加同域下的cookie。
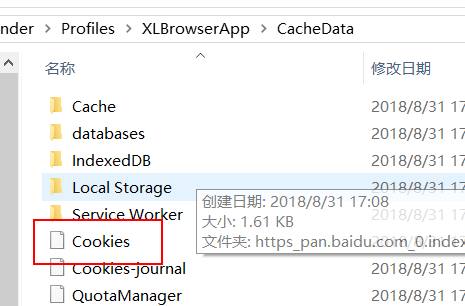
查找发现迅雷内置浏览器的cookie数据保存在”Thunder Network\Thunder\Profiles\XLBrowserApp\CacheData\Cookie“,记事本打开发现是一个sqlite数据表。
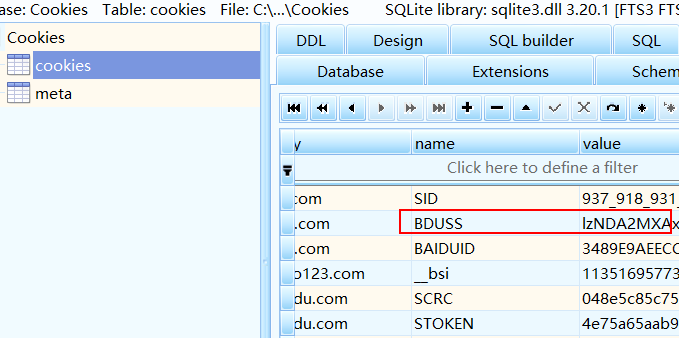
随便打开一个数据表操作工具在Cookies表中写入BDUSS值,然后可以将百度的下载链接复制到迅雷测试下载了。
IDM下载百度资源出现403的解决方法的更多相关文章
- nagios报错HTTP WARNING: HTTP/1.1 403 Forbidden解决方法
Nagios--localhost报警:"WARNING: HTTP/1.1 403 Forbidden "解决方法: In dashboard it shows alert on ...
- IDM使用教程:利用IDM下载百度网盘文件
IDM是什么 其实我使用IDM下载器只是为了方便网页版百度网盘直接下载大于40M文件而已,大家知道文件过大必须打开客户端才能下载,这点对于我的破电脑感觉很烦躁,每次要等待它慢悠悠打开,然后动用我的超级 ...
- Android Studio使用远程依赖时下载不了jar包的解决方法
使用AS很大的一个好处就是可以使用在线jar包,只需在引用jar包的时候在版本后加上+,比如: compile 'com.facebook.fresco:fresco:0.1.0+' 这样不用在jar ...
- 【spring】静态资源的访问受限解决方法
前言 我们知道在整合spring mvc框架的时候需要在web.xml中配置一个servlet 代码如下 <!--spring mvc 的DispatcherServlet--> < ...
- win8安装wampserver报403错误解决方法
看着别人开始体验win8了,前几天我也安装了win8系统,总体来说还不错,但是今天安装完Wampserver后,浏览器输入localhost,竟然报了403错误,我以为我安装出错了,后来研究了半天,发 ...
- Apache 403 错误解决方法-让别人可以访问你的服务器(转)
有一次做好了一个效果放在自己电脑的服务器上,让同学查看(同处于校园网中),却不知apache一直显示403 错误,对方没有权限访问,我知道这应该是配置文件httpd.conf中的问题,网上搜了一下其他 ...
- Chrome浏览器Json查看插件JsonHandle下载以及无法安装插件的解决方法
场景 在使用Chrome浏览器查看Json数据时如果没有插件会挤作一团. 安装JsonHandle插件后 博客: https://blog.csdn.net/badao_liumang_qizhi 关 ...
- django post请求 403错误解决方法
--摘 第一次用Django做项目,遇到了很多问题. 今天遇到的问题是Django在处理post请求时多次出现403错误. 我先描述一下问题出现的环境:我用Django写了一个web服务端,姑且称它为 ...
- 微信小程序访问豆瓣api报403错误解决方法
通过豆瓣API可以获取很多电影.书籍的数据信息,今天在调用豆瓣正在上映电影接口的时候报403错误,原因是豆瓣设置了小程序的访问权限.如下: 解决方法是使用代理,将豆瓣API地址换成 https://d ...
随机推荐
- 阶段5 3.微服务项目【学成在线】_day04 页面静态化_13-页面静态化-数据模型-轮播图DataUrl接口
要开发轮播图的DataUrl的接口 轮播图的配置的集合 xc-framework-model这个module下 CmsConfigModel的类的属性 定义接口 在api里面定义接口:CmsConfi ...
- PAT 甲级 1013 Battle Over Cities (25 分)(图的遍历,统计强连通分量个数,bfs,一遍就ac啦)
1013 Battle Over Cities (25 分) It is vitally important to have all the cities connected by highway ...
- React Native使用NetInfo对当前系统网络的判断
有网状态: 断网状态: 代码如下: 注意:第一次参考了http://www.hangge.com/blog/cache/detail_1614.html代码,一直显示的是unknow状态... 最后处 ...
- iOS- UITextView禁止Emoji表情
UITextView代理方法:判断 -(void)textViewDidEndEditing:(UITextView *)textView{ if ([self stringContai ...
- Caché,Cache数据库下载
Caché数据库主要用于医疗领域,国内的开发人员比较少接触,使用环境相对封闭,前段时间刚才用到,下载也费了许多时间,特记录一下,帮助那些需要的人. 顺便说一下,TreeSoft数据库管理系统,目前支持 ...
- EMC DS300B光纤交换机扩展光口license
一.通过EMC指定的网站激活license 激活license,生成激活码需要三个信息: 1.交换机WWN号:可在交换机铭牌上查看:(16位) 2.SN号码:AQA00***9*6(11位) 3.ke ...
- 【DSP开发】帮您快速入门 TI 的 Codec Engine
德州仪器半导体技术(上海)有限公司 通用DSP 技术应用工程师 崔晶 德州仪器(TI)的第一颗达芬奇(DaVinci)芯片(处理器)DM6446已经问世快三年了.继DM644x之后,TI又陆续推出了D ...
- 第34课.数组操作符的重载("[]"重载)
1.问题:string类对象还具备c方式字符串的灵活性吗?还能直接访问单个字符吗? 答案:可以按照c字符串的方式使用string对象 string s = "a1b2c3d4e"; ...
- MySQL的安装、配置与优化
MySQL 安装配置 参考网址:https://www.runoob.com/linux/mysql-install-setup.html MySQL 是最流行的关系型数据库管理系统,由瑞典MySQL ...
- mui横向滑动菜单
<style> .mui-bar a { color: #E02D26; } #topItem { background: white; border-bottom: 1px solid ...