SQL 创建表
SQL 创建表是通过SQL CREATE TABLE 语句来实现,该语句是DDL SQL语句。CREATE TABLE语句用于创建用于存储数据的表。在创建表时,可以为列定义主键、惟一键和外键等完整性约束。完整性约束可以在列级或表级定义。对于不同的RDBMS, CREATE语句的实现和语法是不同的。
CREATE TABLE语句语法
CREATE TABLE table_name (column_name1 datatype, column_name2 datatype,... column_nameN datatype);
- table_name—是表的名称
column_name1, column_name2 ….-是列的名称
datatype -是列的数据类型,比如char、date、number等
例如:如果要创建employee表,语句应该是这样的:
CREATE TABLE employee ( id number(5), name char(20), dept char(10), age number(2), salary number(10), location char(10));
在Oracle数据库中,整数列的数据类型表示为“number”。在Sybase中,它表示为“int”。
Oracle提供了另一种创建表的方法。
CREATE TABLE temp_employee SELECT * FROM employee在上面的语句中,使用与employee表相同的列数和数据类型创建了temp_employee表。
CREATE TABLE语句例子
比如我们想创建一个球员表,表名为player,里面有两个字段,一个是player_id,它是int类型,另一个player_name字段是varchar(255)类型。这两个字段都不为空,且player_id是递增的。
那么创建的时候就可以写为:
CREATE TABLE player (
player_id int(11) NOT NULL AUTO_INCREMENT,
player_name varchar(255) NOT NULL
);
需要注意的是,语句最后以分号(;)作为结束符,最后一个字段的定义结束后没有逗号。数据类型中int(11)代表整数类型,显示长度为11位,括号中的参数11代表的是最大有效显示长度,与类型包含的数值范围大小无关。varchar(255)代表的是最大长度为255的可变字符串类型。NOT NULL表明整个字段不能是空值,是一种数据约束。AUTO_INCREMENT代表主键自动增长。
实际上,我们通常很少自己写DDL语句,可以使用一些可视化工具来创建和操作数据库和数据表。在这里我推荐使用Navicat,它是一个数据库管理和设计工具,跨平台,支持很多种数据库管理软件,比如MySQL、Oracle、MariaDB等。基本上专栏讲到的数据库软件都可以使用Navicat来管理。
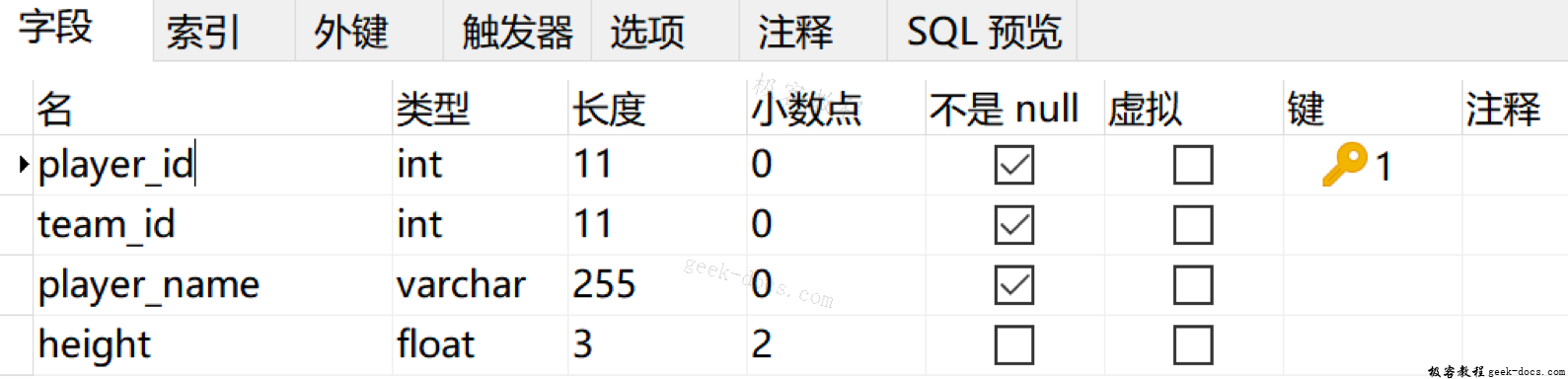
假如还是针对player这张表,我们想设计以下的字段:

其中player_id是数据表player的主键,且自动增长,也就是player_id会从1开始,然后每次加1。player_id、team_id、player_name 这三个字段均不为空,height字段可以为空。
按照上面的设计需求,我们可以使用Navicat软件进行设计,如下所示:
然后,我们还可以对player_name字段进行索引,索引类型为Unique。使用Navicat设置如下:

这样一张player表就通过可视化工具设计好了。我们可以把这张表导出来,可以看看这张表对应的SQL语句是怎样的。方法是在Navicat左侧用右键选中player这张表,然后选择“转储SQL文件”→“仅结构”,这样就可以看到导出的SQL文件了,代码如下:
DROP TABLE IF EXISTS `player`;
CREATE TABLE `player` (
`player_id` int(11) NOT NULL AUTO_INCREMENT,
`team_id` int(11) NOT NULL,
`player_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`height` float(3, 2) NULL DEFAULT 0.00,
PRIMARY KEY (`player_id`) USING BTREE,
UNIQUE INDEX `player_name`(`player_name`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
你能看到整个SQL文件中的DDL处理,首先先删除player表(如果数据库中存在该表的话),然后再创建player表,里面的数据表和字段都使用了反引号,这是为了避免它们的名称与MySQL保留字段相同,对数据表和字段名称都加上了反引号。
其中player_name字段的字符集是utf8,排序规则是utf8_general_ci,代表对大小写不敏感,如果设置为utf8_bin,代表对大小写敏感,还有许多其他排序规则这里不进行介绍。
因为player_id设置为了主键,因此在DDL中使用PRIMARY KEY进行规定,同时索引方法采用BTREE。
因为我们对player_name字段进行索引,在设置字段索引时,我们可以设置为UNIQUE INDEX(唯一索引),也可以设置为其他索引方式,比如NORMAL INDEX(普通索引),这里我们采用UNIQUE INDEX。唯一索引和普通索引的区别在于它对字段进行了唯一性的约束。在索引方式上,你可以选择BTREE或者HASH,这里采用了BTREE方法进行索引。我会在后面介绍BTREE和HASH索引方式的区别。
整个数据表的存储规则采用InnoDB。之前我们简单介绍过InnoDB,它是MySQL5.5版本之后默认的存储引擎。同时,我们将字符集设置为utf8,排序规则为utf8_general_ci,行格式为Dynamic,就可以定义数据表的最后约定了:
ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
你能看出可视化工具还是非常方便的,它能直接帮我们将数据库的结构定义转化成SQL语言,方便数据库和数据表结构的导出和导入。不过在使用可视化工具前,你首先需要了解对于DDL的基础语法,至少能清晰地看出来不同字段的定义规则、索引方法,以及主键和外键的定义。
数据表的常见约束
当我们创建数据表的时候,还会对字段进行约束,约束的目的在于保证RDBMS里面数据的准确性和一致性。下面,我们来看下常见的约束有哪些。
首先是主键约束
主键起的作用是唯一标识一条记录,不能重复,不能为空,即UNIQUE+NOT NULL。一个数据表的主键只能有一个。主键可以是一个字段,也可以由多个字段复合组成。在上面的例子中,我们就把player_id设置为了主键。
其次还有外键约束
外键确保了表与表之间引用的完整性。一个表中的外键对应另一张表的主键。外键可以是重复的,也可以为空。比如player_id在player表中是主键,如果你想设置一个球员比分表即player_score,就可以在player_score中设置player_id为外键,关联到player表中。
除了对键进行约束外,还有字段约束。
唯一性约束。
唯一性约束表明了字段在表中的数值是唯一的,即使我们已经有了主键,还可以对其他字段进行唯一性约束。比如我们在player表中给player_name设置唯一性约束,就表明任何两个球员的姓名不能相同。需要注意的是,唯一性约束和普通索引(NORMAL INDEX)之间是有区别的。唯一性约束相当于创建了一个约束和普通索引,目的是保证字段的正确性,而普通索引只是提升数据检索的速度,并不对字段的唯一性进行约束。
NOT NULL约束。
对字段定义了NOT NULL,即表明该字段不应为空,必须有取值。
DEFAULT,表明了字段的默认值。如果在插入数据的时候,这个字段没有取值,就设置为默认值。比如我们将身高height字段的取值默认设置为0.00,即DEFAULT 0.00。
CHECK约束
用来检查特定字段取值范围的有效性,CHECK约束的结果不能为FALSE,比如我们可以对身高height的数值进行CHECK约束,必须≥0,且<3,即CHECK(height>=0 AND height<3)。
设计数据表的原则
我们在设计数据表的时候,经常会考虑到各种问题,比如:用户都需要什么数据?需要在数据表中保存哪些数据?哪些数据是经常访问的数据?如何提升检索效率?
如何保证数据表中数据的正确性,当插入、删除、更新的时候该进行怎样的约束检查?
如何降低数据表的数据冗余度,保证数据表不会因为用户量的增长而迅速扩张?
如何让负责数据库维护的人员更方便地使用数据库?
除此以外,我们使用数据库的应用场景也各不相同,可以说针对不同的情况,设计出来的数据表可能千差万别。那么有没有一种设计原则可以让我们来借鉴呢?这里我整理了一个“三少一多”原则:
1.数据表的个数越少越好
RDBMS的核心在于对实体和联系的定义,也就是E-R图(Entity Relationship Diagram),数据表越少,证明实体和联系设计得越简洁,既方便理解又方便操作。
2.数据表中的字段个数越少越好
字段个数越多,数据冗余的可能性越大。设置字段个数少的前提是各个字段相互独立,而不是某个字段的取值可以由其他字段计算出来。当然字段个数少是相对的,我们通常会在数据冗余和检索效率中进行平衡。
3.数据表中联合主键的字段个数越少越好
设置主键是为了确定唯一性,当一个字段无法确定唯一性的时候,就需要采用联合主键的方式(也就是用多个字段来定义一个主键)。联合主键中的字段越多,占用的索引空间越大,不仅会加大理解难度,还会增加运行时间和索引空间,因此联合主键的字段个数越少越好。
4.使用主键和外键越多越好
数据库的设计实际上就是定义各种表,以及各种字段之间的关系。这些关系越多,证明这些实体之间的冗余度越低,利用度越高。这样做的好处在于不仅保证了数据表之间的独立性,还能提升相互之间的关联使用率。
你应该能看出来“三少一多”原则的核心就是简单可复用。简单指的是用更少的表、更少的字段、更少的联合主键字段来完成数据表的设计。可复用则是通过主键、外键的使用来增强数据表之间的复用率。因为一个主键可以理解是一张表的代表。键设计得越多,证明它们之间的利用率越高。
极客教程提供了DDL中与表(TABLE)相关的SQL语句:
SQL 创建表的更多相关文章
- sql创建表
表的创建 1.创建列(字段):列名+类型 2.设置主键列:能够唯一表示一条数据 3.设置唯一键:设计--索引/键--添加--唯一键(选择列)--确定 唯一键的内容不能重复 4.外键关系:一张表(从表) ...
- sql 常用的语句(sql 创建表结构 修改列 清空表)
1.创建表 create Table WorkItemHyperlink ( ID bigint primary key ,--主键 WorkItemID ,) not null,--其中identi ...
- SQL创建表脚本
<1>SQL Server设置主键自增长列 SQL Server设置主键自增长列 1.新建一数据表,里面有字段id,将id设为为主键 www.2cto.com create t ...
- sql 创建表、删除表 增加字段 删除字段操作
下面是Sql Server 和 Access 操作数据库结构的常用Sql,希望对你有所帮助. 新建表:create table [表名]([自动编号字段] int IDENTITY (1,1) PRI ...
- mysql用sql创建表完整实例
create table user_login_latest( id int(11) unsigned NOT NULL AUTO_INCREMENT, user_id int(11) not nul ...
- 使用sql创建表并添加注释
Create table T_ErrorLogTable_tb ( ELTID int identity(1,1) primary key,--编号 ELTTime date,--错误发生日期 ELT ...
- Oracle 使用sql创建表空间及用户
create tablespace OrcalDBNamedb datafile 'C:\OracleDBDirc\OrcalDBNamedb.dbf' size 300m; 创建用户create u ...
- sql创建表变量,转百分数
declare @tab table( ID nt identity(1,1) primary key, --从1开始,每次自增1 ,Name nvarchar(200) ) declare a fl ...
- sql创建表、改变表、关联查询语句
随机推荐
- idea在src/main/java下新建包后项目中只显示src/main,后面的东西不显示,但在本地磁盘中是存在的
去掉图中的勾
- HDU 6162 - Ch’s gift | 2017 ZJUT Multi-University Training 9
/* HDU 6162 - Ch’s gift [ LCA,线段树 ] | 2017 ZJUT Multi-University Training 9 题意: N节点的树,Q组询问 每次询问s,t两节 ...
- 什么是webpack模块化构建工具
百度百科模块化:是指解决一个复杂问题时自顶向下逐层把系统划分成若干模块的过程,有多种属性,分别反映其内部特性. 计算机模块化:一般指的是可以被抽象封装的最小/最优代码集合,模块化解决的是功能耦合问题. ...
- learning scala PartialFunction
Partial函数的定义 scala> val isVeryTasty: PartialFunction[String, String] = { case "Glazed Donut& ...
- HDU4254 A Famous Game
luogu嘟嘟嘟 这题刚开始特别容易理解错:直接枚举所有\(n + 1\)种情况,然后算哪一种情况合法,再统计答案. 上述思想的问题就在于我们从已知的结果出发,默认这种每一种情况中取出\(q\)个红球 ...
- java1.8新特性之stream流式算法
在Java1.8之前还没有stream流式算法的时候,我们要是在一个放有多个User对象的list集合中,将每个User对象的主键ID取出,组合成一个新的集合,首先想到的肯定是遍历,如下: List& ...
- ROS手动编写服务端和客户端service demo(C++)
service demo 原理和 topic 通信方式很像 点击打开链接,因此 1.srv : 进入 service_demo 创建 srv 文件夹,创建 Greeting.srv,将以下代码插入: ...
- mutex,thread(c++11 windows linux三种方式)
一 c++11 windows linux三种方式 //#include <stdio.h> //#include <stdlib.h> //#include <uni ...
- git submodule subtree常用指令
submodule 官方文档 添加 git submodule add -b master git@git.xxx:xxx/xxx.git src/xxx 删除 git submodule deini ...
- python 迷宫问题
# -*- coding:utf- -*- from collections import deque # 引入队列 maze = [ [,,,,,,,,,], [,,,,,,,,,], [,,,,, ...