selenium反爬机制
使用selenium模拟浏览器进行数据抓取无疑是当下最通用的数据采集方案,它通吃各种数据加载方式,能够绕过客户JS加密,绕过爬虫检测,绕过签名机制。它的应用,使得许多网站的反采集策略形同虚设。由于selenium不会在HTTP请求数据中留下指纹,因此无法被网站直接识别和拦截。
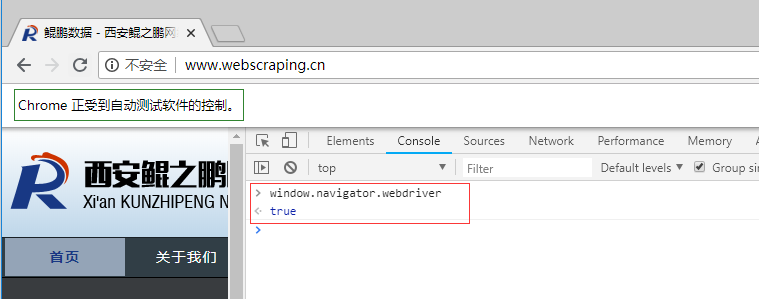
这是不是就意味着selenium真的就无法被网站屏蔽了呢?非也。selenium在运行的时候会暴露出一些预定义的Javascript变量(特征字符串),例如"window.navigator.webdriver",在非selenium环境下其值为undefined,而在selenium环境下,其值为true(如下图所示为selenium驱动下Chrome控制台打印出的值)。
除此之外,还有一些其它的标志性字符串(不同的浏览器可能会有所不同),常见的特征串如下所示:
- webdriver
- __driver_evaluate
- __webdriver_evaluate
- __selenium_evaluate
- __fxdriver_evaluate
- __driver_unwrapped
- __webdriver_unwrapped
- __selenium_unwrapped
- __fxdriver_unwrapped
- _Selenium_IDE_Recorder
- _selenium
- calledSelenium
- _WEBDRIVER_ELEM_CACHE
- ChromeDriverw
- driver-evaluate
- webdriver-evaluate
- selenium-evaluate
- webdriverCommand
- webdriver-evaluate-response
- __webdriverFunc
- __webdriver_script_fn
- __$webdriverAsyncExecutor
- __lastWatirAlert
- __lastWatirConfirm
- __lastWatirPrompt
- $chrome_asyncScriptInfo
- $cdc_asdjflasutopfhvcZLmcfl_
了解了这个特点之后,就可以在浏览器客户端JS中通过检测这些特征串来判断当前是否使用了selenium,并将检测结果附加到后续请求之中,这样服务端就能识别并拦截后续的请求。
下面讲一个具体的例子。
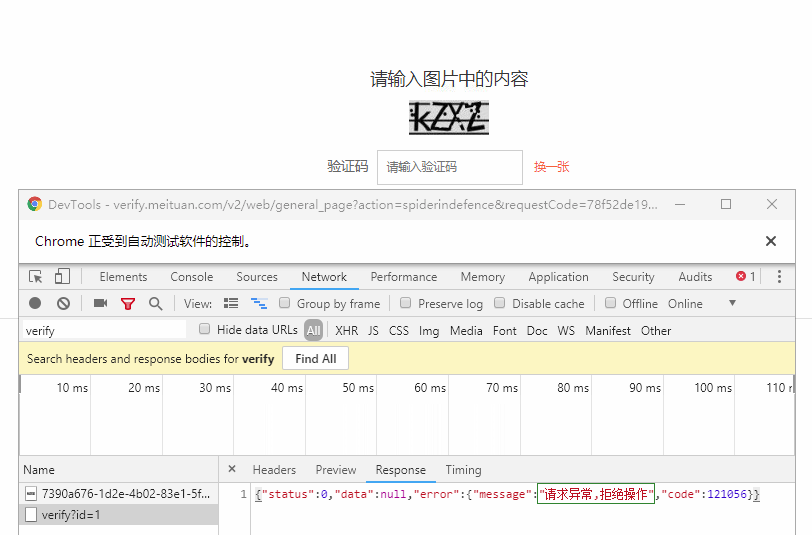
鲲之鹏的技术人员近期就发现了一个能够有效检测并屏蔽selenium的网站应用:大众点评网的验证码表单页,如果是正常的浏览器操作,能够有效的通过验证,但如果是使用selenium就会被识别,即便验证码输入正确,也会被提示“请求异常,拒绝操作”,无法通过验证(如下图所示)。
分析页面源码,可以找到 https://static.meituan.net/bs/yoda-static/file:file/d/js/yoda.e6e7c3988817eb17.js 这个JS文件,将代码格式化后,搜索webdriver可以看到如下代码:
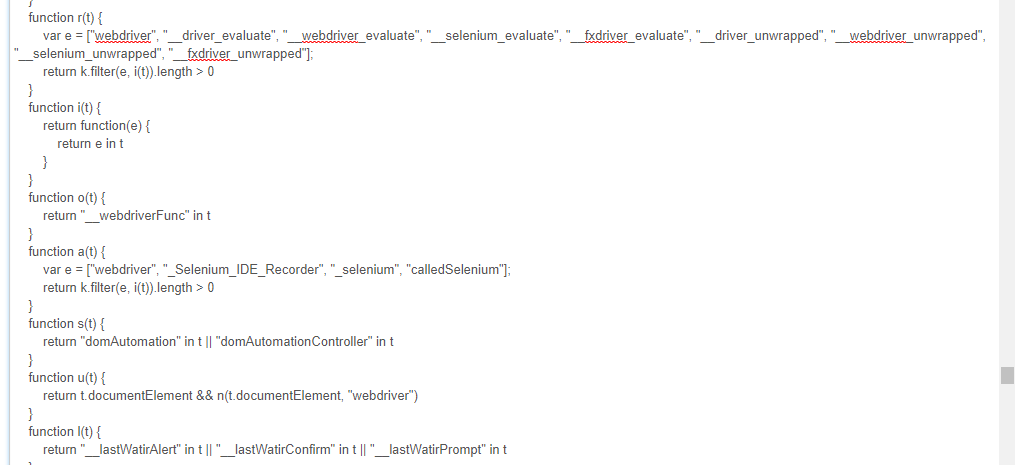
可以看到它检测了"webdriver", "__driver_evaluate", "__webdriver_evaluate"等等这些selenium的特征串。提交验证码的时候抓包可以看到一个_token参数(很长),selenium检测结果应该就包含在该参数里,服务端借以判断“请求异常,拒绝操作”。
现在才进入正题,如何突破网站的这种屏蔽呢?
我们已经知道了屏蔽的原理,只要我们能够隐藏这些特征串就可以了。但是还不能直接删除这些属性,因为这样可能会导致selenium不能正常工作了。我们采用曲线救国的方法,使用中间人代理,比如fidder, proxy2.py或者mitmproxy,将JS文件(本例是yoda.*.js这个文件)中的特征字符串给过滤掉(或者替换掉,比如替换成根本不存在的特征串),让它无法正常工作,从而达到让客户端脚本检测不到selenium的效果。
下面我们验证下这个思路。这里我们使用mitmproxy实现中间人代理),对JS文件(本例是yoda.*.js这个文件)内容进行过滤。启动mitmproxy代理并加载response处理脚本:
- mitmdump.exe -S modify_response.py
其中modify_response.py脚本如下所示:
- # coding: utf-8
- # modify_response.py
- import re
- from mitmproxy import ctx
- def response(flow):
- """修改应答数据
- """
- if '/js/yoda.' in flow.request.url:
- # 屏蔽selenium检测
- for webdriver_key in ['webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate', '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped', '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium', '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate', 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc', '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert', '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo', '$cdc_asdjflasutopfhvcZLmcfl_']:
- ctx.log.info('Remove "{}" from {}.'.format(webdriver_key, flow.request.url))
- flow.response.text = flow.response.text.replace('"{}"'.format(webdriver_key), '"NO-SUCH-ATTR"')
- flow.response.text = flow.response.text.replace('t.webdriver', 'false')
- flow.response.text = flow.response.text.replace('ChromeDriver', '')
在selnium中使用该代理(mitmproxy默认监听127.0.0.1:8080)访问目标网站,mitmproxy将过滤JS中的特征符串,如下图所示:
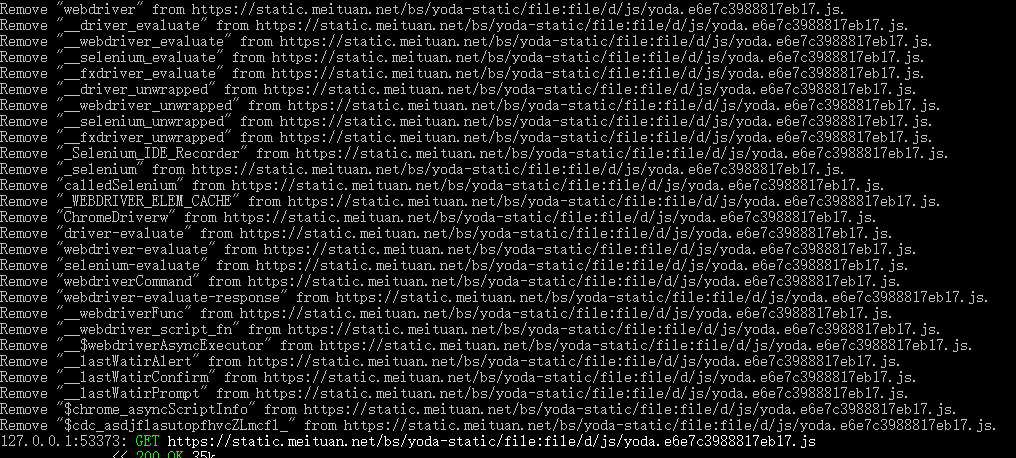
经多次测试,该方法可以有效的绕过大众点评的selenium检测,成功提交大众点评网的验证码表单。
selenium反爬机制的更多相关文章
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用.自动限速.自定义spider的settings,对抗反爬机制 cookie禁用 就是在Scrapy的配置文件set ...
- 用Nginx分流绕开Github反爬机制
用Nginx分流绕开Github反爬机制 0x00 前言 如果哪天有hacker进入到了公司内网为所欲为,你一定激动地以为这是一次蓄谋已久的APT,事实上,还有可能只是某位粗线条的员工把VPN信息泄露 ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题
python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题 一丶爬虫概述 通过编写程序'模拟浏览器'上网,然后通 ...
- Python爬虫实战——反爬机制的解决策略【阿里】
这一次呢,让我们来试一下"CSDN热门文章的抓取". 话不多说,让我们直接进入CSND官网. (其实是因为我被阿里的反爬磨到没脾气,不想说话--) 一.URL分析 输入" ...
- python爬虫破解带有RSA.js的RSA加密数据的反爬机制
前言 同上一篇的aes加密一样,也是偶然发现这个rsa加密的,目标网站我就不说了,保密. 当我发现这个网站是ajax加载时: 我已经习以为常,正在进行爬取时,发现返回为空,我开始用findler抓包, ...
- 破解另一家网站的反爬机制 & HMAC 算法
零.写在前面 本文涉及的反爬技术,仅供个人技术学习,禁止并做到: 干扰被访问网站的正常运行 抓取受到法律保护的特定类型的数据或信息 搜集到的数据禁止传播.交给第三方使用.或者牟利 如有可能,在爬到数据 ...
- 小白突破百度翻译反爬机制,33行Python代码实现汉译英小工具!
表弟17岁就没读书了,在我家呆了差不多一年吧. 呆的前几个月,每天上网打游戏,我又不好怎么在言语上管教他,就琢磨着看他要不要跟我学习Python编程.他开始问我Python编程什么?我打开了我给学生上 ...
- 二十八 Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
cookie禁用 就是在Scrapy的配置文件settings.py里禁用掉cookie禁用,可以防止被通过cookie禁用识别到是爬虫,注意,只适用于不需要登录的网页,cookie禁用后是无法登录的 ...
随机推荐
- javascript_14-对象
什么是对象 生活中的对象,一个车.一个手机 对象具有特性和行为 面向对象和基于对象 面向对象:可以创建自定义的类型.很好的支持继承和多态.面向对象的语言有 c++ .Java. C# ... 面向对象 ...
- [#Linux] CentOS 7 美化调优
优化美化系统,是为了让新系统能更顺眼顺手,符合自己过去在windows下的使用习惯,从而实现平稳过渡. 正如开篇时谈到的,现在的桌面版linux已相当友好(特别是Ubuntu),基本不需要做什么额外设 ...
- CSS之选择器相关
一.选择器的作用 选择器就是用来选择标签的,要使用css对HTML页面中的元素实现一对一,一对多或者多对一的控制,这就需要用到CSS选择器. HTML页面中的元素就是通过CSS选择器进行控制的.每一条 ...
- Python基础Day5
一.字典 ①字典是python的基础数据类型之一 ②字典可以存储大量的数据,关系型数据 ③字典也是python中唯一的映射类的数据类型 字典是以键值对的形式存在的,{键:值} 字典的键必须是不可变的数 ...
- Java--8--新特性--Stream API
Stream API 提供了一种高效且易于使用的处理数据的方式,(java.util.stream.*) 他可以对数组,集合等做一些操作,最终产生一个新的流,原数据是不会发生改变的. “集合”讲的是数 ...
- 系统API是原子操作吗?
系统API里面也会有简单的指令,类似于a++这种,我们认为的简单指令对应到汇编可能很多条.执行在其中某一条汇编的时候可能就切换进程了.切换进程可能发生在用户态(虚拟内存的用户空间),也可能发生在内核态 ...
- HDU_2717_Catch That Cow
很短的 BFS 队列 HDU_2717_Catch That Cow #include<iostream> #include<algorithm> #include<cs ...
- Vim使用技巧(5) -- 宏的录制与使用
想象一个场景,我们怎么快速把下面的所有链接都加上双引号?可能你手速快,可以很快的加完,但是如果链接有上万个呢?你如何在十秒以内加完? 这时候就需要用到“宏”(其实除了宏vim还有其它方法加上双引号,这 ...
- [转]对于BIO/NIO/AIO,你还只停留在烧开水的水平吗
原文:https://www.javazhiyin.com/40106.html https://coding.imooc.com/class/381.html ------------------- ...
- 第119题:杨辉三角II
一. 问题描述 给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行. 在杨辉三角中,每个数是它左上方和右上方的数的和. 示例: 输入: 3 输出: [1,3,3,1] 二. 解题思路 ...