《爬虫学习》(一)(HTTP协议)
Http请求:
1.在浏览器中发送一个http请求的过程:

2.url详解:
URL是Uniform Resource Locator的简写,统一资源定位符。 一个URL由以下几部分组成
scheme://host:port/path/?query-string=xxx#anchor
解析:

注意:写代码时,URL请求之中,中文必须转化为相对应的编码:%+16进制字符(例:何凯明=%E4%BD%95%E6%81%BA%E6%98%8E)
3.常用请求方法:
get请求:一般情况下,浏览器从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求。
post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用post请求。 以上是在网站开发中常用的两种方法。并且一般情况下都会遵循使用的原则。但是有的网站和服务器为了做反爬虫机制,也经常会不按常理出牌,有可能一个应该使用get方法的请求就一定要改成post请求,这个要视情况而定。
4.请求头以及参数:
在http协议中,向服务器发送一个请求,数据分为三部分,第一个是把数据放在url中,第二个是把数据放在body中(在post请求中),第三个就是把数据放在head中。这里介绍在网络爬虫中经常会用到的一些请求头参数:
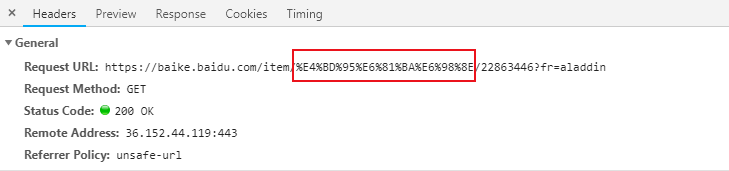
User-Agent:浏览器名称。这个在网络爬虫中经常会被使用到。请求一个网页的时候,服务器通过这个参数就可以知道这个请求是由哪种浏览器发送的。如果我们是通过爬虫发送请求,那么我们的User-Agent就是Python,这对于那些有反爬虫机制的网站来说,可以轻易的判断你这个请求是爬虫。因此我们要经常设置这个值为一些浏览器的值,来伪装我们的爬虫。
Referer:表明当前这个请求是从哪个url过来的。这个一般也可以用来做反爬虫技术。如果不是从指定页面过来的,那么就不做相关的响应。
Cookie:http协议是无状态的。也就是同一个人发送了两次请求,服务器没有能力知道这两个请求是否来自同一个人。因此这时候就用cookie来做标识。一般如果想要做登录后才能访问的网站,那么就需要发送cookie信息了。
5.状态码:

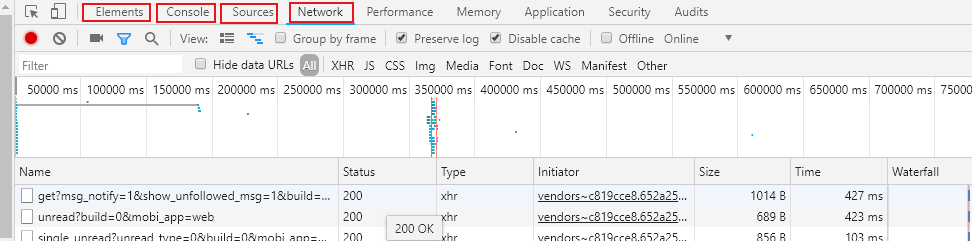
6.F12开发者工具:
Element整体布局
console一些js代码
source文件组成
network浏览器发送的请求
《爬虫学习》(一)(HTTP协议)的更多相关文章
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- HttpClient的使用-爬虫学习1
HttpClient的使用-爬虫学习(一) Apache真是伟大,为我们提供了HttpClient.jar,这个HttpClient是客户端的http通信实现库,这个类库的作用是接受和发送http报文 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- 爬虫学习之基于Scrapy的网络爬虫
###概述 在上一篇文章<爬虫学习之一个简单的网络爬虫>中我们对爬虫的概念有了一个初步的认识,并且通过Python的一些第三方库很方便的提取了我们想要的内容,但是通常面对工作当作复杂的需求 ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
随机推荐
- c++ 踩坑大法好 复合数据类型------vector
1,vector是啥? 是具有动态大小的数组,具有顺序.能够存放各种类型的对象.相比于固定长度的数组,运行效率稍微低一些,不过很方便. 2,咋用? 声明: vector <int> vi; ...
- 如何使用cmd操作数据库
1.首先用win+r输入cmd打开命令工具 (https://www.mysqlzh.com/=>'mysql中文文档地址') 然后用cd 命令进入你mysql的根目录 (bin目录下) 输入命 ...
- android studio编译包真机安装失败解决方案记录
Android studio升级到3.0之后,编译的APK文件无法在真机上安装,提示安装失败,最开始以为是API版本过高,与手机的版本不兼容,然后降低API,结果依然是安装失败. 然后连接手机,直接调 ...
- python爬虫匹配实现步骤
import requests,re url='https://movie.douban.com/top250' urlcontent=requests.get(url).text #正则 ''' 实 ...
- 0003 配置完整的url访问路径
本文本以OrgsAndUser APP为例,每增加一个url都需要做以下步骤: 1 创建模板 在OrgsAndUsers/Templates目录下创建一个名为org-home.html的文件,内容如下 ...
- vue+muse-ui
1.可以很好的配合vue2.0开发 2.安装: npm install muse-ui --save 3.引入: 在main.js中加入 import Vue from 'vue' import M ...
- 用html5自带表单验证 并且用ajax提交的解决方法(附例子)
用submit来提交表单,然后在js中监听submit方法,用ajax提交表单最后阻止submit的自动提交. 在标准浏览器中,阻止浏览器默认行为使用event.preventDefault(),而在 ...
- checkstyle配置规格说明
参考文献:https://blog.csdn.net/yang1982_0907/article/details/18086693?utm_source=blogxgwz1 https://blog. ...
- Virtual Judge POJ 3278 Catch That Cow
#include<iostream> #include<cstdio> #include<cstring> #include<cmath> #inclu ...
- 【C语言】利用二维数组输出成绩
目的:用二维数组输出下面成绩 希望你可以成为第五名童鞋! 代码: #include<stdio.h> int main() { /* 创建一个带有 4行 5 列的数组 */ ][] = { ...