6.7 Mapreduce作业流JobControl和Oozie
1.1 Mapreduce作业流JobControl和Oozie
更复杂的任务,需要多个mapreduce作业,形成作业流,而不是增加map和reduce的复杂度。复杂问题,可以用高级语言pig、hive、cascading、crunch、spark。
1.1.1 问题分解成mapreduce作业流
按天统计每天的最高气温,求出每月的最高气温平均值;再找出每年中平均气温最高的月,找出1901-2000年哪一年的哪一个月的平均气温最高。分解为mapreduce作业流。
Mapreduce作业1
(1) map计算出每天的最高气温;(日期,最高气温)
(2) reduce计算所有每月最高气温的平均值。
MapReduce作业2
(1) 找出每年平均气温最高的月。(年份月份,最高平均气温)
(2) 找出1901-2000年之间气温最高的年月。
1.1.2 JobControl控制作业流顺序
可以使用jobClient线性执行两个作业,并通过waitForcompletion()返回值判断执行是否成功。
JobClient.runJob(conf1);
JobClient.runJob(conf2);
还可以用org.apache.hadoop.mapreduce.jobcontrol包或者org.apache.hadoop.mapred.jobcontrol中的JobControl实例来控制执行顺序。可以查看进程和作业状态,错误信息。使用步骤
(1)作业1加入控制器
ControlledJob ctrljob1 = new ControlledJob(conf);
ctrljob1.setJob(job1);
(2)作业2加入控制器,并依赖于作业1
ControlledJob ctrljob2 = new ControlledJob(conf);
ctrljob2.setJob(job2);
// 设置多个作业直接的依赖关系,意思为job2的启动,依赖于job1作业的完成
ctrljob2.addDependingJob(ctrljob1);
(3) 作业3加入控制容器,并能个依赖于作业2
ControlledJob ctrljob3 = new ControlledJob(conf);
ctrljob3.setJob(job3);
ctrljob3.addDependingJob(ctrljob2);
(4)JobControl控制作业流
// 主的控制容器,控制上面的总的3个子作业
JobControl jobCtrl = new JobControl("myctrl");
// 添加到总的JobControl里,进行控制
jobCtrl.addJob(ctrljob1);
jobCtrl.addJob(ctrljob2);
jobCtrl.addJob(ctrljob3);
// 在线程启动,记住一定要有这个
Thread t = new Thread(jobCtrl);
t.start();
while (true)
{
if (jobCtrl.allFinished())
{// 如果作业成功完成,就打印成功作业的信息
System.out.println(jobCtrl.getSuccessfulJobList());
System.out.println("所有job执行完毕");
jobCtrl.stop();
break;
}
}
1.1.3 Apache Oozie工作流调度系统
http://oozie.apache.org/docs/5.0.0/index.html
Oozie是工作流调度系统,用于调度作业流按照复杂的顺序逻辑执行。先将作业组成工作流workflow,然后coordinate引擎用于协调多个工作流workflow执行。Bundle将多个coordinate进行汇总处理。Workflow->Coordinate->Bundle.
Oozie与支持多种类型的Hadoop作业(如Java map-reduce、流式map-reduce、Pig、Hive、Sqoop和Distcp)以及特定于系统的工作(如Java程序和shell脚本)。
作业流由actions 集合(例如Hadoop map/reduce作业,pig作业),actions被安排在一个控制依赖项DAG(Direct Acyclic Graph)中,按顺序执行。
|
workflow工作流 |
流式作业,将任务分解为hadoop作业(MapReduce,pig,Hive)。通过workflow.xml配置执行工作流。 |
|
coordinator引擎 |
周期性执行工作流或者控制相互依赖的workflow 作业流。 |
|
Bundle |
将多个coordinate进行汇总处理。 |
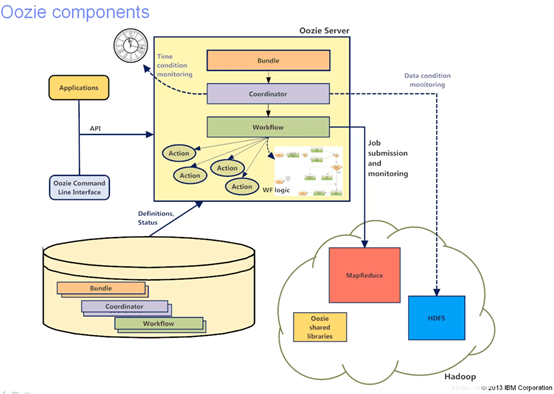
Oozie架构图
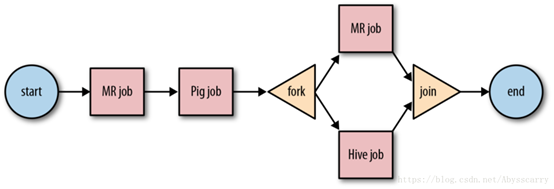
Workflow流程图
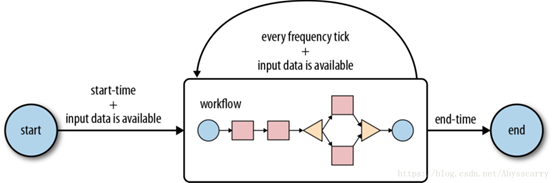
Coordinate流程图
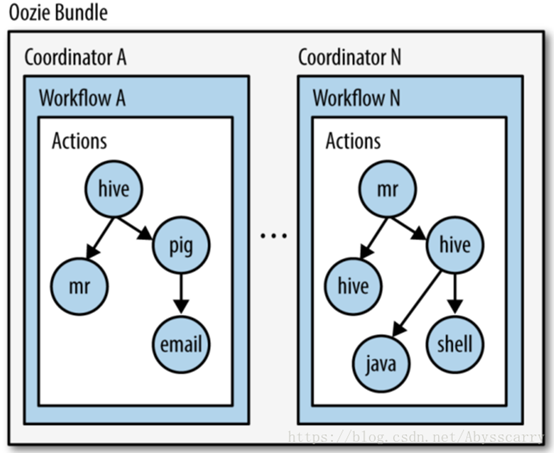
Bundle流程图
1.1.4 oozie工作流job组成
一个oozie 的 job 一般由以下文件组成:
job.properties :记录了job的属性,nameNode,jobTracker和 workflow.xml在hdfs中的位置必须设置。
workflow.xml :使用xml配置文件定义任务的流程和分支
lib目录:用来执行具体的任务。
(1)job.properties属性
|
KEY |
含义 |
|
nameNode |
HDFS地址 |
|
jobTracker |
jobTracker(ResourceManager)地址 |
|
queueName |
Oozie队列(默认填写default) |
|
examplesRoot |
全局目录(默认填写examples) |
|
oozie.usr.system.libpath |
是否加载用户lib目录(true/false) |
|
oozie.libpath |
用户lib库所在的位置 |
|
oozie.wf.application.path |
Oozie流程所在hdfs地址(workflow.xml所在的地址) |
|
user.name |
当前用户 |
|
oozie.coord.application.path |
Coordinator.xml地址(没有可以不写) |
|
oozie.bundle.application.path |
Bundle.xml地址(没有可以不写) |
实例如下
nameNode=hdfs://cm1:8020
jobTracker=cm1:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/workflow/oozie/shell
(2)workflow.xml
Workflow.xml定义了控制节点(start,kill,end)和动作节点action,控制节点控制流程的运行,动作节点定义了作业的任务。
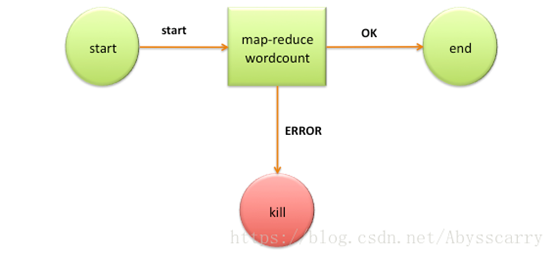
Wordcount的workflow.xml实例
<workflow-app name='wordcount-wf' xmlns="uri:oozie:workflow:0.1">
<start to='wordcount'/>
<action name='wordcount'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.myorg.WordCount.Map</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.myorg.WordCount.Reduce</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to='end'/>
<error to='end'/>
</action>
<kill name='kill'>
<message>Something went wrong: ${wf:errorCode('wordcount')}</message>
</kill/>
<end name='end'/>
</workflow-app>
(3)Lib目录:
在workflow工作流定义的同级目录下,需要有一个lib目录,在lib目录中存在java节点MapReduce使用的jar包。
需要注意的是,oozie并不是使用指定jar包的名称来启动任务的,而是通过指定主类来启动任务的。在lib包中绝对不能存在某个jar包的不同版本,不能够出现多个相同主类。
(4)执行作业流
将job.properties、workflow.xml和lib文件夹放在用户名的目录(${namenode}/user/${user.name})下的max-temp-workflow,复制到HDFS.
%hadoop fs –put Hadoop-examples/target/max-temp-workflow max-temp-workflow.
使用oozie命令行工具设置环境变量OOZIE_URL指定Oozie服务器
%export OOZIE_URL=”http://localhsot:11000/oozie”
运行工作流
% oozie job –config ch06-mr-dev/max-temp-workflow.preoperties –run job:0001-121
–config设置工作流属性文件,内含namenode、资源管理器地址、作业路径(oozie.wf.application.path=${namenode}/user/${user.name}/max-temp-workflow)
-run 参数用于运行指定的作业。
通过-info查看作业状态
%oozie job –info 0001-121
6.7 Mapreduce作业流JobControl和Oozie的更多相关文章
- MapReduce使用JobControl管理实例
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; impo ...
- (转)多个mapreduce工作相互依赖处理方法完整实例(JobControl)
多个mapreduce工作相互依赖处理方法完整实例(JobControl) 原文地址:http://mntms.iteye.com/blog/2096456?utm_source=tuicool&am ...
- 使用JobControl控制MapReduce任务
代码结构 BeanWritable:往数据库读写使用的bean ControlJobTest:JobControl任务控制 DBInputFormatApp:将关系型数据库的数据导入HDFS,其中包含 ...
- 【Hadoop离线基础总结】oozie调度MapReduce任务
目录 1.准备MR执行的数据 2.执行官方测试案例 3.准备我们调度的资源 4.修改配置文件 5.上传调度任务到hdfs对应目录 6.执行调度任务 1.准备MR执行的数据 MR的程序可以是自己写的,也 ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
- (转)MapReduce Design Patterns(chapter 6 (part 1))(十一)
Chapter 6. Metapatterns 这种模式不是解决某个问题的,而是处理模式的关系的.可以理解为“模式的模式”.首先讨论的是job链,把几个模式联合起来解决复杂的,有多个阶段要处理的问题. ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- Apriori on MapReduce
Apiroi算法在Hadoop MapReduce上的实现 输入格式: 一行为一个Bucket 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 34 36 38 ...
- MapReduce实例-NASA博客数据频度简单分析
环境: Hadoop1.x,CentOS6.5,三台虚拟机搭建的模拟分布式环境,gnuplot, 数据:http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.htm ...
随机推荐
- @hdu - 6427@ Problem B. Beads
目录 @description@ @solution@ @accepted code@ @details@ @description@ 有 m 种不同颜色的珠子,颜色分别为 1~m,每一种颜色的珠子有 ...
- Android 使用ViewPager结合PhotoView开源组件实现网络图片在线浏览功能
在实际的开发中,我们市场会遇到这样的情况:点击某图片,浏览某列表(某列表详情)中的所有图片数据,当然,这些图片是可以放大和缩小的,比如我们看下百度贴吧的浏览大图的效果: 链接 这种功能,在一些app ...
- E - Count on a tree 树上第K小
主席树的入门题目,这道题的题意其实就是说,给你一棵树,询问在两个节点之间的路径上的区间第K小 我们如何把树上问题转换为区间问题呢? 其实DFS就可以,我们按照DFS的顺序,对线段树进行建树,那么这个树 ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
- poj 1514 Metal Cutting (dfs+多边形切割)
1514 -- Metal Cutting 一道类似于半平面交的题. 题意相当简单,给出一块矩形以及最后被切出来的的多边形各个顶点的位置.每次切割必须从一端切到另一端,问切出多边形最少要切多长的距离. ...
- tf.variable_scope 参数
最近在看TensorFlow的变量管理,发现很多代码中tf.variable_scope()参数的数量及意义还不太清楚,特此记录: def __init__(self, name_or_scope, ...
- CodeForces 1243"Character Swap (Hard Version)"(multimap)
传送门 •前置知识-multimap的用法 $multimap$ 与 $map$ 的区别在于一个 $key$ 可以对应几个值: 对于 $map$ 而言,一个 $key$ 只能对应一个值,并且按照 $k ...
- notepad2正则表达式替换字符串
例子: 1-385-463-3226替换成13854633226 Ctrl+H开启替换,选中'regular expression search'或者正则表达式: 上面输入:1-(.*)-(.*)-( ...
- linux scull 中的设备注册
在内部, scull 使用一个 struct scull_dev 类型的结构表示每个设备. 这个结构定义为: struct scull_dev { struct scull_qset *data; ...
- 2018-8-10-WPF-程序生成类库错误
title author date CreateTime categories WPF 程序生成类库错误 lindexi 2018-08-10 19:16:53 +0800 2018-2-13 17: ...