AdaBoost笔记之通俗易懂原理介绍
转自:https://blog.csdn.net/px_528/article/details/72963977
写在前面
说到Adaboost,公式与代码网上到处都有,《统计学习方法》里面有详细的公式原理,Github上面有很多实例,那么为什么还要写这篇文章呢?希望从一种更容易理解的角度,来为大家呈现Adaboost算法的很多关键的细节。
本文中暂时没有讨论其数学公式,一些基本公式可以参考《统计学习方法》。
基本原理
Adaboost算法基本原理就是将多个弱分类器(弱分类器一般选用单层决策树)进行合理的结合,使其成为一个强分类器。
Adaboost采用迭代的思想,每次迭代只训练一个弱分类器,训练好的弱分类器将参与下一次迭代的使用。也就是说,在第N次迭代中,一共就有N个弱分类器,其中N-1个是以前训练好的,其各种参数都不再改变,本次训练第N个分类器。其中弱分类器的关系是第N个弱分类器更可能分对前N-1个弱分类器没分对的数据,最终分类输出要看这N个分类器的综合效果。
弱分类器(单层决策树)
Adaboost一般使用单层决策树作为其弱分类器。单层决策树是决策树的最简化版本,只有一个决策点,也就是说,如果训练数据有多维特征,单层决策树也只能选择其中一维特征来做决策,并且还有一个关键点,决策的阈值也需要考虑。
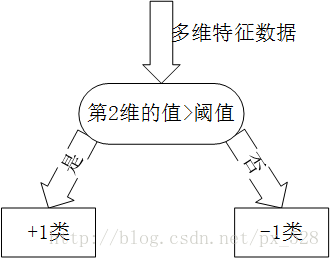
关于单层决策树的决策点,来看几个例子。比如特征只有一个维度时,可以以小于7的分为一类,标记为+1,大于(等于)7的分为另一类,标记为-1。当然也可以以13作为决策点,决策方向是大于13的分为+1类,小于(等于)13的分为-1类。在单层决策树中,一共只有一个决策点,所以下图的两个决策点不能同时选取。
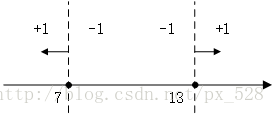
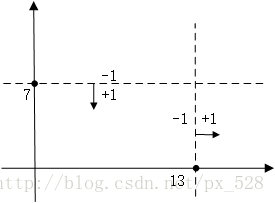
同样的道理,当特征有两个维度时,可以以纵坐标7作为决策点,决策方向是小于7分为+1类,大于(等于)7分类-1类。当然还可以以横坐标13作为决策点,决策方向是大于13的分为+1类,小于13的分为-1类。在单层决策树中,一共只有一个决策点,所以下图的两个决策点不能同时选取。
扩展到三维、四维、N维都是一样,在单层决策树中,一共只有一个决策点,所以只能在其中一个维度中选择一个合适的决策阈值作为决策点。
关于Adaboost的两种权重
Adaboost算法中有两种权重,一种是数据的权重,另一种是弱分类器的权重。其中,数据的权重主要用于弱分类器寻找其分类误差最小的决策点,找到之后用这个最小误差计算出该弱分类器的权重(发言权),分类器权重越大说明该弱分类器在最终决策时拥有更大的发言权。
Adaboost数据权重与弱分类器
刚刚已经介绍了单层决策树的原理,这里有一个问题,如果训练数据保持不变,那么单层决策树找到的最佳决策点每一次必然都是一样的,为什么呢?因为单层决策树是把所有可能的决策点都找了一遍然后选择了最好的,如果训练数据不变,那么每次找到的最好的点当然都是同一个点了。
所以,这里Adaboost数据权重就派上用场了,所谓“数据的权重主要用于弱分类器寻找其分类误差最小的点”,其实,在单层决策树计算误差时,Adaboost要求其乘上权重,即计算带权重的误差。
举个例子,在以前没有权重时(其实是平局权重时),一共10个点时,对应每个点的权重都是0.1,分错1个,错误率就加0.1;分错3个,错误率就是0.3。现在,每个点的权重不一样了,还是10个点,权重依次是[0.01,0.01,0.01,0.01,0.01,0.01, 0.01,0.01,0.01,0.91],如果分错了第1一个点,那么错误率是0.01,如果分错了第3个点,那么错误率是0.01,要是分错了最后一个点,那么错误率就是0.91。这样,在选择决策点的时候自然是要尽量把权重大的点(本例中是最后一个点)分对才能降低误差率。由此可见,权重分布影响着单层决策树决策点的选择,权重大的点得到更多的关注,权重小的点得到更少的关注。
在Adaboost算法中,每训练完一个弱分类器都就会调整权重,上一轮训练中被误分类的点的权重会增加,在本轮训练中,由于权重影响,本轮的弱分类器将更有可能把上一轮的误分类点分对,如果还是没有分对,那么分错的点的权重将继续增加,下一个弱分类器将更加关注这个点,尽量将其分对。
这样,达到“你分不对的我来分”,下一个分类器主要关注上一个分类器没分对的点,每个分类器都各有侧重。
Adaboost分类器的权重
由于Adaboost中若干个分类器的关系是第N个分类器更可能分对第N-1个分类器没分对的数据,而不能保证以前分对的数据也能同时分对。所以在Adaboost中,每个弱分类器都有各自最关注的点,每个弱分类器都只关注整个数据集的中一部分数据,所以它们必然是共同组合在一起才能发挥出作用。所以最终投票表决时,需要根据弱分类器的权重来进行加权投票,权重大小是根据弱分类器的分类错误率计算得出的,总的规律就是弱分类器错误率越低,其权重就越高。
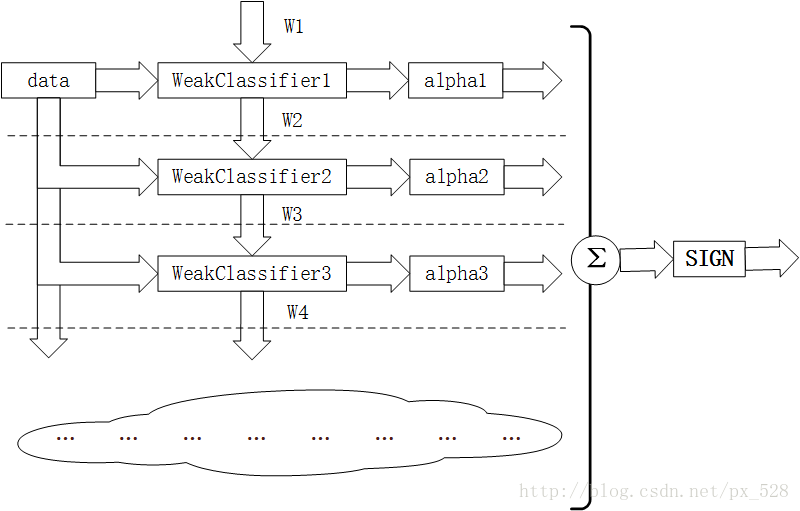
图解Adaboost分类器结构
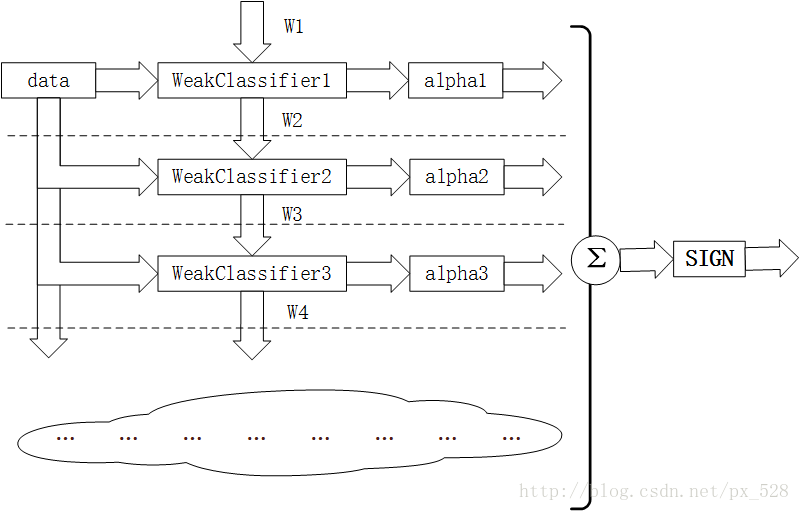
如图所示为Adaboost分类器的整体结构。从右到左,可见最终的求和与符号函数,再看到左边求和之前,图中的虚线表示不同轮次的迭代效果,第1次迭代时,只有第1行的结构,第2次迭代时,包括第1行与第2行的结构,每次迭代增加一行结构,图下方的“云”表示不断迭代结构的省略。
第i轮迭代要做这么几件事:
1. 新增弱分类器WeakClassifier(i)与弱分类器权重alpha(i)
2. 通过数据集data与数据权重W(i)训练弱分类器WeakClassifier(i),并得出其分类错误率,以此计算出其弱分类器权重alpha(i)
3. 通过加权投票表决的方法,让所有弱分类器进行加权投票表决的方法得到最终预测输出,计算最终分类错误率,如果最终错误率低于设定阈值(比如5%),那么迭代结束;如果最终错误率高于设定阈值,那么更新数据权重得到W(i+1)
图解Adaboost加权表决结果
关于最终的加权投票表决,举几个例子:
比如在一维特征时,经过3次迭代,并且知道每次迭代后的弱分类器的决策点与发言权,看看如何实现加权投票表决的。
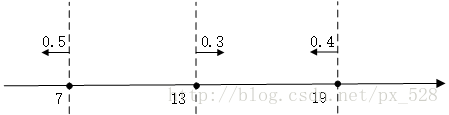
如图所示,3次迭代后得到了3个决策点,
最左边的决策点是小于(等于)7的分为+1类,大于7的分为-1类,且分类器的权重为0.5;
中间的决策点是大于(等于)13的分为+1类,小于13分为-1类,权重0.3;
最右边的决策点是小于(等于19)的分为+1类,大于19分为-1类,权重0.4。
对于最左边的弱分类器,它的投票表示,小于(等于)7的区域得0.5,大与7得-0.5,同理对于中间的分类器,它的投票表示大于(等于)13的为0.3,小于13分为-0.3,最右边的投票结果为小于(等于19)的为0.4,大于19分为-0.4,如下图:
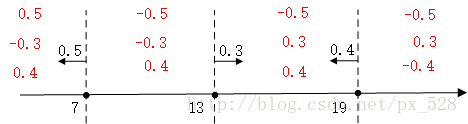
求和可得:
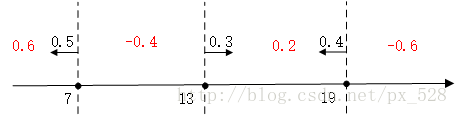
最后进行符号函数转化即可得到最终分类结果:
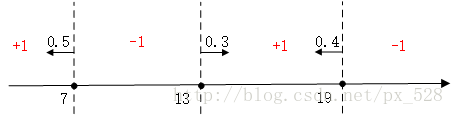
更加直观的,来看一个更复杂的例子。对于二维也是一样,刚好有一个实例可以分析一下,原始数据分布如下图:
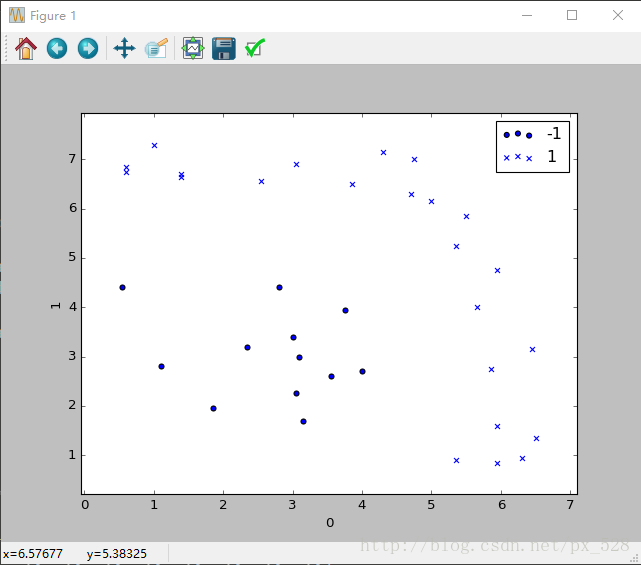
Adaboost分类器试图把两类数据分开,运行一下程序,显示出决策点,如下图:
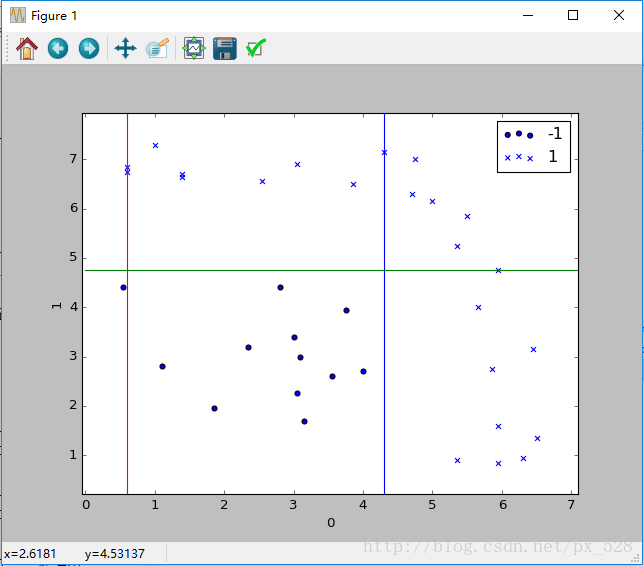
这样一看,似乎是分开了,不过具体参数是怎样呢?查看程序的输出,可以得到如其决策点与弱分类器权重,在图中标记出来如下:
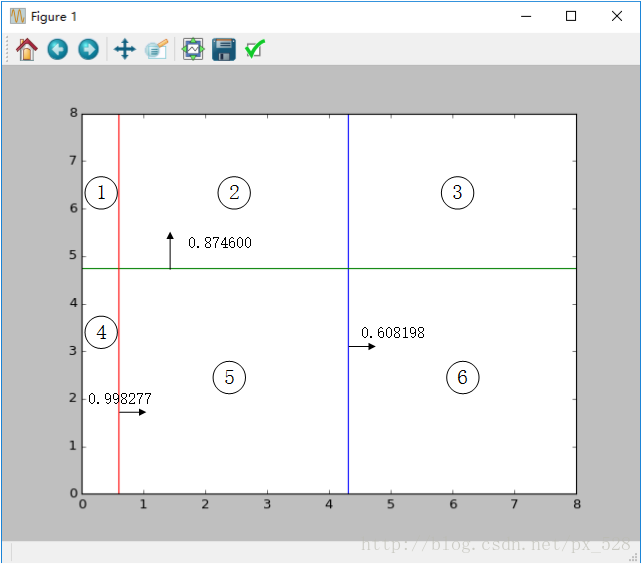
图中被分成了6分区域,每个区域对应的类别就是:
1号:sign(-0.998277+0.874600-0.608198)=-1
2号:sign(+0.998277+0.874600-0.608198)=+1
3号:sign(+0.998277+0.874600+0.608198)=+1
4号:sign(-0.998277-0.874600-0.608198)=-1
5号:sign(+0.998277-0.874600-0.608198)=-1
6号:sign(+0.998277-0.874600+0.608198)=+1
其中sign(x)是符号函数,正数返回1负数返回-1。
最终得到如下效果:
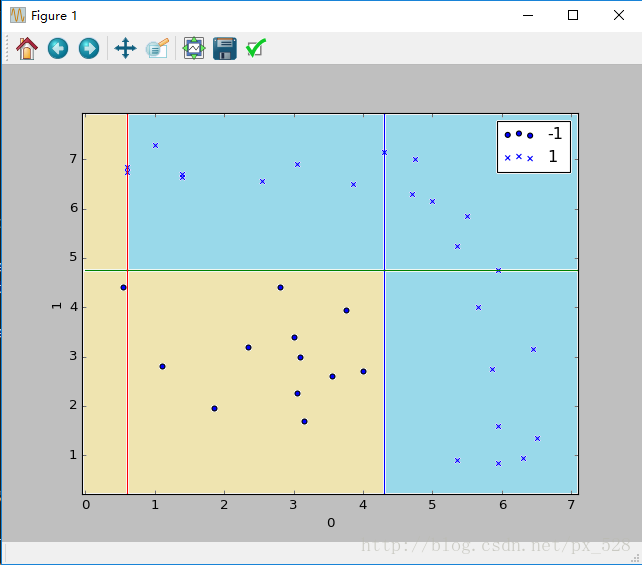
通过这两个例子,相信你已经明白了Adaboost算法加权投票时怎么回事儿了。
总结
说了这么多,也举了这么多例子,就是为了让你从细节上明白Adaboost的基本原理,博主认为理解Adaboost的两种权重的关系是理解Adaboost算法的关键所在。
所有代码可以在Github上找到:
https://github.com/px528/AdaboostExample
AdaBoost笔记之通俗易懂原理介绍的更多相关文章
- elasticsearch学习笔记--原理介绍
前言:上一篇中我们对ES有了一个比较大概的概念,知道它是什么,干什么用的,今天给大家主要讲一下他的工作原理 介绍:ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户 ...
- Java基础笔记 – Annotation注解的介绍和使用 自定义注解
Java基础笔记 – Annotation注解的介绍和使用 自定义注解 本文由arthinking发表于5年前 | Java基础 | 评论数 7 | 被围观 25,969 views+ 1.Anno ...
- Python源代码剖析笔记3-Python运行原理初探
Python源代码剖析笔记3-Python执行原理初探 本文简书地址:http://www.jianshu.com/p/03af86845c95 之前写了几篇源代码剖析笔记,然而慢慢觉得没有从一个宏观 ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- 03 Yarn 原理介绍
Yarn 原理介绍 大纲: Hadoop 架构介绍 YARN 产生的背景 YARN 基础架构及原理 Hadoop的1.X架构的介绍 在1.x中的NameNodes只可能有一个,虽然可以通过Se ...
- 04 MapReduce原理介绍
大数据实战(上) # MapReduce原理介绍 大纲: * Mapreduce介绍 * MapReduce2运行原理 * shuffle及排序 定义 * Mapreduce 最早是由googl ...
- Android Animation学习(一) Property Animation原理介绍和API简介
Android Animation学习(一) Property Animation介绍 Android Animation Android framework提供了两种动画系统: property a ...
- [转]MySQL主从复制原理介绍
MySQL主从复制原理介绍 一.复制的原理 MySQL 复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新.删除等等).每个从服务器从主服务器接收主服务器已经记录到其二进制日志的保存的更新,以 ...
- 分布式文件系统FastDFS原理介绍
在生产中我们一般希望文件系统能帮我们解决以下问题,如:1.超大数据存储:2.数据高可用(冗余备份):3.读/写高性能:4.海量数据计算.最好还得支持多平台多语言,支持高并发. 由于单台服务器无法满足以 ...
随机推荐
- thinkcmf链接多个数据库
1.打开/data/conf/config.php 'db1'=>[ // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '', / ...
- lua 线程
{ //https://blog.csdn.net/gulan0/article/details/50373276 }
- 基础(三):yum(RedHat系列)和apt-get(Debian系列 )用法及区别
文章转载来自:http://blog.csdn.net/chengly0129/article/details/70169760 一般来说著名的linux系统基本上分两大类:1.RedHat系列:Re ...
- Linux shell脚本编程if语句的使用方法(条件判断)
if 语句格式if 条件then Commandelse Commandfi 别忘了这个结尾If语句忘了结尾fitest.sh: line 14: syntax error: unex ...
- webstorm使用说明
1.移动光标到的代码块的结尾处(开始处 [ ) ctrl+] 2.移动光标到的代码块的结尾处并选择 ctrl+shift+] 3.ctrl + b: 跳到变量申明处 4.多光标输入: ...
- 16. Jmeter-监听器
jmeter-监听器介绍与使用 察看结果树 Summary Report 聚合报告 Backend Listener Aggregate Graph 断言结果 Comparison Assertion ...
- Linux两台机器简历信任
cd ~/.ssh ssh-keygen -t rsa scp ./id_rsa.pub root@192.168.1.1:/root/.ssh/authorized_keys
- 剑指offer——70n个骰子的点数
题目: 把n个骰子扔在地上,所有骰子朝上一面的点数之和为s.输入n,打印出s的所有可能的值出现的概率. 题解: 使用两个数组存每次投的点数 void theProbability(const int ...
- 某个ip段可以访问mysql
我们先创建一个测试用户LimitIP,只允许192.168段的IP地址访问,具体权限如下所示: mysql> GRANT SELECT ON MyDB.* TO LimitIP@'192.168 ...
- 大道浮屠诀---NBU7.7.3_oracle11G单机-单机(异机恢复WINDOWS2008平台)
现有环境说明: 一台WINDOWS2008R2:安装有NBU7.7.3,作为服务端 一台WINDOWS2008R2:安装有oracle11.2.0.3,作为数据库服务器 现假设数据库意外崩溃,需要进行 ...