手写数字识别——基于LeNet-5卷积网络模型
在《手写数字识别——利用Keras高层API快速搭建并优化网络模型》一文中,我们搭建了全连接层网络,准确率达到0.98,但是这种网络的参数量达到了近24万个。本文将搭建LeNet-5网络,参数仅有6万左右,该网络是由Yann LeCun在1998年提出,是历史上第一代卷积神经网络。关于其历史可阅读另一篇博客《冬日曙光——回溯CNN的诞生》。
模型结构
LeNet-5提出至今过去了很久,因此其中的很多算法都已经被代替,因此本文所建网络与LeNet-5会有所差异。LeNet-5结构如下图所示,原结构可简单概括为:
input(32*32*1)->Conv(28*28*6)->tanh->AvgPool(14*14*6)->tanh->(局部通道连接)Conv(10*10*16)->tanh->AvgPool(5*5*16)->tanh->Conv(1*1*120)->tanh->fc(84)->RBF->out(10)
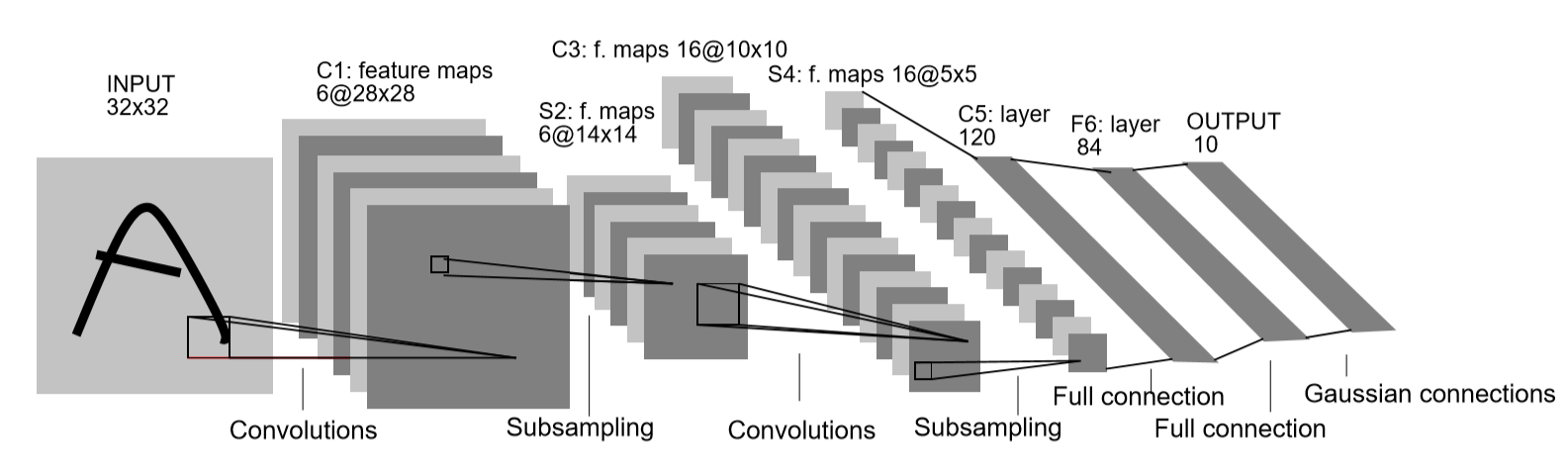
本文采用的结构为:
input(28*28*1)->Conv(28*28*6)->ReLu->MaxPool(14*14*6)->Conv(10*10*16)->ReLu->MaxPool(5*5*16)->Conv(1*1*120)->ReLu->fc(84)->out(10)
数据导入与预处理
跟全连接网络的预处理不同,这里的预处理有以下三个变化:
1.输入采用了z-score 标准化,使均值约为0,标准差约为1。过程类似于将正态分布进行标准化一样。实际证明,这种方法比之前直接除以255收敛更快、准确度更高。
2.不需要将输入打平,而且还得填充1个维度作为通道,目的是使shape符合输入层维度。
3.标签值编成独热码后,还需扩充两个维度,可以跟输出层维度数相同。
标准化需要用到均值函数np.mean(a,axis=None,dtype=None)和标准差函数np.std(a,axis=None,dtype=None)。数据导入和预处理代码如下:
import tensorflow as tf
import numpy as np
from tensorflow.keras import datasets,optimizers,Sequential,layers,metrics #数据预处理
def preprocess(x,y):
#z-score 标准化
x = (tf.cast(x,dtype=tf.float32)-mean)/std
x = tf.reshape(x,(-1,28,28,1))
y = tf.one_hot(y,depth=10,dtype=tf.int32)
y = tf.reshape(y,(-1,1,1,10))
return x,y #加载mnist数据
#trian_x -> shape(60k,28,28) val_x -> shape(10k,28,28)
#trian_y -> shape(60k,10) val_y -> shape(10k,10)
(train_x,train_y),(val_x,val_y) = datasets.mnist.load_data()
mean = np.mean(train_x)
std = np.std(train_x) #生成Dataset对象
#bacthx -> shape(128,28,28) dtype=tf.uint8
#bacthy -> shape(128,10) dtype=tf.uint8
train_db = tf.data.Dataset.from_tensor_slices((train_x,train_y)).shuffle(1000).batch(128)
val_db = tf.data.Dataset.from_tensor_slices((val_x,val_y)).shuffle(1000).batch(128) #特征缩放、独热码处理
train_db = train_db.map(preprocess)
val_db = val_db.map(preprocess)
模型构建
生成卷积层需要使用layers.Conv2D(filters,kernel_size,strides=(1,1),padding="valid",activation),其中filters表示输出通道数(滤波器数量),kernel_size为滤波器大小,strides为卷积步长,padding为边界处理方式(valid表示不进行边界扩展,same表示进行边界扩展),activation一般选择ReLu。
生成池化层需要使用layers.MaxPool2D(pool_size,strides,padding="valid"),一般习惯把MaxPool的padding设为“same”,通过步长来控制缩小倍数。在这里步长为2,每次池化都会将大小减半。
MNIST数据集图片大小为28*28,为了跟LeNet保持一致,第一层卷积没有改变大小,因此padding设为"same"。我把所有全连接层用卷积形式代替了,这样可以避免卷积层输出和全连接层输入之间维度的差异(卷积输出需要被打平),从而可以用一个Sequential容器装下所有神经层。
模型构建代码如下:
model = Sequential([
#input -> shape(128,28,28,1)
#C1 -> shape(128,28,28,6)
layers.Conv2D(6,kernel_size=5,strides=1,padding='same',activation=tf.nn.relu),
#S2 -> shape(128,14,14,6)
layers.MaxPool2D(pool_size=(2,2),strides=2,padding='same'), #C3 -> shape(128,10,10,16)
layers.Conv2D(16,kernel_size=5,strides=1,activation=tf.nn.relu),
#S4 -> shape(128,5,5,16)
layers.MaxPool2D(pool_size=(2,2),strides=2,padding='same'), #C5 -> shape(128,1,1,120)
layers.Conv2D(120,kernel_size=5,strides=1,activation=tf.nn.relu), #卷积转到全连接维数不对应导致不能训练
# #F6 ->shape(128,84)
# layers.Dense(84,activation=tf.nn.relu),
# #output ->shape(128,10)
# layers.Dense(10) #F6 ->shape(128,1,1,84)
layers.Conv2D(84,kernel_size=1,strides=1,activation=tf.nn.relu),
#output ->shape(128,1,1,10)
layers.Conv2D(10,kernel_size=1,strides=1) ]) model.build(input_shape=(None,28,28,1))
model.summary()
模型的训练
LeNet-5当时使用的是随机梯度下降和分段学习率,现在更多都交给Adam了。这里给出了两种实现,一种利用fit的回调进行手动学习率调整,可能需要花点时间调参,另一种则使用Adam自动管理。在SGD下,因为是随机取样,所以Loss相对较小,需要比较大的学习率。
当年LeNet-5迭代20次后收敛,准确率可以达到0.9905。本文SGD版在迭代12次后能达到0.9900水平,在18次时收敛,准确率稳定在0.9917;Adam版在迭代20次收敛于0.9892。也就是说,在普遍使用Adam的今天,SGD(TensorFlow里SGD经过了动量的优化)也是值得一试的。
Adam版:
model.compile(optimizer=optimizers.Adam(),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(train_db,epochs=15,validation_data=val_db,validation_freq=1)
SGD+分段学习率版:
def scheduler(epoch):
if epoch < 10:
return 0.1
else:
return 0.1 * np.exp(0.2 * (10 - epoch))#新建LearningRateScheduler对象
callback = tf.keras.callbacks.LearningRateScheduler(scheduler,verbose=1) model.compile(optimizer=optimizers.SGD(),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(train_db,epochs=20,validation_data=val_db,validation_freq=1,callback
完整代码
import tensorflow as tf
import numpy as np
from tensorflow.keras import datasets,optimizers,Sequential,layers,metrics #数据预处理
def preprocess(x,y):
#z-score 标准化
x = (tf.cast(x,dtype=tf.float32)-mean)/std
x = tf.reshape(x,(-1,28,28,1))
y = tf.one_hot(y,depth=10,dtype=tf.int32)
y = tf.reshape(y,(-1,1,1,10))
return x,y #加载mnist数据
#trian_x -> shape(60k,28,28) val_x -> shape(10k,28,28)
#trian_y -> shape(60k,10) val_y -> shape(10k,10)
(train_x,train_y),(val_x,val_y) = datasets.mnist.load_data()
mean = np.mean(train_x)
std = np.std(train_x) #生成Dataset对象
#bacthx -> shape(128,28,28) dtype=tf.uint8
#bacthy -> shape(128,10) dtype=tf.uint8
train_db = tf.data.Dataset.from_tensor_slices((train_x,train_y)).shuffle(1000).batch(128)
val_db = tf.data.Dataset.from_tensor_slices((val_x,val_y)).shuffle(1000).batch(128) #特征缩放、独热码处理
train_db = train_db.map(preprocess)
val_db = val_db.map(preprocess) model = Sequential([
#input -> shape(128,28,28,1)
#C1 -> shape(128,28,28,6)
layers.Conv2D(6,kernel_size=5,strides=1,padding='same',activation=tf.nn.relu),
#S2 -> shape(128,14,14,6)
layers.MaxPool2D(pool_size=(2,2),strides=2,padding='same'), #C3 -> shape(128,10,10,16)
layers.Conv2D(16,kernel_size=5,strides=1,activation=tf.nn.relu),
#S4 -> shape(128,5,5,16)
layers.MaxPool2D(pool_size=(2,2),strides=2,padding='same'), #C5 -> shape(128,1,1,120)
layers.Conv2D(120,kernel_size=5,strides=1,activation=tf.nn.relu), #F6 ->shape(128,1,1,84)
layers.Conv2D(84,kernel_size=1,strides=1,activation=tf.nn.relu),
#output ->shape(128,1,1,10)
layers.Conv2D(10,kernel_size=1,strides=1) ]) model.build(input_shape=(None,28,28,1))
model.summary() #Adam版
# model.compile(optimizer=optimizers.Adam(),
# loss=tf.losses.CategoricalCrossentropy(from_logits=True),
# metrics=['accuracy'])
# model.fit(train_db,epochs=20,validation_data=val_db,validation_freq=1) #SGD版
def scheduler(epoch):
if epoch < 10:
return 0.1
else:
return 0.1 * np.exp(0.2 * (10 - epoch)) # #新建LearningRateScheduler对象
callback = tf.keras.callbacks.LearningRateScheduler(scheduler,verbose=1) model.compile(optimizer=optimizers.SGD(),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(train_db,epochs=20,validation_data=val_db,validation_freq=1,callbacks=[callback])
手写数字识别——基于LeNet-5卷积网络模型的更多相关文章
- MINST手写数字识别(二)—— 卷积神经网络(CNN)
今天我们的主角是keras,其简洁性和易用性简直出乎David 9我的预期.大家都知道keras是在TensorFlow上又包装了一层,向简洁易用的深度学习又迈出了坚实的一步. 所以,今天就来带大家写 ...
- linux-基于tensorflow2.x的手写数字识别-基于MNIST数据集
数据集 数据集下载MNIST 首先读取数据集, 并打印相关信息 包括 图像的数量, 形状 像素的最大, 最小值 以及看一下第一张图片 path = 'MNIST/mnist.npz' with np. ...
- TensorFlow 卷积神经网络手写数字识别数据集介绍
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 手写数字识别 接下来将会以 MNIST 数据集为例,使用卷积层和池 ...
- 手写数字识别 ----卷积神经网络模型官方案例注释(基于Tensorflow,Python)
# 手写数字识别 ----卷积神经网络模型 import os import tensorflow as tf #部分注释来源于 # http://www.cnblogs.com/rgvb178/p/ ...
- 【深度学习系列】手写数字识别卷积神经--卷积神经网络CNN原理详解(一)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- 手写数字识别 ----在已经训练好的数据上根据28*28的图片获取识别概率(基于Tensorflow,Python)
通过: 手写数字识别 ----卷积神经网络模型官方案例详解(基于Tensorflow,Python) 手写数字识别 ----Softmax回归模型官方案例详解(基于Tensorflow,Pytho ...
- 学习笔记CB009:人工神经网络模型、手写数字识别、多层卷积网络、词向量、word2vec
人工神经网络,借鉴生物神经网络工作原理数学模型. 由n个输入特征得出与输入特征几乎相同的n个结果,训练隐藏层得到意想不到信息.信息检索领域,模型训练合理排序模型,输入特征,文档质量.文档点击历史.文档 ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- [Python]基于CNN的MNIST手写数字识别
目录 一.背景介绍 1.1 卷积神经网络 1.2 深度学习框架 1.3 MNIST 数据集 二.方法和原理 2.1 部署网络模型 (1)权重初始化 (2)卷积和池化 (3)搭建卷积层1 (4)搭建卷积 ...
随机推荐
- 在家想自学Java,有C语言底子,请问哪本书适合?
一.问题剖析 看到这个问题,我想吹水两句再做推荐.一般发出这个疑问都处在初学编程阶段,编程语言都是相通的,只要你领悟了一门语言的"任督二脉",以后你学哪一门语言都会轻易上手.学语言 ...
- num09---建造者模式
建造者模式: 核心思想:将产品 和 产品建造过程解耦
- Go语言实现:【剑指offer】机器人的运动范围
该题目来源于牛客网<剑指offer>专题. 地上有一个m行和n列的方格.一个机器人从坐标0,0的格子开始移动,每一次只能向左,右,上,下四个方向移动一格,但是不能进入行坐标和列坐标的数位之 ...
- Go语言实现:【剑指offer】正则表达式匹配
该题目来源于牛客网<剑指offer>专题. 请实现一个函数用来匹配包括 . 和 * 的正则表达式.模式中的字符.表示任意一个字符,而 * 表示它前面的字符可以出现任意次(包含0次). 在本 ...
- T1飞跃树林 && 【最长等差子序列】
solution by Mr.gtf 一道简单的递推 首先我们对树高从大到小排序 很容易得到递推式 ans[i]=Σans[j] (j<i && h[j]-h[i]<=K) ...
- 《自拍教程17》Python调用命令
他山之石 何为他山之石,就是借助外界工具,来实现自己想要的功能. 命令行界面软件, 即各种命令,我们也叫命令行工具, 此类工具也是测试人员或者开发人员常用的工具的一种. 测试人员可以借助这类工具,快速 ...
- centos6.5下编译安装单实例MySQL5.5
MySQL5.5版本安装3步曲: 1) cmake 2) make 3) make install 查看系统版本号 [root@meinv01 ~]# cat /etc/redhat-release ...
- 解决掉你心中 js function与Function的关系的疑问
前言 在网上有很多关于js function 与 Function直接关系的文章. 但是我感觉过于抽象化了,那么如何是具体化的解释? 正文部分为个人理解部分,如有不对望指出. 正文 <scrip ...
- 【渗透实战】web渗透实战,手动拿学校站点 得到上万人的信息(漏洞已提交)
------------恢复内容开始------------ ’‘’版权tanee转发交流学校请备注漏洞已经提交学校管理员关键过程的截图和脚本代码已经略去.希望大家学习技术和思路就好,切勿进行违法犯罪 ...
- Leetcode字典树-720:词典中最长的单词
第一次做leetcode的题目,虽然做的是水题,但是菜鸟太菜,刚刚入门,这里记录一些基本的知识点.大佬看见请直接路过. https://leetcode-cn.com/problems/longest ...