第十八天re模块和·正则表达式
1.斐波那契 # 问第n个斐波那契数是多少
def func(n):
if n>2:
return func(n-2)+func(n-1)
else:
return 1
num=int(input('请输入一个整数:'))
ret=func(num)
print(ret)
结果为
8
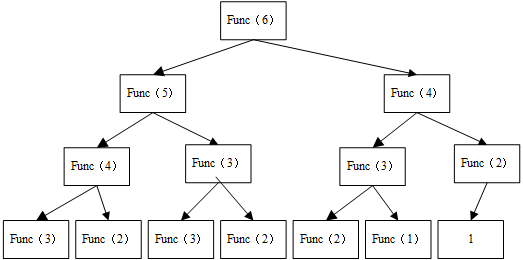
执行过程中,如果出现第一行第一列的func(4)执行过一次,然后到第二列在进行func(4)时,不是把第一列计算出的值直接带进去,而是使用递归再一次进行计算、所以在使用递归时,不建议使用双重递归。对程序的改进是:
def func(n,l=[0]):
l[0]+=1
if n==2 or n==1:
l[0]-=1
return 1,1
else:
a,b=func(n-1)
l[0]-=1
if l[0]==0:
return a+b
return b,a+b
num=int(input('请输入一个整数:'))
ret=func(num)
print(ret)
2阶乘的问题:
def func(n):
if n==1:
return 1
else:
return n*func(n-1)
num=int(input('请输入一个整数:'))
ret=func(num)
print(ret)
结果为
请输入一个整数:6
720
1.在python中使用re模块必须要使用正则表达式:而正则表达式是用来对字符串进行匹配操作用的。
2一个11位手机号码的判断:(根据手机号码的特点一共11位,并且开头只能是13,14,15,18开头的数字这些特点我们写了以下代码:
def mobile_num(num):
#用于手机号码的判断
if len(num)==11\
and num.isdigit() \
and(num.startswith('')or num.startswith('')
or num.startswith('')or num.startswith('')):
return ('你输入的是手机号码合法')
else:
return('你输入的手机号码不合法:')
num=input('请输入你的手机号码:')
print(len(num))
ret=mobile_num(num)
print(ret)
结果为
请输入你的手机号码:18798531683
11
你输入的是手机号码合法
3.正则表达式本身是和python没有关系的,就是匹配字符的一种规则罢了。主要是用来对字符串操作的一种逻辑,就是用事现定义好的一些特殊字符及这些特定字符的组合。
4.如果想要显示某段字符串中拥有多少个某字符则可以使用正则表达式:
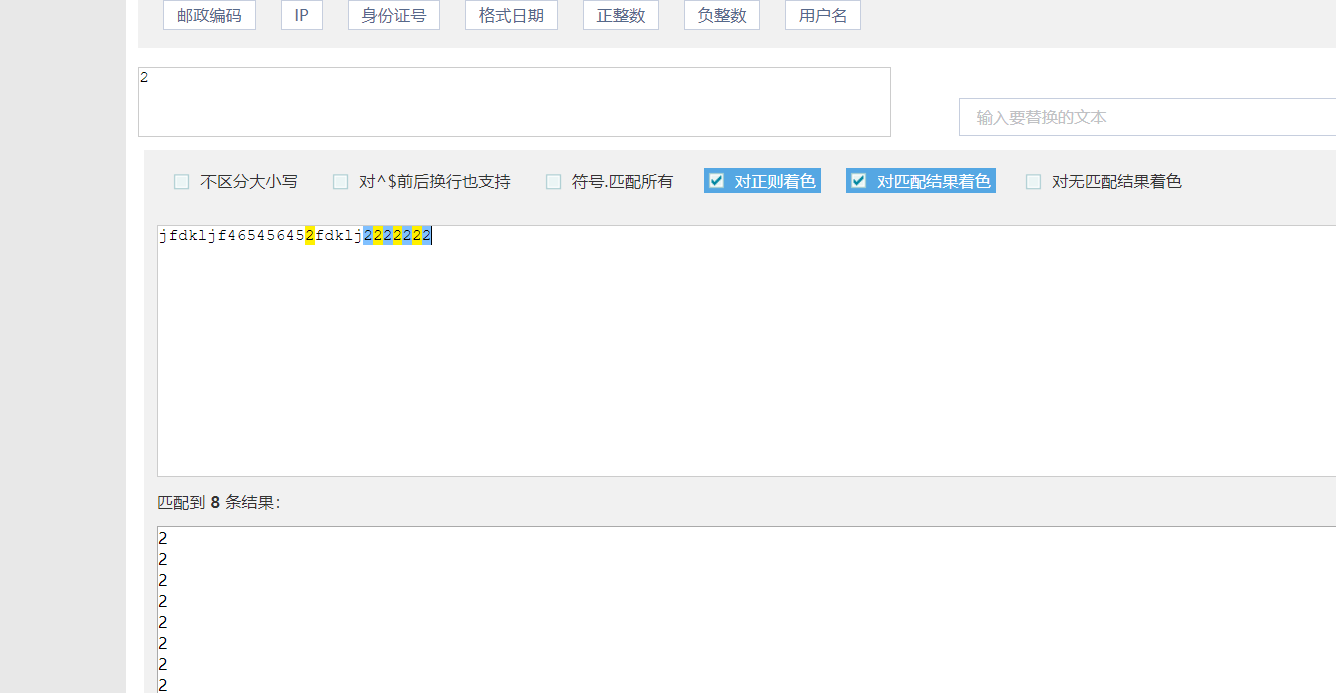
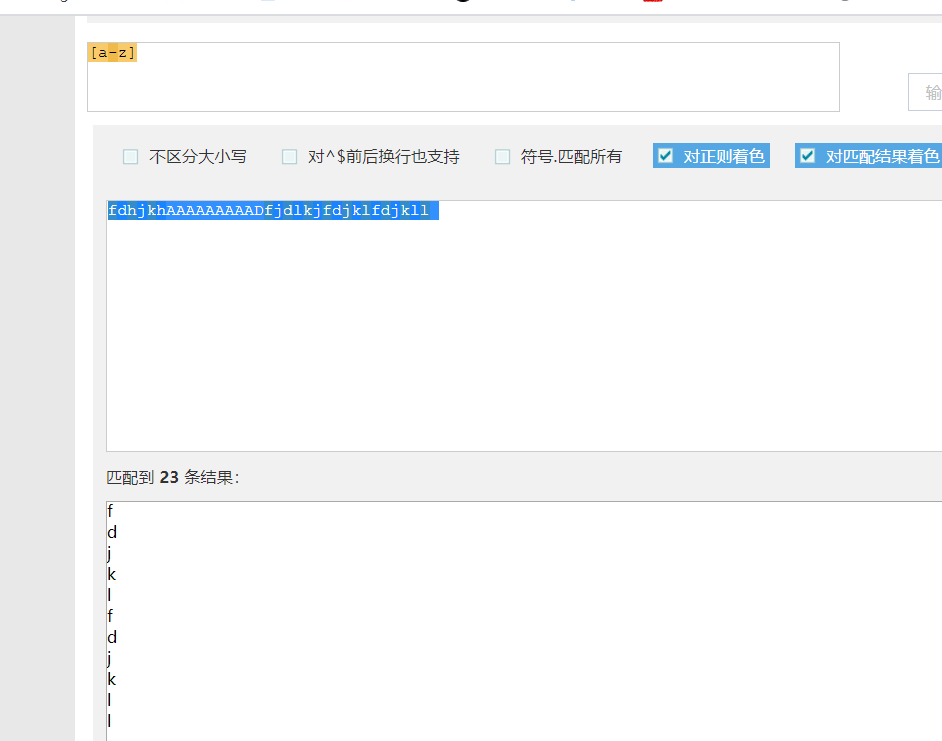
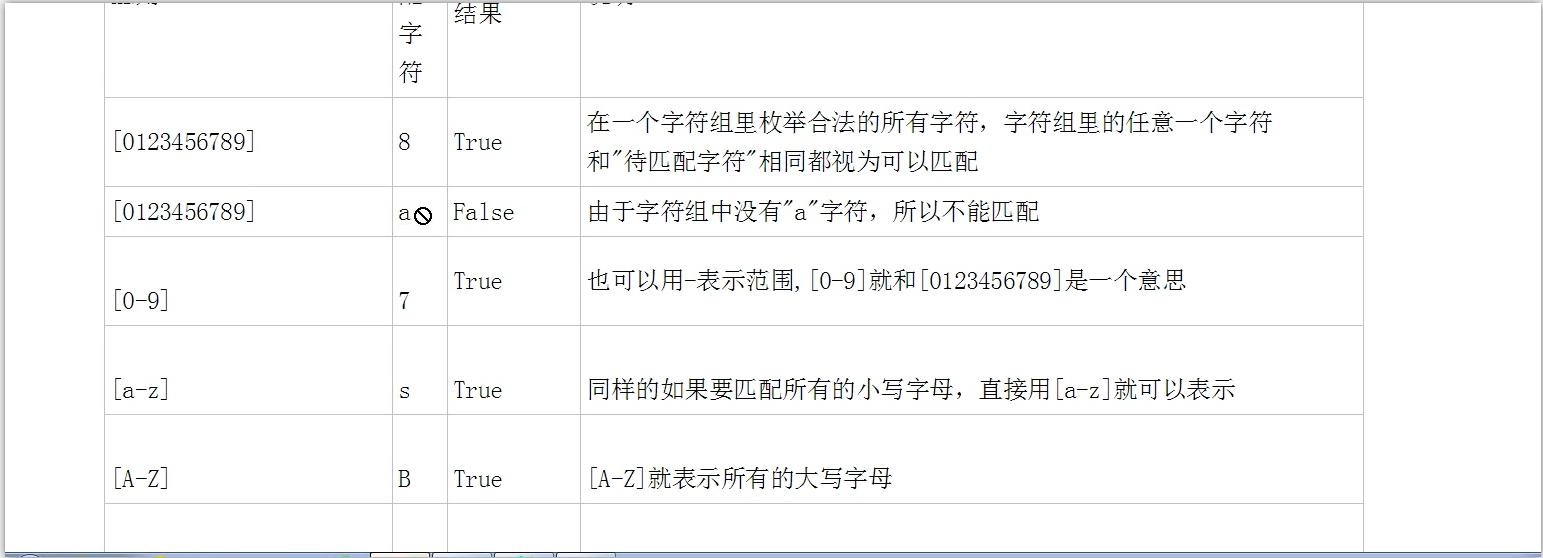
5.如果想要查找某个范围内的字符在某段字符串内相匹配的内容:(在同一位置出现的各种字符组成的一个字符串在正则表达式中用[]来表示)规则是(左边是小的,右边是大的)
而且里面可以有多个限制范围)
6.元字符和其功能:

注:在使用a|b这个时要把匹配信息长的哪一个放在前面,w是word缩写,s是space的缩写,d是digit的缩写$必须要放在结尾位置。
7.量词的使用:(这些都有懒惰原则只要发现都是都是以最大原则来进行计算)


8.元字符和量词的使用规则:必须先写元字符才能写量词,而且量词要和最靠近它的元字符进行匹配
9.要匹配字符串中所有的小写英文字母和数字,并且放在同一行:[a-z ]+\d+
10.想要把海燕、海娇、海东分别输出:海.
11.如果想要输出以海开头,以某一个字符结尾的表达式:
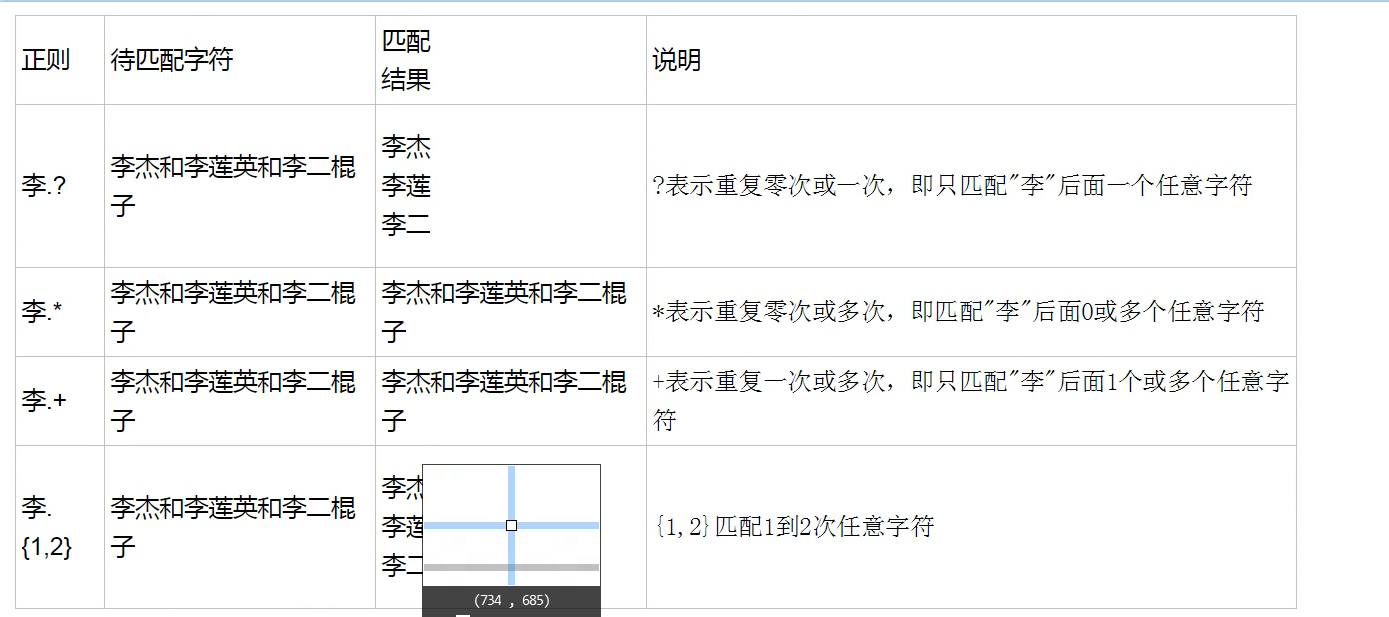
11.如果将每个名字分别输出:[^和]+

13. 如果为字母数字组合则为同一行输出:([a-z]\d)+
14.身份证号码是一个长度为15或者18的字符串,如果为15位则代表全部是数字组成,首位不能为0,如果为18位,则前17位全部是数字,末位可能是数字
或者x:方法为:^[0-9]\d{14}(\d{2}[0-9x])?或者为^[0-9]\d{16}[0-9x]|\d{14}
15.如果要判断字符串中是否有\n而不是换行符的操作是:
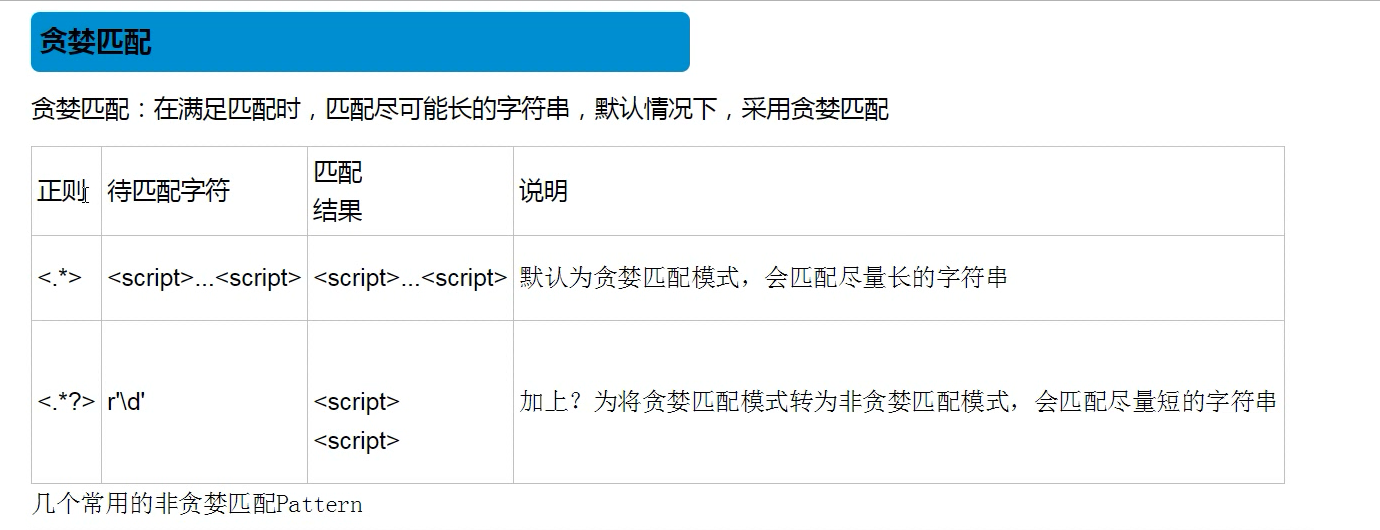
注:<.*>使用规则是:先去寻找所有的字符串,等找到所有字符串后再从最后一个字符串哪里找>这个符号返回
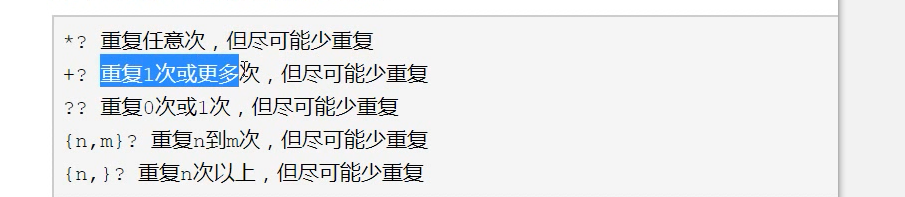
注内容为<script>....Kscript>
1.使用<.*?>结果为<script>
2.
17
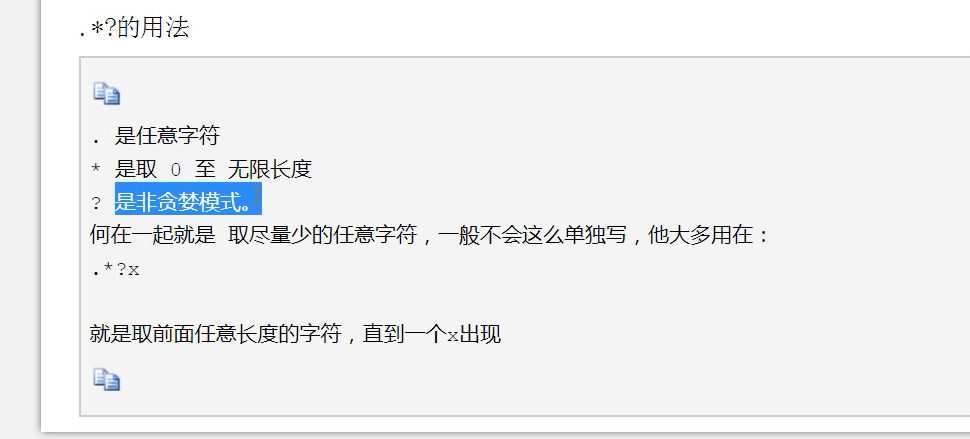
16.python中re模块的用法:findall、search、match原则:
16.1 findall的用法:
import re
ret=re.findall('[a-z]+','eva ego Yuan')#返回所有满足条件的结果放在列表里
print(ret)
结果为
['eva', 'ego', 'uan']
16.2 search的用法:
import re
ret=re.search('a','eva goj yuan')#会从前往后找,找到一个就返回一个对象
print(ret) #如果找不到就返回None而而且调用group会报错
if ret:
print(ret.group())
结果为
<_sre.SRE_Match object; span=(2, 3), match='a'>
a
16.3match的用法:
import re
ret=re.match('[a-z]+','rfjkj fdkjj fdjjfd')#match 是从头开始匹配
if ret:#如果正则规则中从头开始可以匹配上,就返回一个变量
print(ret.group())#如果没有匹配上,就返回None,调用group会报错
结果为
rfjkj
16.4split的用法:
import re
ret=re.split('[ab]','abcd')#先按‘a’进行分割,得到''和'bcd'在对''
print(ret)#和'bcd'分别按'b'分割
结果为
['', '', 'cd']
16.5sub的用法:
import re
ret=re.sub('\d','H','evade3jkjfj4jj6',1)
print(ret)#讲数字用'H'来进行替换,参数1表示只替换一次,默认全部替换
结果为
evadeHjkjfj4jj6
16.6subn的用法:
import re
ret=re.subn('\d','H','evade3jkjfj4jj6')
print(ret)#讲数字用'H'来进行替换,而且返回执行的次数
结果为
('evadeHjkjfjHjjH', 3)
16.7compile的用法:
import re
obj=re.compile('\d{3}')#将正则表达式编译成一个正则表达式对象,规则是要匹配3个数字
ret=obj.search('abc123ssdfff')#正则表达式调用的对象是search参数为待匹配的字符串
print(ret.group())
ret=obj.search('fdlfjklfdjlj2fdj3465')
print(ret.group())
结果为
123
346
finditer的用法:
import re
ret=re.finditer('\d','ds3y34666')
print(ret)
print(next(ret).group())
print(next(ret).group())
print(next(ret).group())
结果为
<callable_iterator object at 0x000001D5A0536A20>
3
3
4
17分组的一些特点:
17.1search里有关分组的用法:(不懂)
ret=re.search('^[0-9]\d{14}(\d{2}[0-9x])?$','')
print(ret.group())
print(ret.group(0))
print(ret.group(1))
结果为
112000456433456
112000456433456
None
import re
ret=re.search('^[0-9](\d{14})(\d{2}[0-9x])?$','')
print(ret.group())
print(ret.group(0))
print(ret.group(1))
print(ret.group(2))
结果为
112000456433456
112000456433456
12000456433456
None
17.2findall优先匹配原则:
import re
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret)#findall 会优先匹配结果组里内容进行返回
结果为
['oldboy']
17.3解决findall优先匹配原则:
import re
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')#使用?:可以把组里的特权取消
print(ret)#findall 会优先匹配结果组里内容进行返回
结果为
C:\pycharm\python.exe D:/python练习程序/第十八天/作业.py
['www.oldboy.com']
17.4split的分离问题:
import re
ret=re.split('\d+','evcjj3jjfdj3jfj5fj')
print(ret)
结果为
['evcjj', 'jjfdj', 'jfj', 'fj']
import re
ret=re.split('(\d+)','evcjj3jjfdj3jfj5fj')#加了分组会把切割内容也返回元组
print(ret)
18.正则表达式中的计算题:
import re
express='1 -2 * ( (6 0 -3 0 +(-40/5)* (9-2*5/3 +7 /3*99/4*2998 +10 *568/14 ))-(-4*3)/ (16-3*2))'
def func3(exp2):
if '+-'in exp2:exp2=exp2.replace('+-','-')
elif '--'in exp2:exp2=exp2.replace('--','+')
return exp2
def func2(exp1):#进行乘除运算的函数
if '/'in exp1: #进行除法运算
a,b=exp1.split('/')
return str(float(a)/float(b)) #并以字符串的形式返回
elif '*'in exp1: #进行乘法运算
a,b=exp1.split('*')
return str(float(a)*float(b))
def func1(exp):#进行拆分的函数
exp=exp.strip('()') #去除括号操作
print(exp)
while True: #计算的规则是先乘除在加减
ret1=re.search('\d+\.?\d*[*/]-?\d+\.?\d*',exp) #寻找式子中的乘除
if ret1:
exp_son1=ret1.group()
print(exp_son1)
ret2=func2(exp_son1) #调用乘除运算的函数
exp=exp.replace(exp_son1,ret2)
print(exp)
continue
else:
exp=func3(exp)#式子中有可能会出现——或者+-的要调用函数去除
ret3=re.findall('-?\d+\.?\d*',exp)
sum1 =0
for i in ret3: #进行加减运算
sum1 +=float(i)
return str(sum1)
new_express=express.replace(' ','') #去掉字符串中的空格
while True:
ret=re.search('\([^()]+\)',new_express) #去找每一次最里面的括号
if ret: #如果找到执行此指令
express_son=ret.group()
print(express_son)
ret4=func1(express_son) #对寻找到括号里的的式子进行计算
new_express=new_express.replace(express_son,ret4)
print(new_express)
else:
ret5=func1(new_express) #进行没有括号的运算
print(ret5)
new_express=func3(new_express)
break
结果为
2776672.6952380957
简洁版:
import re
express='1 -2 * ( (6 0 -3 0 +(-40/5)* (9-2*5/3 +7 /3*99/4*2998 +10 *568/14 ))-(-4*3)/ (16-3*2))'
def func3(exp2):
if '+-'in exp2:exp2=exp2.replace('+-','-')
elif '--'in exp2:exp2=exp2.replace('--','+')
return exp2
def func2(exp1):#进行乘除运算的函数
if '/'in exp1: #进行除法运算
a,b=exp1.split('/')
return str(float(a)/float(b)) #并以字符串的形式返回
elif '*'in exp1: #进行乘法运算
a,b=exp1.split('*')
return str(float(a)*float(b))
def func1(exp):#进行拆分的函数
exp=exp.strip('()') #去除括号操作
while True: #计算的规则是先乘除在加减
ret1=re.search('\d+\.?\d*[*/]-?\d+\.?\d*',exp) #寻找式子中的乘除
if ret1:
exp_son1=ret1.group()
ret2=func2(exp_son1) #调用乘除运算的函数
exp=exp.replace(exp_son1,ret2)
continue
else:
exp=func3(exp)#式子中有可能会出现——或者+-的要调用函数去除
ret3=re.findall('-?\d+\.?\d*',exp)
sum1 =0
for i in ret3: #进行加减运算
sum1 +=float(i)
return str(sum1)
new_express=express.replace(' ','') #去掉字符串中的空格
while True:
ret=re.search('\([^()]+\)',new_express) #去找每一次最里面的括号
if ret: #如果找到执行此指令
express_son=ret.group()
ret4=func1(express_son) #对寻找到括号里的的式子进行计算
new_express=new_express.replace(express_son,ret4)
else:
ret5=func1(new_express) #进行没有括号的运算
new_express=func3(new_express)
break
print(ret5)
第十八天re模块和·正则表达式的更多相关文章
- python模块之re正则表达式
41.python的正则表达式 1. python中re模块提供了正则表达式相关操作 字符: . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线或汉字 \W大写代表非\w ...
- Py修行路 python基础 (二十一)logging日志模块 json序列化 正则表达式(re)
一.日志模块 两种配置方式:1.config函数 2.logger #1.config函数 不能输出到屏幕 #2.logger对象 (获取别人的信息,需要两个数据流:文件流和屏幕流需要将数据从两个数据 ...
- python学习第四十八天json模块与pickle模块差异
在开发过程中,字符串和python数据类型进行转换,下面比较python学习第四十八天json模块与pickle模块差异. json 的优点和缺点 优点 跨语言,体积小 缺点 只能支持 int st ...
- python re 模块和基础正则表达式
1.迭代器:对象在其内部实现了iter(),__iter__()方法,可以用next方法实现自我遍历. 二.python正则表达式 1.python通过re模块支持正则表达式 2.查看当前系统有哪些p ...
- python正则表达式模块re:正则表达式常用字符、常用可选标志位、group与groups、match、search、sub、split,findall、compile、特殊字符转义
本文内容: 正则表达式常用字符. 常用可选标志位. group与groups. match. search. sub. split findall. compile 特殊字符转义 一些现实例子 首发时 ...
- Python 常用模块之re 正则表达式的使用
re模块用来使用正则表达式.正则表达式用来对字符串进行搜索的工作.我们最应该掌握正则表达式的查询,更改,删除的功能.特别是做爬虫的时候,re模块就显得格外重要. 1.查询 import re a = ...
- 5.2.2 re模块方法与正则表达式对象
Python标准库re提供了正则表达式操作所需要的功能,既可以直接使用re模块中的方法,来实现,也可以把模式编译成正则表达式对象再使用. 方法 功能说明 complie(pattern[,flagss ...
- re模块语法—python正则表达式
用字符串匹配实现 对于简单的匹配查找,可以通过字符串匹配实现,比如:查找以”hello”开头的字符串 此时就可以正确查找出以start开始的字符串了 python中的正则表达式模块 在python中为 ...
- 模块3 re + 正则表达式
1. 正则表达式 匹配字符串 元字符 . 除了换行 \w 数字, 字母, 下划线 \d 数字 \s 空白符 \n \t \b 单词的边界 \W 非xxx \D \S [] 字符组 [^xxx] 非xx ...
随机推荐
- Windows10安装node.js
1.下去官网下载node.js https://nodejs.org/zh-cn/download/ 2.安装,直接默认即可,安装路径也可以自己选择 3.设置环境变量 1.安装软件,若是-g,则是全局 ...
- vue中mixins的理解及应用
vue中mixins的理解及应用 vue中提供了一种混合机制--mixins,用来更高效的实现组件内容的复用.最开始我一度认为这个和组件好像没啥区别..后来发现错了.下面我们来看看mixins和普通情 ...
- 每天进步一点点------Allegro 动态显示走线长度
手工布线时还可以动态显示当前走线的长度,设置方法为执行菜单命令Setup->User preferences,打开User preferences Editor对话框.在Etch对应的环境变量中 ...
- win10图标变白的解决办法(亲测有用)
1.首先,随便打开一个文件夹点击[查看]菜单,然后勾选[隐藏的项目]: 2.同时按下快捷键[Win]+[R],在打开的[运行]窗口中输入%localappdata%: 3.在打开的文件夹中,找到[Ic ...
- jmeter的使用---录制脚本
1.设置fidder 2.在fidder中导出请求,选择jmx格式
- ColorPix——到目前为止最好用的屏幕取色器
分享一个颜色取色器网页.PPT.EXCEL配色不再烦恼 简单易用 大家做商业.企业报告的时候是不是经常遇到要调色的困扰呢?PPT.EXCEL等颜色选取会对报告有质的影响!!要更专业要更有美感!给大家分 ...
- sqli-libs总结
security数据库中: select left(database(),1)=‘s’; 前1位是否是s: select database() regexp ‘s’; 匹配第一个字符是否是 s: ...
- gitlab创建项目及分支
链接:https://blog.51cto.com/13760226/2426209
- 安卓按键:读取txt开头出现未知字符的问题
很多时候 我们读取txt 用traceprint输出后 最头上会莫名其妙多出一个问号 但是你用问号匹配他 却匹配不到 就是1个未知字符 这个到底是什么 怎么避免出现这个东西呢 这个主要是txt文件 ...
- 并发编程Semaphore详解
Semaphore的作用:限制线程并发的数量 位于 java.util.concurrent 下, 构造方法 // 构造函数 代表同一时间,最多允许permits执行acquire() 和releas ...