SQL Server SQL性能优化之--通过拆分SQL提高执行效率,以及性能高低背后的原因
复杂SQL拆分优化
拆分SQL是性能优化一种非常有效的方法之一,
具体就是将复杂的SQL按照一定的逻辑逐步分解成简单的SQL,借助临时表,最后执行一个等价的逻辑,已达到高效执行的目的
一直想写一遍通过拆分SQL来优化的博文,最近刚好遇到一个实际案例,比较有代表性,现分享出来,
我们来通过一个案例来分析,为什么拆分语句可以提高SQL执行效率,更重要的是弄清楚,拆分前为什么慢,拆分后为什么快了?
幼稚的话,各位看官莫笑
先看一下相关表的数据量,大表也有5900多万,小表有160多万
(声明:我从来没认为5000W就是大表,或者说表很大就说明业务或者数据库很牛叉,从来么有。能把大表拆分小表,永远不出现超级大表又能满足业务需求,那才叫牛逼)
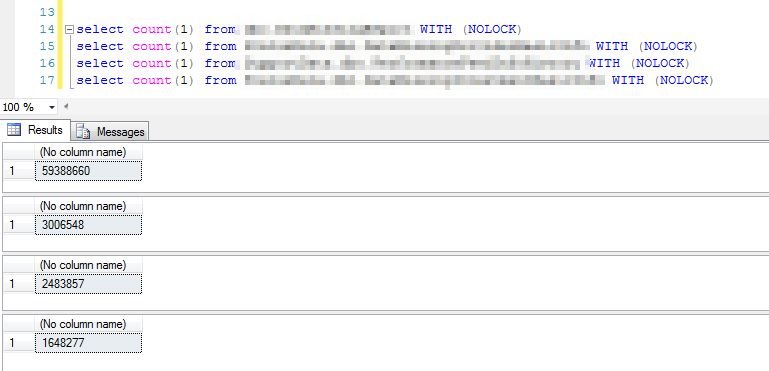
如下是本次优化的SQL语句
其实SQL称不上复杂,无奈这几个表的数据量都稍微显得有些大,另外里面嵌套比较复杂的业务逻辑,
历史上经过几轮“高手”的在索引上全方为的优化之后,也能正常运行
但是随着时间的推移,表中的数据量越来越大,温水煮青蛙一般,SQL越来越慢,越来越慢,
终于还是暴露了出来,性能问题还是无法被掩盖的,
说实话这么个SQL,分页查询运行超过1分钟(服务器比较稳定,没有什么负载,测试之前博主习惯性rebuild所有索引)
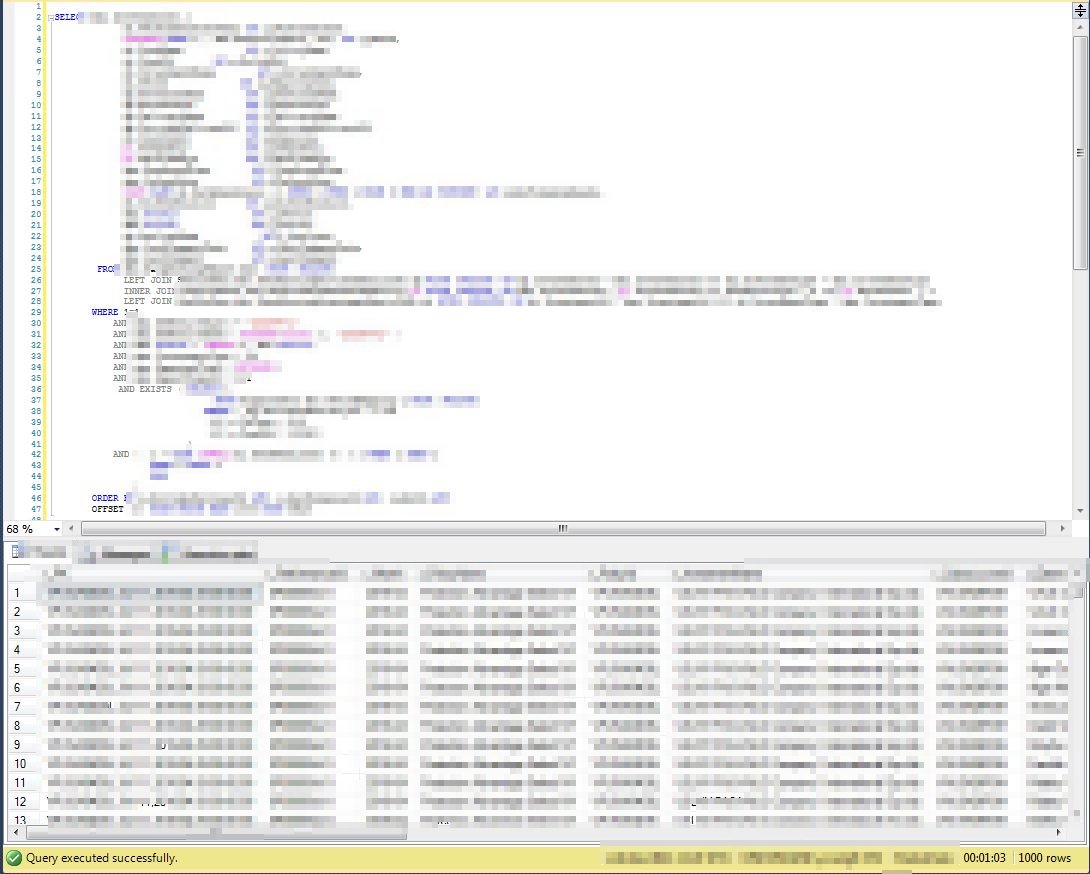
造成上述问题的原因是多样的,业务上的,历史上的,数据上的等等吧,也不用太鄙视了吧,哈哈
家家有本难念的经,其实不用笑,之前有个同事离职去了一家挺牛逼的上市公司,又一次发微信说卧槽这里的系统还真不如咱们在**公司的系统的,哈哈
博主所在的公司,也有数千台SQL Server数据库服务器了,动不动超过一两分钟分钟的查询还是有一些的,
这也是博主能够专职长期优化SQL的原因吧
因为这种SQL遇到太多了,历任开发人员和DBA也不是吃白饭的,想通过索引来实现质的改变是不可能的
并不是我不重视索引,或者说我不懂索引,
我觉得仅仅是通过索引就能优化的SQL语句,或者说建了索引,速度立马上去了几十倍,那只能说明一个问题:这种问题本身就太弱
当我第一次看到这个SQL执行的这么慢,在了解相关表数据之后,
第一感觉能否通过拆分,减小SQL连接条件,查询条件的复杂程度,然后再跟其他表join产生最后的结果集,
但是如何拆分?先拆分哪个表?怎么组合?这才是问题的本质
举个简单的例子
比如下面一个查询语句,有四张表join,有多个查询条件,连接条件等等
select A.colName,B.colName,C.colName,D.colName
from TableA A
inner join TableB B on A.Id=B.Id and A.Type=B.Type and 其它条件
inner join TableC C on B.Code=C.Code and 其它条件
inner join TableD D on C.BusinessId=D.BusinessId and 其它条件
where A.BusinessDate>=Date1
and A.BusinessDate<=Date2
and A.BusinessStatus=''
and B.BusinessDate=''
and C.BusinessDate=''
and 其他查询条件
and 其他查询条件order by col1,col2,col3
OFFSET M ROWS FETCH NEXT N ROWS ONLY
如果是三个表拆分,跟第四个表join,可以通过如下备选方案
可以把ABC join起来加上对应的查询条件,拆分成一个临时表,然后跟D表join,
可以把ABD join起来加上对应的查询条件,拆分成一个临时表,然后跟C表join,
可以把ACD join起来加上对应的查询条件,拆分成一个临时表,然后跟B表join,
可以把BCD join起来加上对应的查询条件,拆分成一个临时表,然后跟A表join,
这里就有一个小技巧,要观察一下三个表加上对应的查询条件结果集的总行数,
比如ABC join是3000条结果集,这3000条结果集跟D表join产生了20w条结果,那么就可以先排除D表,
让ABC join起来加上对应的查询条件,生成临时表,在临时表上建立合理的索引,再跟D表join
也就是说先排除一些产生大结果集的join参与join,其他的表join,得到一个相对较少的临时结果集,
在临时结果集上建立索引,再用这个临时结果集去join其他的表。
这种拆分方式,还有最重要的一步,在临时表上加合适的索引,以最优化临时表与物理表的执行
如果数据量不大,拆分是适得其反的,完全没有必要,但是在数据量越大的时候,效果越明显,
那么这里的拆分后究竟有多明显的效果?
记得之前是多少秒?1分钟3秒,也就是63秒,这里是2秒钟
说实话,这种拆分方式经常用,说实话这个速度的提示是我没有想到的

其实问题到这里才刚刚开始
为什么拆分之前那么慢,为什么拆分之后又变得这么快?
执行计划就不细看了,上文说了,这个查询并不缺少索引,也确实用到了索引,但是并不代表,有了索引,用到了索引,就万事大吉了。
因为查询条件较为复杂,相关的表建立的是复合索引,如果要说索引,就必须说统计信息(statistics),
对于复合索引,也即两个以上字段的索引,其统计信息的特点是只会维护第一个字段的直方图信息,
这就决定了SQL Sever在对数据量做预估的时候,有可能出现误差
我这里有写统计信息相关的知识的,可以参考
某些多个查询条件的情况下,即便是用到了复合索引,
SQL Server并不能准确地预估某些条件下数据的行数,如果SQL Server一开始就错误地预测到预期的数据量很小,
那么后继每一步都无法准确地预测真正数据的大小,也即第一步就错了,导致后面每一步都受到第一步的干扰,
后面往往会采用Loop join的方式执行,这种方式对于较小的结果集,当然没有问题,如果遇到较大的结果集,就非常低效了
(见过很多超级复杂,join的表多,很复杂的查询条件,且运行缓慢的SQL,SQL Server往往是以loop join的方式去处理表之间)

所以我们先拆分出来一个较小的结果集,存放在临时表,
在第一步的拆分过程中,即便某些情况下无法正确地预估表的行数,因为结果集比较小,采用了Loop join的方式来处理也是没有问题的。
一旦我们拆分出来一个临时表,对临时表加上合理的索引,再跟其他的大表join,
由于SQL变得简单了,加上有索引,往往会以高效的方式去执行,性能也就上去了
那么什么是高效?是不是主观臆断或者说是胡说八道,比如呢?
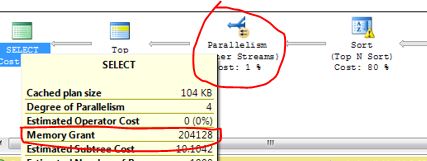
比如通过更大的内存授予(Memory Grant),因为结果集大,采用并行运行(这里有写并行相关的,可参考)等等,获取更多的资源从而提高执行效率
事实上,本文举例的SQL拆分之后的运行,正式因为此,授予更大的内存+并行,才得以高效执行。如图。
总结:
本文通过一个SQL语句的拆分来达到优化的方法,说明在一定情况下,拆分SQL是优化的可选方案。
当然也不是说,复杂的SQL一定会执行的慢,一定需要拆分,对于多个大表join,如果逻辑简单,可能也会快速的执行
但是对于那些多个大表join的SQL,尤其是在连接条件,查询条件,索引信息复杂的情况下,如果出现性能问题,可以考虑通过拆分SQL来优化其执行效率
这个只能说,执行的慢的SQL,通过具体的分析,是可以通过拆分SQL语句生成临时表来解决的。
SQL 拆分解决了性能问题,但,更重要的是,一定要弄明白:慢,是为什么慢,快,是为什么快,弄不清楚的话,类似问题还会时不时地让你感到困惑。
理解了本质,才能够游刃有余,更好地掌握SQL Server。
写的不对请各位看官指出,本人还很菜,希望得到大神的指点,谢谢。
转载请注明出处 http://www.cnblogs.com/wy123/p/5712001.html
SQL Server SQL性能优化之--通过拆分SQL提高执行效率,以及性能高低背后的原因的更多相关文章
- Sql性能检测工具:Sql server profiler和优化工具:Database Engine Tuning Advisor
原文:Sql性能检测工具:Sql server profiler和优化工具:Database Engine Tuning Advisor 一.工具概要 数据库应用系统性能低下,需要对其进行优化 ...
- SQL Server 2014内存优化表的使用场景
SQL Server 2014内存优化表的使用场景 最近一个朋友找到走起君,咨询走起君内存优化表如何做高可用的问题 大家知道,内存优化表是从SQL Server 2014开始引入,可能大家对内存优化表 ...
- SQL Server ->> Memory Allocation Mechanism and Performance Analysis(内存分配机制与性能分析)之 -- Minimum server memory与Maximum server memory
Minimum server memory与Maximum server memory是SQL Server下配置实例级别最大和最小可用内存(注意不等于物理内存)的服务器配置选项.它们是管理SQL S ...
- SQL执行效率和性能测试方法总结
对于做管理系统和分析系统的程序员,复杂SQL语句是不可避免的,面对海量数据,有时候经过优化的某一条语句,可以提高执行效率和整体运行性能.如何选择SQL语句,本文提供了两种方法,分别对多条SQL进行量化 ...
- [转]SQLServer SQL执行效率和性能测试方法总结
本文转自:http://www.zhixing123.cn/net/27495.html 对于做管理系统和分析系统的程序员,复杂SQL语句是不可避免的,面对海量数据,有时候经过优化的某一条语句,可以提 ...
- SQL执行效率和性能测试方法
对于做管理系统和分析系统的程序员,复杂SQL语句是不可避免的,面对海量数据,有时候经过优化的某一条语句,可以提高执行效率和整体运行性能.如何选择SQL语句,本文提供了两种方法,分别对多条SQL进行量化 ...
- SQL Server索引进阶:第九级,读懂执行计划
原文地址: Stairway to SQL Server Indexes: Level 9,Reading Query Plans 本文是SQL Server索引进阶系列(Stairway to SQ ...
- SQL Server游标 C# DataTable.Select() 筛选数据 什么是SQL游标? SQL Server数据类型转换方法 LinQ是什么? SQL Server 分页方法汇总
SQL Server游标 转载自:http://www.cnblogs.com/knowledgesea/p/3699851.html. 什么是游标 结果集,结果集就是select查询之后返回的所 ...
- SQL Server 2000:提示“未与信任SQL SERVER连接相关连”错误
在使用“用户模式”登陆SQL Server 2000时提示“未与信任SQL SERVER连接相关连”错误,因为在安装SQL Server时选择“仅Windows”模式,所以所有用户都不可以登陆. 解决 ...
随机推荐
- node.js学习(三)简单的node程序&&模块简单使用&&commonJS规范&&深入理解模块原理
一.一个简单的node程序 1.新建一个txt文件 2.修改后缀 修改之后会弹出这个,点击"是" 3.运行test.js 源文件 使用node.js运行之后的. 如果该路径下没有该 ...
- 数据库优化案例——————某市中心医院HIS系统
记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也开始分享自己做的优化案例. 最近一直很忙,博客产出也少的 ...
- ajax异步请求
做前端开发的朋友对于ajax异步更新一定印象深刻,作为刚入坑的小白,今天就和大家一起聊聊关于ajax异步请求的那点事.既然是ajax就少不了jQuery的知识,推荐大家访问www.w3school.c ...
- python爬取github数据
爬虫流程 在上周写完用scrapy爬去知乎用户信息的爬虫之后,github上star个数一下就在公司小组内部排的上名次了,我还信誓旦旦的跟上级吹牛皮说如果再写一个,都不好意思和你再提star了,怕你们 ...
- SQL Server-聚焦IN VS EXISTS VS JOIN性能分析(十九)
前言 本节我们开始讲讲这一系列性能比较的终极篇IN VS EXISTS VS JOIN的性能分析,前面系列有人一直在说场景不够,这里我们结合查询索引列.非索引列.查询小表.查询大表来综合分析,简短的内 ...
- Discuz论坛黑链清理教程
本人亲测有效,原创文章哦~~~ 论坛黑链非常的麻烦,如果你的论坛有黑链,那么对不起,百度收录了你的黑链,不会自动删除,需要你手动去清理. 什么是黑链 黑链,顾名思义,就是一些赌博网站的外链,这些黑链相 ...
- [WPF] Wait for a moment.
一.控件介绍 在 WPF 中使用的等待控件,控件包括三种,普通的等待信息提示(WaitTip),进度条提示(WaitProgress),以及主程序覆盖的模拟时钟等待窗口(WaitClock),具体效果 ...
- Flexible 弹性盒子模型之CSS flex-basis 属性
实例 设置第二个弹性盒元素的初始长度为 80 像素: div:nth-of-type(2){flex-basis:80px;} 效果预览 浏览器支持 表格中的数字表示支持该属性的第一个浏览器的版本 ...
- Android Studio开发RecyclerView遇到的各种问题以及解决(二)
开发RecyclerView时候需要导入别人的例子,我的是从github导入的,下载下github的压缩包之后解压看你要导入的文件是priject还是Module.(一般有app文件夹的大部分是pro ...
- CentOS7之按时间段截取指定的Tomcat日志到指定文件的方法
CentOS7之按时间段截取指定的Tomcat日志到指定文件的方法 sed -n '/2016-11-02 15:00:/,/2016-11-02 15:05:/p' catalina.out > ...