洗礼灵魂,修炼python(54)--爬虫篇—urllib2模块
urllib2
1.简介
urllib2模块定义的函数和类用来获取URL(主要是HTTP的),他提供一些复杂的接口用于处理: 基本认证,重定向,Cookies等。urllib2和urllib差不多,不过少了些功能,又多了些功能不仅可以使用http协议,而且可以扩展到ftp等协议,大体的用法没什么区别
2.方法/属性

大体都和urllib差不多,所以不做详细的解析
3.常用方法/属性解析
最常用的就是urllib2.urlopen()了,其参数可以用一个request的对象来代替URL(这个在前面伪造头部信息都已经用过了),而且增加了一个URLError异常,对于HTTP协议的错误,增加了一个HTTPError的异常,其中这个HTTPError自动变成一个合法的response来返回。
前面说过,urlopen有两种方式,一种是GET,一种POST,默认data=None,当为None时就是使用的GET方式,如果需要传入data参数,就得是POST参数,在一些情况下,必须是url+?+data才行。
前面GET的请求方式已经解析,这次就说说POST请求方式,但我也不知道咋回事一时没想到可以POST并且符合目前难度的网站,格式样本是这样的:
import urllib
import urllib2
url = 'http://XXX.XXX'
values = {'username' : 'yang',
'passwd' : '123456'}
data = urllib.urlencode(values)
req = urllib2.Request(url, data)
response = urllib2.urlopen(req)
html = response.read()
如果您找到有的话,自己测试吧
这里我只能搞个伪POST的方式来解析了。比如我要用百度搜索胡歌,但大家都知道百度网站是不需要POST任何数据就可以直接访问,如果上一篇博文里关于如果没看懂的话,这里也可以当作巩固吧。先直接用浏览器搜索看看:
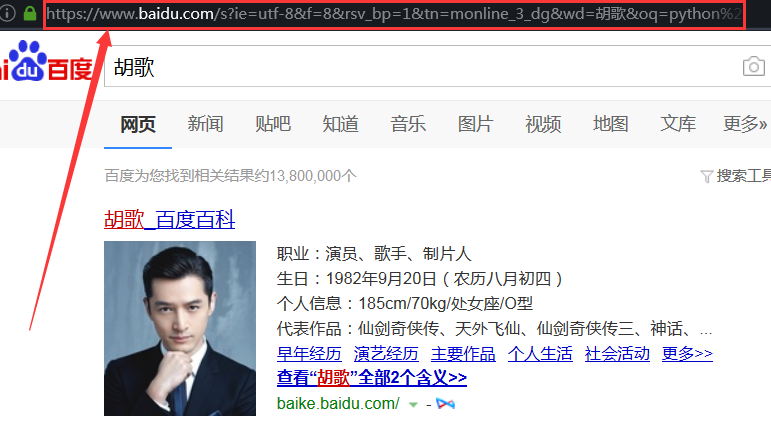
当在百度首页输入关键词【胡歌】时,url会发生变化,把这个url复制下来看看(这里当复制url粘贴时里面的中文【胡歌】却是一个url编码,这也证明了之前说的url编码不能是中文等等特殊符号的规则)
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=monline_3_dg&wd=%E8%83%A1%E6%AD%8C&oq=python%2520urllib2%25E6%25A8%25A1%25E5%259D%2597&rsv_pq=f4f84a020000fe90&rsv_t=98dfd%2FbHG%2BUUjRN7tUwz%2FmgPVkJbNptcPgEj1KyNIHVmkPAjs660ximJgiTjTN7Curbt&rqlang=cn&rsv_enter=1&rsv_sug3=2&rsv_sug1=2&rsv_sug7=100&rsv_sug2=0&inputT=850&rsv_sug4=1543
看到这种格式了吗?上面url里的红色部分是我标记的,不是自然存在的,然后我把url整理下得到:
https://www.baidu.com/s?wd=%E8%83%A1%E6%AD%8C
粘贴到浏览器地址栏里可以访问同样的网页(粘贴到地址栏那些编码符会自动变为中文胡歌):
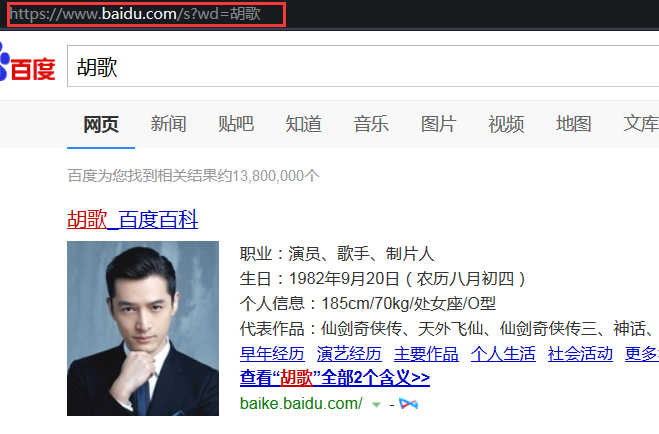
好的,相信有朋友会说,既然这么简单的一串代码就可以搜索,百度干嘛要搞那么一大堆看不懂的东西,那些东西存在自然有其作用,绝对是有用的,不然连正常人都能想到的你觉得百度想不到吗?只是这里我们用不到而已,好的,这问题过。
既然我们已经把url简化到我们可以接受的程序,开始写代码。既然是伪POST,那么可以不用使用urllib2.Request方法了。
# -*- coding:utf-8 -*-
import urllib
import urllib2
url = 'http://www.baidu.com/s'
value = {'wd':'胡歌'} #按照分析的url格式,定义关键词胡歌
data = urllib.urlencode(value) #转为url格式编码
print data
url = url+'?'+data #加入关键词
response = urllib2.urlopen(url) #打开已加入关键词的url
html = response.read()
#print html
with open('test.html','w') as test: #将得到的代码存入当前路径下的test.html文档中,方面查看
test.write(response.read())
因为如果只看网页代码的话,就不好对比直接用浏览器打开的和用程序打开的效果了,所以我们保存到一个文档里,用文档打开。
找到py文件所在目录,test.html也在
双击打开:
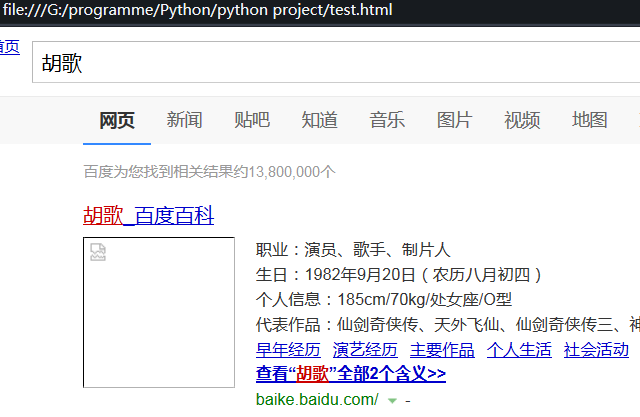
看起来和浏览器打开不太一样是因为当前的文件只是一个html代码,没有js和css样式表作渲染,图片也不存在。但是功能确实是实现了。
你想,我就是要用POST请求来用百度搜索呢?可以啊,我拿出来展示,不用你自己试了:
import urllib
import urllib2
url = 'http://www.baidu.com/s?'
values = {'wd' : '胡歌' }
data = urllib.urlencode(values)
req = urllib2.Request(url, data)
response = urllib2.urlopen(req)
html = response.read()
print html
结果:
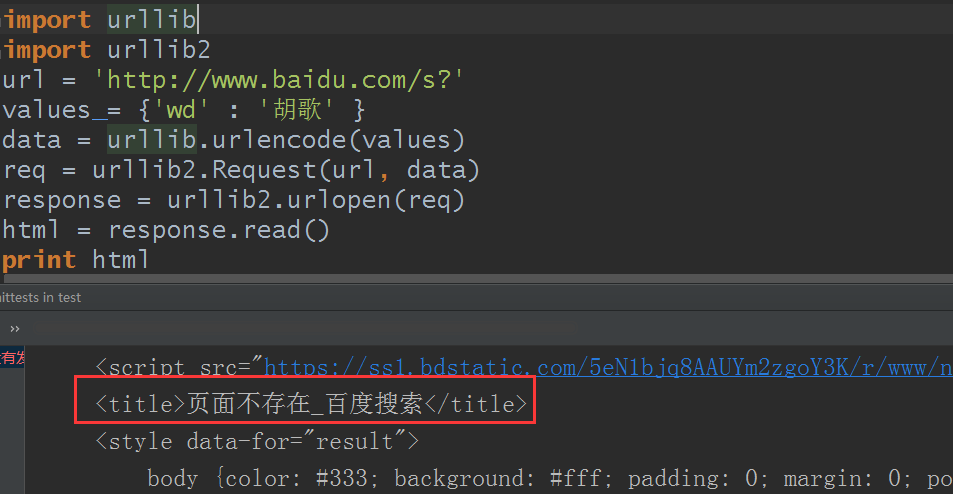
【页面不存在,报错了】。所以确实是不行的。
好的那如果我只想打开那些网站有子目录那种又怎么搞呢?比如http://www.baidu.com/test/download/test/pic …… 像这种网站又怎么办呢?也可以的。
比如就打开百度个人页面,比如我的个人百度页面:
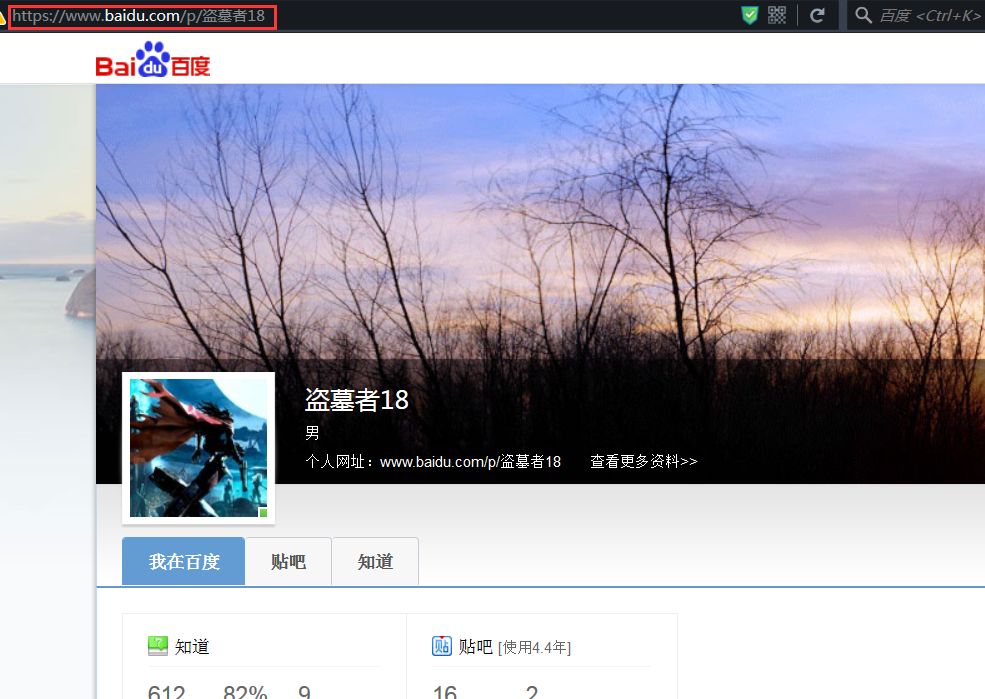
把url复制出来是这样的:https://www.baidu.com/p/%E7%9B%97%E5%A2%93%E8%80%8518,这里并没有【s?】和【wd=】之类的,怎么搞呢?
# -*- coding:utf-8 -*-
import urllib
import urllib2
url = 'http://www.baidu.com/p'
value = {'wd':'盗墓者18'}
data =urllib.urlencode(value).replace('wd=','') #把不需要的用replace去除就行
print data
url = url+'/'+data
print url
response = urllib2.urlopen(url)
with open('baiduperson.html','w') as test:
test.write(response.read())
结果和浏览器打开一样的,不展示了。
4.urllib和urllib2的区别和共性
urllib与urllib2并不是可以代替的,Python的urllib和urllib2模块都做与请求URL相关的操作,但他们提供不同的功能。他们两个最显着的差异如下:
- urllib2可以接受一个Request对象,并以此可以来设置一个URL的headers,但是urllib只接收一个URL。这意味着,urllib不能伪装你的用户代理字符串等。
- urllib模块可以提供进行urlencode的方法,该方法用于GET查询字符串的生成,urllib2的不具有这样的功能。这就是urllib与urllib2经常在一起使用的原因
5.异常
1)URLError异常
通常引起URLError的原因是:无网络连接(没有到目标服务器的路由)、访问的目标服务器不存在。在这种情况下,异常对象会有reason属性(是一个(错误码、错误原因)的元组)
2)HTTPError
每一个从服务器返回的HTTP响应都有一个状态码。其中,有的状态码表示服务器不能完成相应的请求,默认的处理程序可以为我们处理一些这样的状态码(如返回的响应是重定向,urllib2会自动为我们从重定向后的页面中获取信息)。有些状态码,urllib2模块不能帮我们处理,那么urlopen函数就会引起HTTPError异常,其中典型的有404/401
免责声明
本博文只是为了分享技术和共同学习为目的,并不出于商业目的和用途,也不希望用于商业用途,特此声明。如果内容中测试的贵站站长有异议,请联系我立即删除
关于状态码,下一篇讲解
洗礼灵魂,修炼python(54)--爬虫篇—urllib2模块的更多相关文章
- Python的urllib和urllib2模块
Python的urllib和urllib2模块都做与请求URL相关的操作,但他们提供不同的功能.他们两个最显着的差异如下: urllib2可以接受一个Request对象,并以此可以来设置一个URL的h ...
- 洗礼灵魂,修炼python(53)--爬虫篇—urllib模块
urllib 1.简介: urllib 模块是python的最基础的爬虫模块,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如 ...
- 洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1)
爬虫篇前面的某一章了,我们要爬取网站页面源代码的数据,要从中获取到我们想要的数据,是不是感觉很费力,确实费力对吧?那么有没有什么有利的工具来解决这个问题呢?那就是这一篇博文的主题—— 正则表达式简介 ...
- 洗礼灵魂,修炼python(60)--爬虫篇—httplib2模块
这里先要补充一下,Python3自带两个用于和HTTP web 服务交互的标准库(内置模块): http.client 是HTTP协议的底层库 urllib.request 建立在http.clien ...
- Python 学习 第九篇:模块
模块是把程序代码和数据封装的Python文件,也就是说,每一个以扩展名py结尾的Python源代码文件都是一个模块.每一个模块文件就是一个独立的命名空间,用于封装顶层变量名:在一个模块文件的顶层定义的 ...
- 洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2)
前面学习了元家军以及其他的字符匹配方法,那得会用啊对吧?本篇博文就简单的解析怎么运用 正则表达式使用 前面说了正则表达式的知识点,本篇博文就是针对常用的正则表达式进行举例解析.相信你知道要用正则表达式 ...
- 洗礼灵魂,修炼python(59)--爬虫篇—httplib模块
httplib 1.简介 同样的,httplib默认存在于python2,python3不存在: httplib是python中http协议的客户端实现,可以用来与 HTTP 服务器进行交互,支持HT ...
- Python学习——爬虫篇
requests 使用requests进行爬取 下面是我编写的第一个爬虫的脚本 import requests # 导入reques ...
- Python学习—爬虫篇之破解ntml登陆问题
之前帮公司爬取过内部的一个问题单网站,要求将每个问题单的下的附件下载下来.一开始的时候我就遇到一个破解登陆验证的大坑...... (╬ ̄皿 ̄)=○ 由于在公司使用的都是内网,代码和网站的描述 ...
随机推荐
- iOS-AFN Post JSON格式数据
- (void)postRequest{ AFHTTPSessionManager *manager = [AFHTTPSessionManager manager]; // >>> ...
- spring boot -thymeleaf-日期转化
<span th:text="${#dates.format(date)}" ></span><span th:text="${#dates ...
- DFSMN结构快速解读
参考文献如下: (1) Deep Feed-Forward Sequential Memory Networks for Speech Synthesis (2) Deep FSMN for Larg ...
- [EXP]Jenkins 2.150.2 - Remote Command Execution (Metasploit)
## # This module requires Metasploit: https://metasploit.com/download # Current source: https://gith ...
- Java获取URL中的顶级域名domain的工具类
方式一: import java.net.MalformedURLException; import java.net.URL; import java.util.Arrays; import jav ...
- Django+JWT实现Token认证
对外提供API不用django rest framework(DRF)就是旁门左道吗? 基于Token的鉴权机制越来越多的用在了项目中,尤其是对于纯后端只对外提供API没有web页面的项目,例如我们通 ...
- Deep learning with Python 学习笔记(7)
介绍一维卷积神经网络 卷积神经网络能够进行卷积运算,从局部输入图块中提取特征,并能够将表示模块化,同时可以高效地利用数据.这些性质让卷积神经网络在计算机视觉领域表现优异,同样也让它对序列处理特别有效. ...
- POJ 3037 Skiing(如何使用SPFA求解二维最短路问题)
题目链接: https://cn.vjudge.net/problem/POJ-3037 Bessie and the rest of Farmer John's cows are taking a ...
- [TJOI 2018]智力竞赛
Description 题库链接 给出一张 \(m\) 个点的有向图.问可重最小路径覆盖是否 \(\leq n+1\) .若不,求最多用 \(n+1\) 条路径去覆盖,最大化未覆盖点点权最小值. \( ...
- [51nod1514] 美妙的序列
Description 如果对于一个 \(1\sim n\) 的排列满足: 在 \(1\sim n-1\) 这些位置之后将序列断开,使得总可以从右边找一个数,使得该数不会比左边所有数都大,则称该序列是 ...