(代码篇)从基础文件IO说起虚拟内存,内存文件映射,零拷贝
上一篇讲解了基础文件IO的理论发展,这里结合java看看各项理论的具体实现。
传统IO-intsmaze
传统文件IO操作的基础代码如下:
FileInputStream in = new FileInputStream("D:\\java.txt");
in.read();
JAVA虚拟机内部便会调用OS底层的 read()系统调用完成操作,在调用 in.read()的时候就是从内核缓冲区直接返回数据了。
FileInputStream基础read()内部也是调用的read(char[] arg0, int arg1, int arg2)方法。
public int read() throws IOException {
return this.read0();
}
private int read0() throws IOException {
Object arg0 = this.lock;
synchronized (this.lock) {
...int arg2 = this.read(arg1, 0, 2);
...
}
}
public int read(char[] arg0, int arg1, int arg2) throws IOException {
int arg3 = arg1;
int arg4 = arg2;
Object arg5 = this.lock;
synchronized (this.lock) {
this.ensureOpen();
...return arg6 + this.implRead(arg0, arg3, arg3 + arg4);
...
}
}
传统IO的缓冲优化-intsmaze
JAVA提供一个 BufferedInputStream (同理 BufferedOuputStream , BufferedReader/Writer)类来作为缓冲区。
当程序读取OS内核缓冲区数据的时候,便发起了一次系统调用操作,而系统调用的代价相对来说是比较高的,涉及到进程用户态和内核态的上下文切换等一系列操作,所以jdk用如下的包装:
FileInputStream in = new FileInputStream("D:\\java.txt");
BufferedInputStream intsmaze= new BufferedInputStream(in);
intsmaze.read();
每一次 intsmaze.read(),BufferedInputStream 会根据情况自动为我们预读更多的字节数据到它自己维护的一个内部字节数组缓冲区中,这样我们便可以减少系统调用次数,从而达到其缓冲区的目的。所以要明确的一点是BufferedInputStream 的作用不是减少磁盘IO操作次数(这个OS已经帮我们做了,系统read()会因为局部性原理预读一批数据,供系统IO多次调用,见上篇),而是通过减少系统调用次数来提高性能的。
JDK8 中 BufferedInputStream 的源码验证-intsmaze
public class BufferedReader extends Reader {
private Reader in;
private char cb[];
private int nChars, nextChar;
private static int defaultCharBufferSize = 8192;
public BufferedReader(Reader in, int sz) {
this.in = in;
cb = new char[sz];
nextChar = nChars = 0;
}
public BufferedReader(Reader in) {
this(in, defaultCharBufferSize);
}
public int read() throws IOException {
synchronized (lock) {
for (;;) {
if (nextChar >= nChars) {
fill();
}
......
return cb[nextChar++];
}
}
}
private void fill() throws IOException {
......//判断逻辑
int n;
n = in.read(cb, dst, cb.length - dst);//从这里可以看到,缓冲类中还是调用的FileReader的read(char cbuf[], int offset, int length)方法
......
}
BufferedInputStream 内部维护着一个字节数组 byte[] buf 来实现缓冲区的功能,调用的 bufferedInputStream.read()方法在返回数据之前有做一个 if 判断,如果 buf 数组的当前索引不在有效的索引范围之内,即 if 条件成立,buf 字段维护的缓冲区已经不够了,这时候会调用内部的 fill() 方法进行填充,而fill()会预读更多的数据到 buf 数组缓冲区中去,然后再返回当前字节数据,如果 if 条件不成立便直接从 buf缓冲区数组返回数据了。
从缓冲类的read()方法内部我们也可以看到也是调用的FileInputStream的read(char[] arg0, int arg1, int arg2)方法。

新IO(NIO)-intsmaze
新IO两大核心对象Channel(通道)和Buffer(缓冲)。
Channel(通道):新IO中所有数据都需要通过通道Channel传输,与传统的流对象的区别在于,Channel可以将制定文件的部分或全部直接映射成buffer。Channel常用方法,map(),read(),write();map()方法用于将Channel对应的部分或全部数据映射成bytebuffer;read()和write()方法用于从buffer中读取数据或向buffer中写入数据。
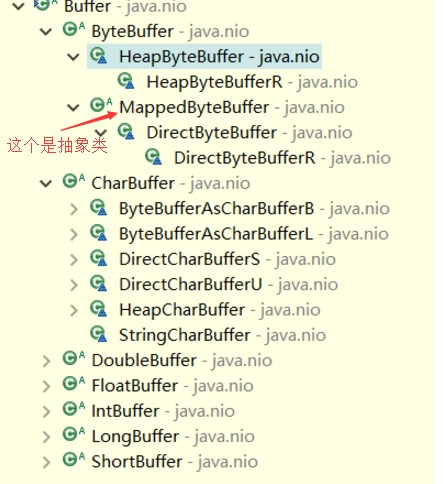
Buffer(缓冲):Buffer是一个数组,发送到channel中的所有对象都必须先放到buffer中,从channel中读取的数据也必须先放到buffer中。Buffer是抽象类,常用的子类是ByteBuffer和CharBuffer(这两个也是抽象的)。
创建缓冲区-intsmaze
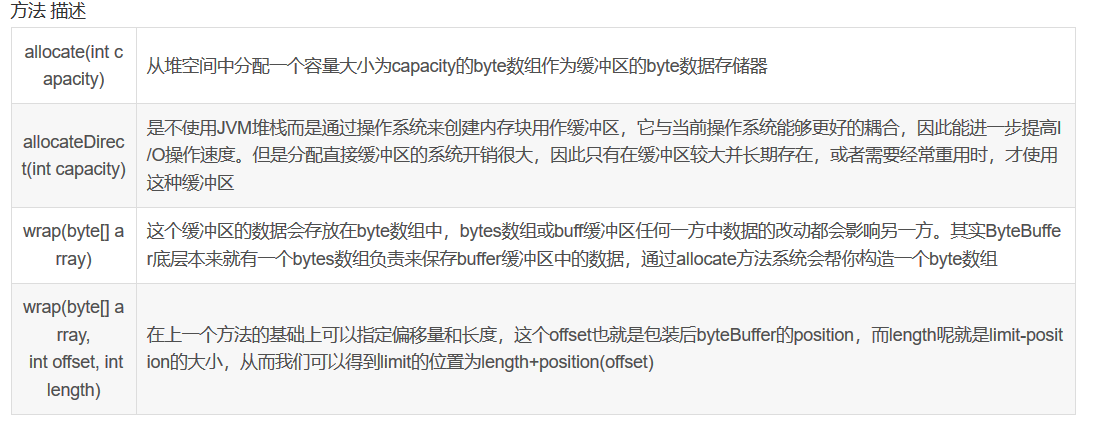
static XxxBuffer allocate(int capacity)//创建一个容量为capacity的XxxBuffer对象,内部创建子类对象为HeapXxxBuffer。
char[] myArray=new char[100];
CharBuffer charBuffer=CharBuffer.wrap(myArray);
CharBuffer charBuffer=CharBuffer.wrap(myArray,12,48);
创建了一个position值为12,limit值为60,容量为myArray.length的缓冲区。
读文件操作-intsmaze
FileInputStream fis = new FileInputStream(file);
FileChannel channel = fis.getChannel(); byte[] bytes = new byte[1024];
ByteBuffer byteBuffer = ByteBuffer.allocate(1024); // channel.read(ByteBuffer) 方法就类似于 inputstream.read(byte)
// 每次read都将读取 1024个字节到ByteBuffer
int len;
while ((len = channel.read(byteBuffer)) != -1) {
byteBuffer.flip();
// 类似与InputStrean的read(byte[],offset,len)方法读取
byteBuffer.get(bytes, 0, len); byteBuffer.clear();
}
channel.close();
fis.close();
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
直接缓冲区-intsmaze
ByteBuffer还有一个特殊的子类DirectByteBuffer(父抽象类为MappedByteBuffer 注意继承层次),用于表示channel将磁盘文件的部分或全部内容映射到内存中后得到的结果。
MappedByteBuffer对象有两种方式获得,channel的map()方法返回或者ByteBuffer.allocateDirect(capacity)。
注意,其他buffer子类没有allocateDirect方法,不支持内容映射的;字节缓冲区跟其他缓冲区最明显的不同在于,它可以成为通道所执行的I/0的源头/或目标。观察源码你会发现通道只接受ByteBuffer作为参数。
// 分配128MB直接内存
ByteBuffer bb = ByteBuffer.allocateDirect(1024 * 1024 * 128);
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
bytebyffer可以是两种类型,一种是基于直接内存(也就是非堆内存);另一种是非直接内存(也就是堆内存)。
对于直接内存来说,JVM将会在IO操作上具有更高的性能,因为它直接作用于本地系统的IO操作。
直接内存使用allocateDirect创建,它比申请普通的堆内存需要耗费更高的性能。不过,这部分的数据是在JVM之外的,因此它不会占用应用的内存。当你有很大的数据要缓存,并且它的生命周期又很长,那么就比较适合使用直接内存。只是一般来说,如果不是能带来很明显的性能提升,还是推荐直接使用堆内存。
直接内存并不是虚拟机运行时数据区的一部分,也不是Java
虚拟机规范中定义的内存区域。在JDK1.4 中新加入了NIO(New
Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O 方式,它可以使用native
函数库直接分配堆外内存,然后通过一个存储在Java堆中的DirectByteBuffer
对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
从数据流的角度,非直接内存是下面这样的作用链:
本地IO-->直接内存-->非直接内存-->直接内存-->本地IO
而直接内存是:
本地IO-->直接内存-->本地IO
内存文件映射(属于直接缓冲区)-intsmaze
按照jdk文档的官方说法,内存映射文件也属于JVM中的直接缓冲区。
File file=new File("D://develop/CodeWorkSpace/1.txt");
FileInputStream fr = new FileInputStream(file);
FileChannel fileChannel=fr.getChannel();
// map()将channel对应的全部或部分数据映射成MappedByteBuffer,第一个参数是映射模式,第二,第三参数就是用于将fileChannel哪些数据映射到buffer中。
// MappedByteBuffer mappedByteBuffer=fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, file.length());//将fileChannel全部数据映射到buffer
MappedByteBuffer mappedByteBuffer=fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, 20);
CharBuffer cb=Charset.forName("UTF-8").newDecoder().decode(mappedByteBuffer);
System.out.println(cb);
mappedByteBuffer.clear();
mappedByteBuffer=fileChannel.map(FileChannel.MapMode.READ_ONLY, 21, 20);
cb=Charset.forName("UTF-8").newDecoder().decode(mappedByteBuffer);
System.out.println("-------------------------");
System.out.println(cb);
mappedByteBuffer.clear();
内存映射文件特别适合于对大文件的操作,JAVA中的限制是最大不得超过Integer.MAX_VALUE,即2G左右,我们可以通过分次映射文件(channel.map)的不同部分来达到操作整个文件的目的。
java中提供了3种内存映射模式-intsmaze
只读模式:如果程序试图进行写操作,则会抛出ReadOnlyBufferException异常;
读写模式:通过内存映射文件的方式写或修改文件内容的话是会立刻反映到磁盘文件中去的,别的进程如果共享了同一个映射文件,那么也会立即看到变化!而不是像标准IO那样每个进程有各自的内核缓冲区,比如JAVA代码中,没有执行IO输出流的 flush()或者close() 操作,那么对文件的修改不会更新到磁盘去,除非进程运行结束;
专用模式:采用的是OS的“写时拷贝”原则,即在没有发生写操作的情况下,多个进程之间都是共享文件的同一块物理内存(进程各自的虚拟地址指向同一片物理地址),一旦某个进程进行写操作,那么将会把受影响的文件数据单独拷贝一份到进程的私有缓冲区中,不会反映到物理文件中去。
MappedByteBuffer,可被通道读写-intsmaze
MappedByteBuffer提供的方法:
load():加载整个文件到内存
isLoaded():判断文件数据是否全部加载到了内存
force():将缓冲区的更改刷新到磁盘
加载文件所使用的内存是Java堆区之外,并驻留共享内存,允许两个不同进程共享文件。
不要频繁调用MappedByteBuffer.force()方法,这个方法意味着强制操作系统将内存中的内容写入磁盘,所以如果你每次写入内存映射文件都调用force()方法,你将不会体会到使用映射字节缓冲的好处,相反,它(的性能)将类似于磁盘IO的性能。
直接内存DirectMemory大小设置-intsmaze
直接内存DirectMemory的大小默认为 -Xmx 的JVM堆的最大值,但是并不受其限制(理论上说受限于进程的虚拟地址空间大小,比如 32位的windows上,每个进程有4G的虚拟空间除去 2G为OS内核保留外,再减去 JVM堆的最大值,剩余的才是DirectMemory大小。),而是由JVM参数 MaxDirectMemorySize单独控制
/**
* @author:YangLiu
* @describe:
* 测试一:设置JVM参数-Xmx100m,运行异常,因为如果没设置-XX:MaxDirectMemorySize,则默认与-Xmx参数值相同
* ,分配128M直接内存超出限制范围。
* 测试用例2:设置JVM参数-Xmx256m,运行正常,因为128M小于256M,属于范围内分配。
* 测试用例3:设置JVM参数-Xmx256m
* -XX:MaxDirectMemorySize=100M,运行异常,分配的直接内存128M超过限定的100M。
* 测试用例4:设置JVM参数
* -Xmx768m,运行程序观察内存使用变化,会发现clean()后内存马上下降,说明使用clean()方法能有效及时回收直接缓存。
*/
public class DirectByteBufferTest {
public static void main(String[] args) throws InterruptedException {
// 分配128MB直接内存
ByteBuffer bb = ByteBuffer.allocateDirect(1024 * 1024 * 128); TimeUnit.SECONDS.sleep(20);
System.out.println("intsmaze");
// 清除直接缓存
((DirectBuffer) bb).cleaner().clean();
System.out.println("intsmaze");
}
}
堆外内存,其实就是不受JVM控制的内存。
1 减少了垃圾回收的工作
2 加快了复制的速度。因为堆内在flush到远程时,会先复制到直接内存(非堆内存),然后在发送;而堆外内存相当于省略掉了这个工作。
为了快速构建项目,使用高性能框架是我的职责,但若不去深究底层的细节会让我失去对技术的热爱。
探究的过程是痛苦并激动的,痛苦在于完全理解甚至要十天半月甚至没有机会去应用,激动在于技术的相同性,新的框架不再是我焦虑。
每一个底层细节的攻克,就越发觉得自己对计算机一无所知,这可能就是对知识的敬畏。
(代码篇)从基础文件IO说起虚拟内存,内存文件映射,零拷贝的更多相关文章
- (理论篇)从基础文件IO说起虚拟内存,内存文件映射,零拷贝
为了快速构建项目,使用高性能框架是我的职责,但若不去深究底层的细节会让我失去对技术的热爱. 探究的过程是痛苦并激动的,痛苦在于完全理解甚至要十天半月甚至没有机会去应用,激动在于技术的相同性,新的框架不 ...
- Qt-QML-C++交互实现文件IO系统-后继-读取XML文件和创建XML文件
在前面两篇中,大致完成了一个文件IO的读和写操作.前面两篇文章链接 http://blog.csdn.net/z609932088/article/details/71488250 http://bl ...
- SprinMVC中文件上传只在内存保留一份拷贝
背景:web项目里经常有上传文件的模块,某些特殊场景下,上传文件的人不希望在服务器留存一份原始文件,这个时候就需要把文件放到内存里了. 笔者调试了一下springmvc里面的CommonsMultip ...
- Python文件基础操作(IO入门1)
转载请标明出处: http://www.cnblogs.com/why168888/p/6422270.html 本文出自:[Edwin博客园] Python文件基础操作(IO入门1) 1. pyth ...
- LWJGL3的内存管理,第一篇,基础知识
LWJGL3的内存管理,第一篇,基础知识 为了讨论LWJGL在内存分配方面的设计,我将会分为数篇随笔分开介绍,本篇将主要介绍一些大方向的问题和一些必备的知识. 何为"绑定(binding)& ...
- Linux C 文件IO
文件IO 2021-05-31 12:46:14 星期一 目录 文件IO 基础IO open 错误 creat read 一个例子 write close lseek 文件空洞 unlink删除 io ...
- Unix环境高级编程:文件 IO 原子性 与 状态 共享
参考 UnixUnix环境高级编程 第三章 文件IO 偏移共享 单进程单文件描述符 在只有一个进程时,打开一个文件,对该文件描述符进行写入操作后,后续的写入操作会在原来偏移的基础上进行,这样就可以实现 ...
- Java - 文件(IO流)
Java - 文件 (IO) 流的分类: > 文件流:FileInputStream | FileOutputStream | FileReader | FileWriter ...
- linux 中的页缓存和文件 IO
本文所述是针对 linux 引入了虚拟内存管理机制以后所涉及的知识点.linux 中页缓存的本质就是对于磁盘中的部分数据在内存中保留一定的副本,使得应用程序能够快速的读取到磁盘中相应的数据,并实现不同 ...
随机推荐
- 自动化测试基础篇--Selenium Python环境搭建
学习selenium python需要的工具: 1.浏览器 2.Python 3.Selenium 4.FireBug(Firefox) 5.chromedriver.IEDriverServer.g ...
- CentOS 7下systemd是如何stop mysql服务的
[背景] 有同事在研究mongo的服务启动方式,讨论到mysql5.7的服务管理时一起做了下面测试. MySQL5.7是用systemd来管理service的,它的配置文件/usr/lib/sys ...
- iTween for Unity
你曾经在你的游戏中制作过动画吗?问这个问题可能是愚蠢的,几乎每个Game都有动画,虽然有一些没有,但你必须处理有动画和没有动画.让我们结识 ITween. iTween 官方网站:http://itw ...
- 简易 Token 验证的实现
简易 Token 验证的实现 前言 在我们的服务器和客户端的交互中,由于我们的业务中使用 RESTful API 的形式和客户端交互,而 API 又是无状态的,无法帮助我们识别这一次和上一次的请求由谁 ...
- 基础数据类型之AbstractStringBuilder
String内部是一个private final char value[]; 也就意味着每次调用的各种处理方法,返回的字符串都是一个新的,性能上,显然.... 所以,对于可变字符序列的需求是很明确的 ...
- CF895C: Square Subsets && 【BZOJ2844】albus就是要第一个出场
CF895C: Square Subsets && [BZOJ2844]albus就是要第一个出场 这两道题很类似,都是线性基的计数问题,解题的核心思想也一样. CF895C Squa ...
- C#常见委托のdelegate定义,Func,Action,Predicate总结
委托,顾名思义,就是让其他代理,本质就是为具有共性方法组定义一个方法模板:(交流可以加qq群:435226676) 委托常见的方式有一般委托显示定义,Func<T,TResult> (T, ...
- MySQL的用户的创建以及远程登录配置
最近工作中使用HIve工具,因此搭建了一个Hive的测试环境.通常我们都将Hive的元数据信息存储在外界的MySQL中,因此需要安装并配置MySQL数据库.接下来将讲解MySQL的安装以及配置过程. ...
- 理解 JavaScript 中的 for…of 循环
什么是 for…of 循环 for...of 语句创建一个循环来迭代可迭代的对象.在 ES6 中引入的 for...of 循环,以替代 for...in 和 forEach() ,并支持新的迭代协议. ...
- http://blog.csdn.net/pipisorry/article/details/51471222
这个博主很有意思 机器学习之用Python从零实现贝叶斯分类器 参数估计:贝叶斯思想和贝叶斯参数估计