目标检测(二)SSPnet--Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognotion
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
以前的CNNs都要求输入图像尺寸固定,这种硬性要求也许会降低识别任意尺寸图像的准确度。为避免这个问题,何凯明等人在该论文中提出了一种池化策略,“spatial pyramid pooling(SSP)“,即空间金字塔池化。带有该池化层的网络被称为SPPnet,对任何尺寸的输入图像都能生成固定长度的特征表示。由此可见,理论上SPPnet可以改进所有基于CNN的图像分类等方法中。在性能上,SPPnert能够大幅提升CNN的准确度。同样,在object detection方面也有重要应用。使用SPPnet时可以只计算一次整个图像的feature maps,然后在featrue maps中选择任意region(sub-images)进行pooling以产生固定长度的特征给后面的detectors。这样就可以避免重复地计算卷积特征。因此,使用SPPnet的话可以大幅降低网络的训练和测试时间。
以下对论文部分内容进行记录:
2.2 The Spatial Pyramid Pooling Layer
卷积层的输入是任意size的,输出的尺寸会与之对应,因为也是一个变化的size。但是分类器(SVM/softmax)或者全连接层的输入需要是fixed-length vectors。这样的vectors可以使用Bag-of-Words(BoW)法池化特征得到,但是该方法会带来空间信息丢失的问题,而论文中提出的空间金字塔则可以通过在本地空间容器中池化从而保留空间信息。那些容器与图像的size成正比,且不管图像的尺寸如何变化,容器的数量都是固定的。
在CNN中使用Spatial Pyramid Pooling Layer时需要将网络的最后一个池化层换成一个空间金字塔池化层。Figure 3说明了具体的方法。
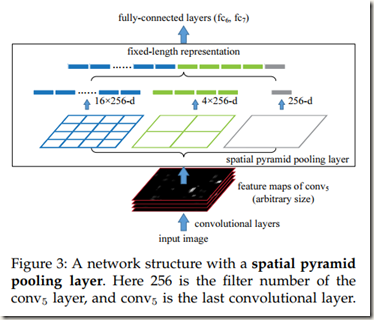
从图中可以看出,在每个容器(bin, 每个含多通道的小方格,图中有21个bins)中我们池化每个filter(Figure 3中单通道的小方格)的响应(论文中使用的都是max pooling);空间池化的输出是kM-dimentional vectors,其中M是bins的数量,k是最后一个卷积层中filters的数量,即通道数;fixed-dimentional vectors被输入到全连接层。
上图中最终提取的特征长度为16x256+4x256+256,即16c+4c+c
4. SPP-net for Object Detection
作者回顾了最近在目标检测领域最顶尖的R-CNN算法,发现由于R-CNN重复将深度卷积网络应用于每幅图像的数千个windows,导致R-CNN在训练和测试时耗时较长。SPPnet正好可以有效地缓解该问题。方法大致如下:先计算一次整幅图像的feature maps(可能是多通道),然后对每个candidate window在feature maps中的映射区域进行空间金字塔池化,以得到该window的固定长度特征(Figrure)。由此可见,卷积网络只进行一次耗时的卷积计算,这让R-CNN快几个数量级。
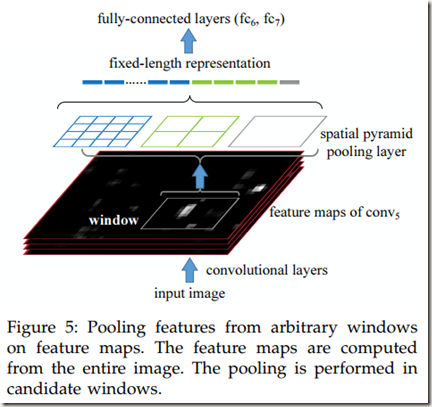
论文中的方法从feature maps(可能是multi-scale,即多通道)的rigion中得到windows的features,而R-CNN直接从所有Image regions中提取。
4.1 Detection Algorithm
算法过程:
- 使用selective search的‘fast’模式从每一幅图像产生大约2000个candidate windows
- 调整图像的大小使得min(w,h)=s,即图像的最短边长度为s,并且计算整幅图像的feature maps
- 暂时使用single-size trained(指输入图像是固定尺寸的,还有一种multi-size训练),在每个candidate window中使用4级空间金字塔进行池化(1x1,2x2,3x3,6,x6,总共有50 bins),得到一个12800-d(256x50)的representation。
- 将上一步得到的所有candidate windows的representations提供给网络的全连接层(R-CNN也有全连接层)计算得到features
- 使用线性SVMs根据features给candidate windows打分,然后对scored windows使用非极大值抑制,阈值取0.3(每一类的二值线性SVM classifier是使用上一步得到的features训练的)
- 利用features进行bounding-box regression
SVMs的训练:将ground-truth windows标记为Positive examples,将与一个positive example交叉比最多0.3的candidate Windows标记为negative examples。和R-CNN中SVMs的训练类似,IoU大于0.3且不是positive examples的windows会被忽略。同时,那些与另一个negative example的IoU大于0.7的negative examples会被移除,不再被视为negative examples。论文中训练SVMs使用的是standard hard negative mining。在测试时,SVMs classifier被用来给candidate windows打分,然后对打过分的windows使用非极大值抑制。
multi-scale feature extraction 能够进一步改善算法:论文中将image 尺度调整为min(w,h)=s,s属于{480,576,688,864,1200},并且计算每个scale的feature maps。可以通过逐个通道池化的方法结合从每个尺度提取到的特征,也就是训练的时候在epoch中首先训练一个尺寸产生一个Model,然后加载该Model训练第二个尺度,直到训练完所有的尺寸为止。但是作者根据经验发现了另一种可以带来更好效果的方法:先将image resize到五个尺度:480,576,688,864,1200,加自己6个。然后在map window to feature map一步中,选择ROI框尺度在{6个尺度}中大小最接近224x224的那个尺度下的feature maps中提取对应的roi feature。这样做可以提高系统的准确率。同样,该方法也只需要在每个scale上计算一次卷积,不管candidate Windows的数量。
window 到Feature maps的映射关系:
假设(x’,y’)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关: (x,y)=(S*x’,S*y’)。那么通过(x,y)坐标求解(x’,y’)的计算公式如下:

式中S就是CNN中所有的strides的乘积,包含了池化、卷积的stride
SPPnet与R-CNN的相同点:它们都遵循着提取候选框、提取特征、分类几个步骤;在提取特征后都使用了SVM进行分类;训练都分为多个阶段,复杂且耗时;features都需要写入硬盘。
SPPnet与R-CNN的不同点:R-CNN要对每个缩放后的region proposal计算卷积,而SPPnet只需要计算一次整幅图像的卷积,因此SPPnet的效率比R-CNN高得多

SPPnet明显的缺陷:与R-CNN一样,SPPnet的训练分为多个阶段,涉及到提取特征、微调网络、训练SVMs和最后的bounding-box regressors拟合;特征需要写入硬盘;另外,不像R-CNN,SPPnet在微调时不能更新空间金字塔池化层之前的卷积层参数,这一点限制了深度网络的精度。关于最后一点其实不准确,SPPnet也可以反向传播,但是会很复杂,可以参见知乎。本文作者给出的解释如下图:

而Ross Girshick在论文《Fast R-CNN》中认为SPPnet在微调时不能更新卷积层参数,给出的解释如下:


显然,Ross Girshick其实是认为当训练来自不同图像的ROIs时反向传播经过SPP 层的效率非常低下,这时更新卷积层参数耗时较长,不能更新卷积层参数,而不是不可以更新。
至于Ross Girshick为什么说SPP层反向时效率非常低,网上的解释如下:
SPP-Net中fine-tuning的样本是来自所有图像的所有RoI打散后均匀采样的,即RoI-centric sampling,这就导致SGD的每个batch的样本来自不同的图像,需要同时计算和存储这些图像的Feature Map,过程变得expensive. Fast R-CNN采用分层采样思想,先采样出N张图像(image-centric sampling),在这N张图像中再采样出R个RoI,具体到实际中,N=2,R=128,同一图像的RoI共享计算和内存,也就是只用计算和存储2张图像,消耗就大大减少了
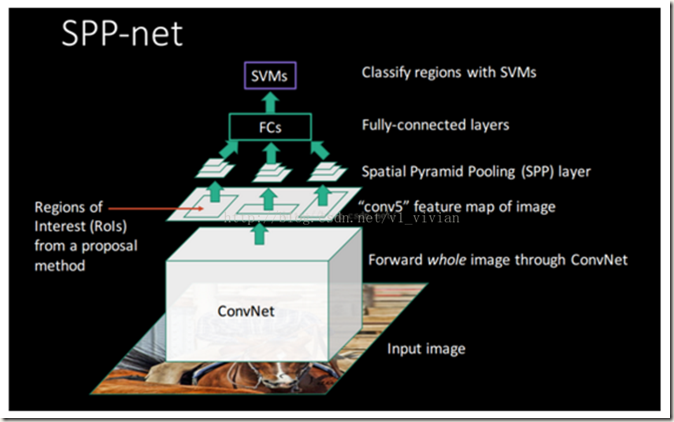
完整的SPPnet模型示意图:
参考链接:
- https://blog.csdn.net/v1_vivian/article/details/73275259
- https://www.cnblogs.com/CodingML-1122/p/9043122.html
目标检测(二)SSPnet--Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognotion的更多相关文章
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- SPP Net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)论文理解
论文地址:https://arxiv.org/pdf/1406.4729.pdf 论文翻译请移步:http://www.dengfanxin.cn/?p=403 一.背景: 传统的CNN要求输入图像尺 ...
- 论文解读2——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
背景 用ConvNet方法解决图像分类.检测问题成为热潮,但这些方法都需要先把图片resize到固定的w*h,再丢进网络里,图片经过resize可能会丢失一些信息.论文作者发明了SPP pooling ...
- SPP NET (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
1. https://www.cnblogs.com/gongxijun/p/7172134.html (SPP 原理) 2.https://www.cnblogs.com/chaofn/p/9305 ...
- 空间金字塔池化(Spatial Pyramid Pooling,SPP)
基于空间金字塔池化的卷积神经网络物体检测 原文地址:http://blog.csdn.net/hjimce/article/details/50187655 作者:hjimce 一.相关理论 本篇博文 ...
随机推荐
- 如何加大tomcat可以使用的内存
tomcat默认可以使用的内存为128MB,在较大型的应用项目中,这点内存是不够的,需要调大. linux下,在文件{tomcat_home}/bin/catalina.sh的前面, 增加如下设置:J ...
- mybatis #与$区别
mybatis #与$区别 #{}变量解析到SQL有带引号字符串:如查询条件变量如:select * from user where name = #{name}; 为:select * from u ...
- Linux系统中文显示
# Linux系统中文显示 ### 配置文件路径------------------------------ 路径`/etc/locate.conf` ### 查看系统当前字符集----------- ...
- NO.1 hadoop简介
第一次接触这个时候在网上查了很多讲解,以下很多只是来自网络. 1.Hadoop (1)Hadoop简介 Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层 ...
- React Native常用组件之ListView
1. ListView常用属性 ScrollView 相关属性样式全部继承 dataSource ListViewDataSource 设置ListView的数据源 initialListSize n ...
- AOP 技术原理——代理模式全面总结
前言 非常重要的一个设计模式,也很常见,很多框架都有它的影子.定义就不多说了.两点: 1.为其它对象提供一个代理服务,间接控制对这个对象的访问,联想 Spring 事务机制,在合适的方法上加个 tra ...
- [Z] 从Uncaught SyntaxError: Unexpected token ")" 问题看javascript:void的作用
https://blog.csdn.net/hongweigg/article/details/78094338 问题 在前端编程中,突然出现Uncaught SyntaxError: Unex ...
- 如何查看已经安装的nginx、apache、mysql和php的编译参数
1.nginx编译参数: nginx -V(大写) #注意:需保证nginx在环境变量中,或者使用这样的形式:/user/local/nginx/sbin/nginx -V 2.apache编译参数 ...
- Linux常见问题整理
1. 操作系统应该要控制硬件的哪些单元? 运算单元.控制单元.寄存器组.总线接口单元.输入/输出接口单元. 2. 一个较为完整的操作系统应该包含哪些部分? 比较完整的操作系统应该包含两个组件,一个是核 ...
- ReentrantLock可重入锁的理解和源码简单分析
import java.util.concurrent.TimeUnit; import java.util.concurrent.locks.ReentrantLock; /** * @author ...