web自动化测试---xpath方式定位页面元素
在实际应用中,如果存在多个相同元素,包括属性相同时,一般会选用这种方式,当然如果定位属性唯一的话,也是可以使用的,不过这种方式没有像id,tag,name等容易理解,下面讲下xpath定位元素的方法
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择 |
| @ | 选取属性 |
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
我们就以百度首页右上一排的元素来定位,一般来说通过find_element_by_link来定位,这里我们只介绍xpath来定位的方式
我们查看下原始的百度页面中tag='a',class='mnav'的元素有多少:
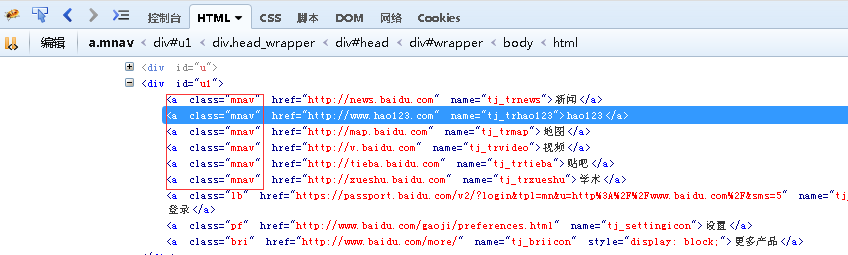
总共有6个,下面我们就来定位
1、定位第一个新闻的链接,语句如下:
driver.find_element_by_xpath('//a[@class="mnav"][1]').click()
这里用到的是短xpath,即如果不是从web的根开始查找元素,那么用 // 来表示,如果是根开始那只有一个 / 就可以了
2、定位最后一个学术链接,语句如下:
driver.find_element_by_xpath('//a[@class="mnav"][last()]').click()
#如果显示不是最后一个元素,可以写成如下:
driver.find_element_by_xpath('//a[@class-"mnav"][not last()]')
3、定位倒数第二个贴吧链接,语句如下:
driver.find_element_by_xpath('//a[@class="mnav"][last()-1]').click()
4、如果需要选取前俩个元素,则语句如下:
driver.find_element_by_xpath('//a[@class="mnav"][position()<3]')
5、我们也可以通过下面语句定位学术链接,语句如下:
driver.find_element_by_xpath('//a[@name="tj_trxueshu"]').click()
6、如果需要选取不在一起的俩个元素(比如地图和贴吧),那么可以参考如下语句:
driver.find_element_by_xpath('//a[@name="tj_trmap"]|//a[@name="tj_trtieba"')
7、通过tag也可以也可以选取:
driver.find_element_by_xpath('//*[local-name()="a"]')
#或者通过tag以a开头来获取:
driver.find_element_by_xpath('//*[starts-with(local-name(),"a")]')
#或者通过tag包含a来获取:
driver.find_element_by_xpath('//*[contains(local-name(),"a")]')
#或者通过tag的长度来获取:
dirver.find_element_by_xpath('//*[string-length(local-name())=5]')
8、父兄节点
<div>
<a id="" href="www.baidu.com">我是第1个a标签</a>
<p>我是p标签</p>
<a id="" href="www.baidu.com">我是第2个a标签</a>
<a id="" href="www.baidu.com">我是第3个a标签</a>
<a id="" href="www.baidu.com">我是第4个a标签</a>
<p>我是p标签</p>
<a id="" href="www.baidu.com">我是第5个a标签</a>
</div>
获取第三个a标签的下一个a标签:"//a[@id='3']/following-sibling::a[1]" 获取第三个a标签后面的第N个标签:"//a[@id='3']/following-sibling::*[N]" 获取第三个a标签的上一个a标签:"//a[@id='3']/preceding-sibling::a[1]" 获取第三个a标签的前面的第N个标签:"//a[@id='3']/preceding-sibling::*[N]" 获取第三个a标签的父标签:"//a[@id=='3']/.."
web自动化测试---xpath方式定位页面元素的更多相关文章
- web自动化测试---css方式定位页面元素
css方式定位的方法也有很多,相较于xpath更灵活一点,下面就介绍下使用方法(以百度输入框为例) 1.通过tag来定位,可以写成如下: driver.find_element_by_css_sele ...
- By.Xpath快速定位页面元素常用方法
先看一看xpath的语法 我们将在下面的例子中使用这个 XML 文档. <?xml version="1.0" encoding="ISO-8859-1" ...
- 定位页面元素之xpath详解以及定位不到测试元素的常见问题
一.定位元素的方法 id:首选的识别属性,W3C标准推荐为页面每一个元素设置一个独一无二的ID属性, 如果没有且很难找到唯一属性,解决方法:(1)找开发把id或者name加上.如果不行,解决思路可以是 ...
- selenium第三课(selenium八种定位页面元素方法)
selenium webdriver进行元素定位时,通过seleniumAPI官方介绍,获取页面元素的方式一共有以下八种方式,现按照常用→不常用的顺序分别介绍一下. 官方api地址:https://s ...
- selenium webdriver学习(四)------------定位页面元素(转)
selenium webdriver学习(四)------------定位页面元素 博客分类: Selenium-webdriver seleniumwebdriver定位页面元素findElemen ...
- selenium定位页面元素的一件趣事
PS:本博客selenium分类不会记载selenium打开浏览器,定位元素,操作页面元素,切换到iframe,处理alter.confirm和prompt对话框这些在网上随处可见的信息:本博客此分类 ...
- 使用CSS选择器定位页面元素
摘录:http://blog.csdn.net/defectfinder/article/details/51734690 CSS选择器也是一个非常好用的定位元素的方法,甚至比Xpath强大.在自动化 ...
- Selenium 定位页面元素 以及总结页面常见的元素 以及总结用户常见的操作
1. Selenium常见的定位页面元素 2.页面常见的元素 3. 用户常见的操作 1. Selenium常见的定位页面元素 driver.findElement(By.id());driver.fi ...
- Python+Selenium自动化-定位页面元素的八种方法
Python+Selenium自动化-定位页面元素的八种方法 本篇文字主要学习selenium定位页面元素的集中方法,以百度首页为例子. 0.元素定位方法主要有: id定位:find_elemen ...
随机推荐
- 微服务SpringCloud无法进行服务消费
最近用SpringCloud做微服务,一直无法成功进行服务消费. 我使用的服务消费者是Feign,声明式调用服务提供者. 排查过程 1.检查服务提供者: (1)对提供的方法进行测试,确保提供的服务没有 ...
- ELK填坑总结和优化过程
做了几周的测试,踩了无数的坑,总结一下,全是干货,给大家分享~ 一.elk 实用知识点总结 1.编码转换问题(主要就是中文乱码) (1)input 中的codec => plain 转码 cod ...
- APIcloud微信支付和支付宝支付(方案2,主要在后台进行)
支付宝代码 var aliPay = api.require('aliPay'); api.ajax({ url: yuming+'index.php/api/Alipay/getOrder', me ...
- [leetcode]14. Longest Common Prefix 最长公共前缀
Write a function to find the longest common prefix string amongst an array of strings. If there is n ...
- 以太坊Inner Transaction合约内充值转账
- android 平台 java和javascript 通信问题 A WebView method was called on thread 'JavaBridge'.
java.lang.RuntimeException: java.lang.Throwable: A WebView method was called on thread 'JavaBridge ...
- Myeclipse中的tomcat项目的内存溢出
tomcat中 内存溢出 在这里写上 -Xmx1024M -Xms1024M -XX:NewSize=128m -XX:MaxNewSize=128m -XX:PermSize=128m -XX:Ma ...
- JSP内置对象seesion
什么是session session表示客户端与服务器的一次会话 Web中的session指的是用户在浏览某网站时,从进入网站到浏览器关闭所经过的这段时间,也就是用户浏览这个网站所花费的时间 从上述定 ...
- Java 浮点数相加
刚刚遇到个需求,需要对金额求和,上线的时候才知道这时个,这个字段是个小数. 随手就改了个Double ,然后,跑下,没啥问题,直接上线了 然后,就fuck 了 加出一大堆的小数,大概是这样的 pack ...
- CPU寻址
CPU组成和寄存器 1)CPU由运算器.控制器.寄存器等器件组成,这些器件靠内部总线相连 2)寄存器是CPU的组成部分,用来暂存指令.数据和地址,CPU对其读写速度是最快的,不需要IO传输 存储单元 ...