Hadoop之MapReduce(一)简介及简单案例
简介
Hadoop MapReduce是一个分布式运算编程框架,基于该框架能够容易地编写应用程序,进而处理海量数据的计算。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想;Map 负责"分",即把复杂的任务分解为若干个"简单的任务"来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。Reduce 负责"合",即对 map 阶段的结果进行全局汇总。
MapReduce的执行流程
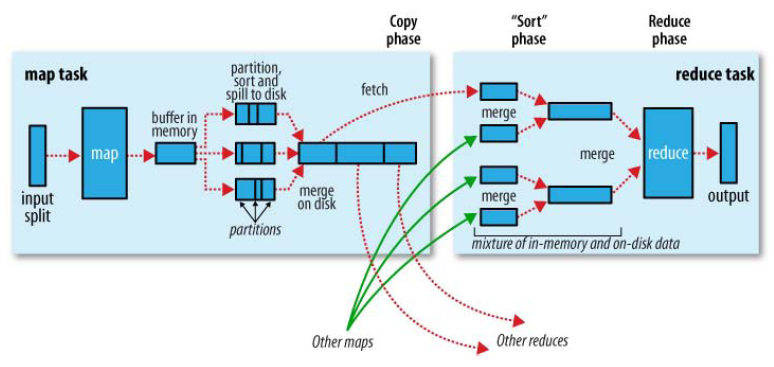
1,由默认读取数据组件TextInputFormat一行一行的读(input)
2,然后做相应的处理(由我们自己编写的Mapper程序做处理),最终context.write出<key,value>到内存缓冲区(图中的buffer in memory)
3,memory缓冲区默认100M,如果满了(或者到了末尾)则spill to disk(溢出到磁盘,最后merge(合并)),如果有分区或者排序的话,这里会分区且排序
4,由我们自己的程序控制一共有几个reduce,每个reduce会去磁盘上拉去属于自己的分区,进而执行我们自己编写的Reducer程序进行处理数据,最终context.write出<key,value>
5,由输出数据组件TextOutPutFomat输出到我们制定的位置(output)
简单示例
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
首先,编写Mapper程序(需要继承org.apache.hadoop.mapreduce.Mapper并重写map方法):
package com.zy.hadoop.mr.wordcount; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* TODO 本类就是mr程序map阶段调用的类 也是就maptask
* KEYIN :map输入kv中key
* 在默认读取数据的组件下TextInputFormat(一行一行读)
* key:表示是改行的起始偏移量(光标所在的偏移值)
* value:表示的改行内容
* 用long来表示
* <p>
* VALUEIN:map输入kv中的value
* 在默认读取数据的组件下TextInputFormat(一行一行读)
* 表明的是一行内容 所有是String
* <p>
* KEYOUT:map输出的kv中的key
* 在我们的需求中 把单词做为输出的key 所以String
* <p>
* VALUEOUT:map输出kv中的value
* 在我们的需求中 把单词的次数1做为输出的value 所以int
* <p>
* Long String是jdk自带的数据类型
* 在网络传输序列化中 hadoop认为其及其垃圾 效率不高 所以自己封装了一套 数据类型 包括自己的序列化机制(Writable)
* Long----->LongWritable
* String--->Text
* int------>IntWritable
* null----->nullWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* @param key
* @param value
* @param context TODO 该方法就是map阶段具体业务逻辑实现的所在地方
* map方法调用次数 取决于TextInputFormat如何读数据
* TextInputFormat读取一行数据--->封装成<k,v>--->调用一次map方法
* <p>
* hello tom hello alex hello--> <0,hello tom hello alex hello>
* alex tom mac apple --> <24,alex tom mac apple>
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿其中一行内容转成String
String line = value.toString();
//按照分隔符分隔
String[] words = line.split(" ");
//遍历数组 单词出现就标记1
for (String word : words) {
//使用哦context把map处理完的结果写出去
context.write(new Text(word), new IntWritable(1)); //<hello,1>
}
}
}
然后,编写Reducer类(需要继承org.apache.hadoop.mapreduce.Reducer并重写reduce方法):
package com.zy.hadoop.mr.wordcount; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* TODO 该类就是mr程序reduce阶段运行的类 也就是reducetask
* KEYIN: reduce输入的kv中k 也就是map输出kv中的k 是单词 Text
* <p>
* VALUEIN:reduce输入的kv中v 也就是map输出kv中的v 是次数1 IntWritable
* <p>
* KEYOUT:reduce输出的kv中k 在本需求中 还是单词 Text
* <p>
* VALUEOUT:reduce输出的kv中v 在本需求中 是单词的总次数 IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个变量
int count = 0;
//遍历values 累计里面的值
for (IntWritable value : values) {
count += value.get();
}
//输出结果
context.write(key, new IntWritable(count));
}
}
最后,编写执行类:
package com.zy.hadoop.mr.wordcount; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* TODO 该类就是mr程序运行的主类 主要用于一些参数的指定拼接 任务的提交
* TODO 比如使用的是哪个mapper 哪个reducer 输入输出的kv是什么 待处理的数据在那 输出结果放哪
*/
public class WordCountRunner {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); //指定mr采用本地模式运行 本地测试用
conf.set("mapreduce.framework.name", "local"); //使用job构建本次mr程序
Job job = Job.getInstance(conf); //指定本次mr程序运行的主类
job.setJarByClass(WordCountRunner.class); //指定本次mr程序的mapper reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class); //指定本次mr程序map阶段的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //指定本次mr程序reduce阶段的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //设置使用几个Reduce执行
job.setNumReduceTasks(2); //指定本次mr程序处理的数据目录 输出结果的目录
// FileInputFormat.setInputPaths(job, new Path("/wordcount/input"));
// FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); //本地测试用
FileInputFormat.setInputPaths(job, new Path("D:\\wordcount\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\wordcount\\output"));//输出的文件夹不能提前创建 否则会报错 //提交本次mr的job
//job.submit(); //提交任务 并且追踪打印job的执行情况
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : -1);
}
}
如果需要将程序提交给YARN集群执行:
1,将程序打成jar包,上传到集群的任意一个节点上
2,用hadoop命令启动:hadoop xxxxx.jar
Hadoop之MapReduce(一)简介及简单案例的更多相关文章
- asp.net core 身份认证/权限管理系统简介及简单案例
如今的网站大多数都离不开账号注册及用户管理,而这些功能就是通常说的身份验证.这些常见功能微软都为我们做了封装,我们只要利用.net core提供的一些工具就可以很方便的搭建适用于大部分应用的权限管理系 ...
- Java基础之UDP协议和TCP协议简介及简单案例的实现
写在前面的废话:马上要找工作了,做了一年的.net ,到要找工作了发现没几个大公司招聘.net工程师,真是坑爹呀.哎,java就java吧,咱从头开始学呗,啥也不说了,玩命撸吧,我真可怜啊. 摘要: ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop mapreduce框架简介
传统hadoop MapReduce架构(老架构) 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 1.首先用户程序 (JobClient) 提交了一个 job,job ...
- 【Hadoop离线基础总结】MapReduce自定义InputFormat和OutputFormat案例
MapReduce自定义InputFormat和OutputFormat案例 自定义InputFormat 合并小文件 需求 无论hdfs还是mapreduce,存放小文件会占用元数据信息,白白浪费内 ...
- oozie与mapreduce简单案例
准备工作 拷贝原来的模板 mkdir oozie-apps cd oozie-apps/ cp -r ../examples/apps/mar-reduce . mv map-reduce mr-w ...
- Hadoop MapReduceV2(Yarn) 框架简介[转]
对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详的卓越开源分布式文件存储及处理框架,对于 Hadoop 框架的介绍在此不再累述,读者可参考 Hadoop 官方简介.使用和学习过老 H ...
随机推荐
- warning MSB8004: Output Directory does not end with a trailing slash.
当在VC里编译时,发现这个警告,就是说设置的目录参数不是以反斜杠结束的目录名称,如下: 1>C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\V ...
- CentOS给网站配置Https证书
1.在腾讯云申请域名的证书 2.配置文件 安装相应模块: yum install mod_ssl openssl 编辑配置文件: cd /etc/httpd/conf.d vi jerryqi.con ...
- (十二)break,continue
class Break { //break,continue public static void main(String[] args) { //break for(int i =0;i<=5 ...
- python学习之函数和函数参数
#方法的参数定义和默认参数的定义 def ask_ok(prompt, retries=4, complaint='Yes or no, please!'): while True: ok = inp ...
- 【JD的一人戏】之"小羊踢足球"第一篇
好多次加班后坐的士回家,副驾驶座位后内嵌的显示屏正好在播放一个美食节目,内容就是一个着装怪异的厨子把各种食材分门别类地摆在你面前,然后用小小的锅碗瓢盆慢慢的做出很精致的够一个人吃的分量的各种美食,做好 ...
- HihoCoder - 1236 Scores (五维偏序,分块+bitset)
题目链接 题意:给定n个五维空间上的点,以及m组询问,每组询问给出一个点,求五个维度都不大于它的点有多少个,强制在线. 神仙题 单独考虑每个维度,把所有点按这个维度上的大小排序,然后分成T块,每块用一 ...
- python 爬虫的一些使用技巧
1.最基本的抓站 import urllib2 content = urllib2.urlopen('http://XXXX').read() -2.使用代理服务器这在某些情况下比较有用,比如IP被封 ...
- Dropping tests(二分加01数字)
个人心得:不能说题目太难,而是自己思维太菜,我开始以为这怎么都想不到的,但是学长说不是很简单吗,好吧我信了,我太low. 其实单纯二分只用于搜索,但是这种逆向答案二分确实比较难理解.给大神代码 [一些 ...
- Xcode7 修改项目名完全攻略
1.先把整个工程文件夹名改为新的工程名. 2 .将旧项目文件夹和Tests文件名夹修改为新的名称,修改后如下图所示 3.右击 ,选择“show content package”(中文:显示包内容),看 ...
- 《Troubleshooting SQL Server》读书笔记-内存管理
自调整的数据库引擎(Self-tuning Database Engine) 长期以来,微软都致力于自调整(Self-Tuning)的SQL Server数据库引擎,用以降低产品的总拥有成本.从SQL ...