【原创】7. MYSQL++中的查询结果获取(各种Result类型)
在本节中,我将首先介绍MYSQL++中的查询的几个简单例子用法,然后看一下mysqlpp::Query中的几个与查询相关的方法原型(重点关注返回值),最后对几个关键类型进行解释。
1. MYSQL++的查询实例
下面的两个例子分别是STORE(所有数据一次性从服务器拉到本地缓存)和USE(将数据一条一条从服务器拉到本地)的使用方式,其中STORE内部实质就是mysql_store( ),而USE实质就是调用了mysql_use( )。
说明,下面的例子虽然使用的都是最为基本的查询过程(即没有使用template sql或者SSQLS),但是这个并不影响我们的讨论,因为遍历结果集的过程是一致的。
STORE
mysqlpp::Query query = conn.query("select item from stock");
mysqlpp::StoreQueryResult res = query.store();
mysqlpp::StoreQueryResult::const_iterator it;
for (it = res.begin(); it != res.end(); ++it)
{
mysqlpp::Row row = *it;
// 第一列 row[0]
// 第二列 row[1]
}
USE
mysqlpp::Query query = conn.query("select * from stock");
mysqlpp::UseQueryResult res = query.use();
while (mysqlpp::Row row = res.fetch_row())
{
row["item"];
row["num"];
}
// Check for error:
// can't distinguish "end of results" and
// error cases in return from fetch_row() otherwise
if (conn.errnum())
{
cout << "Error in fetch_row";
}
从上面的两个例子中我们大致可以看出来,整个结果集的查询过程就是针对相匹配的Result类型,找到ROW,然后逐行或者跳跃着查找。
2. Result相关类型的使用场合
首先让我们回顾mysqlpp::Query中提到的几个方法,以及他们的返回值。以下部分内容直接摘自关于mysqlpp::Query的介绍的内容。
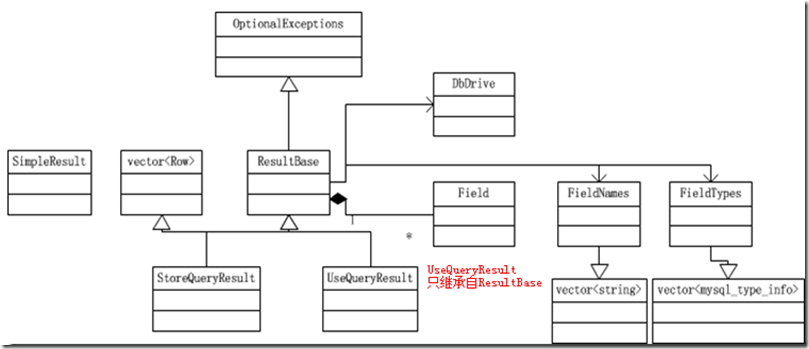
为了讲述方便,我们先来看一下在result.h(Declares classes for holding information about SQL query)中所定义的各种类型的关系。这几个类型后面会仔细说明。
1)
bool mysqlpp::Query::exec(const std::string& str);
这里返回的是bool,表示的是“语句是否执行成功”,我认为适合于那种update, delete,insert,且都不关心有多少rows被touch的情况。
2)
SimpleResult mysqlpp::Query::execute();
这里的SimpleResult正如其名,其中只有如下信息
the last value used for an AUTO_INCREMENT field
(ulonglong insert_id() const)
the number of rows affected by the query
(ulonglong rows( ) const)
any additional information about the query returned by the server(const char* info( ) const)
3)
UseQueryResult mysqlpp::Query::use();
由于use的语义类似于使用游标,也就是支持一行一行地拉出内容,所以UseQueryResult 也就自然而然地支持一些关于fetch row的功能。
4)
StoreQueryResult mysqlpp::Query::store();
StoreQueryResult它本身就是从vector<Row>继承而来,所以它就是vector。所以用户程序可以直接使用下标的形式来获取所有的ROW。这也就是说在这个store之后,所有的ROW的内容都在了这个vecor<Row>里面了。
3. Result相关类型解析
与Result相关的类型主要集中在result.h和result.cpp。
1) SimpleResult
这个类型非常简单,是一个比较单纯的类型,并没有父类。主要的成员变量有3个,分别是
// last value used for an AUTO_INCREMENT field
ulonglong insert_id_; // the number of rows affected by the query
ulonglong rows_; // any additional information about the query returned by the server
std::string info_;
成员方法也比较单纯,就是对上述几个字段的GET,构造函数就是对上述几个字段的SET。
以SimpleResult mysqlpp::Query::execute();为例,让我们来看一下MYSQL++是如何设置这个SimpleResult。 
再来看一下Query::insert_id( ), Query::affected_rows( ), Query::info( ),这几个方法都直接delegate DBDriver的相关函数,直接返回了结果而已。
2) ResultBase
这个类型是StoreQueryResult和UseQueryResult的父类型,该类型其实没有特别的含义,只是作为一个common methods的container而已。但是该类型提供的几乎所有的public methods都是和fields有关的,包括了
- 根据index查找field;
- 根据name查找field;
- 根据index查找到field的名字和属性类型;
- 获取当前所在的field(ResultBase内部会有一个mutable的index名为current_field_用于指明当前fetch_field的是哪一个field,在fetch_field中该index会自增)
该类型的核心成员有如下几个
- Fields(std::vector<Field>) 类型的 fields_
- FieldNames (继承自std::vector<std:: string>)类型的 names_
- FieldTypes ( 继承自std::vector<mysql_type_info>)类型的types_
其中FieldNames和FieldTypes都是被RefCountedPointer包裹着,估计这样做能够节省空间。关于Field类型在后续进行介绍。至于刚才说的几个找field的操作,看着这几个核心成员的类型还是比较好理解的。不就是在vector中不找。
需要额外关注的是以下这个最主要的构造函数

以下几点需要注意,
- names_和types_在new出来之后是不需要显式delete的,因为他们都在智能指针RefCountedPointer包裹着。
- 成员初始化列表中的 fields_(Fields:: size_type(…)) 这一句其实调用的是
explicit std::vector::vector (size_type n, const value_type& val = value_type(), const allocator_type& alloc = allocator_type());
- 从以上构造函数可以看到,其实关于Field的信息还是从DBDriver中拿到的,然后关于FieldNames和FieldTypes的信息,则是通过这两个类型自身的构造函数给实现的(其实就是收到ResultBase*,然后遍历其中的成员变量 fields_ 再各求所需罢了。
- 为什么要有重新将指示field_当前index的指针重置的过程(dbd->field_seek(res, 0))?这是因为方便这个DBDriver再次循环访问这些fields。
3) StoreQueryResult
该类型是同时集成了ResultBase和vecor<Row>类型(请注意了,这个Result居然是一个vecor<Row>!)文档中说,该类型hold results from a SQL query that returns rows: a specialization of std::vector holding Row objects in memory so you get random-access semantics.
说白了,该类型在继承了ResultBase之后,只有以下这个构造函数是比较要紧的了。

有以下几点需要说明
- StoreQueryResult继承自std::vector<Row>
- 在成员初始化列表中,首先调用ResultBase的构造函数
- list_type是std::vector<Row>的typedef,所以在list_type(…)这一行,直接根据DBDriver返回的结果的rows的数量就布置好了vector的长度。
- MYSQL_ROW是MYSQL自带的结构类型(定义域mysql.h中,typedef char **MYSQL_ROW;)
- dbd->fetch_row(MYSQL_RES*)应该只是包装了mysql_fetch_row(MYSQL_RES*)这个MySql C API,而dbd->fetch_lengths(MYSQL_RES*)其实包装的是mysql_fetch_lengths(MYSQL_RES*)这个MYSQL C API,他获取的是整个row的对应的所有field的长度。
- 这一次Query的结果在全部拷贝完之后就释放了(dbd->free_result(res);)
如此一来,所有我们需要的信息都通过构造一个mysqlpp::Row对象来实现了。关于mysqlpp::Row的具体说明请看下文。
4) UseQueryResult
该类型拓展于ResultBase类型。根据MYSQL++ user document的说法,UseQueryResule适用于For these large result sets,a “use” query tells the database server to send the results back one row at a time, to be processed linearly.
该类型的方法比StoreQueryResult丰富多了,主要体现在:
- 可以顺序读取行(mysqlpp::Row fetch_row() const;或者MYSQL_ROW fetch_raw_row() const;)
- 可以获取当前行的各个field的信息(const Field& fetch_field() const; const Field& fetch_field(Fields::size_type i) const)
- 可以获取当前行的所有fields的长度(const unsigned long* fetch_lengths() const;)
值得注意的是,UseQueryResult有一个成员变量
mutable RefCountedPointer<MYSQL_RES> result_;
需要强调的有两点
- MYSQL_RES是 MYSQL C API 中的用于做为资源的结构体,获取一行的函数mysql_fetch_one_row的参数就是MYSQL_RES*
- RefCountedPointer是一个智能指针,但是就在定义这些result类型的result.h中,作者将其针对MYSQL_RES进行了具化,即

很显然,这个是为了在ref count为0时自动调用析构器而准备的,该Destroyer使用mysql_free_result来销毁这里的result_,从而代替默认的delete操作。
接下来,我们来具体看几个函数的实现。
- 构造函数

- 获取fields的信息


请注意,这个result_是一个RefCountedPointer<MYSQL_RES>,所以调用的raw方法将会返回MYSQL_RES*
- 获取一行数据
核心的做法就是利用MYSQL_ROW DBDriver::fetch_row(MYSQL_RES* res) const。其实质也就是调用了mysql_fetch_one_row( )这个C API。然后直接生成一个mysqlpp::Row对象,返回。

【原创】7. MYSQL++中的查询结果获取(各种Result类型)的更多相关文章
- 【面经】面试官:如何以最高的效率从MySQL中随机查询一条记录?
写在前面 MySQL数据库在互联网行业使用的比较多,有些小伙伴可能会认为MySQL数据库比较小,存储不了很多的数据.其实,这些小伙伴是真的不了解MySQL.MySQL的小不是说使用MySQL存储的数据 ...
- mysql中模糊查询的四种用法介绍
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] ...
- mysql中如何查询最近24小时、top n查询
MySQL中如何查询最近24小时. where visittime >= NOW() - interval 1 hour; 昨天. where visittime between CURDATE ...
- Mysql中分页查询两个方法比较
mysql中分页查询有两种方式, 一种是使用COUNT(*)的方式,具体代码如下 1 2 3 SELECT COUNT(*) FROM foo WHERE b = 1; SELECT a FROM ...
- mysql中in查询中排序
mysql中in查询条件的时候,很多时候排序是不规则的,如何按照in里面的条件进行排序呢? mysql中给出了办法,在in后面加order by field,order by field的首个条件是按 ...
- mysql 中合并查询结果union用法 or、in与union all 的查询效率
mysql 中合并查询结果union用法 or.in与union all 的查询效率 (2016-05-09 11:18:23) 转载▼ 标签: mysql union or in 分类: mysql ...
- 下面介绍mysql中模糊查询的四种用法:
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] ...
- MySQL中的查询事务问题
之前帮同学做个app的后台,使用了MySQL+MyBatis,遇到了一个查询提交的问题,卡了很久,现在有时间了来复盘下 环境情况 假设有学生表: USE test; CREATE TABLE `stu ...
- 如何使用python将MySQL中的查询结果导出为Excel----xlwt的使用
如何在MySQL中执行的一条查询语句结果导出为Excel? 一.可选方法 1.使用sql yog等远程登录,执行查询语句并导出结果集为Excel 适用于较简单的查询结果集的导出 如果需要多个SQL语句 ...
随机推荐
- lzugis——Arcgis Server for JavaScript API之自定义InfoWindow
各位看到这个标题不要嫌烦,因为本人最近一直在研究相关的问题,所以相关文章也只能是这些,同时希望看过我的文章的朋友,我的文章能够给你帮助. 在前面的两篇相关的文章里面,实现InfoWindow是通过di ...
- [面试时]我是如何讲清楚TCP/IP是如何实现可靠传输的 转
[面试时]我是如何讲清楚TCP/IP是如何实现可靠传输的 - shawjan的专栏 - 博客频道 - CSDN.NET http://blog.csdn.net/shawjan/article/det ...
- Python 把二进制mnist数据库转换为图片
mnist数据库可以通过caffe里的get_mnist.sh文件下载,路径是: caffe-master/data/mnist/get_mnist.sh,get_mnist.sh内容如下: #!/u ...
- [QT][转载] Qt信号和槽
From: http://blog.csdn.net/rl529014/article/details/51346955 GUI 程序除了要绘制控件,还要响应系统和用户事件,例如重绘.绘制完成.点击鼠 ...
- C++中cin的使用总结
在学习C++时大家肯定迷惑过关于输入输出各种输出函数的功能,现在来总结一下各种函数的简单用法. cin建有一个缓冲区,即输入缓冲区.一次输入过程是这样的,当一次键盘输入结束时会将输入的数据存入输入缓冲 ...
- bzoj 4987 Tree
Written with StackEdit. Description 从前有棵树. 找出\(K\)个点\(A_1,A_2,-,A_K\). 使得\(∑dis(A_i,A_{i+1}),(1<= ...
- Spring中类型自动装配--byType
在Spring中,“类型自动装配”的意思是如果一个bean的数据类型与其它bean属性的数据类型相同,将自动兼容装配它. 例如,一个“persion” bean 公开以“ability”类数据类型作为 ...
- yii2史上最简单式安装教程,没有之一(转)
测试说明:按照文章下载文件,虽然是tgz文件,用winrar解压,在CMD中运行init.bat文件. 既然是安装Yii,我们先去官网下载一份Yii的高级模版,什么,你说打开页面乱七八糟的英文字母你看 ...
- 【openCV学习笔记】【2】读取并播放一段视频
#include <iostream> #include <opencv/highgui.h> int main(int argc, char** argv){ cvNamed ...
- erlang的tcp服务器模板
改来改去,最后放github了,贴的也累,蛋疼 还有一个tcp批量客户端的,也一起了 大概思路是 混合模式 使用erlang:send_after添加recv的超时处理 send在socket的opt ...